clearml fractional gpu
1.0.0
? Leave a star to support the project! ?
تعد مشاركة وحدات معالجة الرسومات المتطورة أو حتى وحدات معالجة الرسومات الخاصة بالمستهلكين والمستهلكين بين عدة مستخدمين هي الطريقة الأكثر فعالية من حيث التكلفة لتسريع تطوير الذكاء الاصطناعي. لسوء الحظ، حتى الآن يتم تطبيق الحل الوحيد الموجود على وحدات معالجة الرسوميات MIG/Slicing المتطورة (A100+) وKubernetes المطلوبة،
؟ مرحبًا بك في وحدة معالجة الرسوميات الجزئية القائمة على الحاوية لأي بطاقة Nvidia! ؟
نقدم حاويات معبأة مسبقًا تدعم CUDA 11.x وCUDA 12.x مع حدود الذاكرة الصلبة المعدة مسبقًا! وهذا يعني أنه يمكن إطلاق حاويات متعددة على نفس وحدة معالجة الرسومات، مما يضمن عدم تمكن مستخدم واحد من تخصيص ذاكرة وحدة معالجة الرسومات المضيفة بالكامل! (لا مزيد من العمليات الجشعة التي تستحوذ على ذاكرة وحدة معالجة الرسومات بأكملها! أخيرًا، لدينا خيار الذاكرة الصعبة لمستوى السائق).
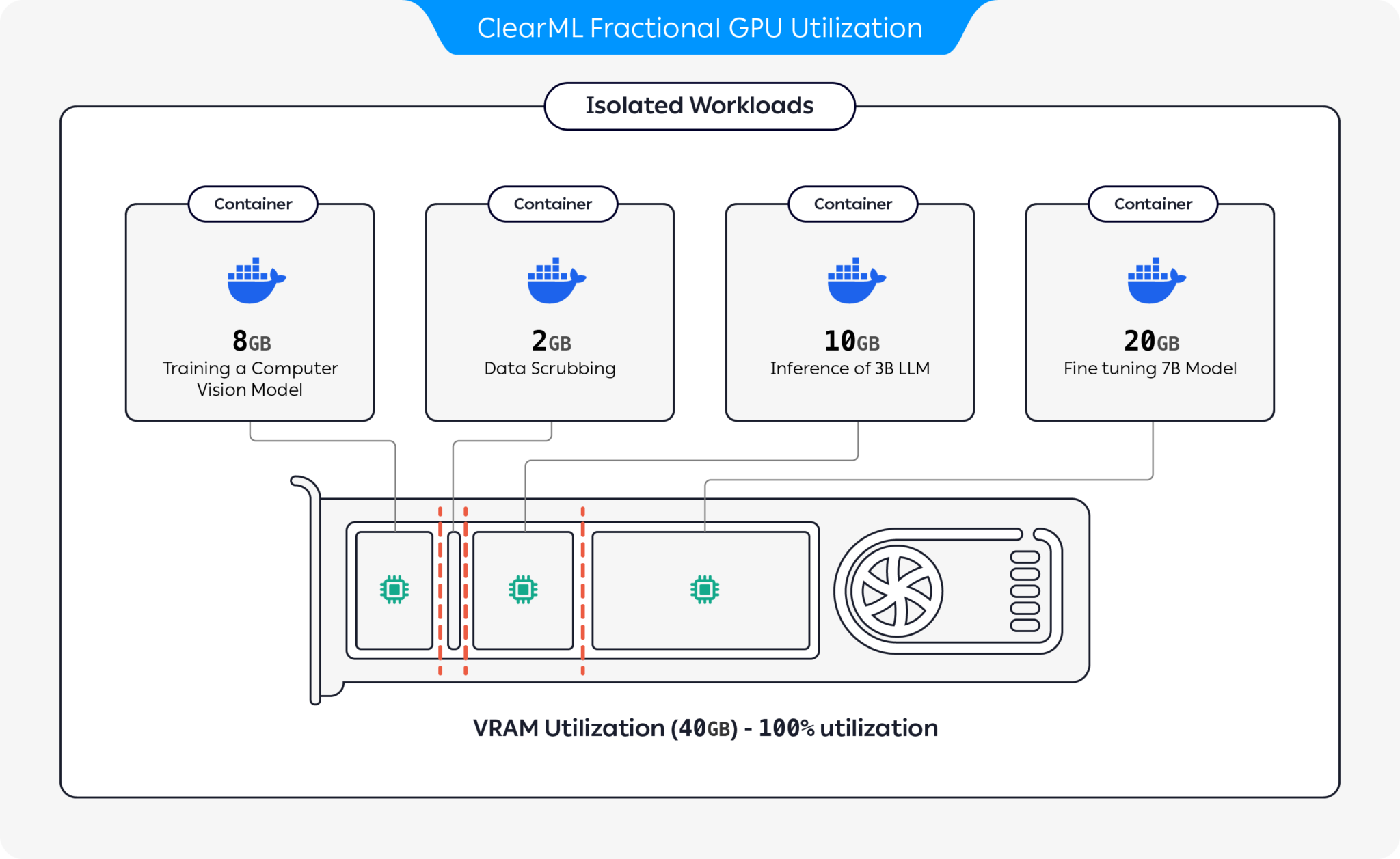
يوفر ClearML العديد من الخيارات لتحسين استخدام موارد وحدة معالجة الرسومات عن طريق تقسيم وحدات معالجة الرسومات:
باستخدام هذه الخيارات، يتيح ClearML تشغيل أحمال عمل الذكاء الاصطناعي مع الاستخدام الأمثل للأجهزة وأداء أحمال العمل. يغطي هذا المستودع وحدات معالجة الرسومات الكسرية القائمة على الحاوية. لمزيد من المعلومات حول عروض GPU الجزئية الخاصة بـ ClearML، راجع وثائق ClearML.
اختر الحاوية التي تناسبك وقم بتشغيلها:
docker run -it --gpus 0 --ipc=host --pid=host clearml/fractional-gpu:u22-cu12.3-8gb bashللتحقق من أن الحد الأقصى لذاكرة GPU يعمل بشكل صحيح، قم بتشغيل داخل الحاوية:
nvidia-smiفيما يلي مثال لإخراج وحدة معالجة الرسوميات A100:
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 545.23.08 Driver Version: 545.23.08 CUDA Version: 12.3 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 A100-PCIE-40GB Off | 00000000:01:00.0 Off | N/A |
| 32% 33C P0 66W / 250W | 0MiB / 8128MiB | 3% Default |
| | | Disabled |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
+---------------------------------------------------------------------------------------+
| حد الذاكرة | كودا الاصدار | أوبونتو الإصدار | صورة عامل الميناء |
|---|---|---|---|
| 12 جيجا بايت | 12.3 | 22.04 | clearml/fractional-gpu:u22-cu12.3-12gb |
| 12 جيجا بايت | 12.3 | 20.04 | clearml/fractional-gpu:u20-cu12.3-12gb |
| 12 جيجا بايت | 11.7 | 22.04 | clearml/fractional-gpu:u22-cu11.7-12gb |
| 12 جيجا بايت | 11.1 | 20.04 | clearml/fractional-gpu:u20-cu11.1-12gb |
| 8 جيجا بايت | 12.3 | 22.04 | clearml/fractional-gpu:u22-cu12.3-8gb |
| 8 جيجا بايت | 12.3 | 20.04 | clearml/fractional-gpu:u20-cu12.3-8gb |
| 8 جيجا بايت | 11.7 | 22.04 | clearml/fractional-gpu:u22-cu11.7-8gb |
| 8 جيجا بايت | 11.1 | 20.04 | clearml/fractional-gpu:u20-cu11.1-8gb |
| 4 جيجا بايت | 12.3 | 22.04 | clearml/fractional-gpu:u22-cu12.3-4gb |
| 4 جيجا بايت | 12.3 | 20.04 | clearml/fractional-gpu:u20-cu12.3-4gb |
| 4 جيجا بايت | 11.7 | 22.04 | clearml/fractional-gpu:u22-cu11.7-4gb |
| 4 جيجا بايت | 11.1 | 20.04 | clearml/fractional-gpu:u20-cu11.1-4gb |
| 2 جيجا بايت | 12.3 | 22.04 | clearml/fractional-gpu:u22-cu12.3-2gb |
| 2 جيجا بايت | 12.3 | 20.04 | clearml/fractional-gpu:u20-cu12.3-2gb |
| 2 جيجا بايت | 11.7 | 22.04 | clearml/fractional-gpu:u22-cu11.7-2gb |
| 2 جيجا بايت | 11.1 | 20.04 | clearml/fractional-gpu:u20-cu11.1-2gb |
مهم
يجب عليك تنفيذ الحاوية باستخدام --pid=host !
ملحوظة
--pid=host مطلوب للسماح للسائق بالتمييز بين عمليات الحاوية والعمليات المضيفة الأخرى عند الحد من استخدام الذاكرة/الاستخدام
نصيحة
يضيف مستخدمو ClearML-Agent [--pid=host] إلى قسم agent.extra_docker_arguments في ملف التكوين الخاص بك
قم ببناء الحاويات الخاصة بك وورثها من الحاويات الأصلية.
يمكنك العثور على بعض الأمثلة هنا.
يمكن استخدام حاويات GPU الجزئية في عمليات التنفيذ المعدنية وكذلك Kubernetes PODs. نعم! باستخدام إحدى حاويات GPU الجزئية، يمكنك الحد من استهلاك الذاكرة لوظيفتك/جرابتك ومشاركة وحدات معالجة الرسومات بسهولة دون الخوف من تعطل الذاكرة لبعضها البعض!
إليك قالب Kubernetes POD بسيط:
apiVersion : v1
kind : Pod
metadata :
name : train-pod
labels :
app : trainme
spec :
hostPID : true
containers :
- name : train-container
image : clearml/fractional-gpu:u22-cu12.3-8gb
command : ['python3', '-c', 'print(f"Free GPU Memory: (free, global) {torch.cuda.mem_get_info()}")'] مهم
يجب عليك تنفيذ الكبسولة باستخدام hostPID: true !
ملحوظة
hostPID: true مطلوب للسماح للسائق بالتمييز بين عمليات الكبسولة والعمليات المضيفة الأخرى عند الحد من استخدام الذاكرة/الاستخدام
تدعم الحاويات برامج تشغيل Nvidia <= 545.xx . سنستمر في تحديث ودعم برامج التشغيل الجديدة مع استمرار إصدارها
وحدات معالجة الرسومات المدعومة : سلسلة RTX 10 و20 و30 و40 وسلسلة A ومركز البيانات P100 وA100 وA10/A40 وL40/s وH100
القيود : أجهزة Windows Host غير مدعومة حاليًا. إذا كان هذا مهمًا بالنسبة لك، فاترك طلبًا في قسم المشكلات
س : هل سيؤدي تشغيل nvidia-smi داخل الحاوية إلى الإبلاغ عن استهلاك وحدة معالجة الرسومات للعمليات المحلية؟
ج : نعم، يتصل nvidia-smi مباشرة مع برامج التشغيل ذات المستوى المنخفض ويبلغ عن كل من ذاكرة GPU الدقيقة للحاوية بالإضافة إلى قيود الذاكرة المحلية للحاوية.
ملاحظة: سيكون استخدام وحدة معالجة الرسومات هو استخدام وحدة معالجة الرسومات العالمية (أي الجانب المضيف) وليس استخدام وحدة معالجة الرسومات الخاصة بالحاوية المحلية المحددة.
س : كيف أتأكد من أن ذاكرة Python / Pytorch / Tensorflow محدودة بالفعل؟
ج : بالنسبة لـ PyTorch يمكنك تشغيل:
import torch
print ( f'Free GPU Memory: (free, global) { torch . cuda . mem_get_info () } ' )مثال نومبا:
from numba import cuda
print ( f'Free GPU Memory: { cuda . current_context (). get_memory_info () } ' ) س : هل يمكن للمستخدم كسر القيد؟
ج : نحن على يقين من أن المستخدم الخبيث سيجد طريقة. لم تكن نيتنا أبدًا الحماية من المستخدمين الضارين.
إذا كان لديك مستخدم ضار يمكنه الوصول إلى أجهزتك، فإن وحدات معالجة الرسومات الكسرية ليست هي المشكلة رقم 1 بالنسبة لك؟
س : كيف يمكنني اكتشاف محدودية الذاكرة برمجياً؟
ج : يمكنك التحقق من متغير بيئة نظام التشغيل GPU_MEM_LIMIT_GB .
لاحظ أن تغييره لن يؤدي إلى إزالة القيد أو تقليله.
س : هل تشغيل الحاوية باستخدام --pid=host آمن/آمن؟
ج : يجب أن يكون آمنًا ومأمونًا. التحذير الرئيسي من منظور أمني هو أن عملية الحاوية يمكنها رؤية أي سطر أوامر يعمل على النظام المضيف. إذا كان سطر أوامر العملية يحتوي على "سر"، فنعم، قد يصبح هذا بمثابة تسرب محتمل للبيانات. لاحظ أن تمرير "الأسرار" في سطر الأوامر أمر غير حكيم، وبالتالي لا نعتبره خطرًا أمنيًا. ومع ذلك، إذا كان الأمان هو المفتاح، فإن إصدار المؤسسة (انظر أدناه) يلغي الحاجة إلى التشغيل مع pid-host وبالتالي آمن تمامًا.
س : هل يمكنك تشغيل الحاوية بدون --pid=host ؟
ج : يمكنك! ولكن سيتعين عليك استخدام إصدار المؤسسة من حاوية Clearml-fractional-gpu (وإلا سيتم تطبيق حد الذاكرة على مستوى النظام بدلاً من عرض الحاوية). إذا كانت هذه الميزة مهمة بالنسبة لك، فيرجى الاتصال بمبيعات ودعم ClearML.
يتم منح ترخيص استخدام ClearML لأغراض البحث أو التطوير فقط. يمكن استخدام ClearML للاستخدام التعليمي أو الشخصي أو التجاري الداخلي.
يتوفر ترخيص تجاري موسع للاستخدام ضمن منتج أو خدمة كجزء من حل ClearML Scale أو Enterprise.
يوفر ClearML ترخيصًا مؤسسيًا وتجاريًا يضيف العديد من الميزات الإضافية بالإضافة إلى وحدات معالجة الرسومات الجزئية، بما في ذلك التنسيق وقوائم الانتظار ذات الأولوية وإدارة الحصص ولوحة معلومات المجموعة الحاسوبية وإدارة مجموعة البيانات وإدارة التجارب، بالإضافة إلى الأمان والدعم على مستوى المؤسسة. تعرف على المزيد حول ClearML Orchestration أو تحدث إلينا مباشرة في مبيعات ClearML.
أخبر الجميع عن ذلك! #ClearMLFractionalGPU
انضم إلى قناة سلاك الخاصة بنا
أخبرنا عندما لا تعمل الأمور، وساعدنا في تصحيح الأخطاء في صفحة المشكلات
تم تقديم هذا المنتج لك بواسطة فريق ClearML مع ❤️


