recurrent memory transformer pytorch
0.7.0
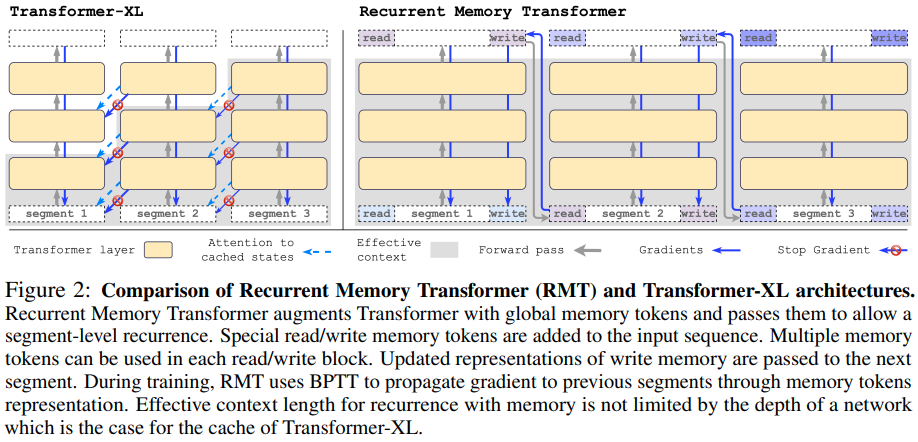
تنفيذ محول الذاكرة المتكررة (مراجعة مفتوحة) في Pytorch. لقد كان لديهم مؤخرًا ورقة متابعة قصيرة أظهرت أنهم قادرون على نسخ المعلومات عبر مليون رمز مميز على الأقل.
ليس هناك شك في ذهني أن RMT من شأنه أن يجعل وكيل RL أقوى من AdA، وهو مجرد محول XL - التحديث: محول الإجراء المتكرر مع الذاكرة (RATE)
مراجعة ورقة يانيك كيلشر
$ pip install recurrent-memory-transformer-pytorch import torch
from recurrent_memory_transformer_pytorch import RecurrentMemoryTransformer
model = RecurrentMemoryTransformer (
num_tokens = 20000 , # number of tokens
num_memory_tokens = 128 , # number of memory tokens, this will determine the bottleneck for information being passed to the future
dim = 512 , # model dimensions
depth = 6 , # transformer depth
causal = True , # autoregressive or not
dim_head = 64 , # dimension per head
heads = 8 , # heads
seq_len = 1024 , # sequence length of a segment
use_flash_attn = True # whether to use flash attention
)
x = torch . randint ( 0 , 256 , ( 1 , 1024 ))
logits1 , mem1 , _ = model ( x ) # (1, 1024, 20000), (1, 128, 512), None
logits2 , mem2 , _ = model ( x , mem1 ) # (1, 1024, 20000), (1, 128, 512), None
logits3 , mem3 , _ = model ( x , mem2 ) # (1, 1024, 20000), (1, 128, 512), None
# and so on ...مع ذكريات XL
import torch
from recurrent_memory_transformer_pytorch import RecurrentMemoryTransformer
model = RecurrentMemoryTransformer (
num_tokens = 20000 ,
num_memory_tokens = 128 ,
dim = 512 ,
depth = 6 ,
causal = True ,
dim_head = 64 ,
heads = 8 ,
seq_len = 1024 ,
use_flash_attn = True ,
use_xl_memories = True , # set this to True
xl_mem_len = 512 # can be shorter than the seq len - i think just having a bit of the past will prevent much of the RMT memories memorizing the immediate preceding text
)
x = torch . randint ( 0 , 256 , ( 1 , 1024 ))
logits1 , mem1 , xl_mem1 = model ( x ) # (1, 1024, 20000), (1, 128, 512), [(2, 1, 512, 512)]
logits2 , mem2 , xl_mem2 = model ( x , mem1 , xl_memories = xl_mem1 ) # (1, 1024, 20000), (1, 128, 512), [(2, 1, 512, 512)]
logits3 , mem3 , xl_mem3 = model ( x , mem2 , xl_memories = xl_mem2 ) # (1, 1024, 20000), (1, 128, 512), [(2, 1, 512, 512)]
# and so on ...تدريب على تسلسل طويل سخيف
import torch
from recurrent_memory_transformer_pytorch import (
RecurrentMemoryTransformer ,
RecurrentMemoryTransformerWrapper
)
model = RecurrentMemoryTransformer (
num_tokens = 256 ,
num_memory_tokens = 128 ,
dim = 512 ,
depth = 6 ,
seq_len = 1024 ,
use_flash_attn = True ,
causal = True
)
model = RecurrentMemoryTransformerWrapper ( model ). cuda ()
seq = torch . randint ( 0 , 256 , ( 4 , 65536 )). cuda () # absurdly long sequence, in reality, they curriculum learned this starting with 1 segment to about 7-8 segments
loss = model ( seq , memory_replay_backprop = True ) # memory efficient training from memformer paper قم بتحريك الدعامة الخلفية لإعادة تشغيل الذاكرة إلى وظيفة الشعلة، واختبر ثنائي الاتجاه، ثم اختبر مشكلة حقيقية
اجعل التضمينات الدوارة تعمل بشكل صحيح مع ذكريات XL
إضافة ذكريات XL، منفصلة
تقديم طريقة لإيقاف التضمينات الدوارة والتضمينات الموضعية المطلقة وإضافة إزاحة رمزية
جعل الذكريات مقنعة سببيا خيارا
إضافة تقنية backprop لإعادة تشغيل الذاكرة من ورق memformer
الترميز الموضعي النسبي
كتلة المحولات المتكررة
ميمفورمر
@inproceedings { bulatov2022recurrent ,
title = { Recurrent Memory Transformer } ,
author = { Aydar Bulatov and Yuri Kuratov and Mikhail Burtsev } ,
booktitle = { Advances in Neural Information Processing Systems } ,
editor = { Alice H. Oh and Alekh Agarwal and Danielle Belgrave and Kyunghyun Cho } ,
year = { 2022 } ,
url = { https://openreview.net/forum?id=Uynr3iPhksa }
} @misc { bulatov2023scaling ,
title = { Scaling Transformer to 1M tokens and beyond with RMT } ,
author = { Aydar Bulatov and Yuri Kuratov and Mikhail S. Burtsev } ,
year = { 2023 } ,
eprint = { 2304.11062 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CL }
} @inproceedings { dao2022flashattention ,
title = { Flash{A}ttention: Fast and Memory-Efficient Exact Attention with {IO}-Awareness } ,
author = { Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{'e}, Christopher } ,
booktitle = { Advances in Neural Information Processing Systems } ,
year = { 2022 }
} @misc { shazeer2020glu ,
title = { GLU Variants Improve Transformer } ,
author = { Noam Shazeer } ,
year = { 2020 } ,
url = { https://arxiv.org/abs/2002.05202 }
} @misc { su2021roformer ,
title = { RoFormer: Enhanced Transformer with Rotary Position Embedding } ,
author = { Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu } ,
year = { 2021 } ,
eprint = { 2104.09864 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CL }
} @inproceedings { Wu2020MemformerAM ,
title = { Memformer: A Memory-Augmented Transformer for Sequence Modeling } ,
author = { Qingyang Wu and Zhenzhong Lan and Kun Qian and Jing Gu and Alborz Geramifard and Zhou Yu } ,
booktitle = { AACL/IJCNLP } ,
year = { 2020 }
} @software { peng_bo_2021_5196578 ,
author = { PENG Bo } ,
title = { BlinkDL/RWKV-LM: 0.01 } ,
month = { aug } ,
year = { 2021 } ,
publisher = { Zenodo } ,
version = { 0.01 } ,
doi = { 10.5281/zenodo.5196578 } ,
url = { https://doi.org/10.5281/zenodo.5196578 }
} @misc { ding2021cogview ,
title = { CogView: Mastering Text-to-Image Generation via Transformers } ,
author = { Ming Ding and Zhuoyi Yang and Wenyi Hong and Wendi Zheng and Chang Zhou and Da Yin and Junyang Lin and Xu Zou and Zhou Shao and Hongxia Yang and Jie Tang } ,
year = { 2021 } ,
eprint = { 2105.13290 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @software { Dayma_DALLE_Mini_2021 ,
author = { Dayma, Boris and Patil, Suraj and Cuenca, Pedro and Saifullah, Khalid and Abraham, Tanishq and Lê Khắc, Phúc and Melas, Luke and Ghosh, Ritobrata } ,
doi = { 10.5281/zenodo.5146400 } ,
license = { Apache-2.0 } ,
month = { jul } ,
title = { {DALL·E Mini} } ,
url = { https://github.com/borisdayma/dalle-mini } ,
version = { v0.1-alpha } ,
year = { 2021 } } @inproceedings { anonymous2022normformer ,
title = { NormFormer: Improved Transformer Pretraining with Extra Normalization } ,
author = { Anonymous } ,
booktitle = { Submitted to The Tenth International Conference on Learning Representations } ,
year = { 2022 } ,
url = { https://openreview.net/forum?id=GMYWzWztDx5 } ,
note = { under review }
} @misc { ding2021erniedoc ,
title = { ERNIE-Doc: A Retrospective Long-Document Modeling Transformer } ,
author = { Siyu Ding and Junyuan Shang and Shuohuan Wang and Yu Sun and Hao Tian and Hua Wu and Haifeng Wang } ,
year = { 2021 } ,
eprint = { 2012.15688 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CL }
} @article { Zhu2024HyperConnections ,
title = { Hyper-Connections } ,
author = { Defa Zhu and Hongzhi Huang and Zihao Huang and Yutao Zeng and Yunyao Mao and Banggu Wu and Qiyang Min and Xun Zhou } ,
journal = { ArXiv } ,
year = { 2024 } ,
volume = { abs/2409.19606 } ,
url = { https://api.semanticscholar.org/CorpusID:272987528 }
} @inproceedings { Zhou2024ValueRL ,
title = { Value Residual Learning For Alleviating Attention Concentration In Transformers } ,
author = { Zhanchao Zhou and Tianyi Wu and Zhiyun Jiang and Zhenzhong Lan } ,
year = { 2024 } ,
url = { https://api.semanticscholar.org/CorpusID:273532030 }
}

