metal flash attention
v1.0.1
يقوم هذا المستودع بتنفيذ التنفيذ الرسمي لـ FlashAttention إلى Apple silicon. إنها مجموعة صغيرة من الملفات المصدر التي يمكن صيانتها والتي تعيد إنتاج خوارزمية FlashAttention.
الاهتمام برأس واحد فقط، للتركيز على الاختناقات الأساسية لخوارزميات الاهتمام المختلفة (تسجيل الضغط، والتوازي). مع تنفيذ الخوارزمية الأساسية بشكل صحيح، يجب أن يكون من السهل نسبيًا إضافة تخصيصات مثل تناثر الكتل.
يتم تجميع كل شيء في JIT في وقت التشغيل. وهذا يتناقض مع التنفيذ السابق، الذي اعتمد على ملف قابل للتنفيذ مضمن في Xcode 14.2.
يستخدم التمرير الخلفي ذاكرة أقل من Dao-AILab/flash-attention. يخصص التنفيذ الرسمي مساحة الصفر للذرات والمبالغ الجزئية. تفتقر أجهزة Apple إلى ذرات FP32 الأصلية ( تتم محاكاة metal::atomic<float> ). أثناء محاولة التحايل على نقص دعم الأجهزة، تم الكشف عن اختناقات النطاق الترددي والتوازي في نواة FlashAttention-2 الخلفية. تم تصميم تمريرة خلفية بديلة بتكلفة حسابية أعلى (7 وحدات GEMM بدلاً من 5 وحدات GEMM). إنه يحقق كفاءة موازية بنسبة 100% عبر أبعاد الصف والعمود لمصفوفة الانتباه. والأهم من ذلك، أنه من الأسهل الترميز والصيانة.
لقد تم القيام بالكثير من الأشياء المجنونة للتغلب على اختناقات ضغط التسجيل. في أبعاد الرأس الكبيرة (مثل 256)، لا يمكن لأي من كتل المصفوفة أن تتناسب مع السجلات. ولا حتى المجمع يستطيع ذلك. ولذلك، يتم تنفيذ تسرب السجل المتعمد، ولكن بطريقة أكثر تحسينًا. تمت إضافة بُعد كتلة ثالث إلى خوارزمية الانتباه، والذي يتم حظره على طول D . تم تشويه نسبة العرض إلى الارتفاع لكتل مصفوفة الانتباه بشكل كبير، لتقليل تكلفة عرض النطاق الترددي لانسكاب التسجيل. على سبيل المثال، 16-32 على طول بعد التوازي و80-128 على طول بعد الاجتياز. يوجد ملف معلمة كبير يأخذ البعد D ، ويحدد المعاملات التي يمكن وضعها في السجلات. ثم يقوم بعد ذلك بتعيين حجم كتلة يوازن بين العديد من الاختناقات المتنافسة.
والنتيجة النهائية هي 4400 جيجا تعليمات متسقة في الثانية على M1 Max (استخدام 83% من ALU)، بطول تسلسل لا نهائي وأبعاد رأس لا نهائية. يتم استخدام محاكاة BF16 المقدمة للحصول على دقة مختلطة (يحتوي bfloat الخاص بـ Metal على تقريب متوافق مع IEEE، وهو عبء كبير على الرقائق القديمة بدون أجهزة BF16).
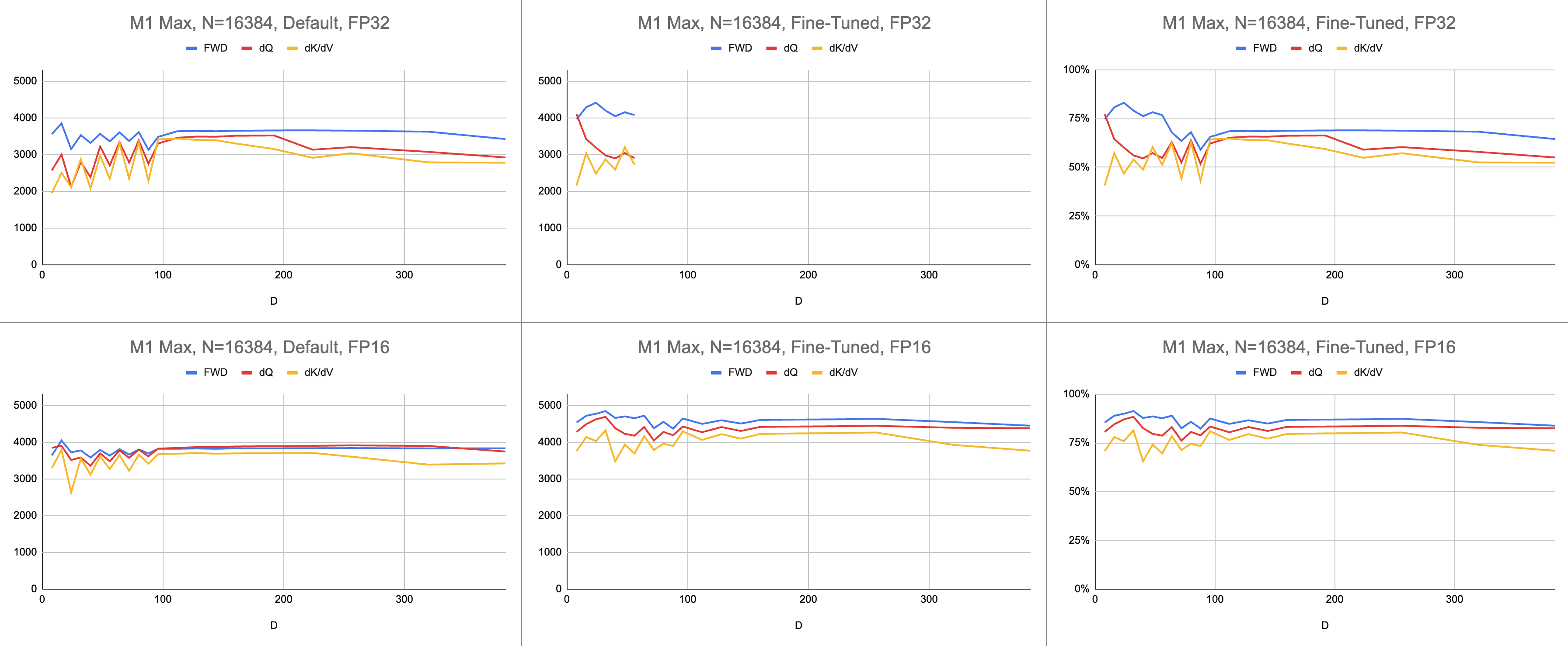
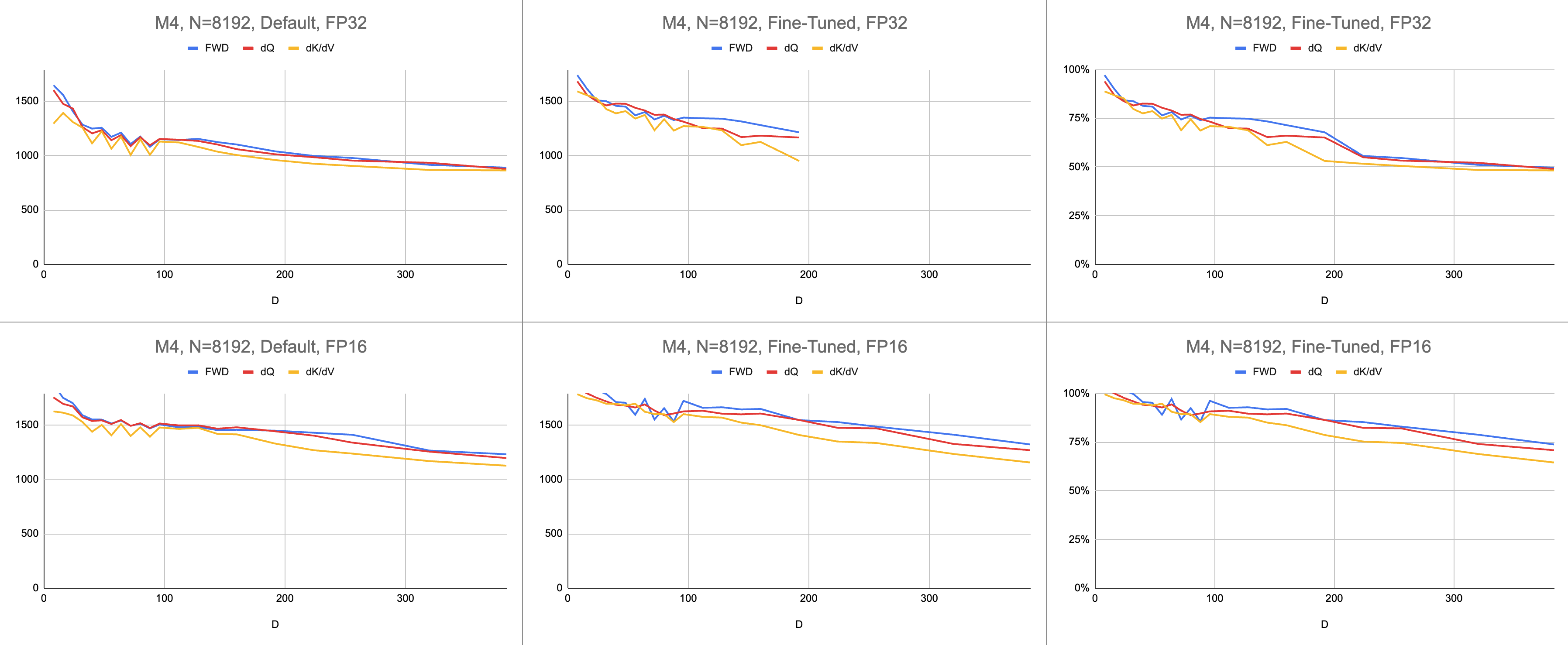
البيانات الأولية: https://docs.google.com/spreadsheets/d/1Xf4jrJ7e19I32J1IWIekGE9uMFTeZKoOpQ6hlUoh-xY/edit?usp=sharing
في مجال الذكاء الاصطناعي، يتم الإبلاغ عن الأداء غالبًا في عمليات النقطة العائمة جيجا في الثانية (GFLOPS). يعكس هذا المقياس نموذجًا مبسطًا للأداء، بحيث تحدث كل تعليمات في GEMM. مع تقدم الأجهزة من وحدات FPU المبكرة إلى معالجات المتجهات الحديثة، تم دمج عمليات الفاصلة العائمة الأكثر شيوعًا في تعليمات واحدة. تنصهر إضافة مضاعفة (FMA). عندما يتم ضرب مصفوفتين 100x100، يتم إصدار مليون تعليمات FMA. لماذا يجب أن نتعامل مع FMA كتعليمتين منفصلتين؟
هذا السؤال ذو صلة بالانتباه، حيث لا يتم إنشاء جميع عمليات الفاصلة العائمة على قدم المساواة. يحدث الأسي أثناء softmax في دورة ساعة واحدة، بشرط أن تذهب معظم التعليمات الأخرى إلى وحدة FMA. لا يمكن دمج بعض عمليات الضرب والإضافة أثناء softmax مع عملية إضافة أو ضرب قريبة. هل يجب أن نتعامل مع هذه العناصر مثل FMA، ونتظاهر بأن الأجهزة تنفذ FMA بشكل أبطأ مرتين؟ ليس من الواضح كيف يمكن لنموذج أداء GEMM أن يوضح ما إذا كان جهاز التظليل الخاص بي يستخدم أجهزة ALU بشكل فعال.
بدلاً من جيجا فلوب، أستخدم تعليمات جيجا لفهم مدى جودة أداء التظليل. إنه يعين الخوارزمية بشكل مباشر أكثر. على سبيل المثال، أحد GEMM هو تعليمات N^3 FMA. يؤدي الانتباه الأمامي إلى ضرب مصفوفتين، أو تعليمات 2 * D * N^2 FMA. الاهتمام الخلفي (بواسطة تطبيق Dao-AILab/flash-attention) هو 5 * D * N^2 تعليمات FMA. حاول مقارنة هذا الجدول بنماذج خط السقف في أوراق Flash1 أو Flash2 أو Flash3.
| عملية | عمل |
|---|---|
| جوهرة مربعة | N^3 |
| الاهتمام إلى الأمام | (2D + 5) * N^2 |
| الاهتمام الساذج إلى الوراء | 4D * N^2 |
| انتباه فلاش إلى الوراء | (5D + 5) * N^2 |
| الدفع الأمامي + الدفع بالعجلات الأمامية مجتمعين | (7D + 10) * N^2 |
نظرًا لتعقيد ذرات FP32، استخدم MFA أسلوبًا مختلفًا للتمرير للخلف. هذا واحد لديه تكلفة حسابية أعلى. يقوم بتقسيم التمريرة الخلفية إلى نواتين منفصلتين: dQ و dK/dV . تظهر القائمة المنسدلة الرمز الكاذب. قارن هذا بإحدى الخوارزميات الموجودة في أوراق Flash1 أو Flash2 أو Flash3.
| عملية | عمل |
|---|---|
| إلى الأمام | (2D + 5) * N^2 |
| إلى الوراء دي ق | (3D + 5) * N^2 |
| إلى الوراء dK / dV | (4D + 5) * N^2 |
| الدفع الأمامي + الدفع بالعجلات الأمامية مجتمعين | (9D + 15) * N^2 |
// Forward
// for c in 0..<C {
// load K[c]
// S = Q * K^T
// (m, l, P) = softmax(m, l, S * scaleFactor)
//
// O *= correction
// load V[c]
// O += P * V
// }
// O /= l
//
// L = m + logBaseE(l)
//
// Backward Query
// D = dO * O
//
// for c in 0..<C {
// load K[c]
// S = Q * K^T
// P = exp(S - L)
//
// load V[c]
// dP = dO * V^T
// dS = P * (dP - D) * scaleFactor
//
// load K[c]
// dQ += dS * K
// }
//
// Backward Key-Value
// for r in 0..<R {
// load Q[r]
// load L[r]
// S^T = K * Q^T
// P^T = exp(S^T - L)
//
// load dO[r]
// dV += P^T * dO
//
// load dO[r]
// load D[r]
// dP^T = V * dO^T
// dS^T = P^T * (dP^T - D) * scaleFactor
//
// load Q[r]
// dK += dS^T * Q
// }يتم قياس الأداء عن طريق حساب مقدار العمل الحسابي، ثم قسمته على الثواني. والنتيجة النهائية هي "تعليمات جيجا في الثانية". بعد ذلك، نحن بحاجة إلى نموذج خط السقف. يوضح الجدول أدناه خطوط السقف لـ GINSTRS، محسوبة بنصف GFLOPS. استخدام ALU هو (تعليمات جيجا الفعلية في الثانية) / (تعليمات جيجا المتوقعة في الثانية). على سبيل المثال، يحقق M1 Max عادةً استخدام ALU بنسبة 80% بدقة مختلطة.
هناك حدود لهذا النموذج. ينهار مع جيل M3 بأبعاد الرأس الصغيرة. قد يتم استخدام وحدات حسابية مختلفة في وقت واحد، مما يجعل الاستخدام الظاهري أكثر من 100%. بالنسبة للجزء الأكبر، يوفر المعيار نموذجًا دقيقًا لمدى الأداء المتبقي على الطاولة.
var operations : Int
switch benchmarkedKernel {
case . forward :
operations = 2 * headDimension + 5
case . backwardQuery :
operations = 3 * headDimension + 5
case . backwardKeyValue :
operations = 4 * headDimension + 5
}
operations *= ( sequenceDimension * sequenceDimension )
operations *= dispatchCount
// Divide the work by the latency, resulting in throughput.
let instrs = Double ( operations ) / Double ( latencySeconds )
let ginstrs = Int ( instrs / 1e9 )| الأجهزة | GFLOPS | جينسترس |
|---|---|---|
| M1 ماكس | 10616 | 5308 |
| م4 | 3580 | 1790 |
ما مدى جودة المنفذ المعدني مقارنة بمستودع FlashAttention الرسمي؟ تخيل أنني استخدمت خوارزمية "atomic dQ" وحققت أداءً بنسبة 100%. بعد ذلك، قمت بالتبديل إلى مستودع MFA الفعلي ووجدت أن التدريب النموذجي أبطأ بمقدار 4 مرات. سيكون ذلك 25% من خط السقف من المستودع الرسمي. للحصول على هذه النسبة، قم بضرب متوسط استخدام ALU عبر النوى الثلاث في 7 / 9 . تم استخدام نموذج أكثر دقة للإحصائيات الخاصة بأجهزة Apple، ولكن هذا هو جوهره.
لحساب استخدام أجهزة Nvidia، استخدمت GFLOPS لوحدات ALU FP16/BF16. قمت بتقسيم أعلى GFLOPS من كل رسم بياني في الورقة على 312000 (A100 SXM)، 989000 (H100 SXM). لاحظ أنه بالنسبة لأبعاد الرأس الأكبر وتسجيل النوى المكثفة (التمرير الخلفي)، لم يتم الإبلاغ عن أي معايير. لقد أكدت أنهم لم يحلوا مشكلة ضغط التسجيل بأبعاد الرأس اللانهائية. على سبيل المثال، يتم الاحتفاظ بالمراكم دائمًا في السجلات. في وقت كتابة هذا التقرير، لم أر دليلًا ملموسًا على تنفيذ التدرج العكسي D=256 بالنتائج الصحيحة.
| A100، فلاش 2، FP16 | د = 64 | د = 128 | د = 256 |
|---|---|---|---|
| إلى الأمام | 192000 | 223000 | 0 |
| إلى الوراء | 170000 | 196000 | 0 |
| للأمام + للخلف | 176000 | 203000 | 0 |
| H100، فلاش 3، FP16 | د = 64 | د = 128 | د = 256 |
|---|---|---|---|
| إلى الأمام | 497000 | 648000 | 756000 |
| إلى الوراء | 474000 | 561000 | 0 |
| للأمام + للخلف | 480000 | 585000 | 0 |
| H100، فلاش 3، FP8 | د = 64 | د = 128 | د = 256 |
|---|---|---|---|
| إلى الأمام | 613000 | 1008000 | 1171000 |
| إلى الوراء | 0 | 0 | 0 |
| للأمام + للخلف | 0 | 0 | 0 |
| A100، فلاش 2، FP16 | د = 64 | د = 128 | د = 256 |
|---|---|---|---|
| إلى الأمام | 62% | 71% | 0% |
| للأمام + للخلف | 56% | 65% | 0% |
| H100، فلاش 3، FP16 | د = 64 | د = 128 | د = 256 |
|---|---|---|---|
| إلى الأمام | 50% | 66% | 76% |
| للأمام + للخلف | 48% | 59% | 0% |
| الهندسة المعمارية M1، FP16 | د = 64 | د = 128 | د = 256 |
|---|---|---|---|
| إلى الأمام | 86% | 85% | 86% |
| للأمام + للخلف | 62% | 63% | 64% |
| الهندسة المعمارية M3، FP16 | د = 64 | د = 128 | د = 256 |
|---|---|---|---|
| إلى الأمام | 94% | 91% | 82% |
| للأمام + للخلف | 71% | 69% | 61% |
| الأجهزة المنتجة في عام 2020 | د = 64 | د = 128 | د = 256 |
|---|---|---|---|
| A100 | 56% | 65% | 0% |
| الهندسة المعمارية M1 — M2 | 62% | 63% | 64% |
| الأجهزة المنتجة في عام 2023 | د = 64 | د = 128 | د = 256 |
|---|---|---|---|
| H100 (باستخدام FP8 GFLOPS) | 24% | 30% | 0% |
| H100 (باستخدام FP16 GFLOPS) | 48% | 59% | 0% |
| الهندسة المعمارية M3—M4 | 71% | 69% | 61% |
على الرغم من إصدار المزيد من العمليات الحسابية، فإن أجهزة Apple تقوم بتدريب المحولات بشكل أسرع من قيام أجهزة Nvidia بنفس العمل . تطبيع الفرق في الحجم بين وحدات معالجة الرسومات المختلفة. التركيز فقط على مدى كفاءة استخدام وحدة معالجة الرسومات.
ربما يجب على المستودع الرئيسي تجربة الخوارزمية التي تتجنب ذرات FP32 وتتعمد تسريب السجلات عندما لا يمكن احتواؤها في قلب وحدة معالجة الرسومات. يبدو هذا غير مرجح، حيث أن لديهم دعمًا مشفرًا لمجموعة فرعية صغيرة من أحجام المشكلات المحتملة. يبدو أن الدافع يدعم النماذج الأكثر شيوعًا، حيث D هي قوة 2، وأقل من 128. بالنسبة لأي شيء آخر، يحتاج المستخدمون إلى الاعتماد على تطبيقات احتياطية بديلة (مثل مستودع MFA)، والتي قد تستخدم أساسًا مختلفًا تمامًا خوارزمية.
على نظام التشغيل macOS، قم بتنزيل حزمة Swift وتجميعها باستخدام -Xswiftc -Ounchecked . يعد خيار برنامج التحويل البرمجي هذا ضروريًا لرموز وحدة المعالجة المركزية الحساسة للأداء. لا يمكن استخدام وضع الإصدار لأنه يفرض إعادة ترجمة قاعدة التعليمات البرمجية بأكملها من البداية، في كل مرة يحدث فيها تغيير واحد. انتقل إلى Git repo في Finder وانقر نقرًا مزدوجًا فوق Package.swift . يجب أن تظهر نافذة Xcode. على اليسار، يجب أن يكون هناك تسلسل هرمي للملفات. إذا لم تتمكن من كشف التسلسل الهرمي، فقد حدث خطأ ما.
git clone https://github.com/philipturner/metal-flash-attention
swift build -Xswiftc -Ounchecked # Does it even compile?
swift test -Xswiftc -Ounchecked # Does the test suite finish in ~10 seconds?
وبدلاً من ذلك، قم بإنشاء مشروع Xcode جديد باستخدام قالب SwiftUI. تجاوز "Hello, world!" سلسلة مع استدعاء دالة تقوم بإرجاع String . ستقوم هذه الوظيفة بتنفيذ البرنامج النصي الذي تختاره، ثم استدعاء exit(0) ، لذلك يتعطل التطبيق قبل عرض أي شيء على الشاشة. ستستخدم المخرجات في وحدة تحكم Xcode كملاحظات حول التعليمات البرمجية الخاصة بك. سير العمل هذا متوافق مع كل من macOS وiOS.
أضف الخيار -Xswiftc -Ounchecked من خلال Project > اسم مشروعك > إعدادات البناء > Swift Compiler - إنشاء التعليمات البرمجية > مستوى التحسين . يسرد العمود الثاني من الجدول اسم مشروعك. انقر فوق أخرى في القائمة المنسدلة واكتب -Ounchecked في اللوحة التي تظهر. بعد ذلك، أضف هذا المستودع باعتباره تبعية لحزمة Swift. قم بالاطلاع على بعض الاختبارات ضمن Tests/FlashAttention . انسخ كود المصدر الأولي لأحد هذه الاختبارات إلى مشروعك. استدعاء الاختبار من الوظيفة في الفقرة السابقة. افحص ما يعرضه على وحدة التحكم.
لتعديل إنشاء كود Metal (على سبيل المثال، إضافة دعم متعدد الرؤوس أو القناع)، انسخ كود Swift الأولي إلى مشروع Xcode الخاص بك. إما أن تستخدم git clone في مجلد منفصل، أو قم بتنزيل الملفات الأولية على GitHub كملف ZIP. هناك أيضًا طريقة للربط بشوكة metal-flash-attention الخاصة بك وحفظ تغييراتك تلقائيًا على السحابة، ولكن إعداد هذا أكثر صعوبة. قم بإزالة تبعية حزمة Swift من الفقرة السابقة. أعد تشغيل الاختبار الذي تختاره. هل يقوم بتجميع وعرض شيء ما في وحدة التحكم؟
حدد موقع أحد القيم الحرفية للسلسلة متعددة الأسطر في أي من هذه المجلدات:
Sources/FlashAttention/Attention/AttentionKernel
Sources/FlashAttention/GEMM/GEMMKernel
إضافة نص عشوائي إلى واحد منهم. ترجمة وتشغيل المشروع مرة أخرى. يجب أن يحدث خطأ فادح. على سبيل المثال، قد يقوم برنامج التحويل البرمجي Metal بإلقاء خطأ. إذا لم يحدث ذلك، فحاول العبث بسطر مختلف من التعليمات البرمجية في مكان آخر. إذا استمر الاختبار في النجاح، فهذا يعني أن Xcode لا يسجل تغييراتك.
استمر في ترميز تناثر الكتلة أو شيء من هذا القبيل. احصل على تعليقات حول ما إذا كانت التعليمات البرمجية تعمل على الإطلاق، وما إذا كانت تعمل بسرعة، وما إذا كانت تعمل بسرعة عند كل حجم مشكلة. قم بدمج كود المصدر الأولي في تطبيقك، أو ترجمته إلى لغة برمجة أخرى.


