MambaTransformer
1.0.0

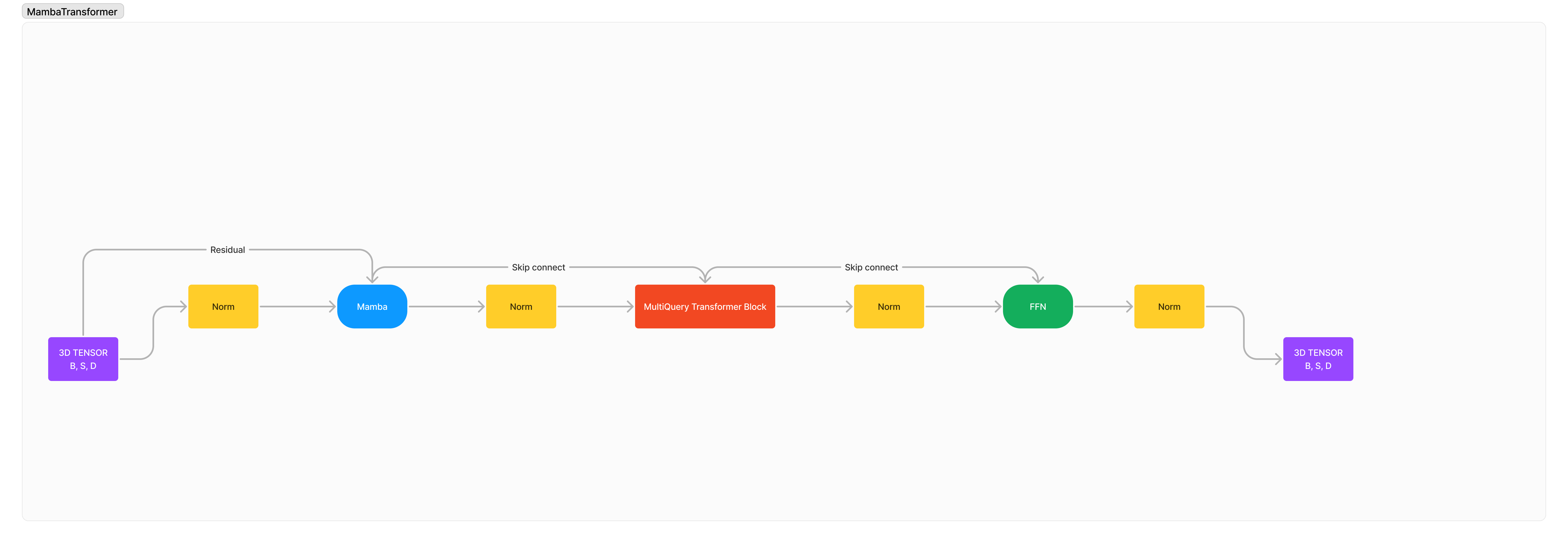
دمج Mamba/SSMs مع Transformer لتعزيز السياق الطويل ونمذجة التسلسل عالي الجودة.
هذه بنية جديدة بنسبة 100% قمت بتصميمها للجمع بين نقاط القوة والضعف في SSMs والاهتمام ببنية متقدمة جديدة تمامًا بغرض تجاوز حدودنا القديمة. سرعة معالجة أسرع، وأطوال سياقية أطول، وحيرة أقل عبر التسلسلات الطويلة، وتفكير معزز ومتفوق مع الحفاظ على صغر حجمه وضغطه.
البنية هي في الأساس: x -> norm -> mamba -> norm -> transformer -> norm -> ffn -> norm -> out .
لقد أضفت العديد من عمليات التطبيع لأنني أعتقد أن استقرار التدريب الافتراضي سوف يتدهور بشدة بسبب تكامل معماريتين أجنبيتين مع بعضهما البعض.
pip3 install mambatransformer
import torch
from mamba_transformer import MambaTransformer
# Generate a random tensor of shape (1, 10) with values between 0 and 99
x = torch . randint ( 0 , 100 , ( 1 , 10 ))
# Create an instance of the MambaTransformer model
model = MambaTransformer (
num_tokens = 100 , # Number of tokens in the input sequence
dim = 512 , # Dimension of the model
heads = 8 , # Number of attention heads
depth = 4 , # Number of transformer layers
dim_head = 64 , # Dimension of each attention head
d_state = 512 , # Dimension of the state
dropout = 0.1 , # Dropout rate
ff_mult = 4 , # Multiplier for the feed-forward layer dimension
return_embeddings = False , # Whether to return the embeddings,
transformer_depth = 2 , # Number of transformer blocks
mamba_depth = 10 , # Number of Mamba blocks,
use_linear_attn = True , # Whether to use linear attention
)
# Pass the input tensor through the model and print the output shape
out = model ( x )
print ( out . shape )
# After many training
model . eval ()
# Would you like to train this model? Zeta Corporation offers unmatchable GPU clusters at unbeatable prices, let's partner!
# Tokenizer
model . generate ( text )
معهد ماساتشوستس للتكنولوجيا


