video diffusion pytorch
0.7.0
هذه الألعاب النارية غير موجودة
تحويل النص إلى فيديو، إنه يحدث! الصفحة الرسمية للمشروع
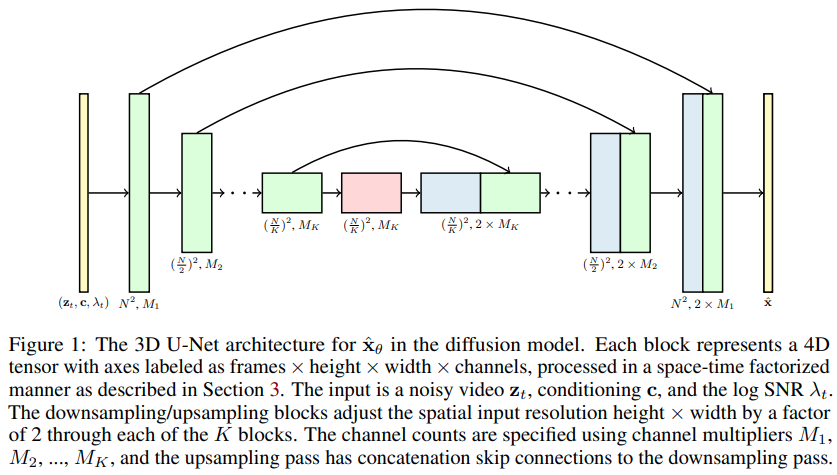
تنفيذ نماذج نشر الفيديو، ورقة جوناثان هو الجديدة التي توسع نطاقات DDPM إلى إنشاء الفيديو - في Pytorch. ويستخدم شبكة U خاصة بعامل الزمكان، مما يعمل على توسيع نطاق الإنتاج من الصور ثنائية الأبعاد إلى مقاطع الفيديو ثلاثية الأبعاد
14k للحركة الصعبة mnist (تتقارب بشكل أسرع وأفضل من NUWA) - Wip

التجارب المذكورة أعلاه ممكنة فقط بفضل الموارد المقدمة من Stability.ai
أي تطورات جديدة في مجال تحويل النص إلى فيديو ستكون مركزية في Imagen-pytorch
$ pip install video-diffusion-pytorch import torch
from video_diffusion_pytorch import Unet3D , GaussianDiffusion
model = Unet3D (
dim = 64 ,
dim_mults = ( 1 , 2 , 4 , 8 )
)
diffusion = GaussianDiffusion (
model ,
image_size = 32 ,
num_frames = 5 ,
timesteps = 1000 , # number of steps
loss_type = 'l1' # L1 or L2
)
videos = torch . randn ( 1 , 3 , 5 , 32 , 32 ) # video (batch, channels, frames, height, width) - normalized from -1 to +1
loss = diffusion ( videos )
loss . backward ()
# after a lot of training
sampled_videos = diffusion . sample ( batch_size = 4 )
sampled_videos . shape # (4, 3, 5, 32, 32)من أجل تكييف النص، قاموا باشتقاق تضمينات النص عن طريق تمرير النص المميز أولاً عبر BERT-large. ثم عليك فقط تدريبه بهذه الطريقة
import torch
from video_diffusion_pytorch import Unet3D , GaussianDiffusion
model = Unet3D (
dim = 64 ,
cond_dim = 64 ,
dim_mults = ( 1 , 2 , 4 , 8 )
)
diffusion = GaussianDiffusion (
model ,
image_size = 32 ,
num_frames = 5 ,
timesteps = 1000 , # number of steps
loss_type = 'l1' # L1 or L2
)
videos = torch . randn ( 2 , 3 , 5 , 32 , 32 ) # video (batch, channels, frames, height, width)
text = torch . randn ( 2 , 64 ) # assume output of BERT-large has dimension of 64
loss = diffusion ( videos , cond = text )
loss . backward ()
# after a lot of training
sampled_videos = diffusion . sample ( cond = text )
sampled_videos . shape # (2, 3, 5, 32, 32)يمكنك أيضًا تمرير أوصاف الفيديو مباشرةً كسلاسل، إذا كنت تخطط لاستخدام قاعدة BERT لتكييف النص
import torch
from video_diffusion_pytorch import Unet3D , GaussianDiffusion
model = Unet3D (
dim = 64 ,
use_bert_text_cond = True , # this must be set to True to auto-use the bert model dimensions
dim_mults = ( 1 , 2 , 4 , 8 ),
)
diffusion = GaussianDiffusion (
model ,
image_size = 32 , # height and width of frames
num_frames = 5 , # number of video frames
timesteps = 1000 , # number of steps
loss_type = 'l1' # L1 or L2
)
videos = torch . randn ( 3 , 3 , 5 , 32 , 32 ) # video (batch, channels, frames, height, width)
text = [
'a whale breaching from afar' ,
'young girl blowing out candles on her birthday cake' ,
'fireworks with blue and green sparkles'
]
loss = diffusion ( videos , cond = text )
loss . backward ()
# after a lot of training
sampled_videos = diffusion . sample ( cond = text , cond_scale = 2 )
sampled_videos . shape # (3, 3, 5, 32, 32) يحتوي هذا المستودع أيضًا على فصل Trainer مفيد للتدريب على مجلد gifs . يجب أن يكون لكل gif الأبعاد الصحيحة image_size و num_frames .
import torch
from video_diffusion_pytorch import Unet3D , GaussianDiffusion , Trainer
model = Unet3D (
dim = 64 ,
dim_mults = ( 1 , 2 , 4 , 8 ),
)
diffusion = GaussianDiffusion (
model ,
image_size = 64 ,
num_frames = 10 ,
timesteps = 1000 , # number of steps
loss_type = 'l1' # L1 or L2
). cuda ()
trainer = Trainer (
diffusion ,
'./data' , # this folder path needs to contain all your training data, as .gif files, of correct image size and number of frames
train_batch_size = 32 ,
train_lr = 1e-4 ,
save_and_sample_every = 1000 ,
train_num_steps = 700000 , # total training steps
gradient_accumulate_every = 2 , # gradient accumulation steps
ema_decay = 0.995 , # exponential moving average decay
amp = True # turn on mixed precision
)
trainer . train () سيتم حفظ نماذج مقاطع الفيديو (كملفات gif ) في ./results بشكل دوري، كما هو الحال مع معلمات نموذج الانتشار.
أحد الادعاءات الواردة في الورقة هو أنه من خلال الاهتمام بالزمكان، يمكن للمرء إجبار الشبكة على الحضور في الوقت الحاضر لتدريب الصور والفيديو بالتزامن، مما يؤدي إلى نتائج أفضل.
ولم يكن من الواضح كيف حققوا ذلك، لكنني عززت التخمين.
لجذب الانتباه إلى اللحظة الحالية لنسبة معينة من عينات مقاطع الفيديو المجمعة، ما عليك سوى تمرير prob_focus_present = <prob> على طريقة الانتشار للأمام
loss = diffusion ( videos , cond = text , prob_focus_present = 0.5 ) # for 50% of videos, focus on the present during training
loss . backward ()إذا كانت لديك فكرة أفضل عن كيفية القيام بذلك، فما عليك سوى فتح مشكلة جيثب.
@misc { ho2022video ,
title = { Video Diffusion Models } ,
author = { Jonathan Ho and Tim Salimans and Alexey Gritsenko and William Chan and Mohammad Norouzi and David J. Fleet } ,
year = { 2022 } ,
eprint = { 2204.03458 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { Saharia2022 ,
title = { Imagen: unprecedented photorealism × deep level of language understanding } ,
author = { Chitwan Saharia*, William Chan*, Saurabh Saxena†, Lala Li†, Jay Whang†, Emily Denton, Seyed Kamyar Seyed Ghasemipour, Burcu Karagol Ayan, S. Sara Mahdavi, Rapha Gontijo Lopes, Tim Salimans, Jonathan Ho†, David Fleet†, Mohammad Norouzi* } ,
year = { 2022 }
}

