Seq2seqChatbots
1.0.0
غلاف حول Tensor2tensor للتدريب والتفاعل وإنشاء البيانات بشكل مرن لروبوتات الدردشة العصبية.
يحتوي موقع الويكي على ملاحظاتي وملخصاتي لأكثر من 150 منشورًا حديثًا يتعلق بنمذجة الحوار العصبي.
؟ قم بإجراء التدريبات الخاصة بك أو قم بتجربة النماذج المدربة مسبقًا
✅ 4 مجموعات بيانات حوارية مختلفة مدمجة مع Tensor2tensor
؟ يعمل على ما يبدو مع أي نموذج أو معلمة تشعبية تم تعيينها في Tensor2tensor
فئة أساسية قابلة للتمديد بسهولة لمشاكل الحوار
قم بتشغيل setup.py الذي يقوم بتثبيت الحزم المطلوبة ويرشدك إلى تنزيل البيانات الإضافية:
python setup.py
يمكنك تنزيل جميع النماذج المدربة المستخدمة في هذه الورقة من هنا. يحتوي كل تدريب على نقطتي تفتيش، واحدة للحد الأدنى من فقدان التحقق والأخرى بعد 150 حقبة. تتطابق البيانات وبنية مجلد التدريبات مع بعضها البعض تمامًا.
python t2t_csaky/main.py --mode=train
يمكن أن تكون وسيطة الوضع واحدة من الأربع التالية: {generate_data، Train، decode، experience} . في وضع التجربة ، يمكنك تحديد ما يجب فعله داخل وظيفة التجربة في ملف التشغيل . ويرد أدناه شرح مفصل لما يفعله كل وضع.
يمكنك التحكم في العلامات والمعلمات لكل وضع مباشرة في هذا الملف. لكل عملية تشغيل تبدأها، سيتم نسخ هذا الملف إلى الدليل المناسب، حتى تتمكن من الوصول بسرعة إلى معلمات أي عملية تشغيل. هناك بعض العلامات التي يتعين عليك تعيينها لكل وضع (قاموس FLAGS في ملف التكوين):
t2t_usr_dir : المسار إلى الدليل الذي يوجد به الكود الخاص بي. ليس عليك تغيير هذا، إلا إذا قمت بإعادة تسمية الدليل.
data_dir : المسار إلى الدليل حيث تريد إنشاء أزواج المصدر والهدف والبيانات الأخرى. سيتم تنزيل مجموعة البيانات بمستوى أعلى من هذا الدليل إلى مجلد البيانات الأولية .
المشكلة : هذا هو اسم المشكلة المسجلة التي يحتاجها Tensor2tensor. مفصلة في قسم generator_data أدناه. يجب أن تكون جميع المسارات من جذر الريبو.
سيقوم هذا الوضع بتنزيل البيانات ومعالجتها مسبقًا وإنشاء أزواج المصدر والهدف. يوجد حاليًا 6 مشاكل مسجلة يمكنك استخدامها إلى جانب تلك التي قدمها Tensor2tensor:
persona_chat_chatbot : تنفذ هذه المشكلة مجموعة بيانات Persona-Chat (بدون استخدام الشخصيات).
daily_dialog_chatbot : تنفذ هذه المشكلة مجموعة بيانات DailyDialog (بدون استخدام المواضيع أو أعمال الحوار أو العواطف).
opensubtitles_chatbot : يمكن استخدام هذه المشكلة للعمل مع مجموعة بيانات OpenSubtitles.
cornell_chatbot_basic : تطبق هذه المشكلة مجموعة Cornell Movie-Dialog Corpus.
cornell_chatbot_separate_names : تستخدم هذه المشكلة نفس مجموعة كورنيل، ولكن يتم إلحاق أسماء المتحدثين والمخاطبين لكل كلام، مما يؤدي إلى نطق المصدر كما هو موضح أدناه.
BIANCA_m0 ما هي الأشياء الجيدة؟ كاميرون_m0
Character_chatbot : هذه مشكلة عامة تعتمد على الأحرف وتعمل مع أي مجموعة بيانات. قبل استخدام هذا، يجب وضع ملفات .txt التي تم إنشاؤها بواسطة أي من المشكلات المذكورة أعلاه داخل دليل البيانات، وبعد ذلك يمكن استخدام هذه المشكلة لإنشاء ملفات بيانات تعتمد على أحرف Tensor2tensor.
يحتوي قاموس PROBLEM_HPARAMS الموجود في ملف التكوين على معلمات محددة للمشكلة يمكنك تعيينها قبل إنشاء البيانات:
num_train_shards / num_dev_shards : إذا كنت تريد تقسيم بيانات القطار أو بيانات التطوير التي تم إنشاؤها على عدة ملفات.
Dictionary_size : حجم المفردات التي نريد استخدامها للمشكلة. سيتم استبدال الكلمات خارج هذه المفردات بالرمز المميز.
dataset_size : عدد أزواج الكلام، إذا لم نرغب في استخدام مجموعة البيانات الكاملة (المحددة بـ 0).
dataset_split : حدد تقسيم اختبار-val-test للمشكلة.
dataset_version : هذا يتعلق فقط بمجموعة بيانات openubtitles، نظرًا لوجود إصدارات متعددة من مجموعة البيانات هذه، يمكنك تحديد سنة مجموعة البيانات التي تريد تنزيلها.
name_vocab_size : هذا يتعلق فقط بمسألة كورنيل ذات الأسماء المنفصلة. يمكنك ضبط حجم المفردات التي تحتوي على الشخصيات فقط.
يتيح لك هذا الوضع تدريب نموذج بالمشكلة المحددة والمعلمات الفائقة. يستدعي الكود فقط البرنامج النصي للتدريب على Tensor2tensor، لذلك يمكن استخدام أي نموذج موجود في Tensor2tensor. بالإضافة إلى ذلك، يوجد أيضًا نموذج فرعي مع تعديلات صغيرة:
gradient_checkpointed_seq2seq : تعديل صغير لنموذج seq2seq القائم على lstm، بحيث يمكن استخدام hparams بالكامل. قبل حساب softmax، من المتوقع أن تصل الوحدات المخفية LSTM إلى 2048 وحدة خطية كما هو الحال هنا. أخيرًا، حاولت تنفيذ فحص التدرج لهذا النموذج، ولكن تم حذفه حاليًا لأنه لم يعط نتائج جيدة.
هناك العديد من العلامات الإضافية التي يمكنك تحديدها لتشغيل التدريب في قاموس FLAGS في ملف التكوين، وبعضها:
Train_dir : اسم الدليل الذي سيتم حفظ ملفات نقاط تفتيش التدريب فيه.
model : اسم النموذج: إما أحد النماذج المذكورة أعلاه أو نموذج محدد بواسطة Tensor2tensor.
hparams : حدد مجموعة hparams_set المسجلة، أو اتركها فارغة إذا كنت تريد تعريف hparams في ملف التكوين. من أجل تحديد hparams لنموذج seq2seq أو محول ، يمكنك استخدام قواميس SEQ2SEQ_HPARAMS و TRANSFORMER_HPARAMS في ملف التكوين (راجعه لمزيد من التفاصيل).
باستخدام هذا الوضع، يمكنك فك التشفير من النماذج المدربة. تؤثر المعلمات التالية على فك التشفير (في قاموس FLAGS في ملف التكوين):
decode_mode : يمكن أن يكون تفاعليًا ، حيث يمكنك الدردشة مع العارضة باستخدام سطر الأوامر. يتيح لك وضع الملف تحديد ملف يحتوي على عبارات المصدر لإنشاء استجابات له، وسيقوم وضع مجموعة البيانات بأخذ عينات عشوائية من بيانات التحقق المقدمة وإخراج الاستجابات.
decode_dir : الدليل الذي يمكنك من خلاله توفير ملف لفك التشفير منه، وسيتم حفظ الاستجابات الناتجة هنا.
input_file_name : اسم الملف الذي يجب عليك تقديمه في وضع الملف (الموجود في decode_dir ).
Output_file_name : اسم الملف، داخل decode_dir ، حيث سيتم حفظ استجابات الإخراج.
beam_size : حجم الشعاع، عند استخدام البحث عن الشعاع.
return_beams : إذا كانت القيمة False، فسيتم إرجاع الشعاع العلوي فقط، وإلا فسيتم إرجاع عدد الحزم من الحزم.
النتائج التالية هي من هاتين الورقتين.
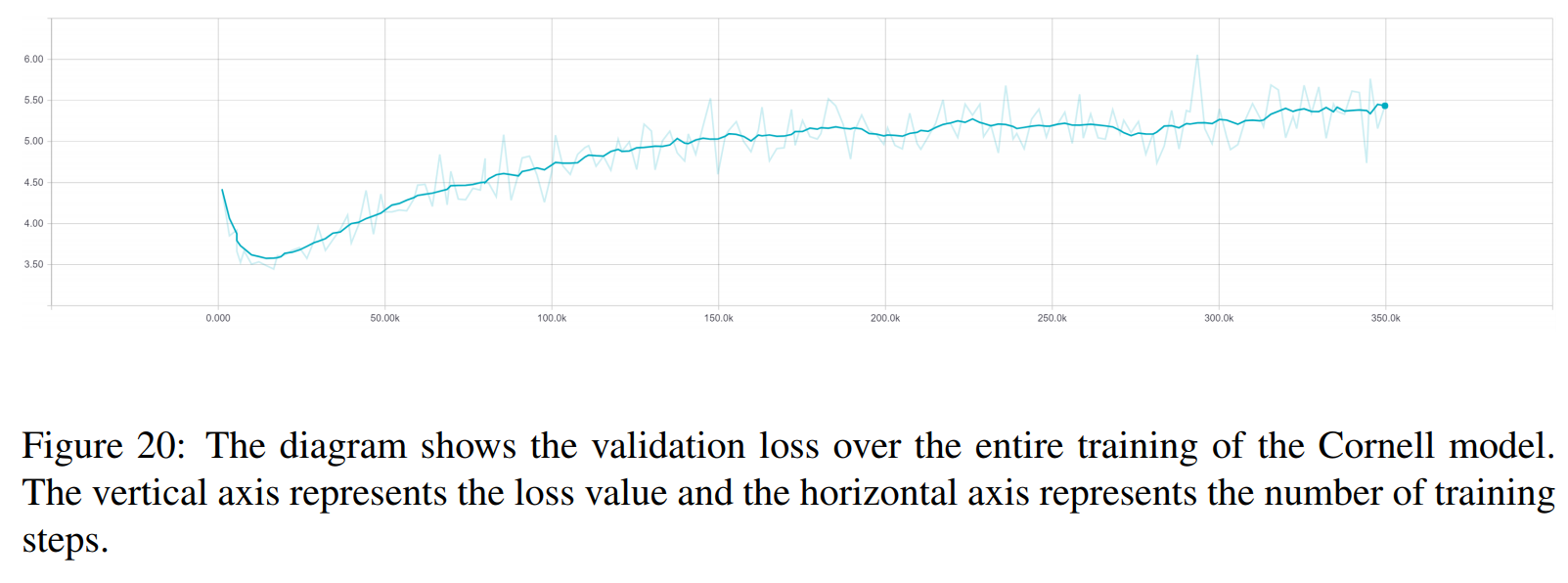

TRF هو نموذج المحولات، بينما RT تعني الاستجابات المختارة عشوائيًا من مجموعة التدريب وGT تعني استجابات الحقيقة الأرضية. للحصول على شرح للمقاييس راجع الورقة.
S2S هو نموذج seq2seq بسيط مع LSTMs المدربة في جامعة كورنيل، والبعض الآخر عبارة عن نماذج محولة. تم تدريب Opensubtitles F مسبقًا على Opensubtitles وتم ضبطه على جامعة Cornell. 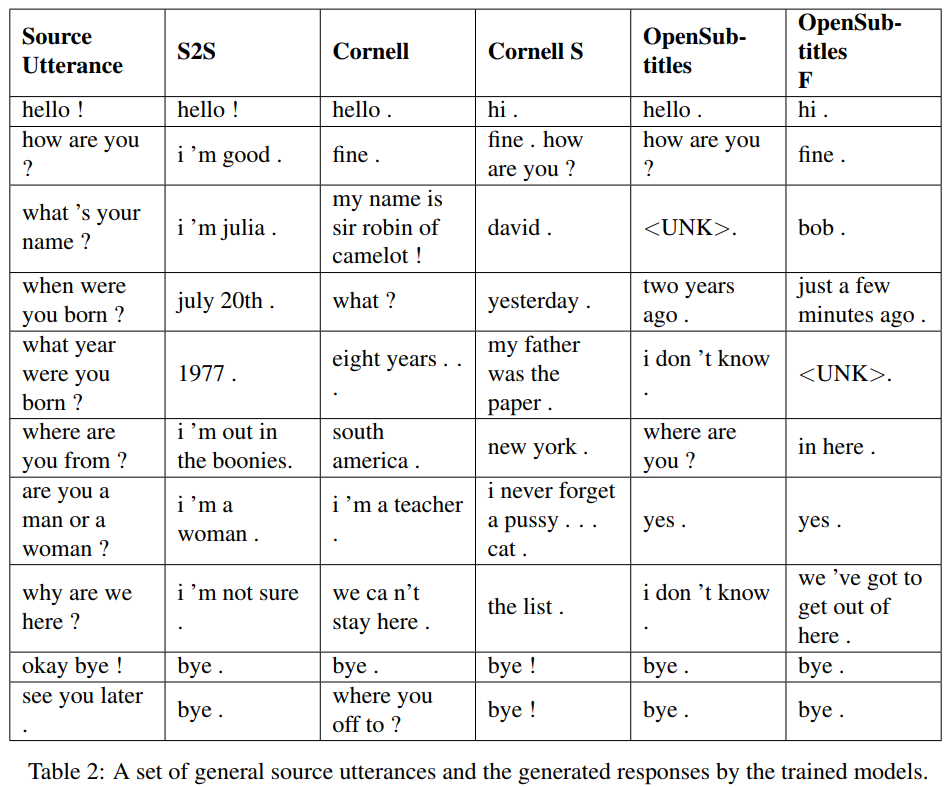
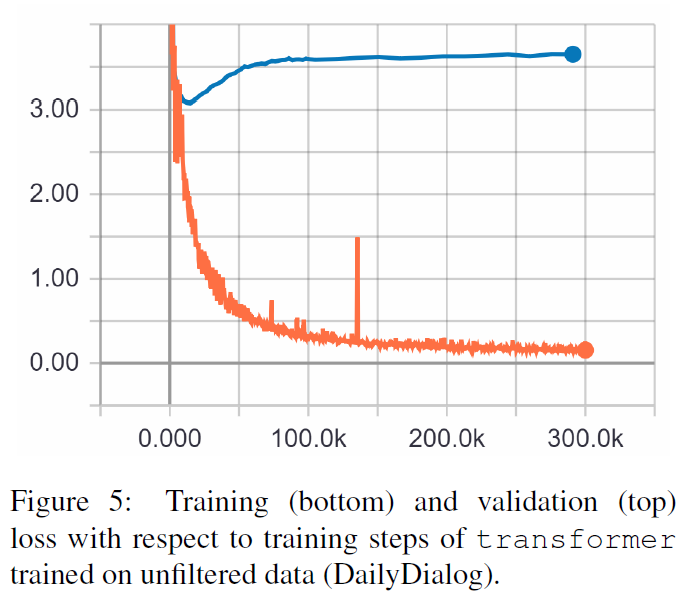

TRF هو نموذج المحولات، بينما RT تعني الاستجابات المختارة عشوائيًا من مجموعة التدريب وGT تعني استجابات الحقيقة الأرضية. للحصول على شرح للمقاييس راجع الورقة.
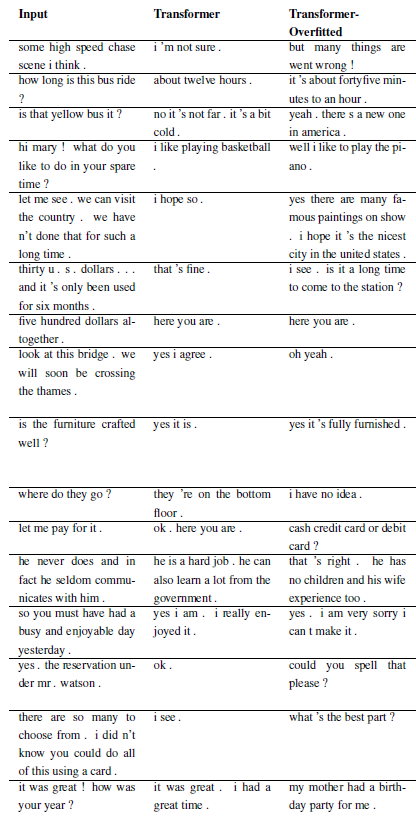
يمكن تسجيل المشكلات الجديدة عن طريق التصنيف الفرعي WordChatbot، أو حتى الأفضل عن طريق التصنيف الفرعي CornellChatbotBasic أو OpensubtitleChatbot، لأنها تنفذ بعض الوظائف الإضافية. عادةً ما يكون ذلك كافيًا لتجاوز وظائف المعالجة المسبقة و create_data . تحقق من الوثائق للحصول على مزيد من التفاصيل وراجع daily_dialog_chatbot للحصول على مثال.
يمكن إضافة نماذج ومعلمات تشعبية جديدة باتباع البرنامج التعليمي لـ Tensor2tensor.
ريتشارد ساكي (إذا كنت بحاجة إلى أي مساعدة في تشغيل الكود: [email protected])
هذا المشروع مرخص بموجب ترخيص MIT - راجع ملف الترخيص للحصول على التفاصيل.
يرجى تضمين رابط لهذا الريبو إذا كنت تستخدمه في عملك وفكر في الاستشهاد بالمقالة التالية:
@InProceedings{Csaky:2017,
title = {Deep Learning Based Chatbot Models},
author = {Csaky, Richard},
year = {2019},
publisher={National Scientific Students' Associations Conference},
url ={https://tdk.bme.hu/VIK/DownloadPaper/asdad},
note={https://tdk.bme.hu/VIK/DownloadPaper/asdad}
} 

