make a video pytorch
0.4.0
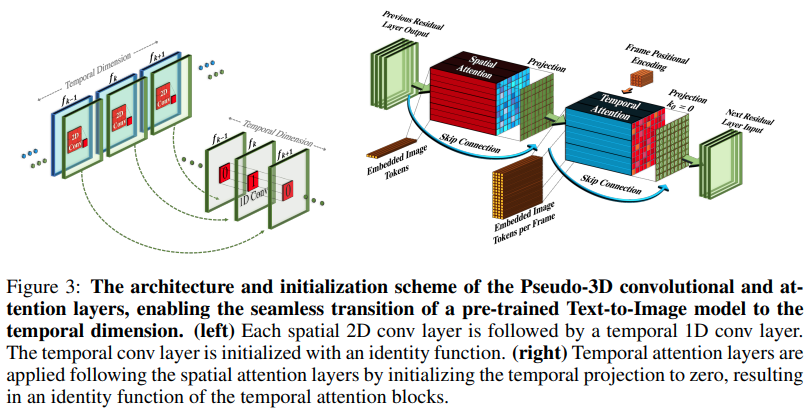
تنفيذ Make-A-Video، نص SOTA الجديد لمولد الفيديو من Meta AI، في Pytorch. إنها تجمع بين التلافيف الزائفة ثلاثية الأبعاد (التلافيف المحورية) والاهتمام الزمني وتظهر اندماجًا زمنيًا أفضل بكثير.
إن التلافيفات الزائفة ثلاثية الأبعاد ليست مفهومًا جديدًا. وقد تم استكشافها من قبل في سياقات أخرى، على سبيل المثال للتنبؤ بالاتصال بالبروتين باعتبارها "شبكات متبقية هجينة ذات أبعاد".
يتلخص جوهر الورقة في اتخاذ نموذج SOTA لتحويل النص إلى صورة (هنا يستخدمون DALL-E2، ولكن نفس نقاط التعلم يمكن تطبيقها بسهولة على Imagen)، وإجراء بعض التعديلات الطفيفة لجذب الانتباه عبر الزمن وبطرق أخرى للتقليل من تكلفة الحوسبة، قم بإجراء استيفاء الإطار بشكل صحيح، واحصل على نموذج فيديو رائع.
شرح AI Coffee Break
Stability.ai على الرعاية السخية للعمل على أحدث أبحاث الذكاء الاصطناعي
جوناثان هو لإحداثه ثورة في الذكاء الاصطناعي التوليدي من خلال بحثه المبتكر
Alex for einops، فكرة مجردة عبقرية. لا توجد كلمة أخرى لذلك.
$ pip install make-a-video-pytorchتمرير في ميزات الفيديو
import torch
from make_a_video_pytorch import PseudoConv3d , SpatioTemporalAttention
conv = PseudoConv3d (
dim = 256 ,
kernel_size = 3
)
attn = SpatioTemporalAttention (
dim = 256 ,
dim_head = 64 ,
heads = 8
)
video = torch . randn ( 1 , 256 , 8 , 16 , 16 ) # (batch, features, frames, height, width)
conv_out = conv ( video ) # (1, 256, 8, 16, 16)
attn_out = attn ( video ) # (1, 256, 8, 16, 16)تمرير الصور (في حالة التدريب المسبق على الصور أولاً)، سيتم تخطي كل من الإلتفاف الزمني والانتباه تلقائيًا. بمعنى آخر، يمكنك استخدام هذا بشكل مباشر في 2d Unet ثم نقله إلى 3d Unet بمجرد الانتهاء من هذه المرحلة من التدريب. تتم تهيئة الوحدات الزمنية لإخراج الهوية كما فعلت الورقة.
import torch
from make_a_video_pytorch import PseudoConv3d , SpatioTemporalAttention
conv = PseudoConv3d (
dim = 256 ,
kernel_size = 3
)
attn = SpatioTemporalAttention (
dim = 256 ,
dim_head = 64 ,
heads = 8
)
images = torch . randn ( 1 , 256 , 16 , 16 ) # (batch, features, height, width)
conv_out = conv ( images ) # (1, 256, 16, 16)
attn_out = attn ( images ) # (1, 256, 16, 16)يمكنك أيضًا التحكم في الوحدتين بحيث أنه عند تغذية الميزات ثلاثية الأبعاد، فإنها تقوم بالتدريب مكانيًا فقط
import torch
from make_a_video_pytorch import PseudoConv3d , SpatioTemporalAttention
conv = PseudoConv3d (
dim = 256 ,
kernel_size = 3
)
attn = SpatioTemporalAttention (
dim = 256 ,
dim_head = 64 ,
heads = 8
)
video = torch . randn ( 1 , 256 , 8 , 16 , 16 ) # (batch, features, frames, height, width)
# below it will not train across time
conv_out = conv ( video , enable_time = False ) # (1, 256, 8, 16, 16)
attn_out = attn ( video , enable_time = False ) # (1, 256, 8, 16, 16) SpaceTimeUnet الكامل الذي لا يهتم بالصور أو التدريب على الفيديو، حيث يمكن تجاهل الوقت حتى إذا تم تمرير الفيديو
import torch
from make_a_video_pytorch import SpaceTimeUnet
unet = SpaceTimeUnet (
dim = 64 ,
channels = 3 ,
dim_mult = ( 1 , 2 , 4 , 8 ),
resnet_block_depths = ( 1 , 1 , 1 , 2 ),
temporal_compression = ( False , False , False , True ),
self_attns = ( False , False , False , True ),
condition_on_timestep = False ,
attn_pos_bias = False ,
flash_attn = True
). cuda ()
# train on images
images = torch . randn ( 1 , 3 , 128 , 128 ). cuda ()
images_out = unet ( images )
assert images . shape == images_out . shape
# then train on videos
video = torch . randn ( 1 , 3 , 16 , 128 , 128 ). cuda ()
video_out = unet ( video )
assert video_out . shape == video . shape
# or even treat your videos as images
video_as_images_out = unet ( video , enable_time = False )انتبه إلى أفضل ما تقدمه أبحاث التضمين الموضعي
حساء الاهتمام
إضافة انتباه فلاش
تأكد من أن dalle2-pytorch يمكنه قبول SpaceTimeUnet للتدريب
@misc { Singer2022 ,
author = { Uriel Singer } ,
url = { https://makeavideo.studio/Make-A-Video.pdf }
} @inproceedings { rogozhnikov2022einops ,
title = { Einops: Clear and Reliable Tensor Manipulations with Einstein-like Notation } ,
author = { Alex Rogozhnikov } ,
booktitle = { International Conference on Learning Representations } ,
year = { 2022 } ,
url = { https://openreview.net/forum?id=oapKSVM2bcj }
} @article { Dong2021AttentionIN ,
title = { Attention is Not All You Need: Pure Attention Loses Rank Doubly Exponentially with Depth } ,
author = { Yihe Dong and Jean-Baptiste Cordonnier and Andreas Loukas } ,
journal = { ArXiv } ,
year = { 2021 } ,
volume = { abs/2103.03404 }
} @article { Zhang2021TokenST ,
title = { Token Shift Transformer for Video Classification } ,
author = { Hao Zhang and Y. Hao and Chong-Wah Ngo } ,
journal = { Proceedings of the 29th ACM International Conference on Multimedia } ,
year = { 2021 }
} @inproceedings { shleifer2022normformer ,
title = { NormFormer: Improved Transformer Pretraining with Extra Normalization } ,
author = { Sam Shleifer and Myle Ott } ,
booktitle = { Submitted to The Tenth International Conference on Learning Representations } ,
year = { 2022 } ,
url = { https://openreview.net/forum?id=GMYWzWztDx5 } ,
} @inproceedings { dao2022flashattention ,
title = { Flash{A}ttention: Fast and Memory-Efficient Exact Attention with {IO}-Awareness } ,
author = { Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{'e}, Christopher } ,
booktitle = { Advances in Neural Information Processing Systems } ,
year = { 2022 }
}

