cassandra lucene index
2.1.20.0
مؤشر Stratio's Cassandra Lucene، المشتق من Stratio Cassandra، هو مكون إضافي لـ Apache Cassandra يعمل على توسيع وظائف الفهرس الخاصة به لتوفير بحث في الوقت الفعلي تقريبًا مثل ElasticSearch أو Solr، بما في ذلك إمكانات البحث عن النص الكامل والبحث المجاني متعدد المتغيرات والجغرافية المكانية والزمانية. يتم تحقيق ذلك من خلال تطبيق Apache Lucene القائم على فهارس Cassandra الثانوية، حيث تقوم كل عقدة من المجموعة بفهرسة بياناتها الخاصة. تعد فهارس Stratio's Cassandra واحدة من الوحدات الأساسية التي تعتمد عليها منصة Stratio's BigData.
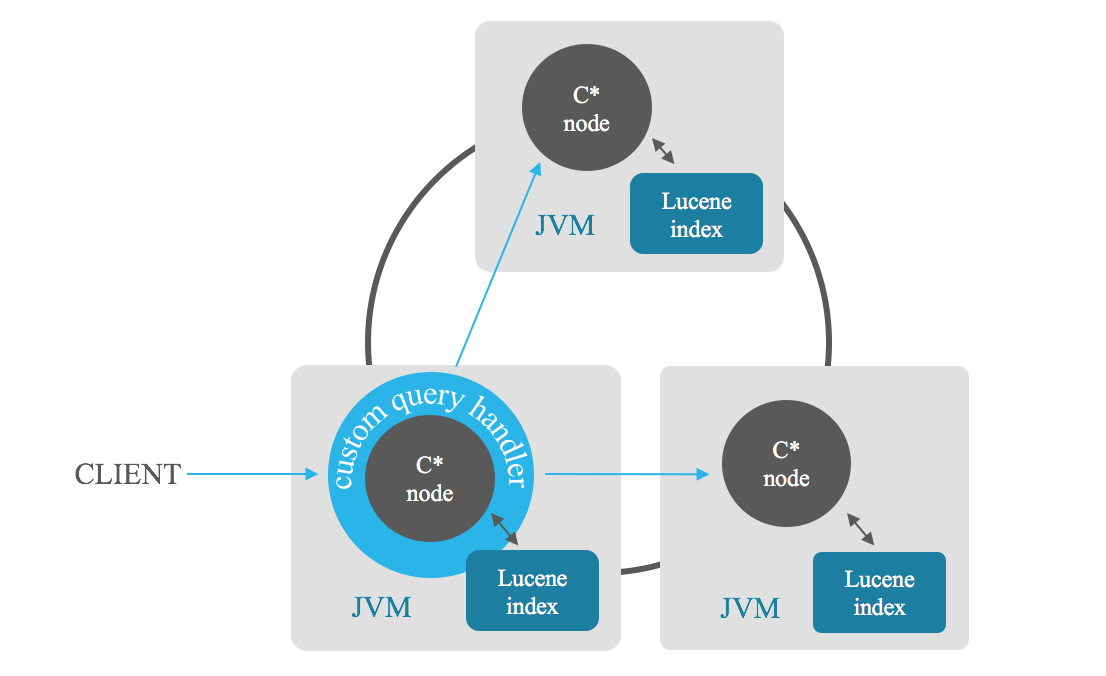
تسمح لك عمليات البحث ذات الصلة بالفهرس باسترداد عدد n من النتائج ذات الصلة التي تلبي البحث. ترسل العقدة المنسقة البحث إلى كل عقدة في المجموعة، وترجع كل عقدة أفضل نتائج لها، ثم يقوم المنسق بدمج هذه النتائج الجزئية ويمنحك أفضل النتائج، مع تجنب الفحص الكامل. يمكنك أيضًا إنشاء الفرز في مجموعة من الحقول.
يمكن فهرسة أي خلية في الجداول، بما في ذلك تلك الموجودة في المفتاح الأساسي وكذلك المجموعات. كما يتم دعم الصفوف الواسعة. يمكنك مسح نطاقات الرمز المميز/المفاتيح، وتطبيق عبارات وصفحة CQL3 إضافية على النتائج التي تمت تصفيتها.
تعد عمليات البحث المصفاة بالفهرسة مساعدة قوية عند تحليل البيانات المخزنة في Cassandra باستخدام أطر عمل MapReduce مثل Apache Hadoop، أو حتى Apache Spark. يمكن أن تؤدي إضافة مرشحات Lucene في مدخلات المهام إلى تقليل كمية البيانات المطلوب معالجتها بشكل كبير، مما يؤدي إلى تجنب الفحص الكامل.
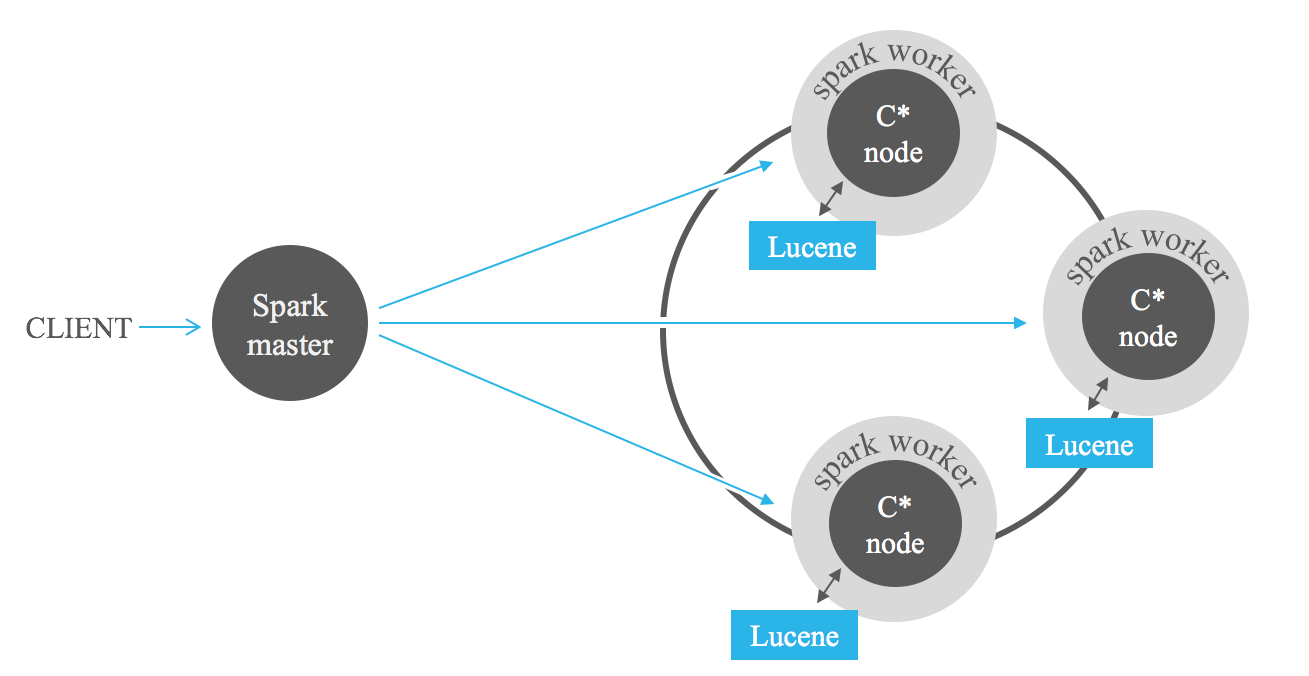
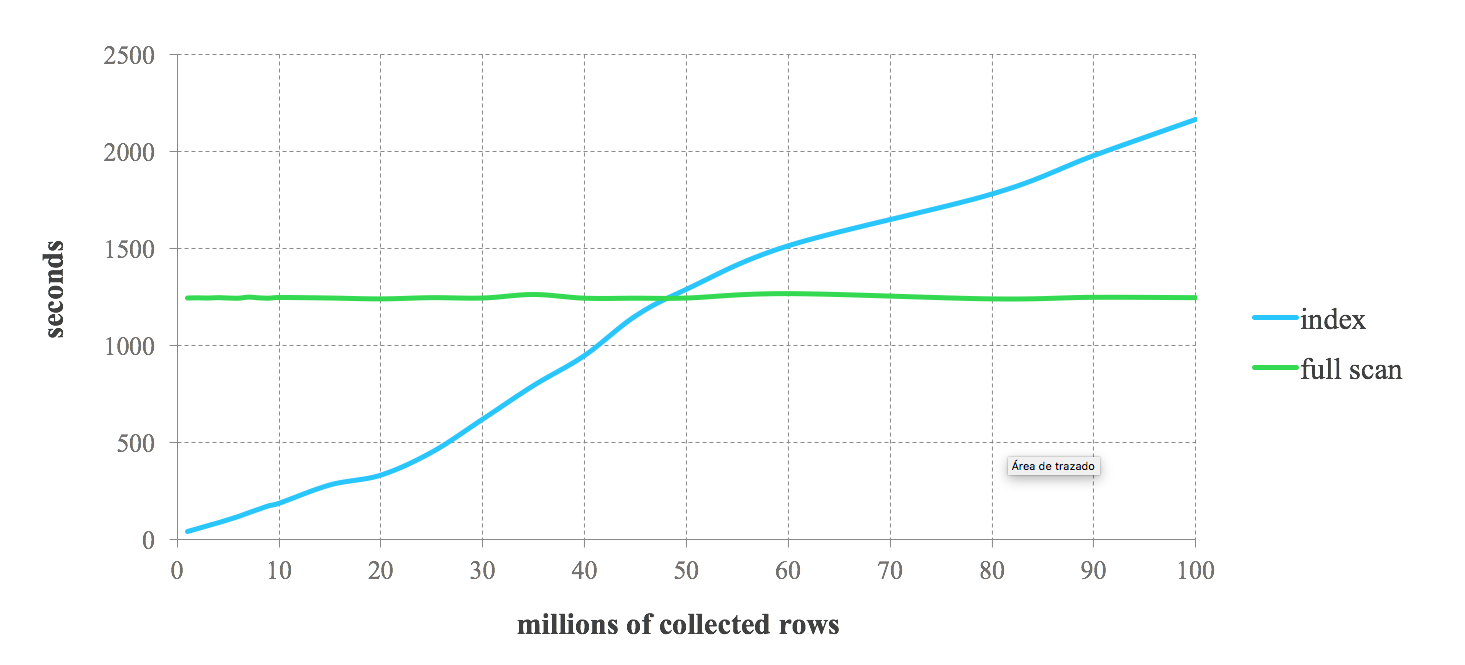
يمكن أن تعطيك النتيجة المعيارية التالية فكرة عن الأداء المتوقع عند دمج مؤشرات Lucene مع Spark. نقوم بإجراء استعلامات متتالية تطلب من 1% إلى 100% من البيانات المخزنة. يمكننا أن نرى أداءً عاليًا للفهرس للاستعلامات التي تطلب بيانات تمت تصفيتها بشدة. ومع ذلك، يتحلل الأداء في استعلامات أقل تقييداً. مع زيادة عدد السجلات التي يتم إرجاعها بواسطة الاستعلام، نصل إلى نقطة يصبح فيها الفهرس أبطأ من الفحص الكامل. لذلك، يعتمد قرار استخدام الفهارس في وظائف Spark الخاصة بك على انتقائية الاستعلام. تعتمد المفاضلة بين كلا النهجين على حالة الاستخدام المحددة. بشكل عام، يوصى بدمج فهارس Lucene مع Spark للمهام التي لا تسترد أكثر من 25% من البيانات المخزنة.
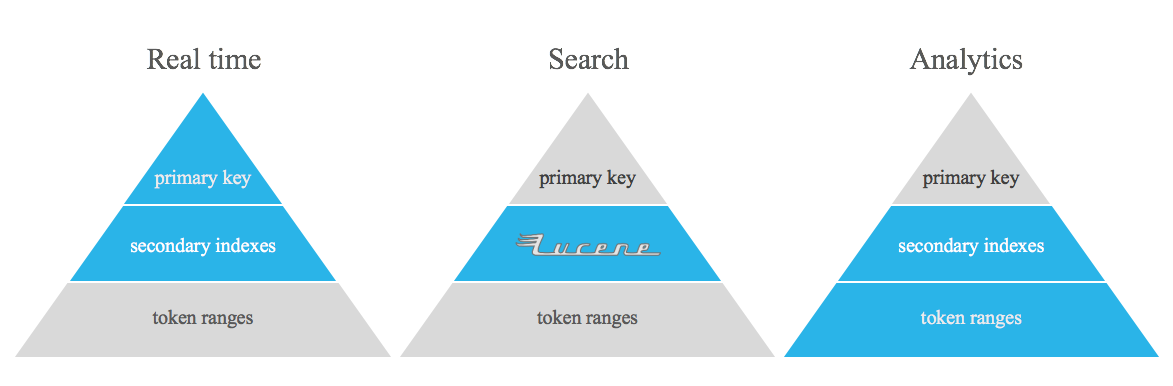
ليس المقصود من هذا المشروع أن يحل محل جداول Apache Cassandra غير الطبيعية، والفهارس المقلوبة، و/أو الفهارس الثانوية. إنها مجرد أداة لتنفيذ بعض أنواع الاستعلامات التي يصعب معالجتها باستخدام ميزات Apache Cassandra المبتكرة، مما يسد الفجوة بين الوقت الفعلي والتحليلات.
تتوفر معلومات أكثر تفصيلاً في وثائق مؤشر Stratio's Cassandra Lucene.
يوفر دمج تقنية بحث Lucene في Cassandra ما يلي:
يوفر مؤشر Stratio's Cassandra Lucene وتكامله مع تقنية بحث Lucene:
غير مدعوم بعد:
counterيتم توزيع مؤشر Stratio's Cassandra Lucene كمكون إضافي لـ Apache Cassandra. وبالتالي، كل ما عليك فعله هو إنشاء ملف JAR يحتوي على المكوّن الإضافي وإضافته إلى مسار فئة Cassandra:
git clone http://github.com/Stratio/cassandra-lucene-indexcd cassandra-lucene-indexgit checkout ABCXmvn clean packagecp plugin/target/cassandra-lucene-index-plugin-*.jar <CASSANDRA_HOME>/lib/تستهدف إصدارات فهرس Cassandra Lucene المحددة إصدارات Apache Cassandra المحددة. لذلك، يهدف cassandra-lucene-index ABCX إلى استخدامه مع Apache Cassandra ABC، على سبيل المثال cassandra-lucene-index:3.0.7.1 لـ cassandra:3.0.7. يرجى ملاحظة أن الإصدارات الجاهزة للإنتاج هي علامات إصدار (على سبيل المثال 3.0.6.3)، ولا تستخدم الفرع X أو الفروع الرئيسية في الإنتاج.
بدلاً من ذلك، يمكن أيضًا إجراء التصحيح باستخدام ملف تعريف Maven هذا، مع تحديد مسار تثبيت Cassandra الخاص بك، وتحذف هذه المهمة أيضًا إصدارات JAR السابقة للمكون الإضافي في دليل CASSANDRA_HOME/lib/:
mvn clean package -Ppatch -Dcassandra_home= < CASSANDRA_HOME >إذا لم يكن لديك إصدار مثبت من Cassandra، فهناك أيضًا ملف تعريف بديل للسماح لـ Maven بتنزيل وتصحيح الإصدار المناسب من Apache Cassandra:
mvn clean package -Pdownload_and_patch -Dcassandra_home= < CASSANDRA_HOME >يمكنك الآن تشغيل Cassandra وإجراء بعض الاختبارات باستخدام لغة استعلام Cassandra:
< CASSANDRA_HOME > /bin/cassandra -f
< CASSANDRA_HOME > /bin/cqlsh سيتم تخزين ملفات فهرس Lucene في نفس الدلائل حيث سيتم تخزين ملفات Cassandra. دليل البيانات الافتراضي هو /var/lib/cassandra/data ، ويتم وضع كل فهرس بجوار SSTables لعائلة الأعمدة المفهرسة الخاصة به.
تذكر أنه إذا كنت تستخدم بحث الشكل الجغرافي، فستحتاج إلى تضمين جرة JTS.
لمزيد من التفاصيل حول Apache Cassandra، يرجى الاطلاع على الوثائق الخاصة به.
سنقوم بإنشاء الجدول التالي لتخزين التغريدات:
CREATE KEYSPACE demo
WITH REPLICATION = { ' class ' : ' SimpleStrategy ' , ' replication_factor ' : 1 };
USE demo;
CREATE TABLE tweets (
id INT PRIMARY KEY ,
user TEXT ,
body TEXT ,
time TIMESTAMP ,
latitude FLOAT,
longitude FLOAT
);يمكنك الآن إنشاء فهرس Lucene مخصص عليه باستخدام العبارة التالية:
CREATE CUSTOM INDEX tweets_index ON tweets ()
USING ' com.stratio.cassandra.lucene.Index '
WITH OPTIONS = {
' refresh_seconds ' : ' 1 ' ,
' schema ' : ' {
fields: {
id: {type: "integer"},
user: {type: "string"},
body: {type: "text", analyzer: "english"},
time: {type: "date", pattern: "yyyy/MM/dd"},
place: {type: "geo_point", latitude: "latitude", longitude: "longitude"}
}
} '
}; سيؤدي هذا إلى فهرسة جميع الأعمدة الموجودة في الجدول بالأنواع المحددة، وسيتم تحديثها مرة واحدة في الثانية. وبدلاً من ذلك، يمكنك تحديث جميع أجزاء الفهرس بشكل صريح من خلال بحث فارغ متسق ALL :
CONSISTENCY ALL
SELECT * FROM tweets WHERE expr(tweets_index, ' {refresh:true} ' );
CONSISTENCY QUORUMالآن، للبحث عن التغريدات ضمن نطاق زمني معين:
SELECT * FROM tweets WHERE expr(tweets_index, ' {
filter: {type: "range", field: "time", lower: "2014/04/25", upper: "2014/05/01"}
} ' );يمكن إجراء نفس البحث عن طريق فرض تحديث صريح لأجزاء الفهرس المعنية:
SELECT * FROM tweets WHERE expr(tweets_index, ' {
filter: {type: "range", field: "time", lower: "2014/04/25", upper: "2014/05/01"},
refresh: true
} ' ) limit 100 ;الآن، للبحث في أفضل 100 تغريدة ذات صلة حيث يحتوي الحقل الأساسي على عبارة "البيانات الضخمة تمنح المؤسسات" ضمن النطاق الزمني المذكور أعلاه:
SELECT * FROM tweets WHERE expr(tweets_index, ' {
filter: {type: "range", field: "time", lower: "2014/04/25", upper: "2014/05/01"},
query: {type: "phrase", field: "body", value: "big data gives organizations", slop: 1}
} ' ) LIMIT 100 ;لتحسين البحث للحصول على التغريدات المكتوبة فقط من قبل المستخدمين الذين تبدأ أسماؤهم بالحرف "a":
SELECT * FROM tweets WHERE expr(tweets_index, ' {
filter: [
{type: "range", field: "time", lower: "2014/04/25", upper: "2014/05/01"},
{type: "prefix", field: "user", value: "a"}
],
query: {type: "phrase", field: "body", value: "big data gives organizations", slop: 1}
} ' ) LIMIT 100 ;للحصول على أحدث 100 نتيجة تمت تصفيتها، يمكنك استخدام خيار الفرز :
SELECT * FROM tweets WHERE expr(tweets_index, ' {
filter: [
{type: "range", field: "time", lower: "2014/04/25", upper: "2014/05/01"},
{type: "prefix", field: "user", value: "a"}
],
query: {type: "phrase", field: "body", value: "big data gives organizations", slop: 1},
sort: {field: "time", reverse: true}
} ' ) limit 100 ;يمكن أن يقتصر البحث السابق على التغريدات التي تم إنشاؤها بالقرب من موقع جغرافي:
SELECT * FROM tweets WHERE expr(tweets_index, ' {
filter: [
{type: "range", field: "time", lower: "2014/04/25", upper: "2014/05/01"},
{type: "prefix", field: "user", value: "a"},
{type: "geo_distance", field: "place", latitude: 40.3930, longitude: -3.7328, max_distance: "1km"}
],
query: {type: "phrase", field: "body", value: "big data gives organizations", slop: 1},
sort: {field: "time", reverse: true}
} ' ) limit 100 ;ومن الممكن أيضًا فرز النتائج حسب المسافة إلى الموقع الجغرافي:
SELECT * FROM tweets WHERE expr(tweets_index, ' {
filter: [
{type: "range", field: "time", lower: "2014/04/25", upper: "2014/05/01"},
{type: "prefix", field: "user", value: "a"},
{type: "geo_distance", field: "place", latitude: 40.3930, longitude: -3.7328, max_distance: "1km"}
],
query: {type: "phrase", field: "body", value: "big data gives organizations", slop: 1},
sort: [
{field: "time", reverse: true},
{field: "place", type: "geo_distance", latitude: 40.3930, longitude: -3.7328}
]
} ' ) limit 100 ;أخيرًا وليس آخرًا، يمكنك توجيه أي بحث إلى نطاق أو قسم معين من الرموز المميزة، بحيث يتم الوصول إلى مجموعة فرعية فقط من عقد المجموعة، مما يوفر الموارد الثمينة:
SELECT * FROM tweets WHERE expr(tweets_index, ' {
filter: [
{type: "range", field: "time", lower: "2014/04/25", upper: "2014/05/01"},
{type: "prefix", field: "user", value: "a"},
{type: "geo_distance", field: "place", latitude: 40.3930, longitude: -3.7328, max_distance: "1km"}
],
query: {type: "phrase", field: "body", value: "big data gives organizations", slop: 1},
sort: [
{field: "time", reverse: true},
{field: "place", type: "geo_distance", latitude: 40.3930, longitude: -3.7328}
]
} ' ) AND TOKEN(id) >= TOKEN( 0 ) AND TOKEN(id) < TOKEN( 10000000 ) limit 100 ;هذا الأخير هو الأساس لدعم Hadoop وSpark وأطر عمل MapReduce الأخرى.
يرجى الرجوع إلى وثائق مؤشر Cassandra Lucene الشاملة من Stratio.


