optuna
v4.1.0
؟ الموقع | ؟ مستندات | دليل التثبيت | البرنامج التعليمي | أمثلة | تويتر | لينكدين | واسطة
Optuna هو إطار عمل برمجي لتحسين المعلمات الفائقة تلقائيًا، وهو مصمم خصيصًا للتعلم الآلي. إنه يتميز بواجهة برمجة تطبيقات مستخدم ذات نمط محدد حسب التشغيل . بفضل واجهة برمجة التطبيقات التي يتم تحديدها عن طريق التشغيل ، تتمتع التعليمات البرمجية المكتوبة باستخدام Optuna بنمطية عالية، ويمكن لمستخدم Optuna إنشاء مساحات بحث للمعلمات الفائقة ديناميكيًا.
Terminator ، والذي تم توسيعه في Optuna 4.0.JournalStorage ، المستقر في Optuna 4.0.pip install -U optuna . ابحث عن الأحدث هنا وتحقق من مقالتنا. تتمتع Optuna بوظائف حديثة على النحو التالي:
نستخدم مصطلحي الدراسة والتجربة على النحو التالي:
الرجاء الرجوع إلى نموذج التعليمات البرمجية أدناه. الهدف من الدراسة هو اكتشاف المجموعة المثالية من قيم المعلمات الفائقة (على سبيل المثال، regressor و svr_c ) من خلال تجارب متعددة (على سبيل المثال، n_trials=100 ). Optuna هو إطار مصمم لأتمتة وتسريع دراسات التحسين.
import ...
# Define an objective function to be minimized.
def objective ( trial ):
# Invoke suggest methods of a Trial object to generate hyperparameters.
regressor_name = trial . suggest_categorical ( 'regressor' , [ 'SVR' , 'RandomForest' ])
if regressor_name == 'SVR' :
svr_c = trial . suggest_float ( 'svr_c' , 1e-10 , 1e10 , log = True )
regressor_obj = sklearn . svm . SVR ( C = svr_c )
else :
rf_max_depth = trial . suggest_int ( 'rf_max_depth' , 2 , 32 )
regressor_obj = sklearn . ensemble . RandomForestRegressor ( max_depth = rf_max_depth )
X , y = sklearn . datasets . fetch_california_housing ( return_X_y = True )
X_train , X_val , y_train , y_val = sklearn . model_selection . train_test_split ( X , y , random_state = 0 )
regressor_obj . fit ( X_train , y_train )
y_pred = regressor_obj . predict ( X_val )
error = sklearn . metrics . mean_squared_error ( y_val , y_pred )
return error # An objective value linked with the Trial object.
study = optuna . create_study () # Create a new study.
study . optimize ( objective , n_trials = 100 ) # Invoke optimization of the objective function. ملحوظة
يمكن العثور على المزيد من الأمثلة في أمثلة optuna/optuna.
تغطي الأمثلة إعدادات المشكلات المتنوعة مثل التحسين متعدد الأهداف، والتحسين المقيد، والتشذيب، والتحسين الموزع.
Optuna متاح في Python Package Index وعلى Anaconda Cloud.
# PyPI
$ pip install optuna # Anaconda Cloud
$ conda install -c conda-forge optunaمهم
يدعم Optuna إصدار Python 3.8 أو الأحدث.
كما نقدم أيضًا صور Optuna docker على DockerHub.
تتمتع Optuna بميزات التكامل مع العديد من مكتبات الطرف الثالث. يمكن العثور على عمليات التكامل في optuna/optuna-integration والوثيقة متاحة هنا.
Optuna Dashboard عبارة عن لوحة تحكم ويب في الوقت الفعلي لـ Optuna. يمكنك التحقق من سجل التحسين وأهمية المعلمة الفائقة وما إلى ذلك في الرسوم البيانية والجداول. لا تحتاج إلى إنشاء برنامج نصي Python لاستدعاء وظائف التصور الخاصة بـ Optuna. نرحب بطلبات الميزات وتقارير الأخطاء!
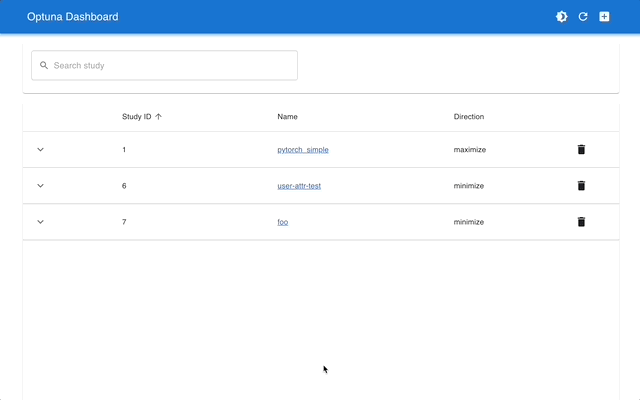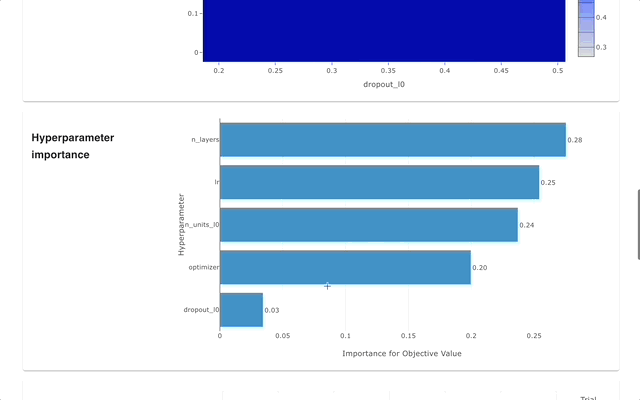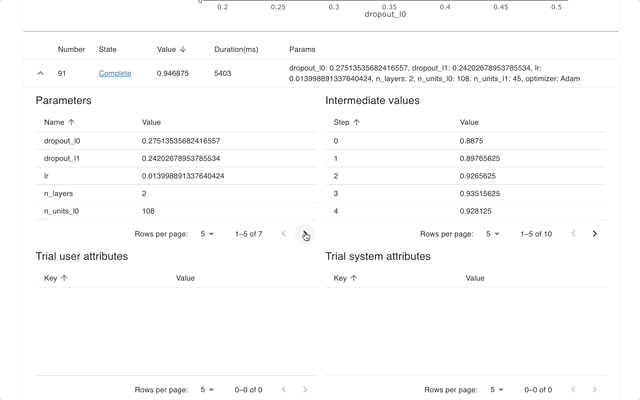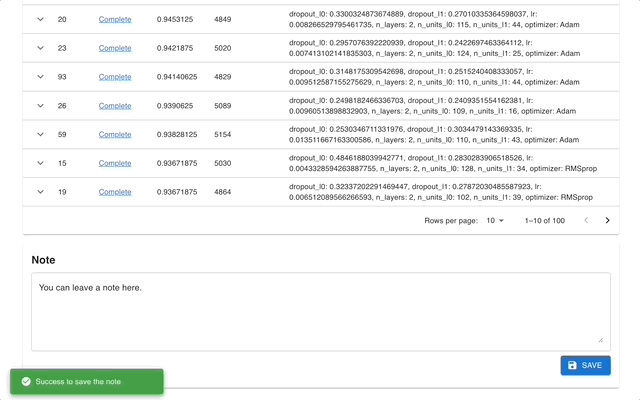
يمكن تثبيت optuna-dashboard عبر النقطة:
$ pip install optuna-dashboardنصيحة
يرجى التحقق من ملاءمة Optuna Dashboard باستخدام نموذج التعليمات البرمجية أدناه.
احفظ الكود التالي باسم optimize_toy.py .
import optuna
def objective ( trial ):
x1 = trial . suggest_float ( "x1" , - 100 , 100 )
x2 = trial . suggest_float ( "x2" , - 100 , 100 )
return x1 ** 2 + 0.01 * x2 ** 2
study = optuna . create_study ( storage = "sqlite:///db.sqlite3" ) # Create a new study with database.
study . optimize ( objective , n_trials = 100 )ثم جرب الأوامر أدناه:
# Run the study specified above
$ python optimize_toy.py
# Launch the dashboard based on the storage `sqlite:///db.sqlite3`
$ optuna-dashboard sqlite:///db.sqlite3
...
Listening on http://localhost:8080/
Hit Ctrl-C to quit.OptunaHub عبارة عن منصة لمشاركة الميزات لـ Optuna. يمكنك استخدام الميزات المسجلة ونشر الحزم الخاصة بك.
يمكن تثبيت optunahub عبر النقطة:
$ pip install optunahub
# Install AutoSampler dependencies (CPU only is sufficient for PyTorch)
$ pip install cmaes scipy torch --extra-index-url https://download.pytorch.org/whl/cpu يمكنك تحميل الوحدة المسجلة باستخدام optunahub.load_module .
import optuna
import optunahub
def objective ( trial : optuna . Trial ) -> float :
x = trial . suggest_float ( "x" , - 5 , 5 )
y = trial . suggest_float ( "y" , - 5 , 5 )
return x ** 2 + y ** 2
module = optunahub . load_module ( package = "samplers/auto_sampler" )
study = optuna . create_study ( sampler = module . AutoSampler ())
study . optimize ( objective , n_trials = 10 )
print ( study . best_trial . value , study . best_trial . params )لمزيد من التفاصيل، يرجى الرجوع إلى وثائق optunahub.
يمكنك نشر الحزمة الخاصة بك عبر سجل optunahub. راجع البرنامج التعليمي OptunaHub.
أي مساهمات في Optuna هي موضع ترحيب كبير!
إذا كنت جديدًا في Optuna، فيرجى التحقق من الأعداد الأولى الجيدة. إنها نقاط بداية بسيطة نسبيًا ومحددة جيدًا وغالبًا ما تكون جيدة للتعرف على سير عمل المساهمة والمطورين الآخرين.
إذا كنت قد ساهمت بالفعل في Optuna، فإننا نوصي بالقضايا الأخرى المتعلقة بالترحيب بالمساهمة.
للحصول على إرشادات عامة حول كيفية المساهمة في المشروع، قم بإلقاء نظرة على CONTRIBUTING.md.
إذا كنت تستخدم Optuna في أحد مشاريعك البحثية، فيرجى الاستشهاد بمقالة KDD الخاصة بنا "Optuna: إطار عمل تحسين المعلمات الفائقة من الجيل التالي":
@inproceedings { akiba2019optuna ,
title = { {O}ptuna: A Next-Generation Hyperparameter Optimization Framework } ,
author = { Akiba, Takuya and Sano, Shotaro and Yanase, Toshihiko and Ohta, Takeru and Koyama, Masanori } ,
booktitle = { The 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining } ,
pages = { 2623--2631 } ,
year = { 2019 }
}ترخيص معهد ماساتشوستس للتكنولوجيا (انظر الترخيص).
تستخدم Optuna الرموز من مشاريع SciPy وfdlibm (راجع LICENSE_THIRD_PARTY).


