SmartFilteringRAG
1.0.0
هل بحثت يومًا عن "أفلام كوميدية قديمة بالأبيض والأسود" لتتعرض لقصف بمزيج من أفلام الحركة الحديثة؟ محبط ، أليس كذلك؟ هذا هو التحدي الذي تواجهه محركات البحث التقليدية - فهي غالبًا ما تكافح من أجل فهم الفروق الدقيقة في استعلاماتنا، مما يتركنا نخوض في نتائج غير ذات صلة.
هذا هو المكان الذي تأتي فيه التصفية الذكية. إنها تغير قواعد اللعبة حيث تستخدم البيانات التعريفية والبحث المتجه لتقديم نتائج بحث تتوافق حقًا مع هدفك. تخيل العثور على الأفلام الكوميدية الكلاسيكية التي تتوق إليها بالضبط، دون أي متاعب.
سوف نتعمق في ماهية التصفية الذكية، وكيفية عملها، وسبب أهميتها لبناء تجارب بحث أفضل. دعنا نكشف عن السحر الكامن وراء هذه التقنية ونكتشف كيف يمكن أن تُحدث ثورة في طريقة البحث.
يعد البحث المتجه أداة قوية تساعد أجهزة الكمبيوتر على فهم المعنى الكامن وراء البيانات، وليس فقط الكلمات نفسها. بدلاً من مطابقة الكلمات الرئيسية، فإنه يركز على المفاهيم والعلاقات الأساسية. تخيل أنك تبحث عن "كلب" وتحصل على نتائج تتضمن "جرو" و"كلاب" وحتى صور للكلاب. هذا هو سحر البحث عن المتجهات!
كيف يعمل؟ حسنًا، فهو يحول البيانات إلى تمثيلات رياضية تسمى المتجهات. تشبه هذه المتجهات الإحداثيات الموجودة على الخريطة، ونقاط البيانات المتشابهة تكون أقرب إلى بعضها البعض في مساحة المتجهات هذه. عندما تبحث عن شيء ما، يعثر النظام على المتجهات الأقرب إلى استعلامك، مما يوفر لك نتائج متشابهة من الناحية اللغوية.
على الرغم من أن بحث المتجهات رائع في فهم السياق، إلا أنه يفشل أحيانًا عندما يتعلق الأمر بمهام التصفية البسيطة. على سبيل المثال، يتطلب العثور على جميع الأفلام التي تم إصدارها قبل عام 2000 تصفية دقيقة، وليس مجرد الفهم الدلالي. هذا هو المكان الذي تأتي فيه التصفية الذكية لاستكمال البحث عن المتجهات.
في حين أن المتجهات تقربنا من فهم المعنى الحقيقي للاستعلامات، لا تزال هناك فجوة بين ما يريده المستخدمون وما تقدمه محركات البحث. لا تزال طلبات البحث المعقدة مثل "أقدم الأفلام الكوميدية قبل عام 2000" تمثل تحديًا. قد يفهم البحث الدلالي مفهومي "الكوميديا" و"الأفلام"، ولكنه قد يواجه صعوبة في التعامل مع تفاصيل "الأقدم" و"قبل عام 2000".
هذا هو المكان الذي تبدأ فيه النتائج بالفوضى. قد نحصل على مزيج من الأعمال الكوميدية القديمة والجديدة، أو حتى الأعمال الدرامية التي تم تضمينها عن طريق الخطأ. ولإرضاء المستخدمين حقًا، نحتاج إلى طريقة لتحسين نتائج البحث هذه وجعلها أكثر دقة. وهنا يأتي دور المرشحات المسبقة.
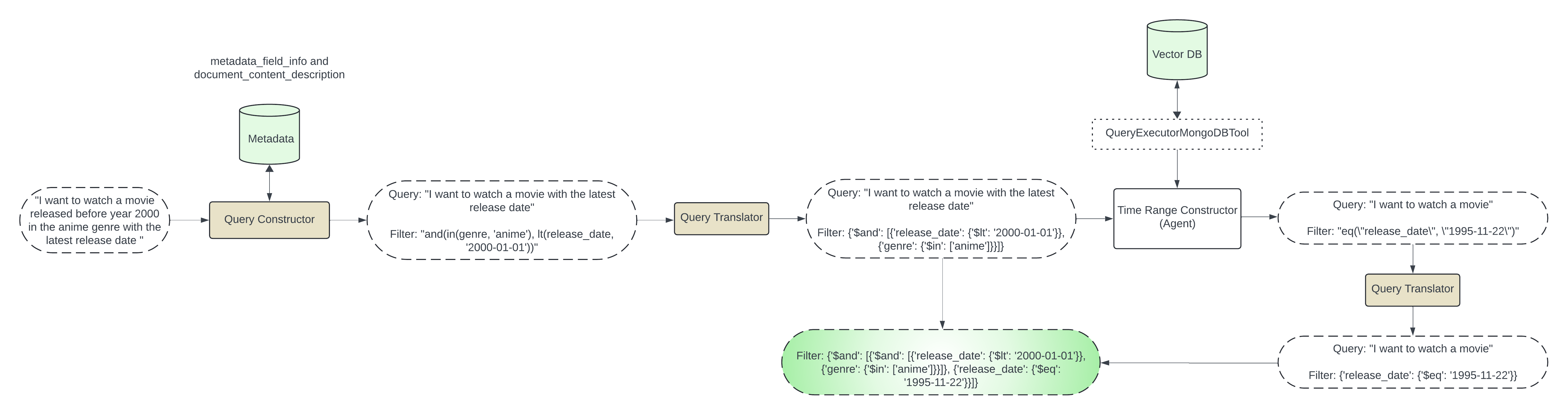
التصفية الذكية هي الحل لهذا التحدي. إنها تقنية تستخدم البيانات التعريفية لمجموعة البيانات لإنشاء مرشحات محددة وتحسين نتائج البحث وجعلها أكثر دقة وكفاءة. من خلال تحليل المعلومات المتعلقة ببياناتك، مثل بنيتها ومحتواها وسماتها، يمكن للتصفية الذكية تحديد المعايير ذات الصلة لتصفية بحثك.
تخيل أنك تبحث عن "أفلام كوميدية صدرت قبل عام 2000". ستستخدم التصفية الذكية البيانات التعريفية مثل النوع وتاريخ الإصدار وربما حتى الكلمات الرئيسية لإنشاء مرشح يتضمن فقط الأفلام المطابقة لتلك المعايير. بهذه الطريقة، ستحصل على قائمة بما تريده بالضبط، دون أي ضجيج غير ذي صلة.
دعنا نتعمق أكثر في كيفية عمل التصفية الذكية في القسم التالي.
التصفية الذكية هي عملية متعددة الخطوات تتضمن استخراج المعلومات من بياناتك وتحليلها وإنشاء عوامل تصفية محددة بناءً على احتياجاتك. دعونا نقسمها:
استخراج البيانات الوصفية: الخطوة الأولى هي جمع المعلومات ذات الصلة ببياناتك. يتضمن ذلك تفاصيل مثل:
إنشاء عوامل التصفية المسبقة: بمجرد حصولك على البيانات التعريفية، يمكنك البدء في إنشاء عوامل التصفية المسبقة. هذه شروط محددة يجب أن تفي بها البيانات حتى يتم تضمينها في نتائج البحث. على سبيل المثال، إذا كنت تبحث عن أفلام كوميدية تم إصدارها قبل عام 2000، فيمكنك إنشاء عوامل تصفية مسبقة لما يلي:
التكامل مع بحث المتجهات: الخطوة الأخيرة هي دمج هذه المرشحات المسبقة مع بحث المتجهات الخاص بك. وهذا يضمن أن البحث المتجهي يأخذ في الاعتبار فقط نقاط البيانات التي تطابق معاييرك المحددة مسبقًا.
باتباع هذه الخطوات، تعمل التصفية الذكية على تحسين دقة وكفاءة نتائج البحث بشكل كبير.
استخراج البيانات الوصفية: لغرض تبسيط الأمور، سنستخدم بيانات نموذجية ونحدد البيانات الوصفية يدويًا. راجع: get_docs_metadata في prepare_test_data.py .
إنشاء المرشح المسبق: سنقوم بإنشاء المرشحات المسبقة في خطوتين.
الخطوة 1: عامل التصفية القائم على البيانات الوصفية
تتضمن هذه الخطوة إنشاء عامل تصفية بناءً على بيانات التعريف. سنقوم بتمرير استعلام المستخدم والبيانات التعريفية إلى LLM وإنشاء مرشح البيانات التعريفية.
سوف نستخدم query_constructor الذي تمت تهيئته باستخدام DEFAULT_SCHEMA_PROMPT.
ملحوظة: قم بتحديث المطالبة وأمثلة اللقطات القليلة وفقًا لحالة الاستخدام الخاصة بك.
على سبيل المثال: إذا كانت البيانات الوصفية تحتوي على genre وتاريخ release_date ، وطلب المستخدم أفلام action التي تم إصدارها قبل عام 2020، فيمكننا استخدام LLM لإنشاء مرشح كما هو موضح أدناه:
{"$and": [{"genre": {"$in": ["anime"]}}, {"release_date": {"$lt": "2024-01-01"}}]}
الخطوة 2: التصفية على أساس الوقت
في هذه الخطوة، سنتعامل مع الحالات التي يطلب فيها المستخدم latest most recent earliest نوع من المعلومات. سيتعين علينا الاستعلام عن البيانات الفعلية لجلب هذه المعلومات. سوف نستخدم LLM Agent في هذه الخطوة للاستعلام عن مجموعة mongodb باستخدام أداة التنفيذ: QueryExecutorMongoDBTool نحن نقوم بإنشاء عامل التصفية المستند إلى الوقت في generator_time_based_filter. سنستخدم أيضًا المرشح المسبق الذي تم إنشاؤه في الخطوة الأولى في $match في مرحلة التجميع. على سبيل المثال: إذا كان المستخدم يريد أحدث فيلم، فسيتم تشغيل وكيل LLM أسفل استعلام التجميع باستخدام أداة المنفذ:
Invoking: `mongo_db_executor` with `{'pipeline': '[{"$match": {"$and": [{"genre": {"$in": ["anime"]}}, {"release_date": {"$lt": "2024-01-01"}}]}}, { "$sort": { "release_date": -1 } }, { "$limit": 1 }, { "$project": { "release_date": 1 } }]'}`
التكامل مع Vector Search: سيتم استخدام عامل التصفية المسبق الذي تم إنشاؤه مع مسترد MongoDBAtlasVectorSearch:
retriever = vectorstore.as_retriever(
search_kwargs={ ' pre_filter ' : pre_filter}
)إنشاء بيئة بايثون جديدة
python3 -m venv env
source env/bin/activateتثبيت المتطلبات
pip3 install -r requirements.txtقم بتعيين التكوينات في config.yaml
database_name: < your database name >
collection_name: < your collection name >
vector_index_name: default
embedding_model_dimensions: 1536
similarity: cosine
model: gpt-4o
embedding_model: text-embedding-ada-002ضبط متغيرات البيئة
export OPEN_AI_API_KEY = " "
export OPEN_API_BASE = " "
# headers are optional
export OPEN_API_DEFAULT_HEADERS= " "
export MONGO_URI= " "قم بتهيئة مجموعة mongodb باستخدام بيانات العينة. سيقوم هذا الأمر بفهرسة بعض نماذج البيانات وإنشاء فهرس بحث متجه في المجموعة أيضًا.
python3 rag/initialize_mongo_collection.pypython3 rag/main.py --queries < list of queries in json format > python3 rag/main.py --queries ' ["I want to watch an anime genre movie", "Recommend a thriller or action movie release after Feb, 2010", "Recommend an anime movie released before 2023 with the latest release date"] 'المرشحات المسبقة التي تم إنشاؤها:
استعلام الإدخال: "I want to watch an anime genre movie", "Recommend a thriller or action movie release after Feb, 2010"
الإخراج: 
استعلام الإدخال: "Recommend a thriller or action movie release after Feb, 2010"
الإخراج: 
استعلام الإدخال: "Recommend an anime movie released before 2023 with the latest release date"
الإخراج: 
توفر التصفية الذكية مجموعة من المزايا، مما يجعلها أداة قيمة لتعزيز تجارب البحث:
تحسين دقة البحث: من خلال استهداف البيانات التي تطابق استعلامك بدقة، تعمل التصفية الذكية على زيادة احتمالية العثور على النتائج ذات الصلة بشكل كبير. لا مزيد من الخوض في المعلومات غير ذات الصلة.
نتائج بحث أسرع: نظرًا لأن التصفية الذكية تعمل على تضييق نطاق البحث، فيمكن للنظام معالجة المعلومات بشكل أكثر كفاءة، مما يؤدي إلى نتائج أسرع.
تجربة مستخدم محسنة: عندما يجد المستخدمون ما يبحثون عنه بسرعة وسهولة، فإن ذلك يؤدي إلى رضا أعلى وتجربة شاملة أفضل.
تعدد الاستخدامات: يمكن تطبيق التصفية الذكية على مجالات مختلفة، بدءًا من عمليات البحث عن منتجات التجارة الإلكترونية وحتى توصيات المحتوى، مما يجعلها أداة متعددة الاستخدامات.
من خلال الاستفادة من البيانات التعريفية وإنشاء مرشحات مسبقة مستهدفة، تمكنك التصفية الذكية من تقديم نتائج بحث تلبي توقعات المستخدم حقًا.
تعتبر التصفية الذكية أداة قوية تعمل على تحويل التجارب من خلال سد الفجوة بين نية المستخدم والنتائج. ومن خلال تسخير قوة البيانات التعريفية والبحث الموجه، فإنه يوفر نتائج بحث أكثر دقة وملاءمة وكفاءة.
سواء كنت تقوم ببناء منصة للتجارة الإلكترونية، أو نظام توصية بالمحتوى، أو أي تطبيق يعتمد على البحث الفعال، فإن دمج التصفية الذكية يمكن أن يعزز رضا المستخدم بشكل كبير ويحقق نتائج أفضل.
من خلال فهم أساسيات التصفية الذكية، تصبح مجهزًا لاستكشاف إمكاناتها وتنفيذها في مشاريعك. فلماذا الانتظار؟ ابدأ في الاستفادة من قوة التصفية الذكية اليوم وأحدث ثورة في لعبة البحث الخاصة بك!
مستوحاة من مسترد الاستعلام الذاتي الخاص بـ LangChain.


