igel
v1.0.0
أداة رائعة للتعلم الآلي تتيح لك تدريب/ملاءمة النماذج واختبارها واستخدامها دون الحاجة إلى كتابة تعليمات برمجية
ملحوظة
أنا أعمل أيضًا على تطبيق واجهة المستخدم الرسومية لسطح المكتب لـ igel بناءً على طلبات الأشخاص. يمكنك العثور عليه ضمن Igel-UI.
جدول المحتويات
الهدف من المشروع هو توفير التعلم الآلي للجميع ، سواء المستخدمين التقنيين أو غير التقنيين.
كنت بحاجة إلى أداة في بعض الأحيان، يمكنني استخدامها لإنشاء نموذج أولي للتعلم الآلي بسرعة. سواء كنت تريد بناء إثبات للمفهوم، أو إنشاء نموذج مسودة سريع لإثبات نقطة ما، أو استخدام التعلم الآلي التلقائي. أجد نفسي في كثير من الأحيان عالقًا في كتابة التعليمات البرمجية المعيارية وأفكر كثيرًا من أين أبدأ. لذلك قررت إنشاء هذه الأداة.
تم بناء igel على رأس أطر تعلم الآلة الأخرى. فهو يوفر طريقة بسيطة لاستخدام التعلم الآلي دون كتابة سطر واحد من التعليمات البرمجية . Igel قابل للتخصيص بدرجة كبيرة ، ولكن فقط إذا كنت تريد ذلك. لا يجبرك Igel على تخصيص أي شيء. إلى جانب القيم الافتراضية، يمكن لـ igel استخدام ميزات القراءة التلقائية لاكتشاف نموذج يمكنه العمل بشكل رائع مع بياناتك.
كل ما تحتاجه هو ملف yaml (أو json )، حيث تحتاج إلى وصف ما تحاول القيام به. هذا كل شيء!
يدعم Igel الانحدار والتصنيف والتجمع. يدعم Igel ميزات القراءة التلقائية مثل ImageClassification وTextClassification
يدعم Igel أنواع مجموعات البيانات الأكثر استخدامًا في مجال علم البيانات. على سبيل المثال، يمكن أن تكون مجموعة بيانات الإدخال الخاصة بك ملف CSV أو txt أو Excel Sheet أو json أو حتى ملف html الذي تريد جلبه. إذا كنت تستخدم ميزات القراءة التلقائية، فيمكنك أيضًا تغذية البيانات الأولية إلى igel وسيكتشف كيفية التعامل معها. المزيد عن هذا لاحقًا في الأمثلة.
$ pip install -U igel نماذج Igel المدعومة:
+--------------------+----------------------------+-------------------------+
| regression | classification | clustering |
+--------------------+----------------------------+-------------------------+
| LinearRegression | LogisticRegression | KMeans |
| Lasso | Ridge | AffinityPropagation |
| LassoLars | DecisionTree | Birch |
| BayesianRegression | ExtraTree | AgglomerativeClustering |
| HuberRegression | RandomForest | FeatureAgglomeration |
| Ridge | ExtraTrees | DBSCAN |
| PoissonRegression | SVM | MiniBatchKMeans |
| ARDRegression | LinearSVM | SpectralBiclustering |
| TweedieRegression | NuSVM | SpectralCoclustering |
| TheilSenRegression | NearestNeighbor | SpectralClustering |
| GammaRegression | NeuralNetwork | MeanShift |
| RANSACRegression | PassiveAgressiveClassifier | OPTICS |
| DecisionTree | Perceptron | KMedoids |
| ExtraTree | BernoulliRBM | ---- |
| RandomForest | BoltzmannMachine | ---- |
| ExtraTrees | CalibratedClassifier | ---- |
| SVM | Adaboost | ---- |
| LinearSVM | Bagging | ---- |
| NuSVM | GradientBoosting | ---- |
| NearestNeighbor | BernoulliNaiveBayes | ---- |
| NeuralNetwork | CategoricalNaiveBayes | ---- |
| ElasticNet | ComplementNaiveBayes | ---- |
| BernoulliRBM | GaussianNaiveBayes | ---- |
| BoltzmannMachine | MultinomialNaiveBayes | ---- |
| Adaboost | ---- | ---- |
| Bagging | ---- | ---- |
| GradientBoosting | ---- | ---- |
+--------------------+----------------------------+-------------------------+بالنسبة إلى ML التلقائي:
يعد أمر المساعدة مفيدًا جدًا للتحقق من الأوامر المدعومة والوسيطات/الخيارات المقابلة
$ igel --helpيمكنك أيضًا تشغيل التعليمات على الأوامر الفرعية، على سبيل المثال:
$ igel fit --helpIgel قابل للتخصيص بدرجة كبيرة. إذا كنت تعرف ما تريده وتريد تكوين نموذجك يدويًا، فتحقق من الأقسام التالية، والتي سترشدك حول كيفية كتابة ملف yaml أو ملف تكوين json. بعد ذلك، كل ما عليك فعله هو إخبار igel بما يجب عليك فعله وأين يمكنك العثور على بياناتك وملف التكوين الخاص بك. هنا مثال:
$ igel fit --data_path ' path_to_your_csv_dataset.csv ' --yaml_path ' path_to_your_yaml_file.yaml 'ومع ذلك، يمكنك أيضًا استخدام ميزات القراءة التلقائية والسماح لـ igel بالقيام بكل شيء نيابةً عنك. ومن الأمثلة الرائعة على ذلك تصنيف الصور. لنتخيل أن لديك بالفعل مجموعة بيانات من الصور الأولية المخزنة في مجلد يسمى الصور
كل ما عليك فعله هو تشغيل:
$ igel auto-train --data_path ' path_to_your_images_folder ' --task ImageClassificationهذا كل شيء! سوف يقوم Igel بقراءة الصور من الدليل، ومعالجة مجموعة البيانات (التحويل إلى مصفوفات، وإعادة القياس، والتقسيم، وما إلى ذلك...) والبدء في التدريب/تحسين النموذج الذي يعمل بشكل جيد على بياناتك. كما ترون، الأمر سهل جدًا، كل ما عليك فعله هو توفير المسار إلى بياناتك والمهمة التي تريد تنفيذها.
ملحوظة
هذه الميزة باهظة الثمن من الناحية الحسابية، حيث سيجرب igel العديد من النماذج المختلفة ويقارن أدائها للعثور على النموذج "الأفضل".
يمكنك تشغيل أمر المساعدة للحصول على التعليمات. يمكنك أيضًا تشغيل التعليمات على الأوامر الفرعية!
$ igel --helpالخطوة الأولى هي توفير ملف yaml (يمكنك أيضًا استخدام json إذا أردت)
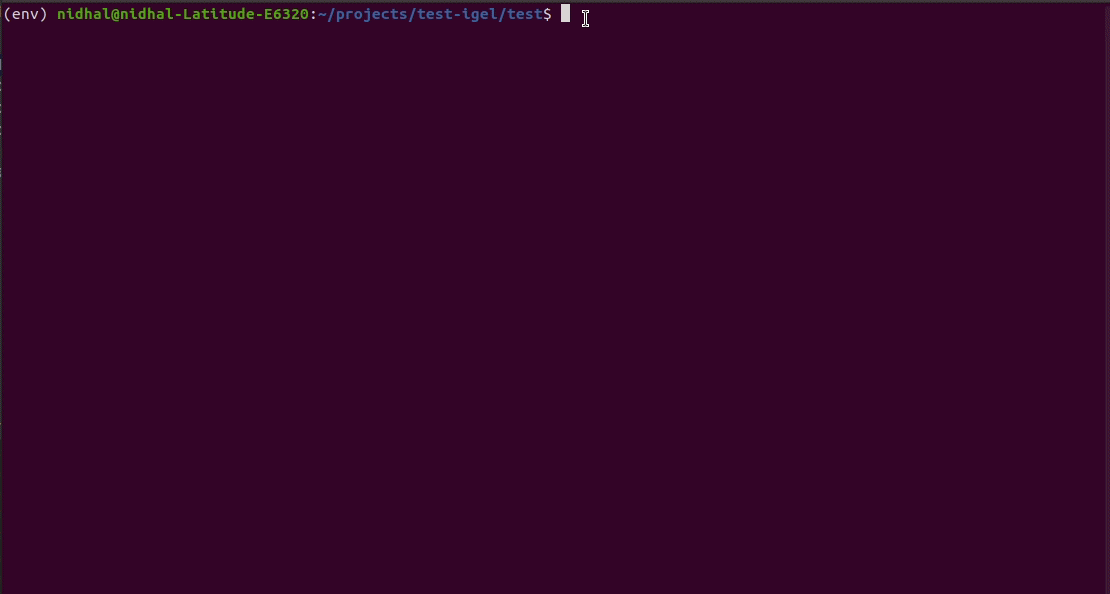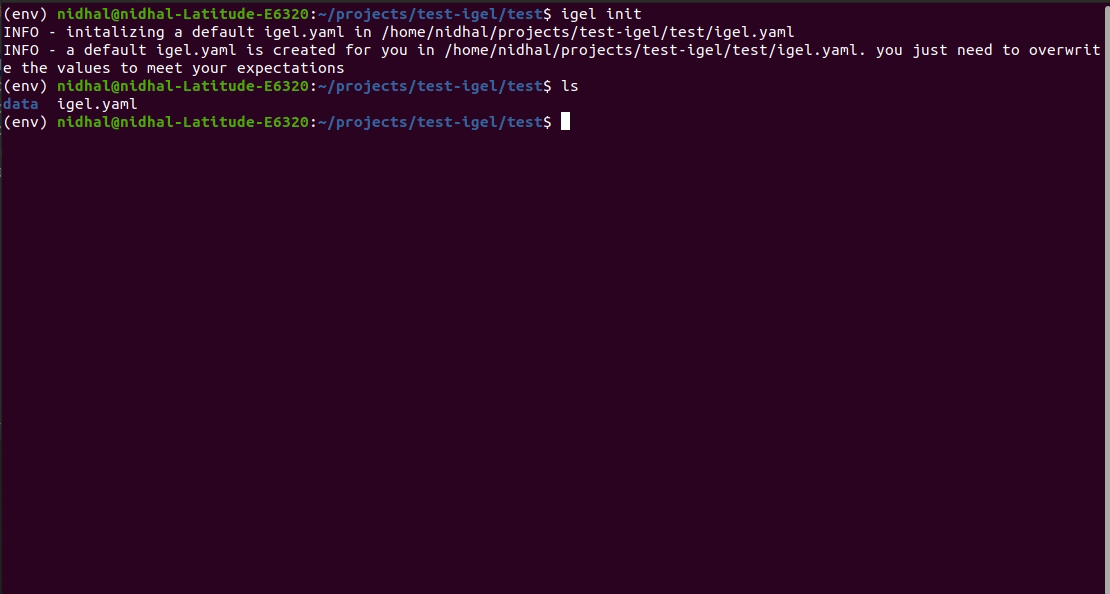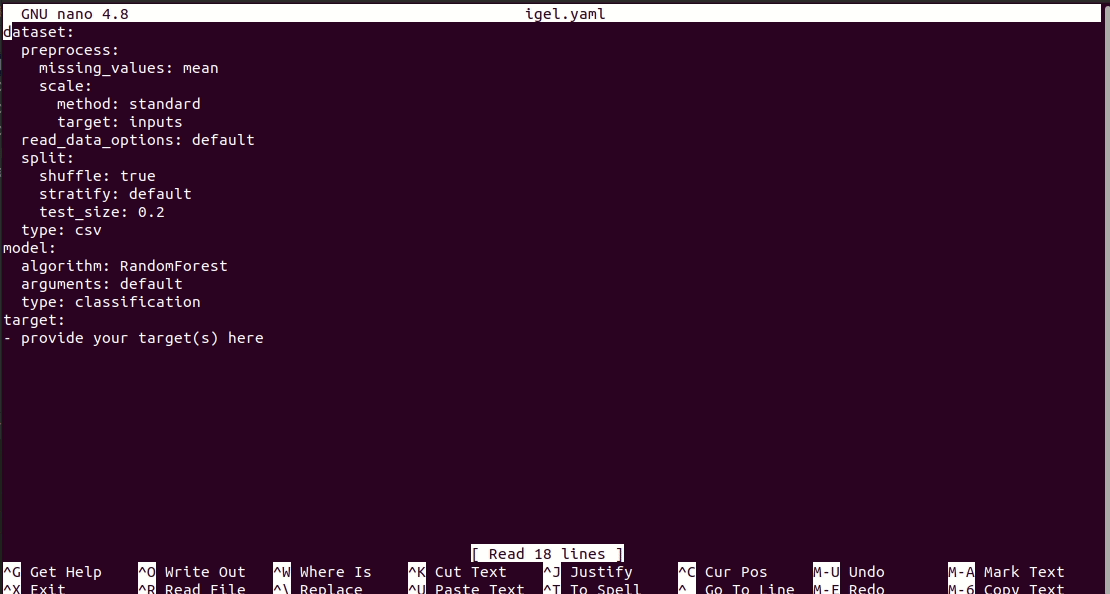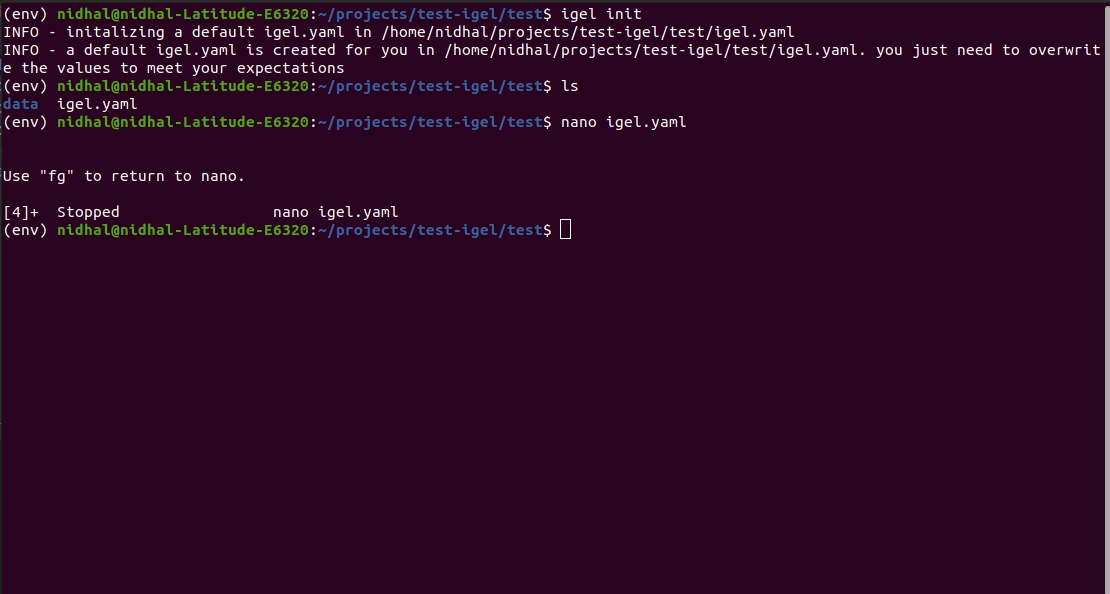
يمكنك القيام بذلك يدويًا عن طريق إنشاء ملف .yaml (يسمى تقليديًا igel.yaml ولكن يمكنك تسمية ما تريد) وتحريره بنفسك. ومع ذلك، إذا كنت كسولًا (وربما تكون كذلك مثلي:D)، فيمكنك استخدام أمر igel init للبدء بسرعة، مما سيؤدي إلى إنشاء ملف تكوين أساسي لك بسرعة.
"""
igel init --help
Example:
If I want to use neural networks to classify whether someone is sick or not using the indian-diabetes dataset,
then I would use this command to initialize a yaml file n.b. you may need to rename outcome column in .csv to sick:
$ igel init -type " classification " -model " NeuralNetwork " -target " sick "
"""
$ igel initبعد تشغيل الأمر، سيتم إنشاء ملف igel.yaml لك في دليل العمل الحالي. يمكنك التحقق من ذلك وتعديله إذا كنت ترغب في ذلك، وإلا يمكنك أيضًا إنشاء كل شيء من الصفر.
# model definition
model :
# in the type field, you can write the type of problem you want to solve. Whether regression, classification or clustering
# Then, provide the algorithm you want to use on the data. Here I'm using the random forest algorithm
type : classification
algorithm : RandomForest # make sure you write the name of the algorithm in pascal case
arguments :
n_estimators : 100 # here, I set the number of estimators (or trees) to 100
max_depth : 30 # set the max_depth of the tree
# target you want to predict
# Here, as an example, I'm using the famous indians-diabetes dataset, where I want to predict whether someone have diabetes or not.
# Depending on your data, you need to provide the target(s) you want to predict here
target :
- sickفي المثال أعلاه، أستخدم غابة عشوائية لتصنيف ما إذا كان شخص ما مصابًا بمرض السكري أم لا اعتمادًا على بعض الميزات الموجودة في مجموعة البيانات التي استخدمت فيها مرض السكري الهندي الشهير في مجموعة بيانات مرض السكري الهندي هذا المثال)
لاحظ أنني قمت بتمرير n_estimators و max_depth كوسيطتين إضافيتين للنموذج. إذا لم تقم بتوفير الوسائط، فسيتم استخدام الوسيط الافتراضي. ليس عليك حفظ الوسائط الخاصة بكل نموذج. يمكنك دائمًا تشغيل igel models في جهازك الطرفي، مما سينقلك إلى الوضع التفاعلي، حيث سيُطلب منك إدخال النموذج الذي تريد استخدامه ونوع المشكلة التي تريد حلها. سيعرض لك Igel بعد ذلك معلومات حول النموذج ورابطًا يمكنك اتباعه لرؤية قائمة بالوسيطات المتاحة وكيفية استخدامها.
قم بتشغيل هذا الأمر في الوحدة الطرفية لملاءمة/تدريب نموذج، حيث يمكنك توفير المسار إلى مجموعة البيانات الخاصة بك والمسار إلى ملف yaml
$ igel fit --data_path ' path_to_your_csv_dataset.csv ' --yaml_path ' path_to_your_yaml_file.yaml '
# or shorter
$ igel fit -dp ' path_to_your_csv_dataset.csv ' -yml ' path_to_your_yaml_file.yaml '
"""
That's it. Your "trained" model can be now found in the model_results folder
(automatically created for you in your current working directory).
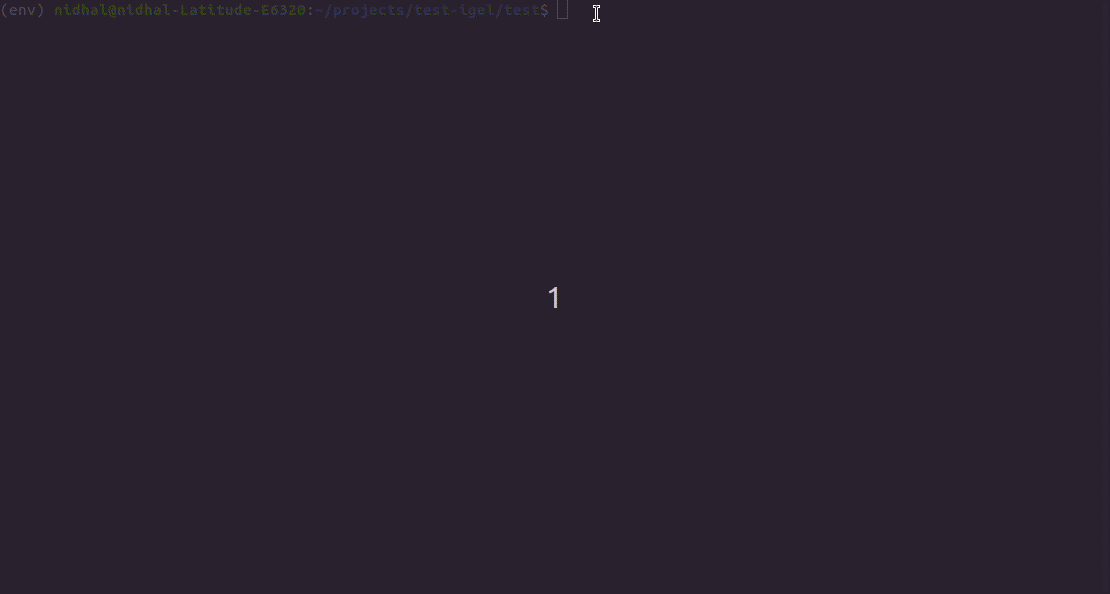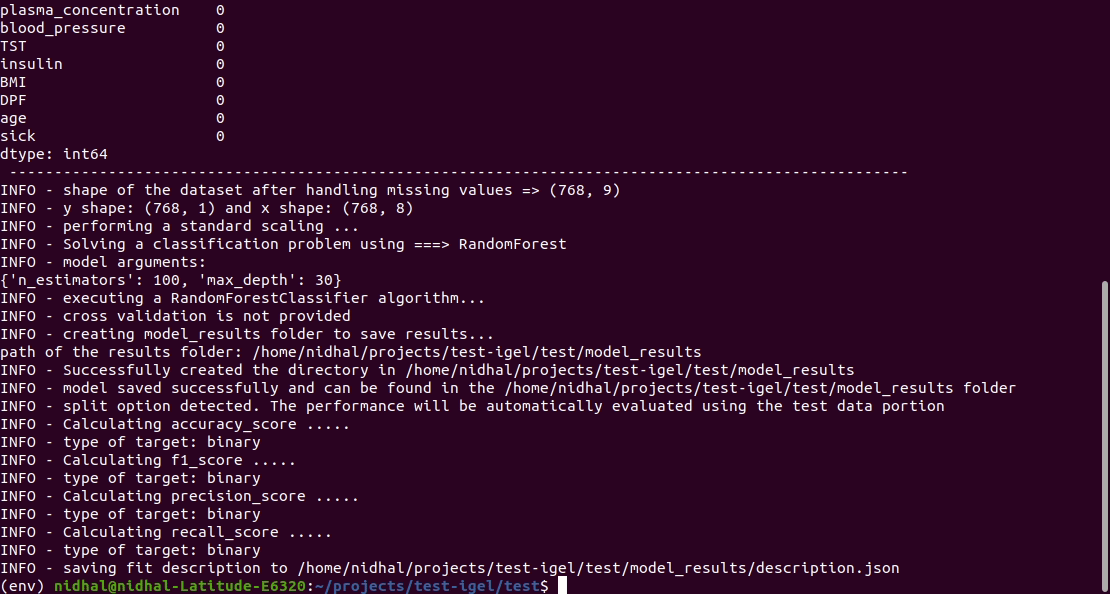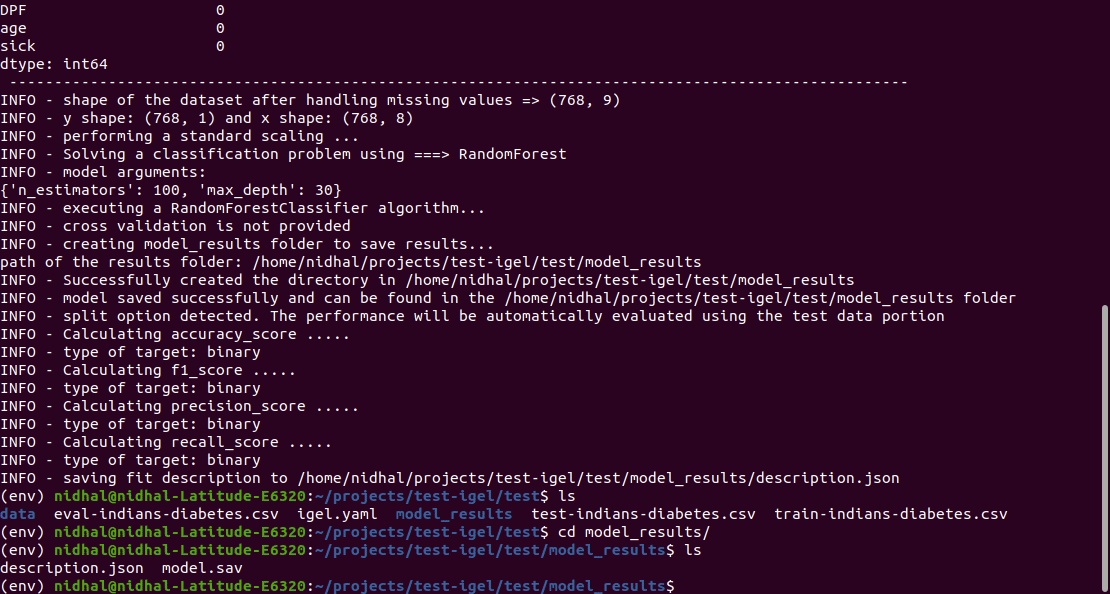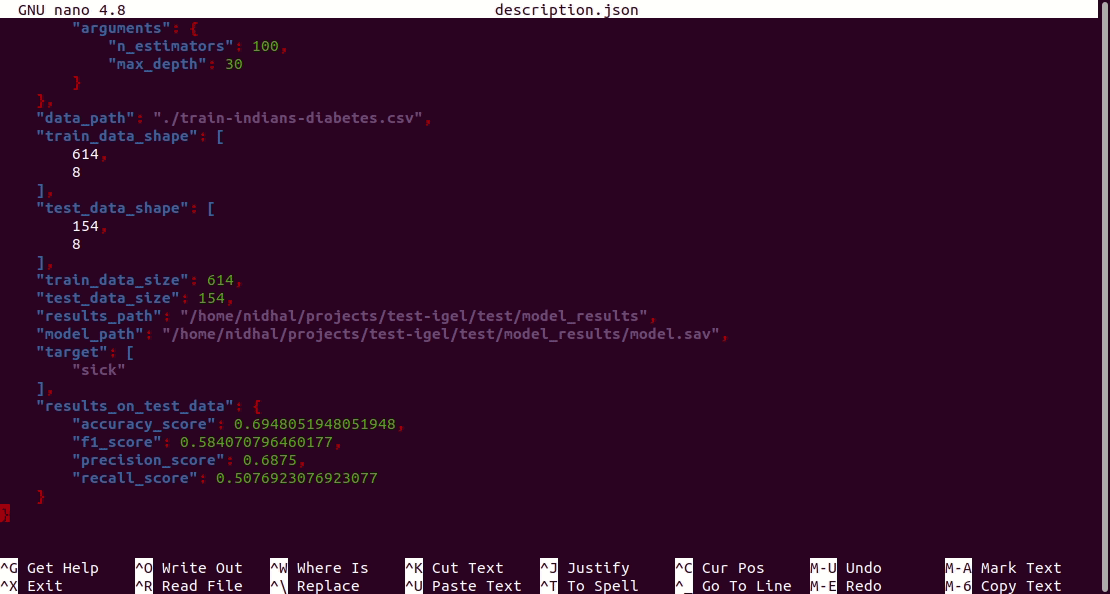
Furthermore, a description can be found in the description.json file inside the model_results folder.
"""
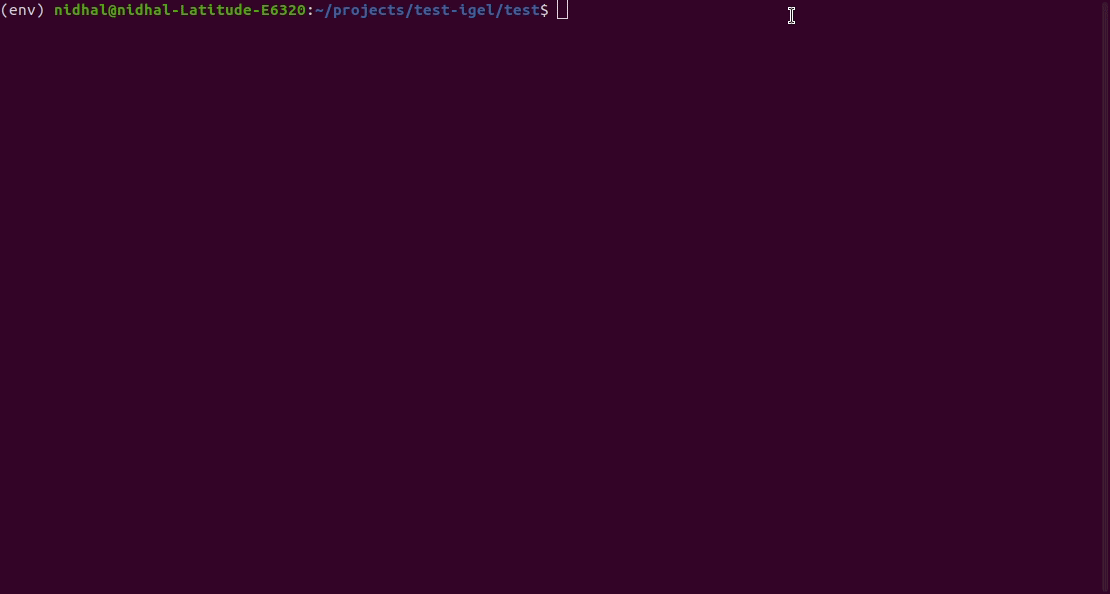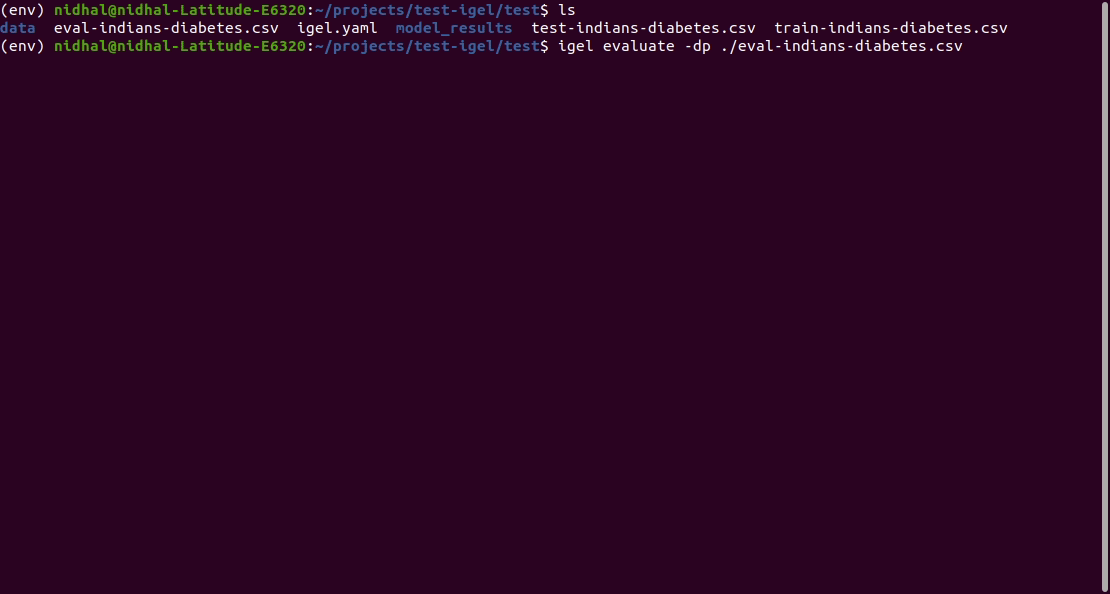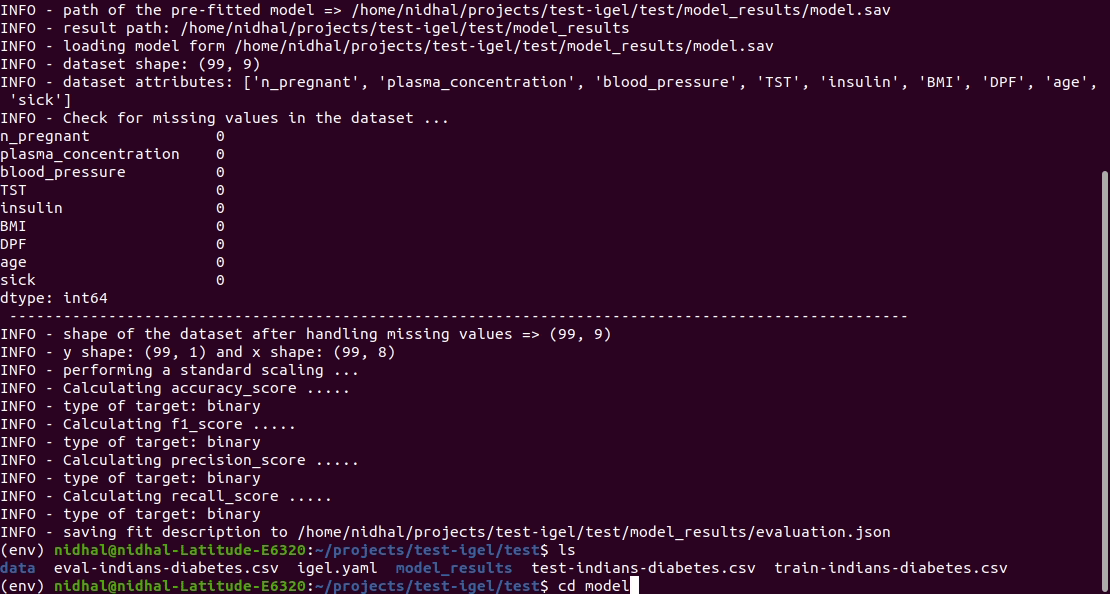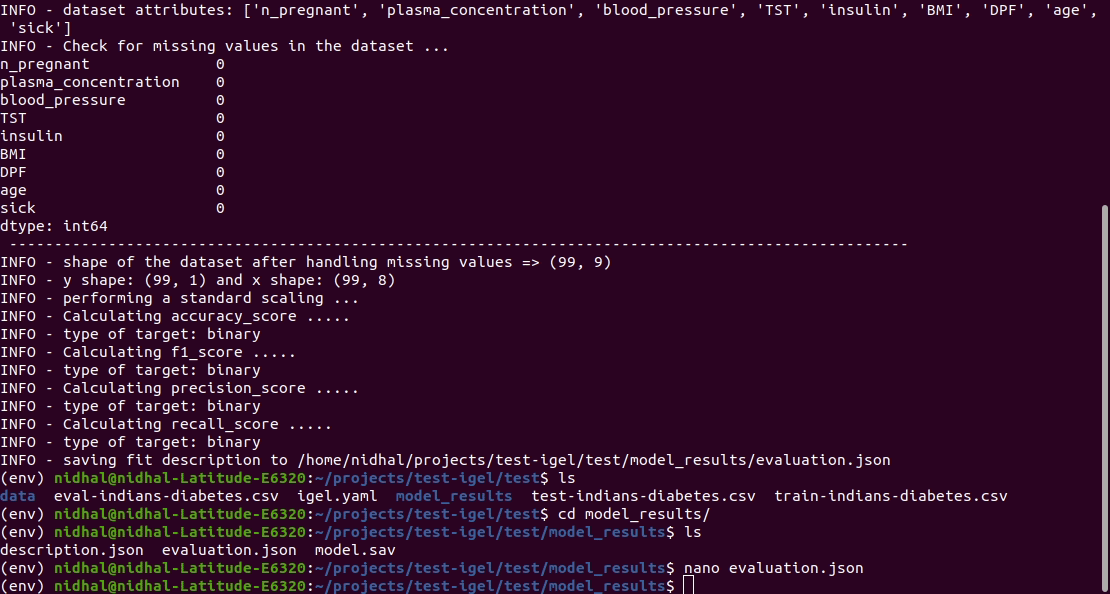
يمكنك بعد ذلك تقييم النموذج المدرب/المجهز مسبقًا:
$ igel evaluate -dp ' path_to_your_evaluation_dataset.csv '
"""
This will automatically generate an evaluation.json file in the current directory, where all evaluation results are stored
"""
وأخيرًا، يمكنك استخدام النموذج المدرب/المجهز مسبقًا لإجراء التنبؤات إذا كنت راضيًا عن نتائج التقييم:
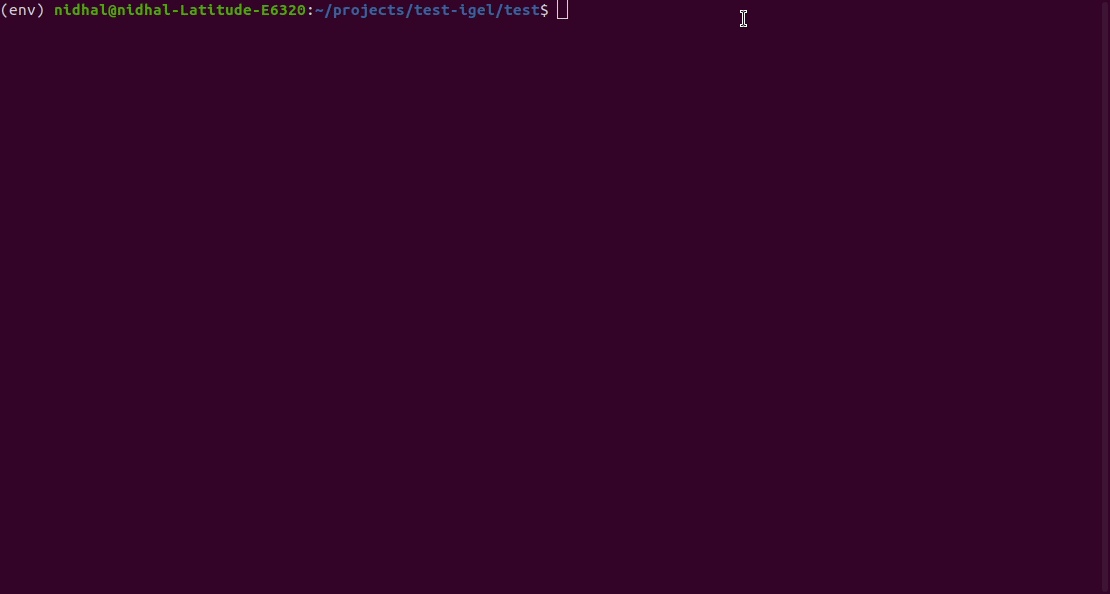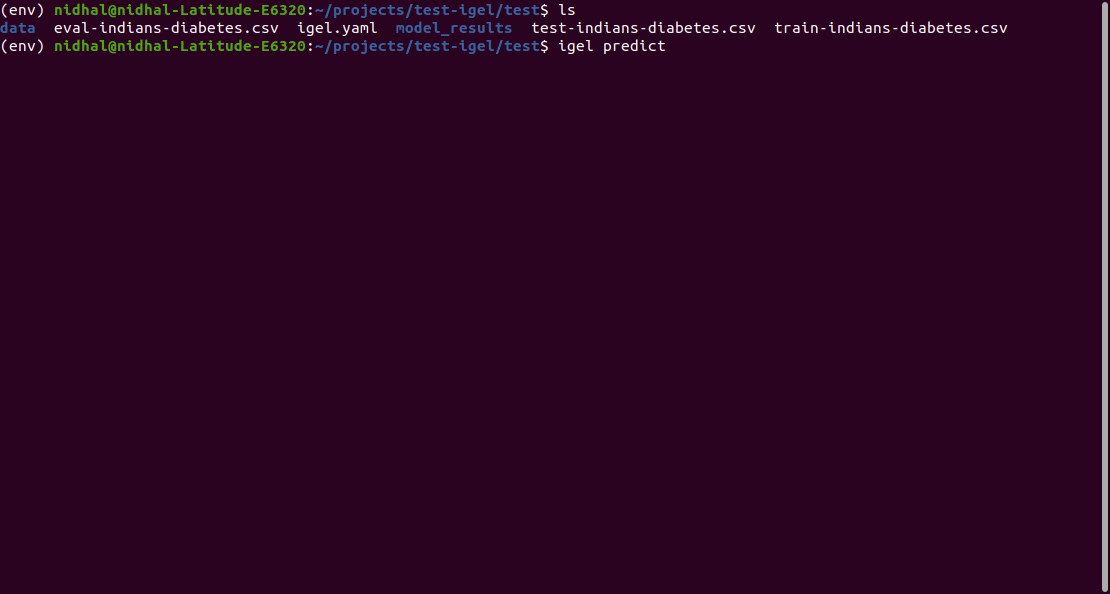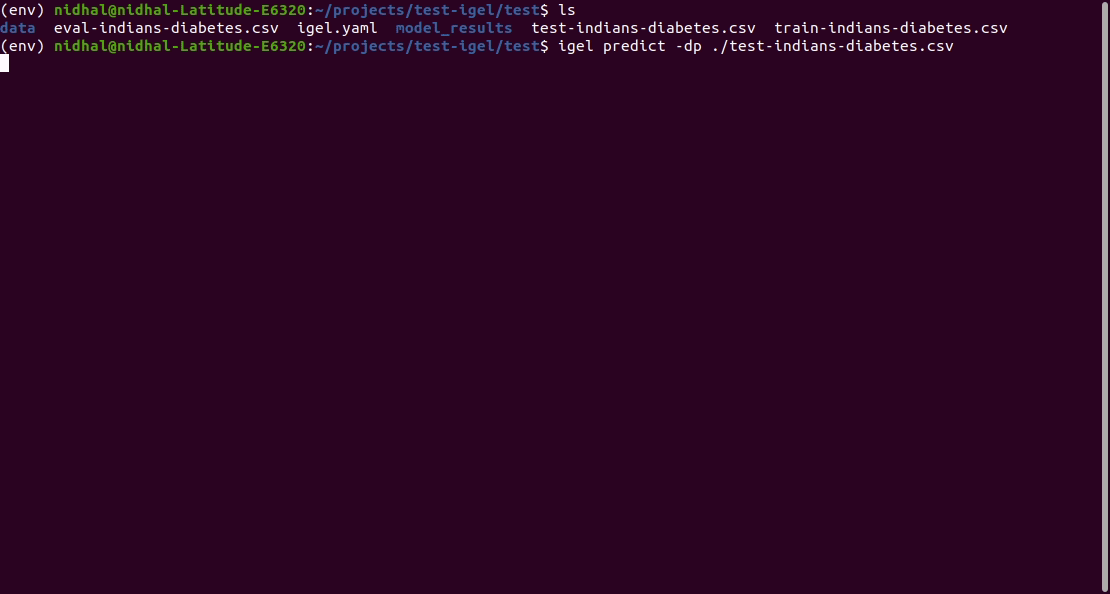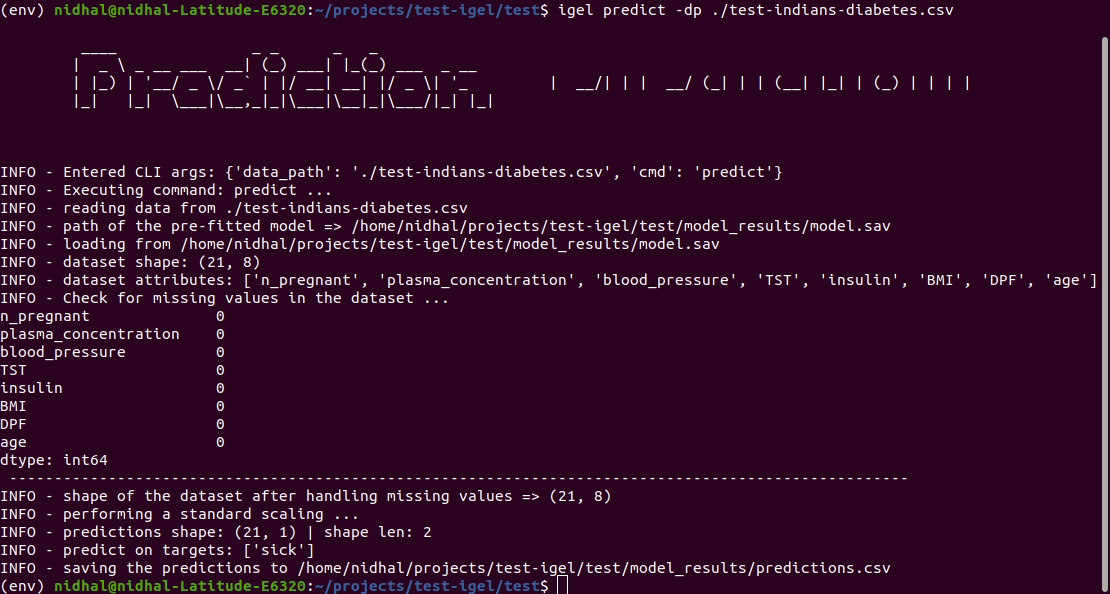
$ igel predict -dp ' path_to_your_test_dataset.csv '
"""
This will generate a predictions.csv file in your current directory, where all predictions are stored in a csv file
"""
يمكنك الجمع بين مراحل التدريب والتقييم والتنبؤ باستخدام أمر واحد يسمى التجربة:
$ igel experiment -DP " path_to_train_data path_to_eval_data path_to_test_data " -yml " path_to_yaml_file "
"""
This will run fit using train_data, evaluate using eval_data and further generate predictions using the test_data
"""
يمكنك تصدير نموذج sklearn المدرّب/المجهز مسبقًا إلى ONNX:
$ igel export -dp " path_to_pre-fitted_sklearn_model "
"""
This will convert the sklearn model into ONNX
""" from igel import Igel
Igel ( cmd = "fit" , data_path = "path_to_your_dataset" , yaml_path = "path_to_your_yaml_file" )
"""
check the examples folder for more
"""الخطوة التالية هي استخدام النموذج الخاص بك في الإنتاج. يساعدك Igel في هذه المهمة أيضًا من خلال توفير أمر الخدمة. سيؤدي تشغيل أمر الخدمة إلى إخبار igel بخدمة النموذج الخاص بك. على وجه التحديد، سيقوم igel تلقائيًا ببناء خادم REST وخدمة النموذج الخاص بك على مضيف ومنفذ محددين، والذي يمكنك تكوينه عن طريق تمريرهما كخيارات cli.
أسهل طريقة هي التشغيل:
$ igel serve --model_results_dir " path_to_model_results_directory "لاحظ أن igel يحتاج إلى خيار --model_results_dir أو قريبًا -res_dir cli من أجل تحميل النموذج وبدء تشغيل الخادم. افتراضيًا، سيخدم igel نموذجك على localhost:8000 ، ومع ذلك، يمكنك تجاوز ذلك بسهولة من خلال توفير خيارات المضيف والمنفذ.
$ igel serve --model_results_dir " path_to_model_results_directory " --host " 127.0.0.1 " --port 8000يستخدم Igel FastAPI لإنشاء خادم REST، وهو إطار عمل حديث عالي الأداء وuvicorn لتشغيله تحت الغطاء.
تم إجراء هذا المثال باستخدام نموذج تم تدريبه مسبقًا (تم إنشاؤه عن طريق تشغيل تصنيف igel init --target Sick-type) ومجموعة بيانات مرض السكري الهندي ضمن الأمثلة/البيانات. رؤوس الأعمدة في ملف CSV الأصلي هي "preg"، و"plas"، و"pres"، و"skin"، و"test"، و"mass"، و"pedi"، و"age".
حليقة:
$ curl -X POST localhost:8080/predict --header " Content-Type:application/json " -d ' {"preg": 1, "plas": 180, "pres": 50, "skin": 12, "test": 1, "mass": 456, "pedi": 0.442, "age": 50} '
Outputs: {"prediction":[[0.0]]}$ curl -X POST localhost:8080/predict --header " Content-Type:application/json " -d ' {"preg": [1, 6, 10], "plas":[192, 52, 180], "pres": [40, 30, 50], "skin": [25, 35, 12], "test": [0, 1, 1], "mass": [456, 123, 155], "pedi": [0.442, 0.22, 0.19], "age": [50, 40, 29]} '
Outputs: {"prediction":[[1.0],[0.0],[0.0]]}التحذيرات/القيود:
مثال لاستخدام عميل بايثون:
from python_client import IgelClient
# the client allows additional args with defaults:
# scheme="http", endpoint="predict", missing_values="mean"
client = IgelClient ( host = 'localhost' , port = 8080 )
# you can post other types of files compatible with what Igel data reading allows
client . post ( "my_batch_file_for_predicting.csv" )
Outputs : < Response 200 > : { "prediction" :[[ 1.0 ],[ 0.0 ],[ 0.0 ]]}الهدف الرئيسي من igel هو تزويدك بطريقة لتدريب/ملاءمة النماذج وتقييمها واستخدامها دون كتابة التعليمات البرمجية. بدلاً من ذلك، كل ما تحتاجه هو تقديم/وصف ما تريد القيام به في ملف yaml بسيط.
بشكل أساسي، يمكنك تقديم وصف أو تكوينات في ملف yaml كأزواج قيمة رئيسية. فيما يلي نظرة عامة على جميع التكوينات المدعومة (في الوقت الحالي):
# dataset operations
dataset :
type : csv # [str] -> type of your dataset
read_data_options : # options you want to supply for reading your data (See the detailed overview about this in the next section)
sep : # [str] -> Delimiter to use.
delimiter : # [str] -> Alias for sep.
header : # [int, list of int] -> Row number(s) to use as the column names, and the start of the data.
names : # [list] -> List of column names to use
index_col : # [int, str, list of int, list of str, False] -> Column(s) to use as the row labels of the DataFrame,
usecols : # [list, callable] -> Return a subset of the columns
squeeze : # [bool] -> If the parsed data only contains one column then return a Series.
prefix : # [str] -> Prefix to add to column numbers when no header, e.g. ‘X’ for X0, X1, …
mangle_dupe_cols : # [bool] -> Duplicate columns will be specified as ‘X’, ‘X.1’, …’X.N’, rather than ‘X’…’X’. Passing in False will cause data to be overwritten if there are duplicate names in the columns.
dtype : # [Type name, dict maping column name to type] -> Data type for data or columns
engine : # [str] -> Parser engine to use. The C engine is faster while the python engine is currently more feature-complete.
converters : # [dict] -> Dict of functions for converting values in certain columns. Keys can either be integers or column labels.
true_values : # [list] -> Values to consider as True.
false_values : # [list] -> Values to consider as False.
skipinitialspace : # [bool] -> Skip spaces after delimiter.
skiprows : # [list-like] -> Line numbers to skip (0-indexed) or number of lines to skip (int) at the start of the file.
skipfooter : # [int] -> Number of lines at bottom of file to skip
nrows : # [int] -> Number of rows of file to read. Useful for reading pieces of large files.
na_values : # [scalar, str, list, dict] -> Additional strings to recognize as NA/NaN.
keep_default_na : # [bool] -> Whether or not to include the default NaN values when parsing the data.
na_filter : # [bool] -> Detect missing value markers (empty strings and the value of na_values). In data without any NAs, passing na_filter=False can improve the performance of reading a large file.
verbose : # [bool] -> Indicate number of NA values placed in non-numeric columns.
skip_blank_lines : # [bool] -> If True, skip over blank lines rather than interpreting as NaN values.
parse_dates : # [bool, list of int, list of str, list of lists, dict] -> try parsing the dates
infer_datetime_format : # [bool] -> If True and parse_dates is enabled, pandas will attempt to infer the format of the datetime strings in the columns, and if it can be inferred, switch to a faster method of parsing them.
keep_date_col : # [bool] -> If True and parse_dates specifies combining multiple columns then keep the original columns.
dayfirst : # [bool] -> DD/MM format dates, international and European format.
cache_dates : # [bool] -> If True, use a cache of unique, converted dates to apply the datetime conversion.
thousands : # [str] -> the thousands operator
decimal : # [str] -> Character to recognize as decimal point (e.g. use ‘,’ for European data).
lineterminator : # [str] -> Character to break file into lines.
escapechar : # [str] -> One-character string used to escape other characters.
comment : # [str] -> Indicates remainder of line should not be parsed. If found at the beginning of a line, the line will be ignored altogether. This parameter must be a single character.
encoding : # [str] -> Encoding to use for UTF when reading/writing (ex. ‘utf-8’).
dialect : # [str, csv.Dialect] -> If provided, this parameter will override values (default or not) for the following parameters: delimiter, doublequote, escapechar, skipinitialspace, quotechar, and quoting
delim_whitespace : # [bool] -> Specifies whether or not whitespace (e.g. ' ' or ' ') will be used as the sep
low_memory : # [bool] -> Internally process the file in chunks, resulting in lower memory use while parsing, but possibly mixed type inference.
memory_map : # [bool] -> If a filepath is provided for filepath_or_buffer, map the file object directly onto memory and access the data directly from there. Using this option can improve performance because there is no longer any I/O overhead.
random_numbers : # random numbers options in case you wanted to generate the same random numbers on each run
generate_reproducible : # [bool] -> set this to true to generate reproducible results
seed : # [int] -> the seed number is optional. A seed will be set up for you if you didn't provide any
split : # split options
test_size : 0.2 # [float] -> 0.2 means 20% for the test data, so 80% are automatically for training
shuffle : true # [bool] -> whether to shuffle the data before/while splitting
stratify : None # [list, None] -> If not None, data is split in a stratified fashion, using this as the class labels.
preprocess : # preprocessing options
missing_values : mean # [str] -> other possible values: [drop, median, most_frequent, constant] check the docs for more
encoding :
type : oneHotEncoding # [str] -> other possible values: [labelEncoding]
scale : # scaling options
method : standard # [str] -> standardization will scale values to have a 0 mean and 1 standard deviation | you can also try minmax
target : inputs # [str] -> scale inputs. | other possible values: [outputs, all] # if you choose all then all values in the dataset will be scaled
# model definition
model :
type : classification # [str] -> type of the problem you want to solve. | possible values: [regression, classification, clustering]
algorithm : NeuralNetwork # [str (notice the pascal case)] -> which algorithm you want to use. | type igel algorithms in the Terminal to know more
arguments : # model arguments: you can check the available arguments for each model by running igel help in your terminal
use_cv_estimator : false # [bool] -> if this is true, the CV class of the specific model will be used if it is supported
cross_validate :
cv : # [int] -> number of kfold (default 5)
n_jobs : # [signed int] -> The number of CPUs to use to do the computation (default None)
verbose : # [int] -> The verbosity level. (default 0)
hyperparameter_search :
method : grid_search # method you want to use: grid_search and random_search are supported
parameter_grid : # put your parameters grid here that you want to use, an example is provided below
param1 : [val1, val2]
param2 : [val1, val2]
arguments : # additional arguments you want to provide for the hyperparameter search
cv : 5 # number of folds
refit : true # whether to refit the model after the search
return_train_score : false # whether to return the train score
verbose : 0 # verbosity level
# target you want to predict
target : # list of strings: basically put here the column(s), you want to predict that exist in your csv dataset
- put the target you want to predict here
- you can assign many target if you are making a multioutput prediction ملحوظة
يستخدم Igel حيوانات الباندا تحت الغطاء لقراءة البيانات وتحليلها. وبالتالي، يمكنك العثور على المعلمات الاختيارية لهذه البيانات أيضًا في الوثائق الرسمية للباندا.
نظرة عامة مفصلة على التكوينات التي يمكنك تقديمها في ملف yaml (أو json) موضحة أدناه. لاحظ أنك بالتأكيد لن تحتاج إلى جميع قيم التكوين لمجموعة البيانات. فهي اختيارية. بشكل عام، سيكتشف igel كيفية قراءة مجموعة البيانات الخاصة بك.
ومع ذلك، يمكنك المساعدة في ذلك من خلال توفير حقول إضافية باستخدام قسم read_data_options هذا. على سبيل المثال، إحدى القيم المفيدة في رأيي هي "sep"، والتي تحدد كيفية فصل الأعمدة في مجموعة بيانات CSV. بشكل عام، يتم فصل مجموعات بيانات CSV بفواصل، وهي أيضًا القيمة الافتراضية هنا. ومع ذلك، قد يتم فصلها بفاصلة منقوطة في حالتك.
ومن ثم، يمكنك توفير ذلك في read_data_options. فقط أضف sep: ";" ضمن read_data_options.
| المعلمة | يكتب | توضيح |
|---|---|---|
| سبتمبر | شارع، الافتراضي '،' | محدد للاستخدام. إذا كانت قيمة sep هي لا شيء، فلن يتمكن محرك C من اكتشاف الفاصل تلقائيًا، لكن محرك تحليل Python يمكنه ذلك، مما يعني أنه سيتم استخدام الأخير واكتشاف الفاصل تلقائيًا بواسطة أداة الشم المدمجة في Python، csv.Sniffer. بالإضافة إلى ذلك، سيتم تفسير الفواصل الأطول من حرف واحد والمختلفة عن 's+' على أنها تعبيرات عادية وستفرض أيضًا استخدام محرك التحليل Python. لاحظ أن محددات regex عرضة لتجاهل البيانات المقتبسة. مثال Regex: "rt". |
| محدد | الافتراضي لا شيء | الاسم المستعار لسبتمبر. |
| header | كثافة العمليات، قائمة كثافة العمليات، الافتراضي "استنتاج" | رقم (أرقام) الصفوف المراد استخدامها كأسماء الأعمدة وبداية البيانات. السلوك الافتراضي هو استنتاج أسماء الأعمدة: إذا لم يتم تمرير أي أسماء، يكون السلوك مطابقًا للرأس=0 ويتم استنتاج أسماء الأعمدة من السطر الأول من الملف، وإذا تم تمرير أسماء الأعمدة بشكل صريح، فسيكون السلوك مطابقًا للرأس=لا شيء . قم بتمرير header=0 بشكل صريح لتتمكن من استبدال الأسماء الموجودة. يمكن أن يكون الرأس عبارة عن قائمة من الأعداد الصحيحة التي تحدد مواقع الصفوف لفهارس متعددة على الأعمدة، على سبيل المثال [0,1,3]. سيتم تخطي الصفوف المتداخلة التي لم يتم تحديدها (على سبيل المثال، تم تخطي 2 في هذا المثال). لاحظ أن هذه المعلمة تتجاهل الأسطر التي تم التعليق عليها والأسطر الفارغة إذا كان Skip_blank_lines=True، لذا فإن الرأس = 0 يشير إلى السطر الأول من البيانات بدلاً من السطر الأول من الملف. |
| أسماء | مثل المصفوفة، اختياري | قائمة بأسماء الأعمدة المراد استخدامها. إذا كان الملف يحتوي على صف رأس، فيجب عليك تمرير header=0 بشكل صريح لتجاوز أسماء الأعمدة. التكرارات في هذه القائمة غير مسموح بها. |
| Index_col | int، str، تسلسل int / str، أو False، الافتراضي لا شيء | العمود (الأعمدة) الذي سيتم استخدامه كتسميات صفوف لـ DataFrame، إما يتم تقديمه كاسم سلسلة أو فهرس عمود. إذا تم إعطاء تسلسل int / str، فسيتم استخدام MultiIndex. ملاحظة: يمكن استخدام Index_col=False لإجبار الباندا على عدم استخدام العمود الأول كفهرس، على سبيل المثال، عندما يكون لديك ملف مشوه بمحددات في نهاية كل سطر. |
| com.usecols | تشبه القائمة أو قابلة للاستدعاء، اختيارية | إرجاع مجموعة فرعية من الأعمدة. إذا كانت تشبه القائمة، فيجب أن تكون جميع العناصر إما موضعية (أي مؤشرات صحيحة في أعمدة المستند) أو سلاسل تتوافق مع أسماء الأعمدة المقدمة إما من قبل المستخدم في الأسماء أو يتم استنتاجها من صف (صفوف) رأس المستند. على سبيل المثال، قد تكون معلمة usecols الصالحة المشابهة للقائمة هي [0, 1, 2] أو ['foo', 'bar', 'baz']. يتم تجاهل ترتيب العناصر، لذا فإن usecols=[0, 1] هو نفسه [1, 0]. لإنشاء مثيل DataFrame من البيانات مع الحفاظ على ترتيب العناصر، استخدم pd.read_csv(data, usecols=['foo', 'bar'])[['foo', 'bar']] للأعمدة الموجودة في ['foo', 'bar '] order أو pd.read_csv(data, usecols=['foo', 'bar'])[['bar', 'foo']] لـ ['bar', 'foo'] أمر. إذا كانت قابلة للاستدعاء، فسيتم تقييم الوظيفة القابلة للاستدعاء مقابل أسماء الأعمدة، مما يؤدي إلى إرجاع الأسماء حيث يتم تقييم الوظيفة القابلة للاستدعاء إلى True. مثال على وسيطة صالحة للاستدعاء سيكون lambda x: x.upper() في ['AAA', 'BBB', 'DDD']. يؤدي استخدام هذه المعلمة إلى وقت تحليل أسرع بكثير واستخدام أقل للذاكرة. |
| ضغط | منطقي، افتراضي خطأ | إذا كانت البيانات التي تم تحليلها تحتوي على عمود واحد فقط، فقم بإرجاع سلسلة. |
| بادئة | شارع، اختياري | بادئة للإضافة إلى أرقام الأعمدة في حالة عدم وجود رأس، على سبيل المثال "X" لـ X0، X1، ... |
| mangle_dupe_cols | منطقي، الافتراضي صحيح | سيتم تحديد الأعمدة المكررة كـ 'X'، 'X.1'، …'X.N'، بدلاً من 'X'...'X'. سيؤدي التمرير خطأ إلى الكتابة فوق البيانات في حالة وجود أسماء مكررة في الأعمدة. |
| dtype | {'ج'، 'بيثون'}، اختياري | محرك محلل للاستخدام. يعد المحرك C أسرع بينما يكون محرك python حاليًا أكثر اكتمالاً للميزات. |
| المحولات | إملاء، اختياري | إملاء الوظائف لتحويل القيم في أعمدة معينة. يمكن أن تكون المفاتيح أعدادًا صحيحة أو تسميات أعمدة. |
| true_values | القائمة، اختيارية | القيم التي يجب اعتبارها صحيحة. |
| false_values | القائمة، اختيارية | القيم التي يجب اعتبارها خاطئة. |
| hackinitialspace | منطقي، افتراضي خطأ | تخطي المسافات بعد المحدد. |
| تخطي | يشبه القائمة، int أو قابل للاستدعاء، اختياري | أرقام الأسطر التي يجب تخطيها (0-فهرسة) أو عدد الأسطر التي يجب تخطيها (int) في بداية الملف. إذا كانت قابلة للاستدعاء، فسيتم تقييم الدالة القابلة للاستدعاء مقابل فهارس الصفوف، وإرجاع True إذا كان يجب تخطي الصف وخطأ بخلاف ذلك. مثال على وسيطة صالحة للاستدعاء سيكون lambda x: x in [0, 2]. |
| com.skipfooter | إنت، الافتراضي 0 | عدد الأسطر الموجودة أسفل الملف المطلوب تخطيها (غير مدعوم مع المحرك='c'). |
| nrows | كثافة العمليات، اختياري | عدد صفوف الملف المراد قراءتها. مفيد لقراءة أجزاء من الملفات الكبيرة. |
| na_values | عددي، str، يشبه القائمة، أو dict، اختياري | سلاسل إضافية للتعرف عليها كـ NA/NaN. إذا تم تمرير الإملاء، قيم NA محددة لكل عمود. افتراضيًا، يتم تفسير القيم التالية على أنها NaN: ''، '#N/A'، '#N/AN/A'، '#NA'، '-1.#IND'، '-1.#QNAN'، '-NaN'، '-nan'، '1.#IND'، '1.#QNAN'، '<NA>'، 'N/A'، 'NA'، 'NULL'، 'NaN'، 'n / أ'، 'نان'، 'باطل'. |
| keep_default_na | منطقي، الافتراضي صحيح | ما إذا كان سيتم تضمين قيم NaN الافتراضية أم لا عند تحليل البيانات. اعتمادًا على ما إذا تم تمرير na_values، يكون السلوك كما يلي: إذا كانت قيمة keep_default_na صحيحة، وتم تحديد na_values، فسيتم إلحاق na_values بقيم NaN الافتراضية المستخدمة للتحليل. إذا كانت قيمة keep_default_na صحيحة، ولم يتم تحديد na_values، فسيتم استخدام قيم NaN الافتراضية فقط للتحليل. إذا كانت قيمة keep_default_na False، وتم تحديد na_values، فسيتم استخدام قيم NaN المحددة فقط لـ na_values للتحليل. إذا كانت قيمة keep_default_na False، ولم يتم تحديد na_values، فلن يتم تحليل أي سلاسل على أنها NaN. لاحظ أنه إذا تم تمرير na_filter كـ False، فسيتم تجاهل المعلمات keep_default_na وna_values. |
| na_filter | منطقي، صحيح الافتراضي | كشف علامات القيمة المفقودة (السلاسل الفارغة وقيمة na_values). في البيانات التي لا تحتوي على أي NAs، يمكن أن يؤدي تمرير na_filter=False إلى تحسين أداء قراءة ملف كبير. |
| مطول | منطقي، افتراضي خطأ | الإشارة إلى عدد قيم NA الموضوعة في أعمدة غير رقمية. |
| Skip_blank_lines | منطقي، الافتراضي صحيح | إذا كان True، قم بتخطي الأسطر الفارغة بدلاً من تفسيرها كقيم NaN. |
| parse_dates | منطقي أو قائمة int أو أسماء أو قائمة قوائم أو dict، افتراضي False | السلوك كما يلي: منطقي. إذا كان صحيحًا -> حاول تحليل ملف Index. قائمة int أو الأسماء. على سبيل المثال، إذا كان [1، 2، 3] -> حاول تحليل الأعمدة 1، 2، 3 كعمود تاريخ منفصل. قائمة القوائم. على سبيل المثال، إذا [[1، 3]] -> قم بدمج العمودين 1 و3 وتحليلهما كعمود تاريخ واحد. dict، على سبيل المثال {'foo' : [1, 3]} -> تحليل الأعمدة 1 و 3 كتاريخ واستدعاء النتيجة "foo" إذا كان لا يمكن تمثيل عمود أو فهرس كمصفوفة من أوقات التاريخ، على سبيل المثال بسبب قيمة غير قابلة للتحليل أو مزيج من المناطق الزمنية، سيتم إرجاع العمود أو الفهرس دون تغيير كنوع بيانات كائن. |
| infer_datetime_format | منطقي، افتراضي خطأ | إذا تم تمكين True وparse_dates، فستحاول الباندا استنتاج تنسيق سلاسل التاريخ والوقت في الأعمدة، وإذا كان من الممكن استنتاجها، فانتقل إلى طريقة أسرع لتحليلها. في بعض الحالات يمكن أن يؤدي ذلك إلى زيادة سرعة التحليل بمقدار 5-10x. |
| keep_date_col | منطقي، افتراضي خطأ | إذا كان True وparse_dates يحددان دمج أعمدة متعددة، فاحتفظ بالأعمدة الأصلية. |
| date_parser | وظيفة، اختيارية | دالة يتم استخدامها لتحويل سلسلة من أعمدة السلسلة إلى مصفوفة من مثيلات التاريخ والوقت. يستخدم الإعداد الافتراضي dateutil.parser.parser لإجراء التحويل. ستحاول Pandas استدعاء date_parser بثلاث طرق مختلفة، والتقدم إلى الطريقة التالية في حالة حدوث استثناء: 1) تمرير مصفوفة واحدة أو أكثر (كما هو محدد بواسطة parse_dates) كوسيطات؛ 2) قم بتسلسل (حسب الصف) قيم السلسلة من الأعمدة المحددة بواسطة parse_dates في مصفوفة واحدة وتمريرها؛ و3) استدعاء date_parser مرة واحدة لكل صف باستخدام سلسلة واحدة أو أكثر (المقابلة للأعمدة المحددة بواسطة parse_dates) كوسائط. |
| dayfirst | منطقي، افتراضي خطأ | تواريخ بتنسيق DD/MM، والتنسيق الدولي والأوروبي. |
| Cache_dates | منطقي، الافتراضي صحيح | إذا كان True، فاستخدم ذاكرة تخزين مؤقت للتواريخ المحولة الفريدة لتطبيق تحويل التاريخ والوقت. قد ينتج عنه تسريع كبير عند تحليل سلاسل التاريخ المكررة، خاصة تلك التي تحتوي على إزاحات المنطقة الزمنية. |
| الآلاف | شارع، اختياري | فاصل الآلاف. |
| عشري | شارع، الافتراضي '.' | الحرف الذي سيتم التعرف عليه كنقطة عشرية (على سبيل المثال، استخدم "،" للبيانات الأوروبية). |
| com.lineterminator | str (الطول 1)، اختياري | حرف لتقسيم الملف إلى أسطر. صالحة فقط مع المحلل اللغوي C. |
| com.escapechar | str (الطول 1)، اختياري | سلسلة مكونة من حرف واحد تستخدم للهروب من الأحرف الأخرى. |
| تعليق | شارع، اختياري | يشير إلى أنه لا ينبغي تحليل بقية السطر. إذا تم العثور عليه في بداية السطر، فسيتم تجاهل السطر تمامًا. |
| ترميز | شارع، اختياري | الترميز الذي سيتم استخدامه لـ UTF عند القراءة/الكتابة (على سبيل المثال "utf-8"). |
| لهجة | str أو csv.Dialect، اختياري | إذا تم توفيرها، فستتجاوز هذه المعلمة القيم (افتراضية أم لا) للمعلمات التالية: المحدد، وعلامة الاقتباس المزدوجة، ورمز الهروب، ومسافة التخطي، ورمز الاقتباس، والاقتباس |
| low_memory | منطقي، الافتراضي صحيح | معالجة الملف داخليًا على شكل أجزاء، مما يؤدي إلى تقليل استخدام الذاكرة أثناء التحليل، ولكن من المحتمل أن يكون هناك استنتاج مختلط من النوع. للتأكد من عدم وجود أنواع مختلطة، قم بتعيين False، أو حدد النوع باستخدام المعلمة dtype. لاحظ أنه تتم قراءة الملف بأكمله في DataFrame واحد بغض النظر، |
| Memory_map | منطقي، افتراضي خطأ | قم بتعيين كائن الملف مباشرة على الذاكرة والوصول إلى البيانات مباشرة من هناك. يمكن أن يؤدي استخدام هذا الخيار إلى تحسين الأداء لأنه لم يعد هناك أي حمل إضافي للإدخال/الإخراج. |
يتم توفير حل كامل من البداية إلى النهاية في هذا القسم لإثبات قدرات igel . كما شرحنا سابقًا، أنت بحاجة إلى إنشاء ملف تكوين yaml. فيما يلي مثال شامل للتنبؤ بما إذا كان شخص ما مصابًا بمرض السكري أم لا باستخدام خوارزمية شجرة القرار . يمكن العثور على مجموعة البيانات في مجلد الأمثلة.
model :
type : classification
algorithm : DecisionTree
target :
- sick $ igel fit -dp path_to_the_dataset -yml path_to_the_yaml_fileهذا كل شيء، سوف يقوم igel الآن بملاءمة النموذج لك وحفظه في مجلد model_results في دليلك الحالي.
تقييم النموذج المجهز مسبقًا. سيقوم Igel بتحميل النموذج المجهز مسبقًا من دليل model_results وتقييمه لك. كل ما عليك فعله هو تشغيل أمر التقييم وتوفير المسار لبيانات التقييم الخاصة بك.
$ igel evaluate -dp path_to_the_evaluation_datasetهذا كل شيء! سيقوم Igel بتقييم النموذج وتخزين الإحصائيات/النتائج في ملف Evaluation.json داخل المجلد model_results
استخدم النموذج المجهز مسبقًا للتنبؤ بالبيانات الجديدة. يتم ذلك تلقائيًا بواسطة igel، ما عليك سوى توفير المسار إلى بياناتك التي تريد استخدام التنبؤ عليها.
$ igel predict -dp path_to_the_new_datasetهذا كل شيء! سيستخدم Igel النموذج المجهز مسبقًا لإجراء التنبؤات وحفظه في ملف التنبؤات.csv داخل المجلد model_results
يمكنك أيضًا تنفيذ بعض طرق المعالجة المسبقة أو العمليات الأخرى من خلال توفيرها في ملف yaml. فيما يلي مثال، حيث تم تقسيم البيانات إلى 80% للتدريب و20% للتحقق/الاختبار. كما يتم خلط البيانات أثناء التقسيم.
علاوة على ذلك، تتم معالجة البيانات مسبقًا عن طريق استبدال القيم المفقودة بالمتوسط (يمكنك أيضًا استخدام الوسيط والوضع وما إلى ذلك.). تحقق من هذا الرابط لمزيد من المعلومات
# dataset operations
dataset :
split :
test_size : 0.2
shuffle : True
stratify : default
preprocess : # preprocessing options
missing_values : mean # other possible values: [drop, median, most_frequent, constant] check the docs for more
encoding :
type : oneHotEncoding # other possible values: [labelEncoding]
scale : # scaling options
method : standard # standardization will scale values to have a 0 mean and 1 standard deviation | you can also try minmax
target : inputs # scale inputs. | other possible values: [outputs, all] # if you choose all then all values in the dataset will be scaled
# model definition
model :
type : classification
algorithm : RandomForest
arguments :
# notice that this is the available args for the random forest model. check different available args for all supported models by running igel help
n_estimators : 100
max_depth : 20
# target you want to predict
target :
- sickبعد ذلك، يمكنك ملاءمة النموذج عن طريق تشغيل أمر igel كما هو موضح في الأمثلة الأخرى
$ igel fit -dp path_to_the_dataset -yml path_to_the_yaml_fileللتقييم
$ igel evaluate -dp path_to_the_evaluation_datasetللإنتاج
$ igel predict -dp path_to_the_new_dataset في مجلد الأمثلة الموجود في المستودع، ستجد مجلد بيانات، حيث يتم تخزين مجموعات بيانات Indian-diabetes الشهيرة ومجموعة بيانات iris وlinnerud (من sklearn). علاوة على ذلك، هناك أمثلة شاملة داخل كل مجلد، حيث توجد نصوص برمجية وملفات yaml ستساعدك على البدء.
يحتوي مجلد Indian-diabetes-example على مثالين لمساعدتك على البدء:
يحتوي مجلد iris-example على مثال للانحدار اللوجستي ، حيث يتم إجراء بعض المعالجة المسبقة (ترميز ساخن واحد) على العمود الهدف لتظهر لك المزيد من إمكانيات igel.
علاوة على ذلك، يحتوي مثال المخرجات المتعددة على مثال انحدار متعدد المخرجات . أخيرًا، يحتوي مثال السيرة الذاتية على مثال باستخدام مصنف Ridge باستخدام التحقق المتقاطع.
يمكنك أيضًا العثور على أمثلة للتحقق من الصحة وبحث عن المعلمات التشعبية في المجلد.
أقترح عليك اللعب بالأمثلة وigel cli. ومع ذلك، يمكنك أيضًا تنفيذ fit.py، وvalue.py، وpredict.py مباشرةً إذا كنت ترغب في ذلك.
أولاً، قم بإنشاء أو تعديل مجموعة بيانات من الصور التي تم تصنيفها في مجلدات فرعية بناءً على تصنيف/فئة الصورة. على سبيل المثال، إذا كان لديك صور للكلاب والقطط، فستحتاج إلى مجلدين فرعيين:
بافتراض أن هذين المجلدين الفرعيين موجودان في مجلد رئيسي واحد يسمى الصور، فما عليك سوى إدخال البيانات إلى igel:
$ igel auto-train -dp ./images --task ImageClassificationسوف يتعامل Igel مع كل شيء بدءًا من المعالجة المسبقة للبيانات وحتى تحسين المعلمات الفائقة. في النهاية، سيتم تخزين أفضل نموذج في دليل العمل الحالي.
أولاً، قم بإنشاء أو تعديل مجموعة بيانات نصية تم تصنيفها إلى مجلدات فرعية بناءً على تسمية/فئة النص. على سبيل المثال، إذا كان لديك مجموعة بيانات نصية تحتوي على تعليقات إيجابية وسلبية، فستحتاج إلى مجلدين فرعيين:
بافتراض أن هذين المجلدين الفرعيين موجودان في مجلد رئيسي واحد يسمى النصوص، فما عليك سوى تغذية البيانات إلى igel:
$ igel auto-train -dp ./texts --task TextClassificationسوف يتعامل Igel مع كل شيء بدءًا من المعالجة المسبقة للبيانات وحتى تحسين المعلمات الفائقة. في النهاية، سيتم تخزين أفضل نموذج في دليل العمل الحالي.
يمكنك أيضًا تشغيل igel UI إذا لم تكن معتادًا على الجهاز. فقط قم بتثبيت igel على جهازك كما هو مذكور أعلاه. ثم قم بتشغيل هذا الأمر الفردي في جهازك الطرفي
$ igel guiسيؤدي هذا إلى فتح واجهة المستخدم الرسومية، وهي سهلة الاستخدام للغاية. تحقق من الأمثلة لكيفية ظهور واجهة المستخدم الرسومية وكيفية استخدامها هنا: https://github.com/nidhaloff/igel-ui
يمكنك سحب الصورة أولاً من مركز الإرساء
$ docker pull nidhaloff/igelثم استخدمه:
$ docker run -it --rm -v $( pwd ) :/data nidhaloff/igel fit -yml ' your_file.yaml ' -dp ' your_dataset.csv 'يمكنك تشغيل igel داخل عامل الإرساء عن طريق إنشاء الصورة أولاً:
$ docker build -t igel .ثم قم بتشغيله وإرفاق دليلك الحالي (لا يلزم أن يكون دليل igel) كـ /data (دليل العمل) داخل الحاوية:
$ docker run -it --rm -v $( pwd ) :/data igel fit -yml ' your_file.yaml ' -dp ' your_dataset.csv ' إذا واجهتك أي مشكلة فلا تتردد في فتح موضوع. بالإضافة إلى ذلك، يمكنك الاتصال بالمؤلف لمزيد من المعلومات/الأسئلة.
هل تحب ايجل؟ يمكنك دائمًا المساعدة في تطوير هذا المشروع من خلال:
هل تعتقد أن هذا المشروع مفيد وترغب في تقديم أفكار جديدة وميزات جديدة وإصلاحات للأخطاء وتوسيع المستندات؟
المساهمات هي موضع ترحيب دائما. تأكد من قراءة الإرشادات أولاً
رخصة معهد ماساتشوستس للتكنولوجيا
حقوق الطبع والنشر (ج) 2020 حتى الآن، نضال البكوري


