RoboFlamingo
1.0.0
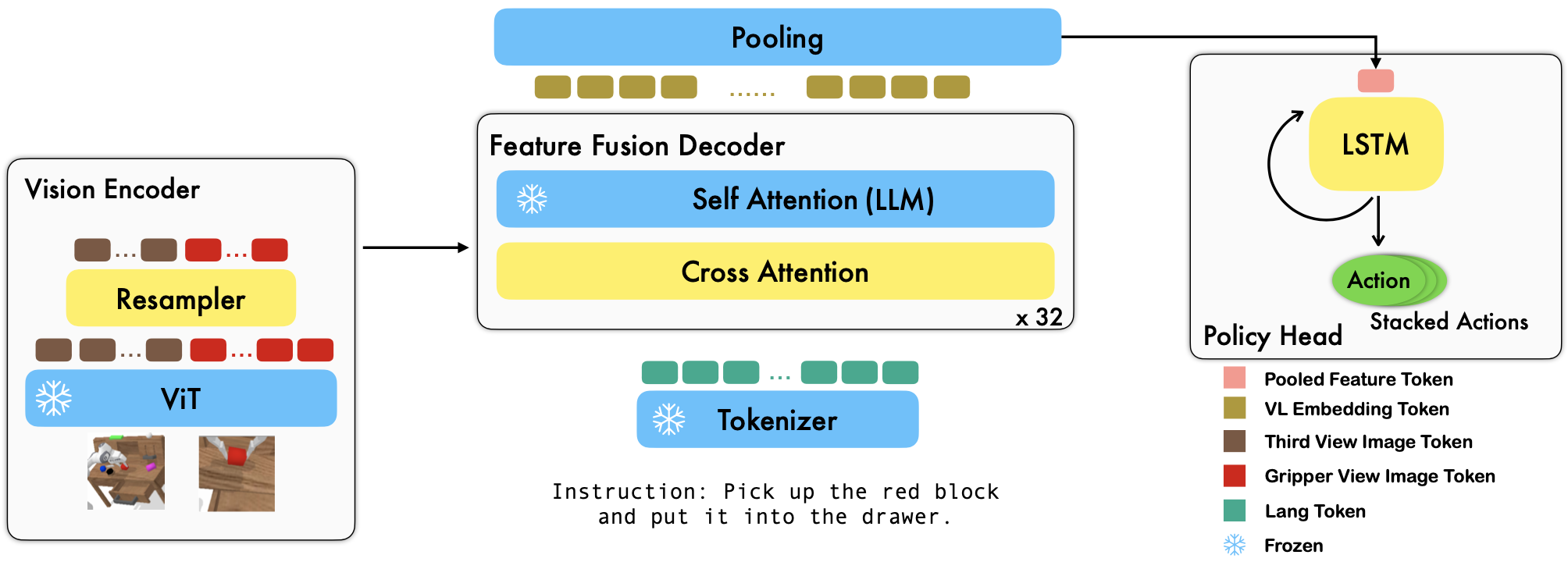
RoboFlamingo هو إطار عمل لتعلم الروبوتات مُدرب مسبقًا ومعتمد على VLM والذي يتعلم مجموعة واسعة من مهارات الروبوت المكيفة اللغة من خلال الضبط الدقيق لمجموعات البيانات المقلدة ذات الشكل الحر غير المتصلة بالإنترنت. من خلال تجاوز الأداء المتطور بهامش كبير في معيار CALVIN، نظهر أن RoboFlamingo يمكن أن يكون بديلاً فعالاً وتنافسيًا لتكييف VLMs مع التحكم الآلي. تكشف نتائجنا التجريبية الشاملة أيضًا عن العديد من الاستنتاجات المثيرة للاهتمام فيما يتعلق بسلوك مختلف أجهزة VLM المدربة مسبقًا في مهام المعالجة. يمكن تدريب RoboFlamingo أو تقييمه على خادم GPU واحد (تعتمد متطلبات ذاكرة GPU على حجم النموذج)، ونعتقد أن RoboFlamingo لديه القدرة على أن يكون حلاً فعالاً من حيث التكلفة وسهل الاستخدام لمعالجة الروبوتات، وتمكين الجميع من القدرة على ضبط سياسة الروبوتات الخاصة بهم.
هذا أيضًا هو مستودع التعليمات البرمجية الرسمي للورقة "نماذج مؤسسة الرؤية واللغة كمقلدين فعالين للروبوتات".
يتم إجراء جميع تجاربنا على خادم GPU واحد مع 8 وحدات معالجة رسوميات Nvidia A100 (80G).
تتوفر النماذج المدربة مسبقًا على Hugging Face.
نحن ندعم برامج تشفير الرؤية المدربة مسبقًا من حزمة OpenCLIP، والتي تتضمن نماذج OpenAI المدربة مسبقًا. نحن ندعم أيضًا نماذج اللغة المدربة مسبقًا من حزمة transformers ، مثل نماذج MPT وRedPajama وLLaMA وOPT وGPT-Neo وGPT-J وPythia.
from robot_flamingo . factor import create_model_and_transforms
model , image_processor , tokenizer = create_model_and_transforms (
clip_vision_encoder_path = "ViT-L-14" ,
clip_vision_encoder_pretrained = "openai" ,
lang_encoder_path = "PATH/TO/LLM/DIR" ,
tokenizer_path = "PATH/TO/LLM/DIR" ,
cross_attn_every_n_layers = 1 ,
decoder_type = 'lstm' ,
) تتحكم الوسيطة cross_attn_every_n_layers في عدد مرات تطبيق طبقات الانتباه المتبادل ويجب أن تكون متسقة مع VLM. تتحكم الوسيطة decoder_type في نوع وحدة فك التشفير، حاليًا، نحن ندعم lstm و fc و diffusion (توجد أخطاء في أداة تحميل البيانات) و GPT .
نقوم بالإبلاغ عن النتائج وفقًا لمعيار CALVIN.
| طريقة | بيانات التدريب | اختبار الانقسام | 1 | 2 | 3 | 4 | 5 | متوسط لين |
|---|---|---|---|---|---|---|---|---|
| MCIL | ABCD (كامل) | د | 0.373 | 0.027 | 0.002 | 0.000 | 0.000 | 0.40 |
| HULC | ABCD (كامل) | د | 0.889 | 0.733 | 0.587 | 0.475 | 0.383 | 3.06 |
| HULC (أعيد تدريبه) | ABCD (لانج) | د | 0.892 | 0.701 | 0.548 | 0.420 | 0.335 | 2.90 |
| RT-1 (أعيد تدريبه) | ABCD (لانج) | د | 0.844 | 0.617 | 0.438 | 0.323 | 0.227 | 2.45 |
| لنا | ABCD (لانج) | د | 0.964 | 0.896 | 0.824 | 0.740 | 0.66 | 4.09 |
| MCIL | ABC (كامل) | د | 0.304 | 0.013 | 0.002 | 0.000 | 0.000 | 0.31 |
| HULC | ABC (كامل) | د | 0.418 | 0.165 | 0.057 | 0.019 | 0.011 | 0.67 |
| RT-1 (أعيد تدريبه) | ABC (لانج) | د | 0.533 | 0.222 | 0.094 | 0.038 | 0.013 | 0.90 |
| لنا | ABC (لانج) | د | 0.824 | 0.619 | 0.466 | 0.331 | 0.235 | 2.48 |
| HULC | ABCD (كامل) | د (إثراء) | 0.715 | 0.470 | 0.308 | 0.199 | 0.130 | 1.82 |
| RT-1 (أعيد تدريبه) | ABCD (لانج) | د (إثراء) | 0.494 | 0.222 | 0.086 | 0.036 | 0.017 | 0.86 |
| لنا | ABCD (لانج) | د (إثراء) | 0.720 | 0.480 | 0.299 | 0.211 | 0.144 | 1.85 |
| لنا (تجميد Emb) | ABCD (لانج) | د (إثراء) | 0.737 | 0.530 | 0.385 | 0.275 | 0.192 | 2.12 |
اتبع الإرشادات الموجودة في OpenFlamingo وCALVIN لتنزيل مجموعة البيانات الضرورية ونماذج VLM المدربة مسبقًا.
قم بتنزيل مجموعة بيانات CALVIN، واختر تقسيمًا باستخدام:
cd $HULC_ROOT /dataset
sh download_data.sh D | ABC | ABCD | debugقم بتنزيل نماذج OpenFlamingo التي تم إصدارها:
| # المعلمات | نموذج اللغة | تشفير الرؤية | الفاصل الزمني Xatn* | كوكو 4 طلقة عصير التفاح | دقة VQAv2 4 طلقات | متوسط لين | الأوزان |
|---|---|---|---|---|---|---|---|
| 3 ب | أنس-عوض الله/mpt-1b-redpajama-200b | أوبيناي كليب ViT-L/14 | 1 | 77.3 | 45.8 | 3.94 | وصلة |
| 3 ب | أنس-عوض الله/mpt-1b-redpajama-200b-dolly | أوبيناي كليب ViT-L/14 | 1 | 82.7 | 45.7 | 4.09 | وصلة |
| 4 ب | Togethercomputer/RedPajama-INCITE-Base-3B-v1 | أوبيناي كليب ViT-L/14 | 2 | 81.8 | 49.0 | 3.67 | وصلة |
| 4 ب | Togethercomputer/RedPajama-INCITE-Instruct-3B-v1 | أوبيناي كليب ViT-L/14 | 2 | 85.8 | 49.0 | 3.79 | وصلة |
| 9 ب | أنس-عوض الله/mpt-7b | أوبيناي كليب ViT-L/14 | 4 | 89.0 | 54.8 | 3.97 | وصلة |
استبدل ${lang_encoder_path} و ${tokenizer_path} من قاموس المسار (على سبيل المثال، mpt_dict ) في robot_flamingo/models/factory.py لكل VLM تم تدريبه مسبقًا بمساراتك الخاصة.
استنساخ هذا الريبو
git clone https://github.com/RoboFlamingo/RoboFlamingo.git
تثبيت الحزم المطلوبة:
cd RoboFlamingo
conda create -n RoboFlamingo python=3.8
source activate RoboFlamingo
pip install -r requirements.txt
torchrun --nnodes=1 --nproc_per_node=8 --master_port=6042 robot_flamingo/train/train_calvin.py
--report_to_wandb
--llm_name mpt_dolly_3b
--traj_cons
--use_gripper
--fusion_mode post
--rgb_pad 10
--gripper_pad 4
--precision fp32
--num_epochs 5
--gradient_accumulation_steps 1
--batch_size_calvin 6
--run_name RobotFlamingoDBG
--calvin_dataset ${calvin_dataset_path}
--lm_path ${lm_path}
--tokenizer_path ${tokenizer_path}
--openflamingo_checkpoint ${openflamingo_checkpoint}
--cross_attn_every_n_layers 4
--dataset_resampled
--loss_multiplier_calvin 1.0
--workers 1
--lr_scheduler constant
--warmup_steps 5000
--learning_rate 1e-4
--save_every_iter 10000
--from_scratch
--window_size 12 > ${log_file} 2>&1
${calvin_dataset_path} هو المسار إلى مجموعة بيانات CALVIN؛
${lm_path} هو المسار إلى LLM المُدرب مسبقًا؛
${tokenizer_path} هو المسار إلى رمز VLM المميز؛
${openflamingo_checkpoint} هو المسار إلى نموذج OpenFlamingo المُدرب مسبقًا؛
${log_file} هو المسار إلى ملف السجل.
نوفر أيضًا robot_flamingo/pt_run_gripper_post_ws_12_traj_aug_mpt_dolly_3b.bash لبدء التدريب. يقوم هذا bash بضبط إصدار MPT-3B-IFT من نموذج OpenFlamingo، والذي يحتوي على المعلمات الفائقة الافتراضية لتدريب النموذج، ويتوافق مع أفضل النتائج في الورقة.
python eval_ckpts.py
من خلال إضافة اسم نقطة التفتيش والدليل إلى eval_ckpts.py ، سيقوم البرنامج النصي تلقائيًا بتحميل النموذج وتقييمه. على سبيل المثال، إذا كنت تريد تقييم نقطة التحقق في المسار "your-checkpoint-path"، فيمكنك تعديل متغيرات ckpt_dir و ckpt_names في eval_ckpts.py، وسيتم حفظ نتائج التقييم كـ "logs/your-checkpoint-prefix". سجل'.
تشير النتائج الموضحة أدناه إلى أن التدريب المشترك يمكن أن يحافظ على معظم قدرة العمود الفقري للـ VLM في مهام VL، مع فقدان القليل من الأداء في مهام الروبوت.
يستخدم
bash robot_flamingo/pt_run_gripper_post_ws_12_traj_aug_mpt_dolly_3b_co_train.bash
لإطلاق تدريب RoboFlamingo المشترك مع CoCO وVQAV2 وCALVIN. يجب عليك تحديث مسارات CoCO وVQA في get_coco_dataset و get_vqa_dataset في robot_flamingo/data/data.py .
| ينقسم | ريال 1 | ريال 2 | 3 ريال | 4 ريال | 5 ريال سعودي | متوسط لين |
|---|---|---|---|---|---|---|
| شارك في التدريب | ABC->د | 82.9% | 63.6% | 45.3% | 32.1% | 23.4% |
| ضبط دقيق | ABC->د | 82.4% | 61.9% | 46.6% | 33.1% | 23.5% |
| شارك في التدريب | ABCD->د | 95.7% | 85.8% | 73.7% | 64.5% | 56.1% |
| ضبط دقيق | ABCD->د | 96.4% | 89.6% | 82.4% | 74.0% | 66.2% |
| شارك في التدريب | ABCD->D (إثراء) | 67.8% | 45.2% | 29.4% | 18.9% | 11.7% |
| ضبط دقيق | ABCD->D (إثراء) | 72.0% | 48.0% | 29.9% | 21.1% | 14.4% |
| كوكو | VQA | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| بلو-1 | بلو-2 | بلو-3 | بلو-4 | نيزك | ROUGE_L | عصير التفاح | سبايس | لجنة التنسيق الإدارية | |
| ضبط دقيق (3B، لقطة صفرية) | 0.156 | 0.051 | 0.018 | 0.007 | 0.038 | 0.148 | 0.004 | 0.006 | 4.09 |
| ضبط دقيق (3B، 4 لقطات) | 0.166 | 0.056 | 0.020 | 0.008 | 0.042 | 0.158 | 0.004 | 0.008 | 3.87 |
| تدريب مشترك (3B، صفر طلقة) | 0.225 | 0.158 | 0.107 | 0.072 | 0.124 | 0.334 | 0.345 | 0.085 | 36.37 |
| فلامنغو الأصلي (80B، ضبط دقيق) | - | - | - | - | - | - | 1.381 | - | 82.0 |
يتم إنشاء الشعار باستخدام MidJourney
يستخدم هذا العمل تعليمات برمجية من المشاريع ومجموعات البيانات مفتوحة المصدر التالية:
الأصل: https://github.com/mees/calvin الترخيص: معهد ماساتشوستس للتكنولوجيا
الأصل: https://github.com/openai/CLIP الترخيص: معهد ماساتشوستس للتكنولوجيا
الأصل: https://github.com/mlfoundations/open_flamingo الترخيص: معهد ماساتشوستس للتكنولوجيا
@article{li2023vision,
title = {Vision-Language Foundation Models as Effective Robot Imitators},
author = {Li, Xinghang and Liu, Minghuan and Zhang, Hanbo and Yu, Cunjun and Xu, Jie and Wu, Hongtao and Cheang, Chilam and Jing, Ya and Zhang, Weinan and Liu, Huaping and Li, Hang and Kong, Tao},
journal={arXiv preprint arXiv:2311.01378},
year={2023}


