RobustSAM
1.0.0
المستودع الرسمي لـ RobustSAM: قسّم أي شيء بقوة إلى الصور المتدهورة
صفحة المشروع | ورق | فيديو | مجموعة البيانات
أغسطس 2024: يمكنك الرجوع إلى بطاقات نموذج Hugging Face والعرض التوضيحي الذي أنشأه @jadechoghari لتسهيل الاستخدام عبر هذا الرابط.
يوليو 2024: تم إصدار كود التدريب والبيانات ونقاط التفتيش النموذجية لمختلف العمود الفقري لـ ViT!
يونيو 2024: تم إصدار رمز الاستدلال!
فبراير 2024: تم قبول RobustSAM في CVPR 2024!
لقد ظهر نموذج Segment Anything Model (SAM) كنهج تحويلي في تجزئة الصور، وهو مشهور بقدراته القوية على التجزئة بدون لقطة ونظام المطالبة المرن. ومع ذلك، فإن أداءه يواجه تحديات من خلال الصور ذات الجودة المتدهورة. لمعالجة هذا القيد، نقترح نموذج أي شيء للقطاع القوي (RobustSAM)، الذي يعزز أداء SAM في الصور منخفضة الجودة مع الحفاظ على قابليته للسرعة وتعميم اللقطة الصفرية.
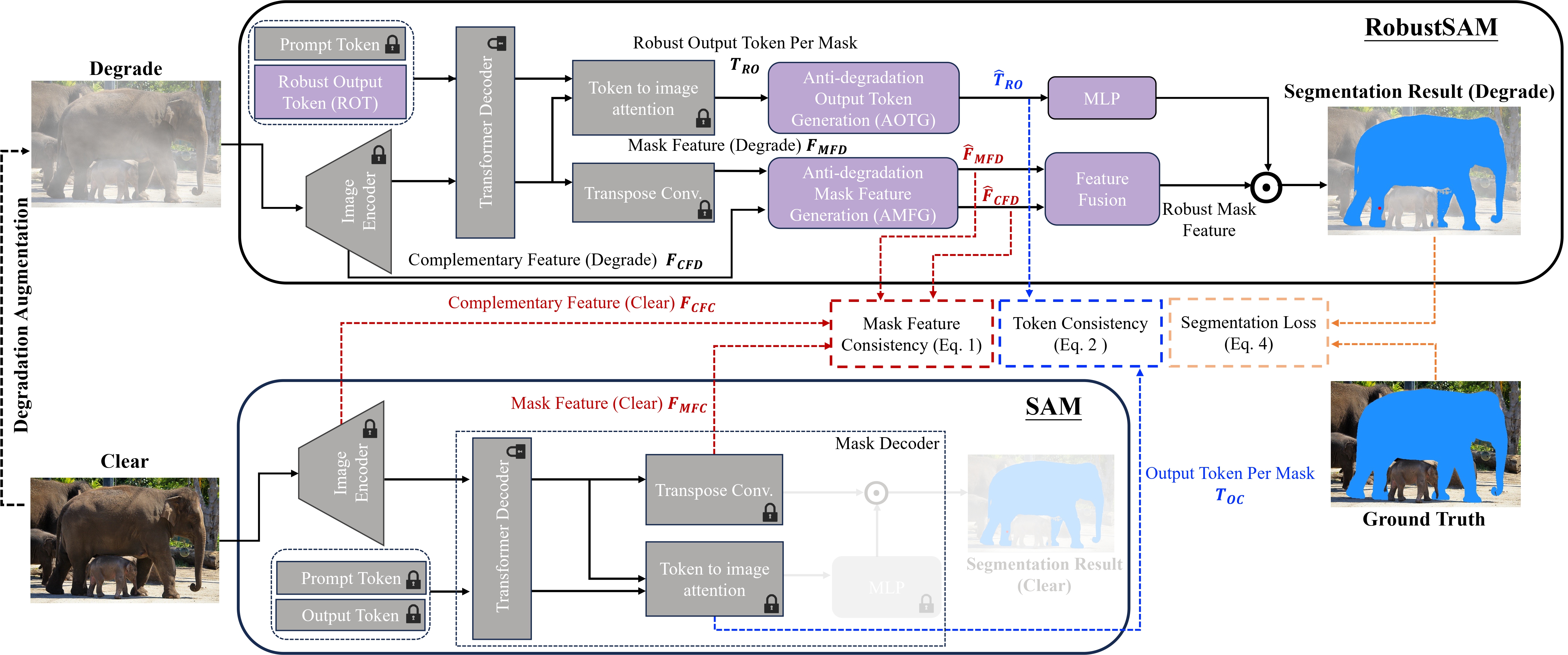
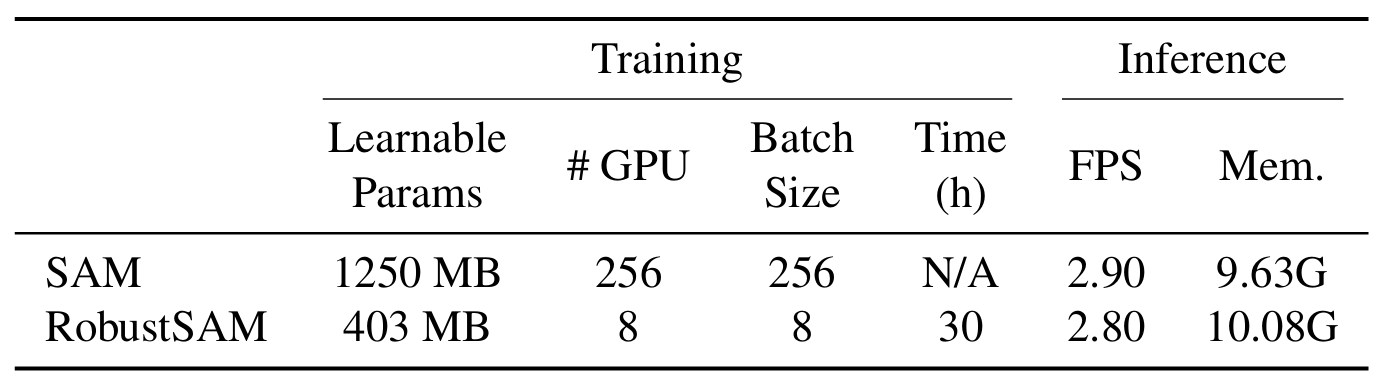
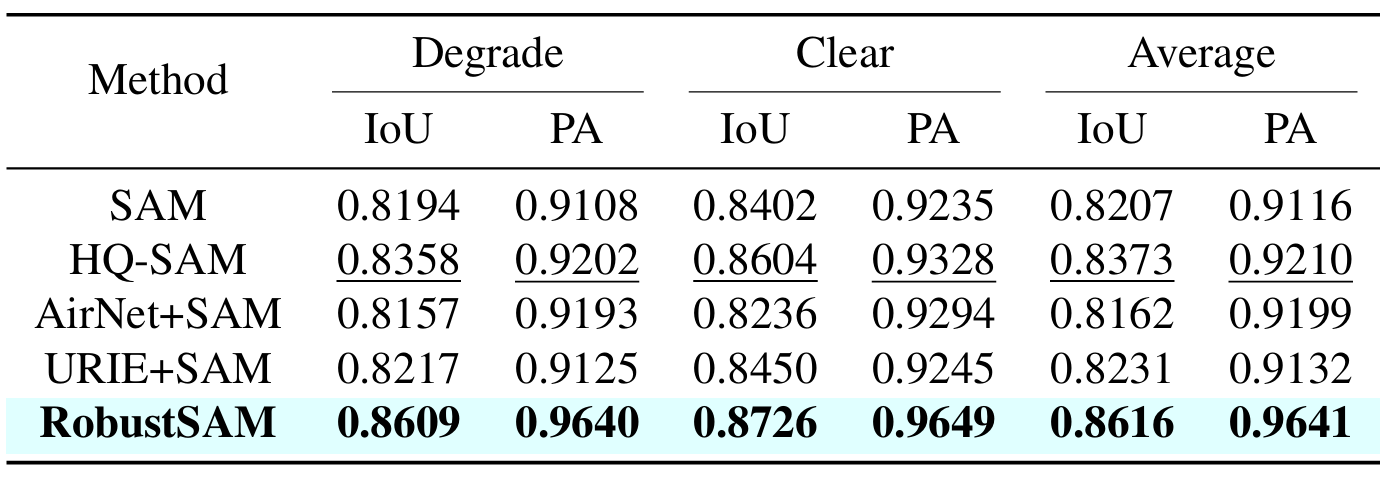
تستفيد طريقتنا من نموذج SAM المُدرب مسبقًا مع زيادات المعلمات الهامشية والمتطلبات الحسابية فقط. يمكن تحسين المعلمات الإضافية لـ RobustSAM خلال 30 ساعة على ثماني وحدات معالجة رسوميات، مما يوضح جدواها وعمليتها لمختبرات الأبحاث النموذجية. نقدم أيضًا مجموعة بيانات Robust-Seg، وهي عبارة عن مجموعة من 688 ألف زوج من أقنعة الصور مع انحطاطات مختلفة مصممة لتدريب نموذجنا وتقييمه على النحو الأمثل. تؤكد التجارب الموسعة عبر مختلف مهام التجزئة ومجموعات البيانات الأداء المتفوق لـ RobustSAM، خاصة في ظل ظروف الصفر، مما يؤكد إمكاناته لتطبيقات واسعة النطاق في العالم الحقيقي. بالإضافة إلى ذلك، لقد ثبت أن طريقتنا تعمل على تحسين أداء المهام النهائية المستندة إلى SAM بشكل فعال مثل إزالة الصورة الواحدة وإزالة الضبابية.
إنشاء بيئة كوندا وتفعيلها.
conda create --name robustsam python=3.10 -y conda activate robustsam
استنساخ وأدخل في دليل الريبو.
git clone https://github.com/robustsam/RobustSAM cd RobustSAM
استخدم الأمر أدناه للتحقق من إصدار CUDA الخاص بك.
nvidia-smi
استبدل إصدار CUDA بإصدارك الموجود في الأمر أدناه.
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu[$YOUR_CUDA_VERSION] # For example: pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu117 # cu117 = CUDA_version_11.7
تثبيت التبعيات المتبقية
pip install -r requirements.txt
قم بتنزيل نقاط فحص RobustSAM المدربة مسبقًا بأحجام مختلفة ووضعها في الدليل الحالي.
نقطة تفتيش ViT-B RobustSAM
نقطة تفتيش ViT-L RobustSAM
نقطة تفتيش ViT-H RobustSAM
قم بتغيير الدليل الحالي إلى دليل "البيانات".
cd data
قم بتنزيل القطار والفال والاختبار ومجموعة بيانات COCO وLVIS الإضافية. (ملاحظة: الصور الموجودة في مجموعة بيانات القطار وفال والاختبار تتكون من صور من LVIS وMSRA10K وThinObject-5k وNDD20 وSTREETS وFSS-1000)
bash download.sh
لا يوجد سوى صور واضحة تم تنزيلها في الخطوة السابقة. استخدم الأمر أدناه لإنشاء الصور المتدهورة المقابلة.
bash gen_data.sh
إذا كنت ترغب في التدريب من الصفر، استخدم الأمر أدناه.
python -m torch.distributed.launch train_ddp.py --multiprocessing-distributed --exp_name [$YOUR_EXP_NAME] --model_size [$MODEL_SIZE] # Example usage: python -m torch.distributed.launch train_ddp.py --multiprocessing-distributed --exp_name test --model_size l
إذا كنت تريد التدريب من نقطة تفتيش مدربة مسبقًا، استخدم الأمر أدناه.
python -m torch.distributed.launch train_ddp.py --multiprocessing-distributed --exp_name [$YOUR_EXP_NAME] --model_size [$MODEL_SIZE] --load_model [$CHECKPOINT_PATH] # Example usage: python -m torch.distributed.launch train_ddp.py --multiprocessing-distributed --exp_name test --model_size l --load_model robustsam_checkpoint_l.pth
python gradio_app.py
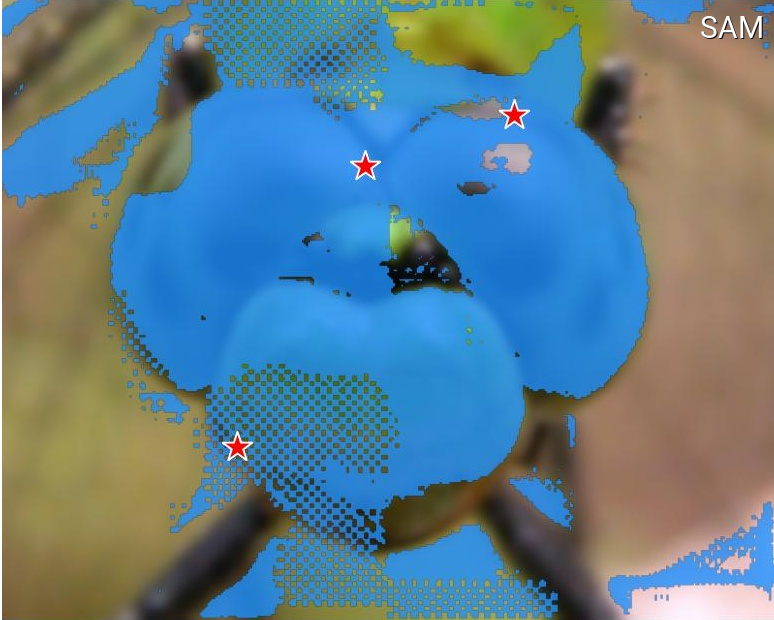
لقد قمنا بإعداد بعض الصور في مجلد demo_images لغرض العرض التوضيحي. بالإضافة إلى ذلك، يتوفر وضعان للمطالبة (مطالبات الصندوق ومطالبات النقاط).
لمطالبة الصندوق:
python eval.py --bbox --model_size l
لمطالبة النقطة:
python eval.py --model_size l
افتراضيًا، سيتم حفظ نتائج العرض التوضيحي في demo_result/[$PROMPT_TYPE] .
 |  |
 |  |

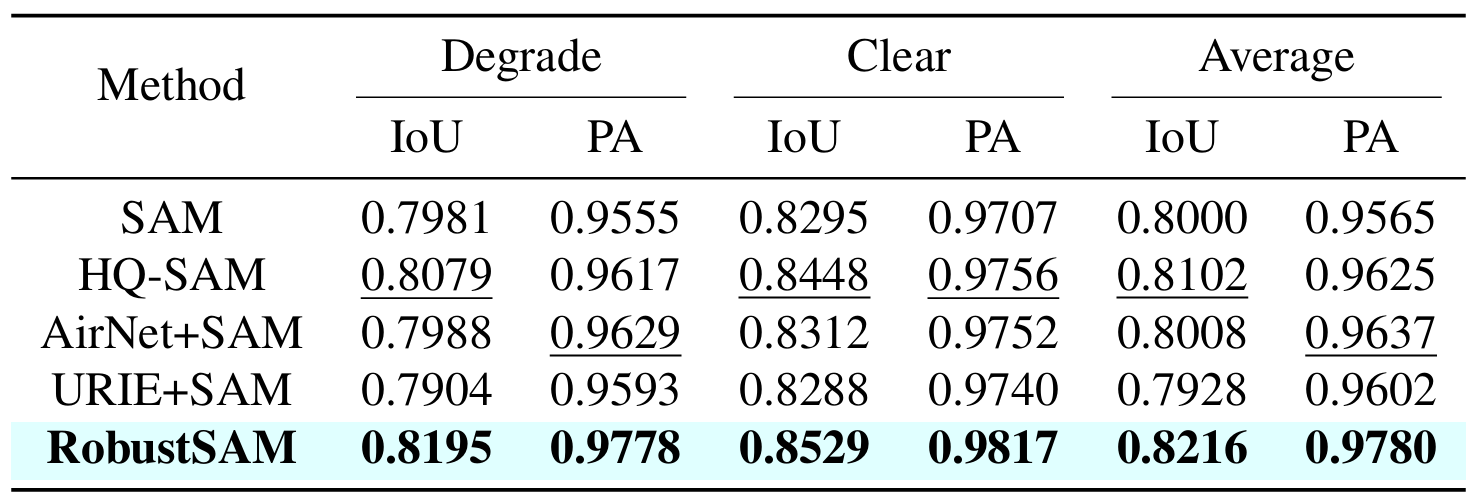
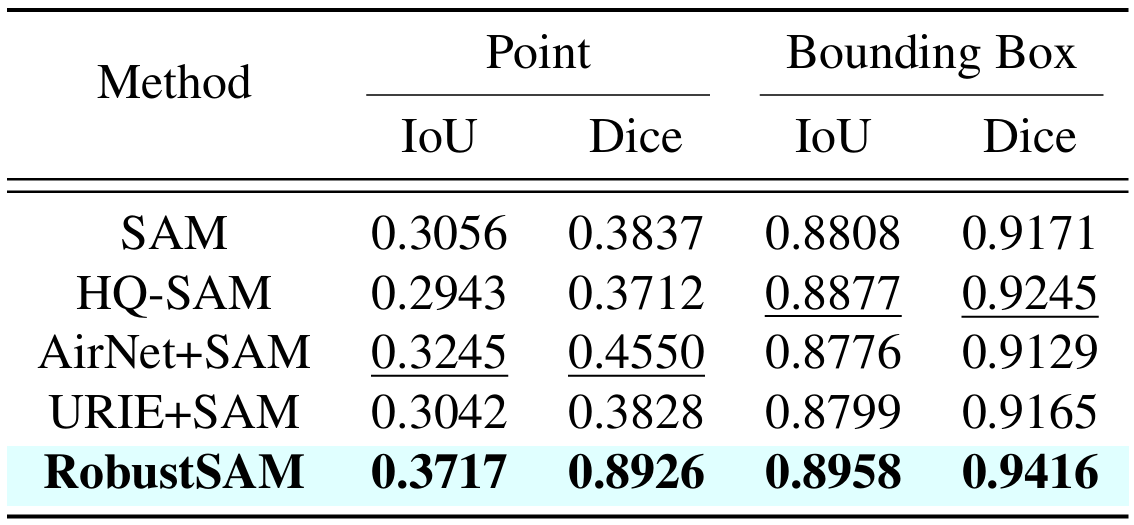
إذا وجدت هذا العمل مفيدًا، فيرجى التفكير في الاستشهاد بنا!
@inproceedings{chen2024robustsam, title={RobustSAM: قسم أي شيء بقوة على الصور المتدهورة}، المؤلف={Chen, Wei-Ting and Vong, Yu-Jiet and Kuo, Sy-Yen and Ma, Sizhou and Wang, Jian}، مجلة= {CVPR}، السنة={2024}}نشكر مؤلفي SAM الذي يستند إليه الريبو الخاص بنا.


