offensive ai compilation
1.0.0
قائمة منسقة من الموارد المفيدة التي تغطي الذكاء الاصطناعي الهجومي.
استغلال نقاط الضعف في نماذج الذكاء الاصطناعي.
يعد التعلم الآلي التنافسي مسؤولاً عن تقييم نقاط الضعف وتوفير التدابير المضادة.
يتم تنظيمها في أربعة أنواع من الهجمات: الاستخراج والانعكاس والتسميم والتهرب.
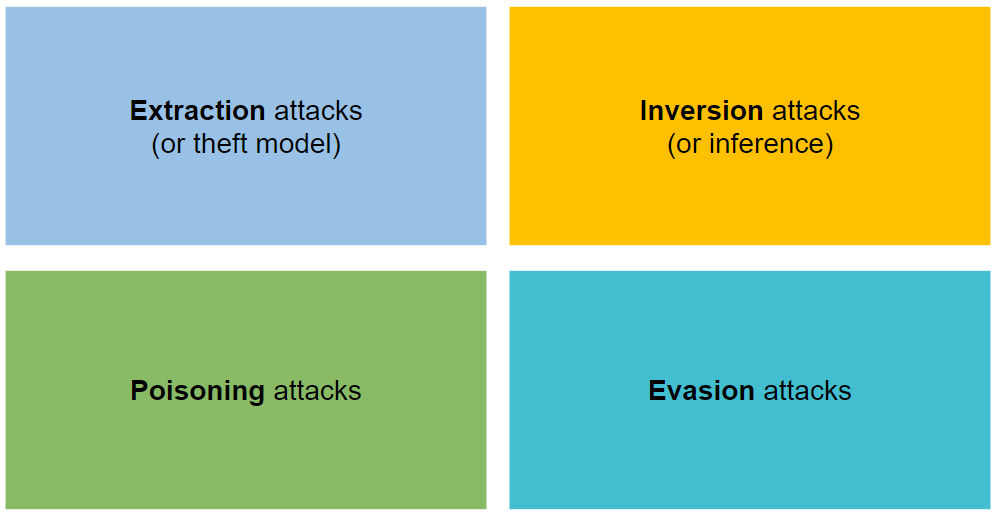
يحاول سرقة المعلمات والمعلمات الفائقة للنموذج عن طريق تقديم طلبات تزيد من استخلاص المعلومات.
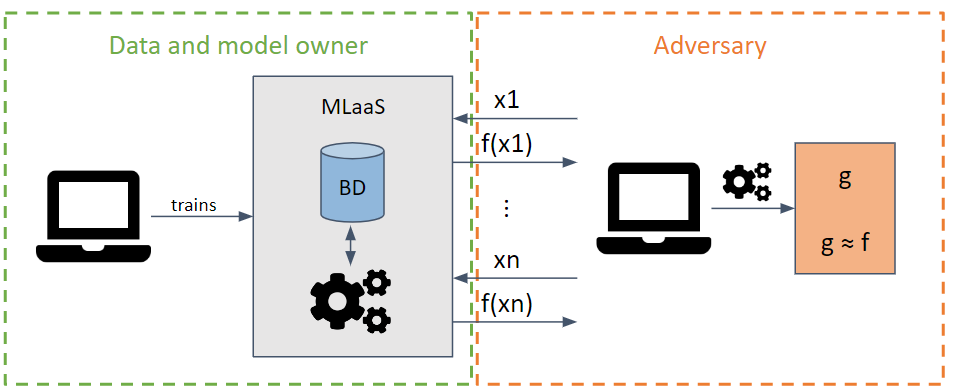
اعتمادًا على معرفة نموذج الخصم، يمكن تنفيذ هجمات الصندوق الأبيض والصندوق الأسود.
في أبسط حالة الصندوق الأبيض (عندما يكون لدى الخصم معرفة كاملة بالنموذج، على سبيل المثال، دالة سينية)، يمكن للمرء إنشاء نظام من المعادلات الخطية التي يمكن حلها بسهولة.
في الحالة العامة، حيث لا توجد معرفة كافية بالنموذج، يتم استخدام النموذج البديل. يتم تدريب هذا النموذج بناءً على الطلبات المقدمة إلى النموذج الأصلي لتقليد نفس وظيفة النموذج الأصلي.
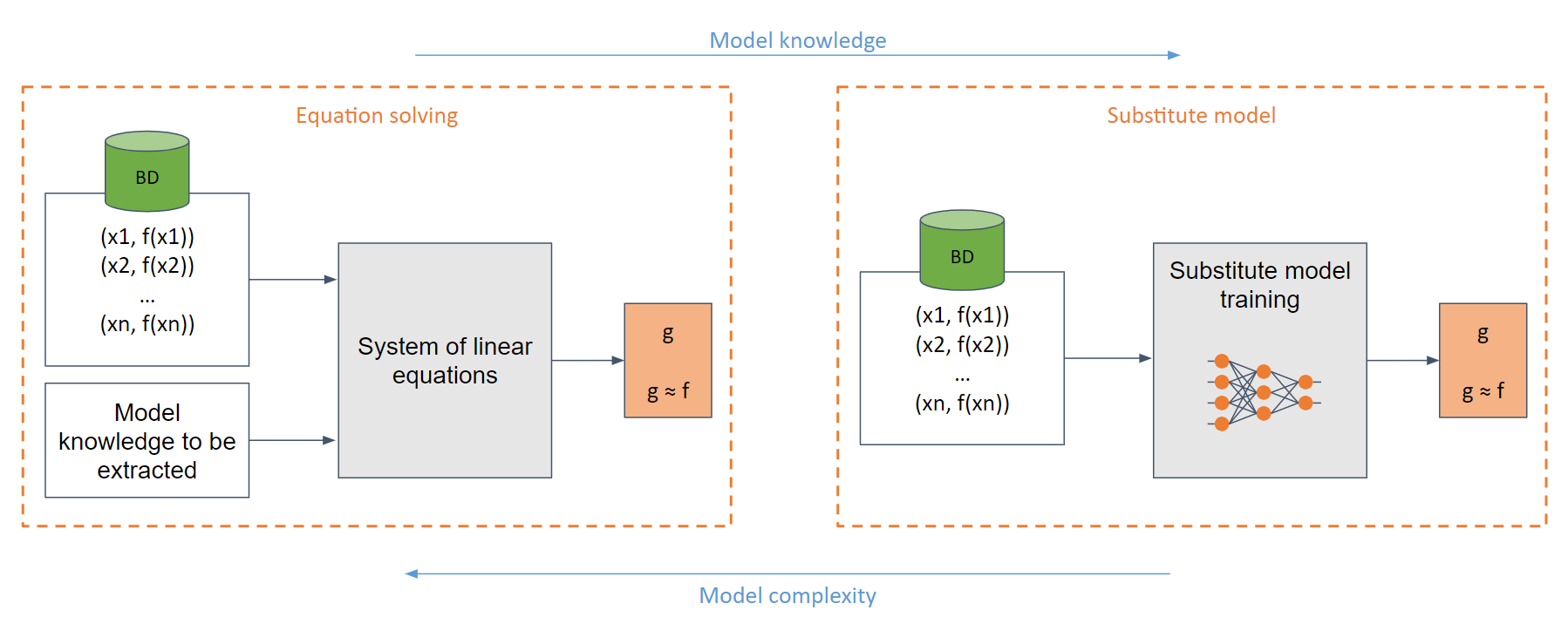
إن تدريب نموذج بديل يعادل (في كثير من الحالات) تدريب نموذج من الصفر.
مكثفة حسابيا للغاية.
لدى الخصم قيود على عدد الطلبات قبل اكتشافها.
تقريب قيم الإخراج.
استخدام الخصوصية التفاضلية.
استخدام الفرق.
استخدام دفاعات محددة
وهي تهدف إلى عكس تدفق المعلومات لنموذج التعلم الآلي.
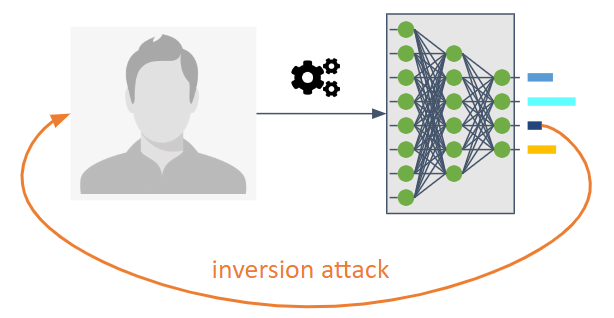
فهي تمكن الخصم من معرفة النموذج الذي لم يكن المقصود صراحة مشاركته.
أنها تسمح لنا بمعرفة بيانات أو معلومات التدريب كخصائص إحصائية للنموذج.
ثلاثة أنواع ممكنة:
هجوم استدلال العضوية (MIA) : يحاول الخصم تحديد ما إذا كانت العينة قد تم استخدامها كجزء من التدريب.
هجوم استنتاج الخاصية (PIA) : يهدف الخصم إلى استخراج الخصائص الإحصائية التي لم يتم تشفيرها بشكل صريح كميزات أثناء مرحلة التدريب.
إعادة البناء : يحاول الخصم إعادة بناء عينة واحدة أو أكثر من مجموعة التدريب و/أو التسميات المقابلة لها. ويسمى أيضا الانقلاب.
استخدام التشفير المتقدم. تشمل الإجراءات المضادة الخصوصية التفاضلية والتشفير المتماثل والحساب الآمن متعدد الأطراف.
استخدام تقنيات التنظيم مثل التسرب بسبب العلاقة بين الإفراط في التدريب والخصوصية.
تم اقتراح ضغط النموذج كدفاع ضد هجمات إعادة الإعمار.
إنهم يهدفون إلى إفساد مجموعة التدريب عن طريق التسبب في تقليل دقتها في نموذج التعلم الآلي.
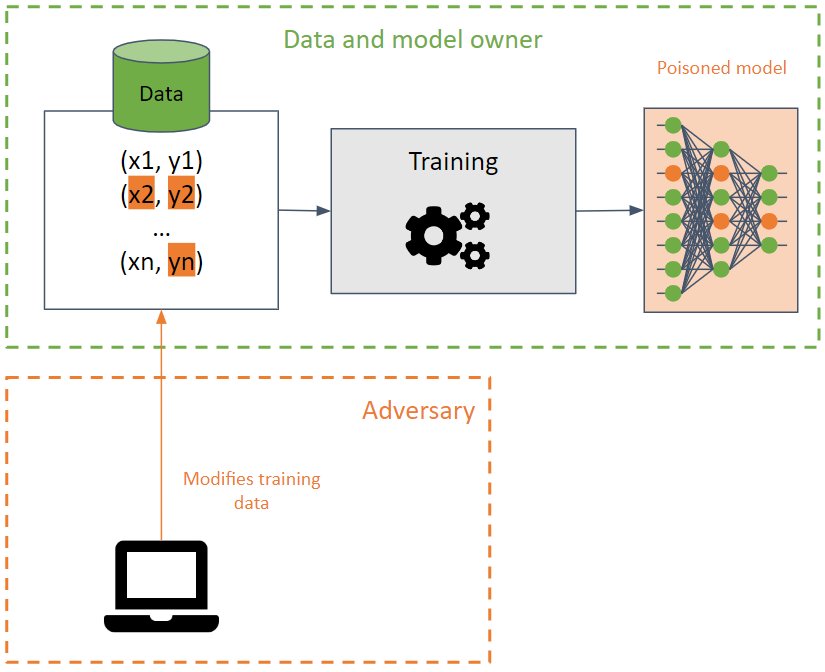
من الصعب اكتشاف هذا الهجوم عند تنفيذه على بيانات التدريب حيث يمكن أن ينتشر الهجوم بين نماذج مختلفة باستخدام نفس بيانات التدريب.
يسعى الخصم إلى تدمير توفر النموذج عن طريق تعديل حدود القرار، ونتيجة لذلك، إنتاج تنبؤات غير صحيحة أو إنشاء باب خلفي في النموذج. وفي الأخير، يتصرف النموذج بشكل صحيح (يعرض التنبؤات المطلوبة) في معظم الحالات، باستثناء بعض المدخلات التي أنشأها الخصم خصيصًا والتي تؤدي إلى نتائج غير مرغوب فيها. يمكن للخصم التلاعب بنتائج التنبؤات وشن هجمات مستقبلية.
تُعد شبكات BadNets أبسط أنواع الأبواب الخلفية في نموذج التعلم الآلي. علاوة على ذلك، يمكن الحفاظ على شبكات BadNets في نموذج، حتى لو تم إعادة تدريبها مرة أخرى للقيام بمهمة مختلفة عن النموذج الأصلي (نقل التعلم).
من المهم ملاحظة أن النماذج العامة المدربة مسبقًا قد تحتوي على أبواب خلفية .
الكشف عن البيانات المسمومة، إلى جانب استخدام عملية تعقيم البيانات.
أساليب التدريب القوية.
دفاعات محددة.
يضيف الخصم اضطرابًا صغيرًا (على شكل ضوضاء) إلى مدخلات نموذج التعلم الآلي لجعله يصنف بشكل غير صحيح (الخصم على سبيل المثال).
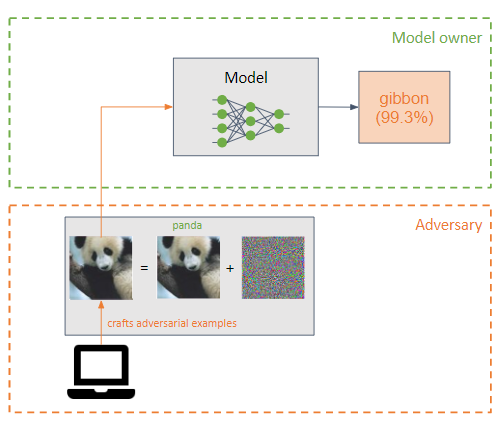
وهي تشبه هجمات التسمم، لكن الاختلاف الرئيسي بينها هو أن هجمات التهرب تحاول استغلال نقاط الضعف في النموذج في مرحلة الاستدلال.
هدف الخصم هو أن تكون الأمثلة العدائية غير محسوسة للإنسان.
يمكن تنفيذ نوعين من الهجوم اعتمادًا على النتيجة التي يرغب فيها الخصم:
المستهدف : يهدف الخصم إلى الحصول على تنبؤ من اختياره.
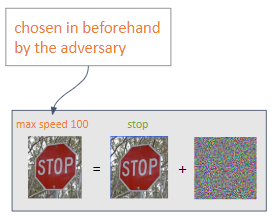
غير مستهدف : ينوي الخصم تحقيق تصنيف خاطئ.

الهجمات الأكثر شيوعًا هي هجمات الصندوق الأبيض :
تدريب الخصومة، والذي يتكون من صياغة أمثلة الخصومة أثناء التدريب للسماح للنموذج بتعلم ميزات الأمثلة الخصومة، مما يجعل النموذج أكثر قوة لهذا النوع من الهجوم.
التحولات على المدخلات.
اخفاء التدرج / التنظيم. ليست فعالة جدا.
دفاعات ضعيفة .
دفاعات الحقن الفوري: كل دفاع عملي ومقترح ضد الحقن الفوري.
مقياس Lakera PINT: يوفر معيار اختبار الحقن الفوري (PINT) طريقة محايدة لتقييم أداء نظام الكشف عن الحقن الفوري، مثل Lakera Guard، دون الاعتماد على مجموعات البيانات العامة المعروفة التي يمكن أن تستخدمها هذه الأدوات لتحسين أداء التقييم.
استدلال الشيطان: طريقة لتقييم نموذج Phi-3 Instruct بشكل عدائي من خلال مراقبة توزيع الانتباه عبر رؤوسه عند تعرضه لمدخلات محددة. ويدفع هذا النهج النموذج إلى تبني "عقلية الشيطان"، مما يمكنه من توليد مخرجات ذات طبيعة عنيفة.
| اسم | يكتب | الخوارزميات المدعومة | أنواع الهجوم المدعومة | الهجوم/الدفاع | الأطر المدعومة | شعبية |
|---|---|---|---|---|---|---|
| كليفرهانس | صورة | التعلم العميق | التهرب | هجوم | تنسورفلو، كيراس، جاكس | |
| صندوق الحمقى | صورة | التعلم العميق | التهرب | هجوم | تنسورفلو، بايتورتش، جاكس | |
| فن | أي نوع (صورة، بيانات جدولية، صوت، ...) | التعلم العميق، SVM، LR، إلخ. | أي (الاستخراج، الاستدلال، التسمم، التهرب) | كلاهما | Tensorflow، Keras، Pytorch، Scikit Learn | |
| هجوم النص | نص | التعلم العميق | التهرب | هجوم | كيراس، معانقة الوجه | |
| معلن | صورة | التعلم العميق | التهرب | كلاهما | --- | |
| AdvBox | صورة | التعلم العميق | التهرب | كلاهما | بايتورتش، تنسورفلو، مكسنيت | |
| عميق | صورة، رسم بياني | التعلم العميق | التهرب | كلاهما | باي تورش | |
| مكافحة | أي | أي | التهرب | هجوم | --- | |
| أمثلة الصوت الخصومة | صوتي | كلام عميق | التهرب | هجوم | --- |
Adversarial Robustness Toolbox، والمختصرة بـ ART، هي مكتبة مفتوحة المصدر للتعلم الآلي العدائي لاختبار قوة نماذج التعلم الآلي.

تم تطويره بلغة بايثون وينفذ هجمات ودفاعات الاستخراج والعكس والتسميم والتهرب.
يدعم ART أطر العمل الأكثر شيوعًا: Tensorflow وKeras وPyTorch وMxNet وScikitLearn وغيرها الكثير.
ولا يقتصر الأمر على استخدام النماذج التي تستخدم الصور كمدخلات، بل يدعم أيضًا أنواعًا أخرى من البيانات، مثل الصوت والفيديو والبيانات الجدولية وما إلى ذلك.
ورشة عمل لتعلم التعلم الآلي التنافسي باستخدام الفن ؟؟
Cleverhans هي مكتبة لتنفيذ هجمات التهرب واختبار قوة نموذج التعلم العميق على نماذج الصور.

تم تطويره بلغة Python ويتكامل مع أطر عمل Tensorflow وTorch وJAX.
وهو ينفذ العديد من الهجمات مثل L-BFGS، وFGSM، وJSMA، وC&W، وغيرها.
يُستخدم الذكاء الاصطناعي لإنجاز المهام الضارة وتعزيز الهجمات الكلاسيكية.
ميغيل هيرنانديز | خوسيه Ignacio Escribano |


