ChatLearner
1.0.0
روبوت محادثة تم تنفيذه في TensorFlow استنادًا إلى نموذج التسلسل إلى التسلسل (NMT) الجديد، مع دمج قواعد معينة بسلاسة.
بالنسبة لأولئك المهتمين بروبوتات الدردشة باللغة الصينية، يرجى التحقق هنا.
تم بناء جوهر ChatLearner (Papaya) على نموذج NMT (https://github.com/tensorflow/nmt)، والذي تم تكييفه هنا ليناسب احتياجات chatbot. نظرًا للتغييرات التي تم إجراؤها على tf.data API في TensorFlow 1.4 والعديد من التغييرات الأخرى منذ TensorFlow 1.12، فإن إصدار ChatLearner هذا يدعم فقط إصدار TF من 1.4 إلى 1.11. يمكن إجراء تحديثات سهلة في ملف tokenizeddata.py إذا كنت بحاجة إلى دعم TensorFlow 1.12.
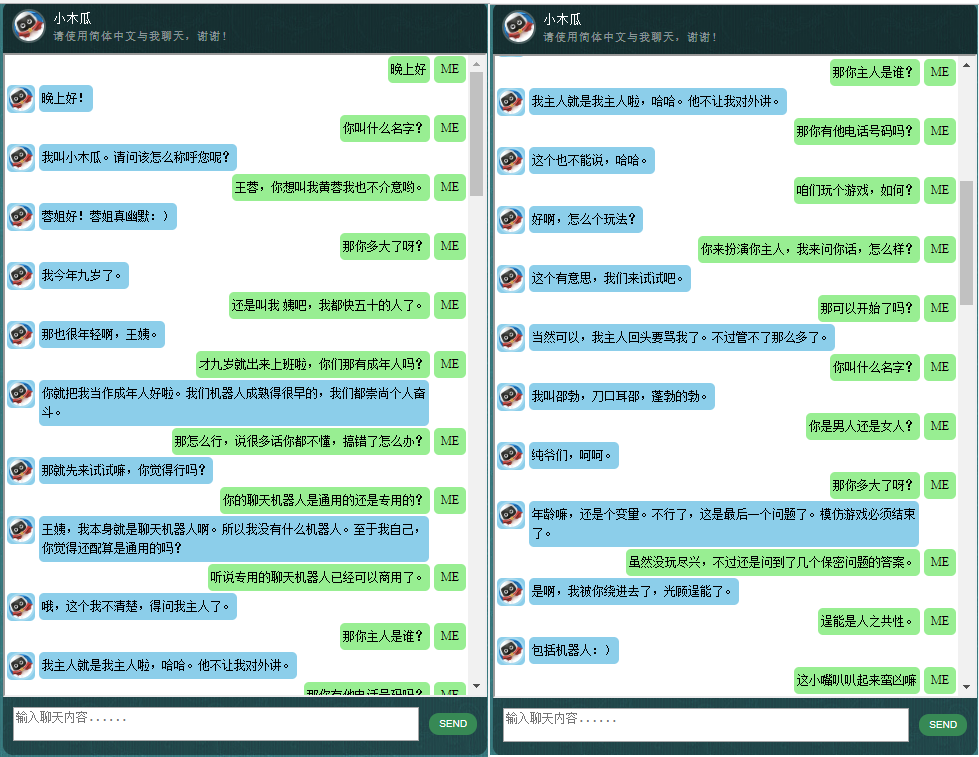
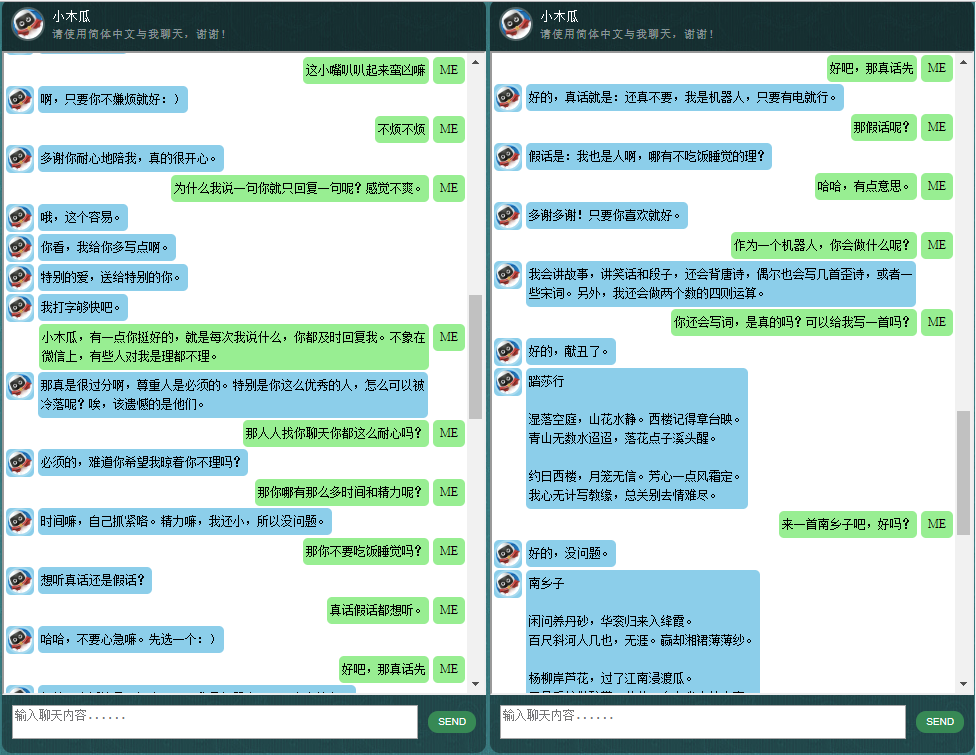
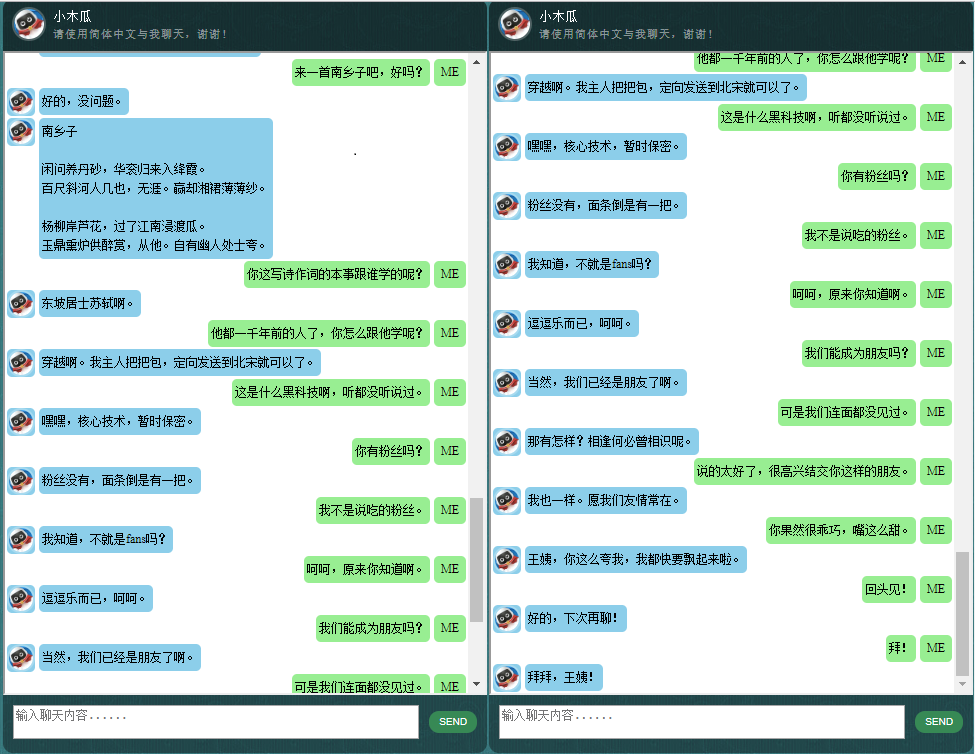
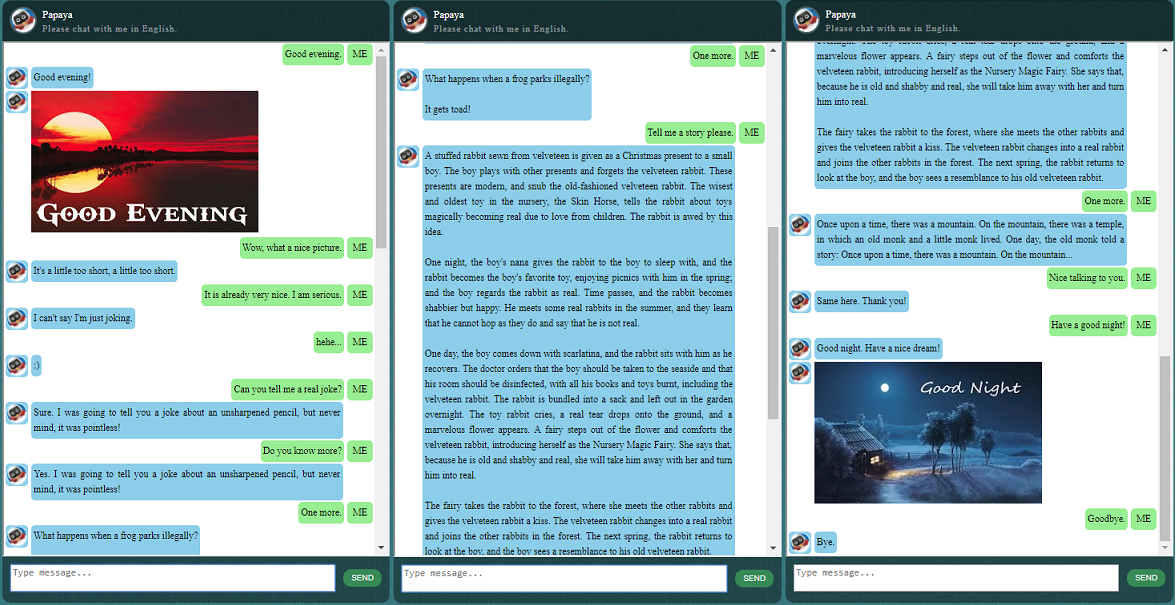
قبل البدء بكل شيء آخر، قد ترغب في التعرف على كيفية تصرف ChatLearner. قم بإلقاء نظرة على نموذج المحادثة أدناه أو هنا، أو إذا كنت تفضل تجربة نموذجي المدرب، قم بتنزيله هنا. قم بفك ضغط ملف .rar الذي تم تنزيله، وانسخ مجلد النتيجة إلى مجلد البيانات ضمن جذر المشروع الخاص بك. يتم أيضًا تضمين ملف vocab.txt في حالة قيامي بتحديثه دون تحديث النموذج المُدرب في المستقبل.
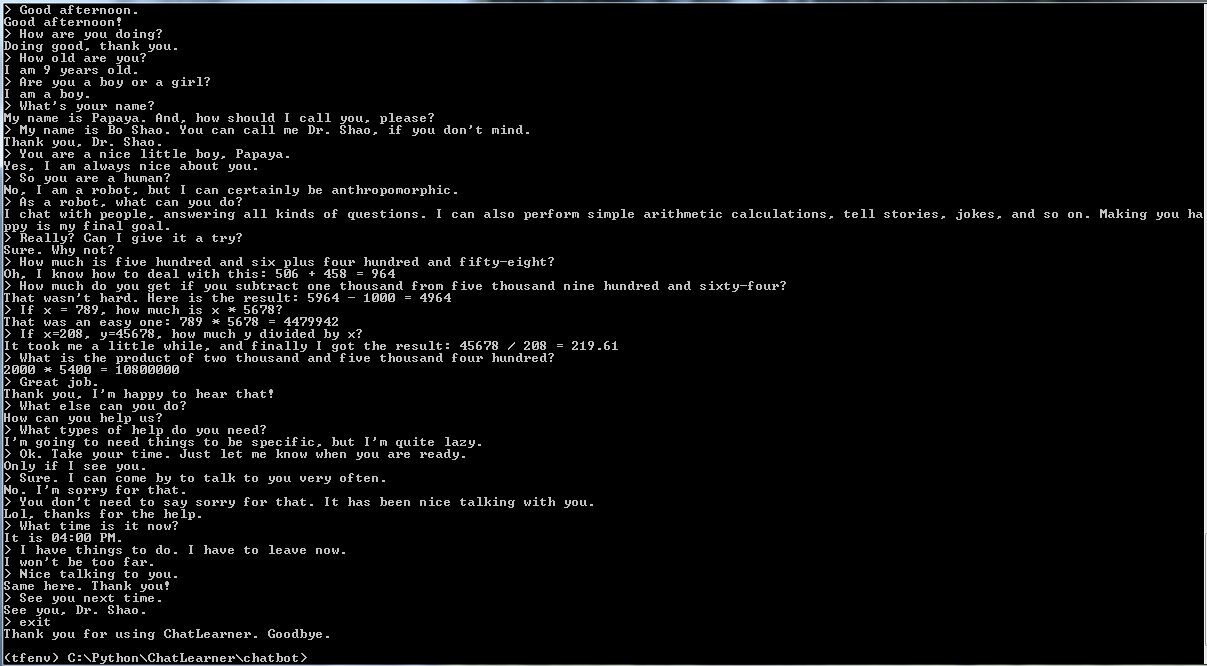
لماذا تريد قضاء بعض الوقت في التحقق من هذا المستودع؟ فيما يلي بعض الأسباب المحتملة:
مجموعة بيانات البابايا لتدريب روبوت الدردشة. يمكنك بسهولة العثور على الكثير من بيانات التدريب عبر الإنترنت، ولكن لا يمكنك العثور على أي منها بهذه الجودة العالية. انظر الوصف التفصيلي أدناه حول مجموعة البيانات.
نمط التعليمات البرمجية الموجز والتنفيذ الواضح لنموذج seq2seq الجديد المستند إلى RNN الديناميكي (المعروف أيضًا باسم نموذج NMT الجديد). إنه مخصص لروبوتات الدردشة وهو أسهل بكثير في الفهم مقارنةً بالبرنامج التعليمي الرسمي.
فكرة استخدام ChatSession المتكاملة بسلاسة للتعامل مع سياق المحادثة الأساسي.
تم دمج بعض القواعد لعرض كيفية الجمع بين برامج الدردشة التقليدية القائمة على القواعد ونماذج التعلم العميق الجديدة. بغض النظر عن مدى قوة نموذج التعلم العميق، فإنه لا يستطيع حتى الإجابة على الأسئلة التي تتطلب حسابات حسابية بسيطة، وغيرها الكثير. يمكن تكييف النهج الموضح هنا بسهولة لاسترداد الأخبار أو المعلومات الأخرى عبر الإنترنت. ومع تطبيق القواعد، يمكنه بعد ذلك الإجابة بشكل صحيح على العديد من الأسئلة المثيرة للاهتمام. على سبيل المثال:
إذا لم تكن مهتمًا بالقواعد، فيمكنك بسهولة إزالة تلك السطور المرتبطة بـ Knowledgebase.py وfunctiondata.py.
تتيح لك خدمة الويب المستندة إلى SOAP (والبديل المستند إلى REST-API، إذا كنت لا ترغب في استخدام SOAP) تقديم واجهة المستخدم الرسومية في Java، بينما يتم تدريب النموذج وتشغيله في Python وTensorFlow.
حل بسيط (في الرسم البياني) لتحويل موتر السلسلة إلى أحرف صغيرة في TensorFlow. يكون ذلك مطلوبًا إذا كنت تستخدم DataSet API الجديد (tf.data.TextLineDataSet) في TensorFlow لتحميل بيانات التدريب من الملفات النصية.
يحتوي المستودع أيضًا على تطبيق chatbot استنادًا إلى نموذج seq2seq القديم. في حال كنت مهتمًا بذلك، يرجى مراجعة فرع Legacy_Chatbot على https://github.com/bshao001/ChatLearner/tree/Legacy_Chatbot.
تعد مجموعة بيانات Papaya أفضل بيانات المحادثة الإنجليزية المجانية (الأكثر تنظيمًا وتنظيمًا) التي يمكنك العثور عليها على الويب لتدريب روبوت الدردشة. وهنا بعض التفاصيل:
تتكون البيانات من مجموعتين: المجموعة الأولى مصنوعة يدويًا، وقمنا بإنشاء العينات من أجل الحفاظ على دور ثابت لروبوت الدردشة، والذي يمكن بالتالي تدريبه ليكون مهذبًا، وصبورًا، وروح الدعابة، وفلسفيًا، ويدرك أنه كذلك. روبوت، لكنه يتظاهر بأنه صبي يبلغ من العمر 9 سنوات يدعى بابايا؛ تم تنظيف المجموعة الثانية من بعض الموارد عبر الإنترنت، بما في ذلك محادثات السيناريو المصممة لتدريب الروبوتات، ومربعات حوار أفلام كورنيل، وبيانات Reddit التي تم تنظيفها.
يتم تقسيم مجموعة بيانات التدريب إلى ثلاث فئات: سيتم زيادة/تكرار مجموعتين فرعيتين أثناء التدريب، بمستويات أو أوقات مختلفة، في حين لن يتم زيادة/تكرار المجموعة الثالثة. تهدف المجموعات الفرعية المعززة إلى تدريب النموذج بالقواعد التي يجب اتباعها، وبعض المعرفة والحس السليم، في حين أن المجموعة الفرعية الثالثة تهدف فقط إلى المساعدة في تدريب نموذج اللغة.
تم استخراج محادثات السيناريو وإعادة تنظيمها من http://www.eslfast.com/robot/. إذا كان النموذج الخاص بك يمكنه دعم السياق، فسيعمل بشكل أفضل بكثير من خلال الاستفادة من هذه المحادثات.
يمكن العثور على مجموعة بيانات كورنيل الأصلية هنا. قمنا بتنظيفه باستخدام برنامج Python النصي (يمكن أيضًا العثور على البرنامج النصي في مجلد Corpus)؛ قمنا بعد ذلك بتنظيفه يدويًا من خلال البحث السريع في أنماط معينة.
بالنسبة لبيانات Reddit، يتم تضمين مجموعة فرعية منقحة (حوالي 110 ألف زوج) في هذا المستودع. يتم إنشاء ملف vocab ومعلمات النموذج وتعديلهما بناءً على جميع ملفات البيانات المضمنة. في حالة احتياجك إلى مجموعة أكبر، يمكنك أيضًا العثور على نصوص برمجية لتحليل تعليقات Reddit وتنظيفها في مجلد Corpus/RedditData. من أجل استخدام هذه البرامج النصية، تحتاج إلى تنزيل سيل من تعليقات Reddit من رابط تورنت هنا. عادةً ما يكون شهر واحد من التعليقات كبيرًا بما يكفي (يمكن إنشاء 3 ملايين زوج من عينات التدريب تقريبًا). يمكنك ضبط المعلمات في البرامج النصية بناءً على احتياجاتك.
تمت معالجة ملفات البيانات الموجودة في مجموعة البيانات هذه مسبقًا باستخدام رمز NLTK بحيث تكون جاهزة للتغذية في النموذج باستخدام واجهة برمجة التطبيقات tf.data الجديدة في TensorFlow.
يرجى التأكد من أن لديك الإصدار الصحيح من TensorFlow. إنه يعمل فقط مع TensorFlow 1.4، وليس أي إصدارات سابقة لأن واجهة برمجة تطبيقات tf.data المستخدمة هنا تم تحديثها حديثًا في TF 1.4.
الرجاء التأكد من أن لديك إعداد PYTHONPATH لمتغير البيئة. يجب أن يشير إلى الدليل الجذر للمشروع، حيث يوجد مجلد chatbot وData وwebui. إذا كنت تستخدم بيئة تطوير متكاملة (IDE)، مثل PyCharm، فسوف يقوم بإنشاء ذلك لك. ولكن إذا قمت بتشغيل أي نصوص برمجية لبايثون في سطر الأوامر، فيجب أن يكون لديك متغير البيئة هذا، وإلا فستحصل على أخطاء في استيراد الوحدة النمطية.
يرجى التأكد من أنك تستخدم نفس ملف vocab.txt لكل من التدريب والاستدلال/التنبؤ. ضع في اعتبارك أن النموذج الخاص بك لن يرى أبدًا أي كلمات كما نفعل. إنها عبارة عن أعداد صحيحة في الداخل، وأعداد صحيحة في الخارج، بينما تساعد الكلمات وترتيبها في vocab.txt على التعيين بين الكلمات والأعداد الصحيحة.
اقضِ بعض الوقت في التفكير في حجم النموذج الذي يجب أن يكون عليه، وما يجب أن يكون الحد الأقصى لطول جهاز التشفير/وحدة فك التشفير، وحجم مجموعة المفردات، وعدد أزواج بيانات التدريب التي تريد استخدامها. انتبه إلى أن النموذج له حد للسعة: مقدار البيانات التي يمكنه تعلمها أو تذكرها. عندما يكون لديك عدد ثابت من الطبقات، وعدد الوحدات، ونوع خلية RNN (مثل GRU)، وتقرر طول التشفير/وحدة فك التشفير، فإن حجم المفردات هو الذي يؤثر بشكل أساسي على قدرة النموذج الخاص بك على التعلم، وليس عدد عينات التدريب. إذا تمكنت من عدم السماح لحجم المفردات بالنمو عند الاستفادة من المزيد من بيانات التدريب، فمن المحتمل أن ينجح ذلك، ولكن الحقيقة هي أنه عندما يكون لديك المزيد من عينات التدريب، فإن حجم المفردات أيضًا يزداد بسرعة كبيرة، وقد تلاحظ بعد ذلك لا يمكن لنموذجك استيعاب هذا الحجم من البيانات على الإطلاق. لا تتردد في فتح موضوع للمناقشة إذا أردت.
بخلاف Python 3.6 (يجب أن يعمل 3.5 أيضًا)، Numpy، وTensorFlow 1.4. تحتاج أيضًا إلى الإصدار 3.2.4 (أو 3.2.5) من NLTK (مجموعة أدوات اللغة الطبيعية).
أثناء التدريب، أقترح عليك حقًا تجربة اللعب باستخدام المعلمة (colocate_gradients_with_ops) في الوظيفة tf.gradients. يمكنك العثور على سطر مثل هذا في modelcreator.py: gradients = tf.gradients(self.train_loss, params). قم بتعيين colocate_gradients_with_ops=True (إضافته) وقم بتشغيل التدريب لفترة واحدة على الأقل، وقم بتدوين الوقت، ثم قم بتعيينه على False (أو قم بإزالته فقط) وقم بتشغيل التدريب لفترة واحدة على الأقل ومعرفة ما إذا كانت الأوقات مطلوبة لعصر واحد تختلف بشكل كبير. إنه أمر صادم بالنسبة لي على الأقل.
بخلاف ذلك، التدريب واضح ومباشر. تذكر إنشاء مجلد باسم النتيجة ضمن مجلد البيانات أولاً. ثم قم فقط بتشغيل الأوامر التالية:
cd chatbot
python bottrainer.pyيوصى بشدة باستخدام وحدات معالجة الرسومات الجيدة للتدريب لأنها قد تستغرق وقتًا طويلاً للغاية. إذا كان لديك وحدات معالجة رسومات متعددة، فسيتم استخدام الذاكرة من جميع وحدات معالجة الرسومات بواسطة TensorFlow، ويمكنك ضبط معلمة Batch_size في ملف hparams.json وفقًا لذلك لتحقيق الاستفادة الكاملة من الذاكرة. ستتمكن من رؤية نتائج التدريب ضمن المجلد Data/Result/. تأكد من وجود الملفين التاليين حيث أن كل هذه الملفات ستكون مطلوبة للاختبار والتنبؤ (ملف .meta اختياري حيث سيتم إنشاء نموذج الاستدلال بشكل مستقل):
للاختبار والتنبؤ، نقدم واجهة أوامر بسيطة وواجهة قائمة على الويب. لاحظ أن ملف vocab.txt (والملفات الموجودة في KnowledgeBase، لبرنامج chatbot هذا) مطلوب أيضًا للاستدلال. للتحقق بسرعة من أداء النموذج المُدرب، استخدم واجهة الأوامر التالية:
cd chatbot
python botui.pyانتظر حتى تحصل على موجه الأوامر ">".
يتم توفير نتيجة الاختبار التجريبي كذلك. يرجى التحقق من ذلك لمعرفة كيف يتصرف برنامج الدردشة الآلي هذا الآن: https://github.com/bshao001/ChatLearner/blob/master/Data/Test/responses.txt
يتم تنفيذ بنية خدمة الويب القائمة على SOAP، مع خادم Python وعميل Java. يتم أيضًا تضمين واجهة المستخدم الرسومية الرائعة للرجوع إليها. لمزيد من التفاصيل، يرجى مراجعة: https://github.com/bshao001/ChatLearner/tree/master/webui. يرجى العلم أن بعض المعلومات (مثل الصور) متاحة فقط على واجهة الويب (وليس في واجهة سطر الأوامر).
يتم أيضًا توفير بديل يستند إلى REST-API إذا لم يكن SOAP هو اختيارك. للحصول على التفاصيل، يرجى مراجعة: https://github.com/bshao001/ChatLearner/tree/master/webui_alternative. قد لا تتوفر بعض التحديثات الأخيرة مع هذا الخيار. قم بدمج التغييرات من الخيار الآخر إذا كنت بحاجة إلى استخدام هذا.
تم إنشاء إطار عمل ترميز البرمجة اللغوية العصبية (NLP) مرة أخرى. (自然语言处理标记框架) لا داعي للقلق بشأن هذا الأمر. ))服务等.有兴趣的朋友欢迎微信联系.