أصبح Stable Diffusion ممكنًا بفضل التعاون مع Stability AI وRunway ويعتمد على عملنا السابق:
تركيب صور عالية الدقة باستخدام نماذج الانتشار الكامنة
روبن رومباخ*، أندرياس بلاتمان*، دومينيك لورينز، باتريك إيسر، بيورن أومر
CVPR '22 عن طريق الفم | جيثب | أرخايف | صفحة المشروع
 يعد Stable Diffusion نموذجًا كامنًا لنشر النص إلى الصورة. بفضل التبرع السخي للحوسبة من Stability AI والدعم من LAION، تمكنا من تدريب نموذج الانتشار الكامن على صور مقاس 512 × 512 من مجموعة فرعية من قاعدة بيانات LAION-5B. على غرار Google Imagen، يستخدم هذا النموذج برنامج تشفير النص CLIP ViT-L/14 المجمد لتكييف النموذج مع المطالبات النصية. بفضل 860M UNet وبرنامج تشفير النص 123M، يعد الطراز خفيف الوزن نسبيًا ويعمل على وحدة معالجة الرسومات (GPU) مع ذاكرة VRAM سعة 10 جيجابايت على الأقل. انظر هذا القسم أدناه وبطاقة النموذج.
يعد Stable Diffusion نموذجًا كامنًا لنشر النص إلى الصورة. بفضل التبرع السخي للحوسبة من Stability AI والدعم من LAION، تمكنا من تدريب نموذج الانتشار الكامن على صور مقاس 512 × 512 من مجموعة فرعية من قاعدة بيانات LAION-5B. على غرار Google Imagen، يستخدم هذا النموذج برنامج تشفير النص CLIP ViT-L/14 المجمد لتكييف النموذج مع المطالبات النصية. بفضل 860M UNet وبرنامج تشفير النص 123M، يعد الطراز خفيف الوزن نسبيًا ويعمل على وحدة معالجة الرسومات (GPU) مع ذاكرة VRAM سعة 10 جيجابايت على الأقل. انظر هذا القسم أدناه وبطاقة النموذج.
يمكن إنشاء بيئة كوندا مناسبة تسمى ldm وتنشيطها باستخدام:
conda env create -f environment.yaml
conda activate ldm
يمكنك أيضًا تحديث بيئة النشر الكامنة الموجودة عن طريق التشغيل
conda install pytorch torchvision -c pytorch
pip install transformers==4.19.2 diffusers invisible-watermark
pip install -e .
يشير Stable Diffusion v1 إلى تكوين محدد لبنية النموذج الذي يستخدم أداة التشفير التلقائي ذات عامل الاختزال 8 مع جهاز تشفير النص 860M UNet وCLIP ViT-L/14 لنموذج النشر. تم تدريب النموذج مسبقًا على صورة مقاس 256 × 256 ثم تحسينه على صور مقاس 512 × 512.
ملحوظة: Stable Diffusion v1 هو نموذج عام لنشر النص إلى الصورة، وبالتالي يعكس التحيزات والمفاهيم (الخاطئة) الموجودة في بيانات التدريب الخاصة به. يمكن العثور على تفاصيل حول إجراءات التدريب والبيانات، بالإضافة إلى الاستخدام المقصود للنموذج في بطاقة النموذج المقابلة.
تتوفر الأوزان عبر مؤسسة CompVis في Hugging Face بموجب ترخيص يحتوي على قيود محددة قائمة على الاستخدام لمنع سوء الاستخدام والضرر كما هو مذكور في بطاقة النموذج، ولكن بخلاف ذلك يظل مسموحًا به. في حين أن الاستخدام التجاري مسموح به بموجب شروط الترخيص، إلا أننا لا نوصي باستخدام الأوزان المقدمة للخدمات أو المنتجات دون آليات واعتبارات أمان إضافية ، نظرًا لوجود قيود وتحيزات معروفة للأوزان، والأبحاث حول النشر الآمن والأخلاقي للأوزان تعتبر نماذج تحويل النص إلى صورة العامة جهدًا مستمرًا. الأوزان عبارة عن قطع أثرية بحثية ويجب معاملتها على هذا النحو.
ترخيص CreativeML OpenRAIL M هو ترخيص Open RAIL M، مقتبس من العمل الذي تقوم به BigScience ومبادرة RAIL بشكل مشترك في مجال الترخيص المسؤول للذكاء الاصطناعي. راجع أيضًا المقالة حول ترخيص BLOOM Open RAIL الذي يعتمد عليه ترخيصنا.
نحن نقدم حاليا نقاط التفتيش التالية:
sd-v1-1.ckpt : 237 ألف خطوة بدقة 256x256 على laion2B-en. 194 ألف خطوة بدقة 512x512 بدقة عالية (170 مليون مثال من LAION-5B بدقة >= 1024x1024 ).sd-v1-2.ckpt : مستأنف من sd-v1-1.ckpt . 515 ألف خطوة بدقة 512x512 على laion-aesthetics v2 5+ (مجموعة فرعية من laion2B-en مع درجة جمالية تقديرية > 5.0 ، بالإضافة إلى تصفيتها إلى صور ذات حجم أصلي >= 512x512 ، واحتمالية تقديرية للعلامة المائية < 0.5 . تقدير العلامة المائية من البيانات التعريفية LAION-5B، يتم تقدير النتيجة الجمالية باستخدام LAION-Aesthetics Predictor V2).sd-v1-3.ckpt : مستأنف من sd-v1-2.ckpt . 195 ألف خطوة بدقة 512x512 على "laion-aesthetics v2 5+" وإسقاط تكييف النص بنسبة 10% لتحسين أخذ عينات التوجيه الخالية من المصنف.sd-v1-4.ckpt : مستأنف من sd-v1-2.ckpt . 225 ألف خطوة بدقة 512x512 على "laion-aesthetics v2 5+" وإسقاط تكييف النص بنسبة 10% لتحسين أخذ عينات التوجيه الخالية من المصنف. تُظهر التقييمات بمقاييس توجيه مختلفة خالية من المصنف (1.5، 2.0، 3.0، 4.0، 5.0، 6.0، 7.0، 8.0) و50 خطوة لأخذ عينات PLMS التحسينات النسبية لنقاط التفتيش: 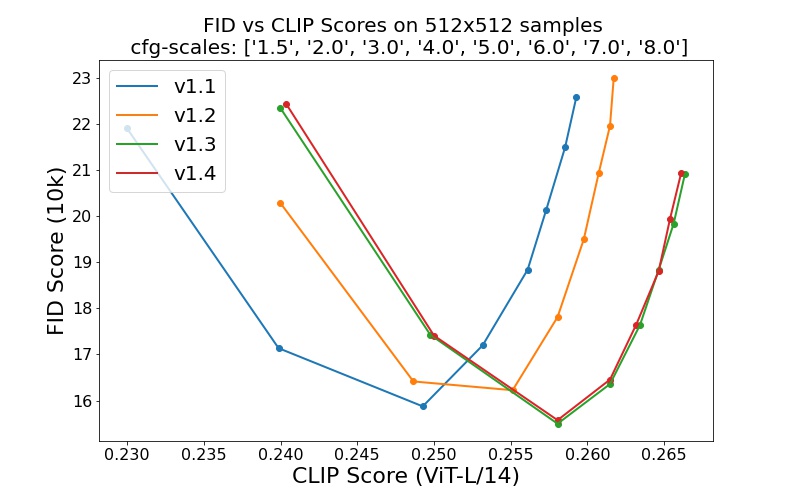


يعد Stable Diffusion نموذج نشر كامن مشروط بتضمين النص (غير المجمع) لجهاز تشفير النص CLIP ViT-L/14. نحن نقدم نصًا مرجعيًا لأخذ العينات، ولكن يوجد أيضًا تكامل للناشرين، والذي نتوقع أن يشهد تنمية مجتمعية أكثر نشاطًا.
نحن نقدم نصًا مرجعيًا لأخذ العينات، والذي يتضمن
بعد الحصول على الأوزان stable-diffusion-v1-*-original اربطها
mkdir -p models/ldm/stable-diffusion-v1/
ln -s <path/to/model.ckpt> models/ldm/stable-diffusion-v1/model.ckpt
وعينة مع
python scripts/txt2img.py --prompt "a photograph of an astronaut riding a horse" --plms
افتراضيًا، يستخدم هذا مقياس توجيه --scale 7.5 ، وهو تطبيق Katherine Crowson لأخذ عينات PLMS، ويعرض صورًا بحجم 512x512 (التي تم التدريب عليها) في 50 خطوة. جميع الوسائط المدعومة مدرجة أدناه (اكتب python scripts/txt2img.py --help ).
usage: txt2img.py [-h] [--prompt [PROMPT]] [--outdir [OUTDIR]] [--skip_grid] [--skip_save] [--ddim_steps DDIM_STEPS] [--plms] [--laion400m] [--fixed_code] [--ddim_eta DDIM_ETA]
[--n_iter N_ITER] [--H H] [--W W] [--C C] [--f F] [--n_samples N_SAMPLES] [--n_rows N_ROWS] [--scale SCALE] [--from-file FROM_FILE] [--config CONFIG] [--ckpt CKPT]
[--seed SEED] [--precision {full,autocast}]
optional arguments:
-h, --help show this help message and exit
--prompt [PROMPT] the prompt to render
--outdir [OUTDIR] dir to write results to
--skip_grid do not save a grid, only individual samples. Helpful when evaluating lots of samples
--skip_save do not save individual samples. For speed measurements.
--ddim_steps DDIM_STEPS
number of ddim sampling steps
--plms use plms sampling
--laion400m uses the LAION400M model
--fixed_code if enabled, uses the same starting code across samples
--ddim_eta DDIM_ETA ddim eta (eta=0.0 corresponds to deterministic sampling
--n_iter N_ITER sample this often
--H H image height, in pixel space
--W W image width, in pixel space
--C C latent channels
--f F downsampling factor
--n_samples N_SAMPLES
how many samples to produce for each given prompt. A.k.a. batch size
--n_rows N_ROWS rows in the grid (default: n_samples)
--scale SCALE unconditional guidance scale: eps = eps(x, empty) + scale * (eps(x, cond) - eps(x, empty))
--from-file FROM_FILE
if specified, load prompts from this file
--config CONFIG path to config which constructs model
--ckpt CKPT path to checkpoint of model
--seed SEED the seed (for reproducible sampling)
--precision {full,autocast}
evaluate at this precision
ملاحظة: تم تصميم تكوين الاستدلال لجميع إصدارات v1 ليتم استخدامه مع نقاط فحص EMA فقط. لهذا السبب use_ema=False تم تعيينه في التكوين، وإلا سيحاول الكود التبديل من أوزان غير EMA إلى أوزان EMA. إذا كنت ترغب في فحص تأثير EMA مقابل عدم وجود EMA، فإننا نقدم نقاط فحص "كاملة" تحتوي على كلا النوعين من الأوزان. بالنسبة لهذه، سيتم تحميل use_ema=False واستخدام الأوزان غير EMA.
هناك طريقة بسيطة لتنزيل Stable Diffusion وأخذ عينات منه وهي استخدام مكتبة الناشرين:
# make sure you're logged in with `huggingface-cli login`
from torch import autocast
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline . from_pretrained (
"CompVis/stable-diffusion-v1-4" ,
use_auth_token = True
). to ( "cuda" )
prompt = "a photo of an astronaut riding a horse on mars"
with autocast ( "cuda" ):
image = pipe ( prompt )[ "sample" ][ 0 ]
image . save ( "astronaut_rides_horse.png" )باستخدام آلية تقليل الضوضاء للانتشار كما اقترحتها SDEdit لأول مرة، يمكن استخدام النموذج لمهام مختلفة مثل ترجمة صورة إلى صورة موجهة بالنص ورفع المستوى. على غرار البرنامج النصي لأخذ العينات txt2img، فإننا نقدم برنامجًا نصيًا لإجراء تعديل الصورة باستخدام Stable Diffusion.
يصف ما يلي مثالاً حيث يتم تحويل رسم تقريبي تم إجراؤه في Pinta إلى عمل فني مفصل.
python scripts/img2img.py --prompt "A fantasy landscape, trending on artstation" --init-img <path-to-img.jpg> --strength 0.8
هنا، القوة هي قيمة تتراوح بين 0.0 و1.0، والتي تتحكم في مقدار الضوضاء التي تتم إضافتها إلى الصورة المدخلة. تسمح القيم التي تقترب من 1.0 بالكثير من الاختلافات ولكنها ستنتج أيضًا صورًا غير متسقة لغويًا مع الإدخال. انظر المثال التالي.
مدخل

النواتج


يمكن أيضًا استخدام هذا الإجراء، على سبيل المثال، لترقية العينات من النموذج الأساسي.
تعتمد قاعدة التعليمات البرمجية الخاصة بنا لنماذج الانتشار بشكل كبير على قاعدة تعليمات OpenAI's ADM وhttps://github.com/lucidrains/denoising-diffusion-pytorch. شكرا للمصادر المفتوحة!
يتم تنفيذ تشفير المحولات من محولات x بواسطة lucidrains.
@misc{rombach2021highresolution,
title={High-Resolution Image Synthesis with Latent Diffusion Models},
author={Robin Rombach and Andreas Blattmann and Dominik Lorenz and Patrick Esser and Björn Ommer},
year={2021},
eprint={2112.10752},
archivePrefix={arXiv},
primaryClass={cs.CV}
}


