toyCarIRL
1.0.0
التعلم المعزز (RL) هو الشكل الأساسي والأكثر بديهية للتعلم عن طريق التجربة والخطأ، وهو الطريقة التي تتعلم بها معظم الكائنات الحية التي تتمتع بشكل ما من أشكال قدرات التفكير. غالبًا ما يشار إليه باسم التعلم عن طريق الاستكشاف، وهو الطريقة التي يتعلم بها الطفل البشري المولود حديثًا اتخاذ خطواته الأولى، وذلك عن طريق اتخاذ إجراءات عشوائية في البداية ثم اكتشاف الإجراءات التي تؤدي إلى حركة المشي للأمام ببطء.
لاحظ أن هذا المنشور يفترض فهمًا جيدًا لإطار التعلم المعزز، يرجى التعرف على RL خلال الأسبوعين الخامس والسادس من هذه الدورة التدريبية الرائعة عبر الإنترنت AI_Berkeley.
والسؤال الذي ظللت أطرحه على نفسي هو، ما هي القوة الدافعة لهذا النوع من التعلم، وما الذي يجبر الشخص على تعلم سلوك معين بالطريقة التي يفعل بها ذلك. عند معرفة المزيد عن RL، خطرت ببالي فكرة المكافآت ، حيث يحاول الوكيل في الأساس اختيار أفعاله بطريقة يتم فيها تعظيم المكافآت التي يحصل عليها من هذا السلوك المعين. الآن لجعل الوكيل يقوم بسلوكيات مختلفة، فإن بنية المكافأة هي التي يجب على الشخص تعديلها/استغلالها. لكن لنفترض أننا لا نملك سوى المعرفة بسلوك الخبير الموجود معنا، فكيف يمكننا تقدير هيكل المكافأة في ضوء سلوك معين في البيئة؟ حسنًا، هذه هي مشكلة التعلم المعزز العكسي (IRL) ، حيث نرغب في تحديد هيكل المكافأة الأساسي، نظرًا لسياسة الخبراء المثالية (التي يُفترض أنها الأمثل في الواقع).
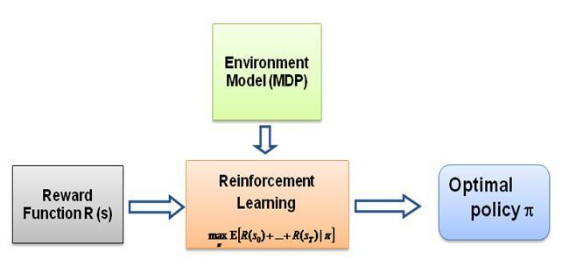
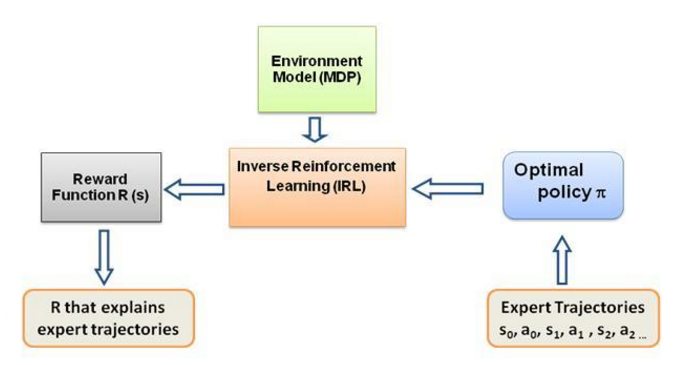
مرة أخرى، هذه ليست مقدمة إلى منشور تعلم التعزيز العكسي، بل هي برنامج تعليمي حول كيفية استخدام/ترميز إطار التعلم المعزز العكسي لمشكلتك الخاصة، ولكن IRL يكمن في جوهره، ومن الضروري معرفة ذلك أولا. تمت دراسة IRL على نطاق واسع في الماضي وتم تطوير خوارزميات لها، يرجى الاطلاع على الأوراق البحثية Ng and Russell,2000 وAbbeel and Ng, 2004 لمزيد من المعلومات.
تتكيف هذه المنشورات مع الخوارزمية من Abbeel and Ng, 2004 لحل مشكلة IRL.
الفكرة هنا هي برمجة وكيل بسيط في عالم ثنائي الأبعاد مليء بالعقبات التي تحول دون نسخ/استنساخ السلوكيات المختلفة في البيئة، ويتم إدخال السلوكيات بمساعدة مسارات الخبراء المقدمة يدويًا من قبل خبير بشري/كمبيوتر. يسمى هذا النوع من التعلم من عروض الخبراء بالتعلم المهني في الأدبيات العلمية، وفي جوهره يكمن التعلم المعزز العكسي، ونحن نحاول فقط معرفة وظائف المكافأة المختلفة لهذه السلوكيات المختلفة.
بشكل عام، نعم، هما نفس الشيء، مما يعني التعلم من العرض التوضيحي (LfD). تتعلم كلتا الطريقتين من العرض التوضيحي، لكنهما تتعلمان أشياء مختلفة:
سيحاول التعلم المهني عبر التعلم المعزز العكسي استنتاج هدف المعلم . بمعنى آخر، سوف يتعلم وظيفة المكافأة من الملاحظة، والتي يمكن استخدامها بعد ذلك في التعلم المعزز. إذا اكتشف أن الهدف هو ضرب مسمار بمطرقة، فسوف يتجاهل الرمشات والخدوش من المعلم، لأنها لا علاقة لها بالهدف.
سيحاول التعلم بالتقليد (المعروف أيضًا باسم الاستنساخ السلوكي) تقليد المعلم مباشرة . ويمكن تحقيق ذلك من خلال التعلم الخاضع للإشراف وحده. سيحاول الذكاء الاصطناعي نسخ كل إجراء، حتى الإجراءات غير ذات الصلة مثل الرمش أو الخدش، على سبيل المثال، أو حتى الأخطاء. يمكنك استخدام RL هنا أيضًا، ولكن فقط إذا كان لديك وظيفة المكافأة.
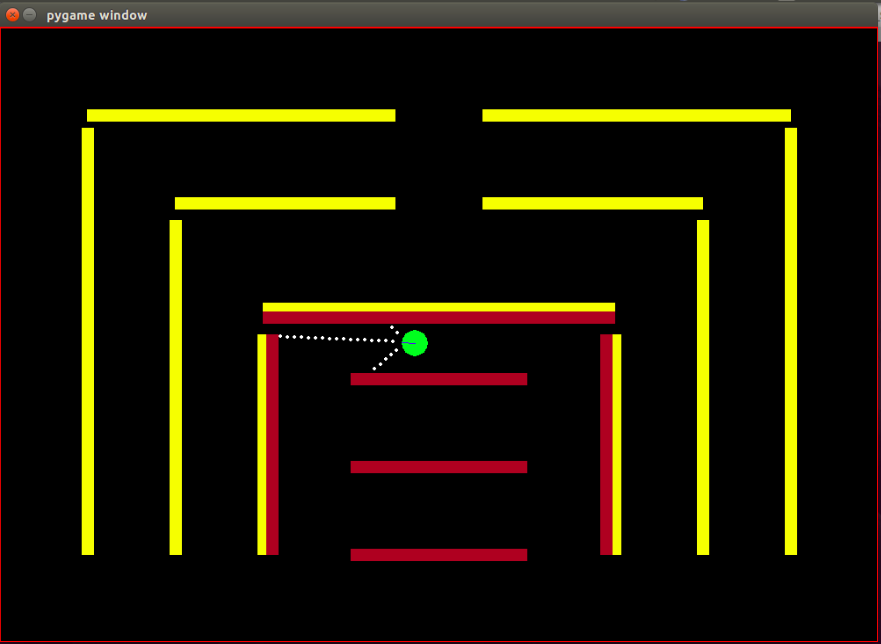
الوكيل: الوكيل عبارة عن دائرة خضراء صغيرة يُشار إلى اتجاه رأسها بخط أزرق.
أجهزة الاستشعار: تم تجهيز الوكيل بثلاثة أجهزة استشعار للألوان عن بعد، وهذه هي المعلومات الوحيدة التي يمتلكها الوكيل عن البيئة.
مساحة الحالة: تتكون حالة الوكيل من 8 سمات يمكن ملاحظتها-
لاحظ أنه يتم إجراء التسوية للتأكد من أن كل قيمة ميزة يمكن ملاحظتها تقع في النطاق [0،1] وهو شرط ضروري لتقارب مكافآت خوارزمية IRL.
المكافآت: يتم حساب المكافأة بعد كل إطار كمجموعة خطية مرجحة لقيم الميزات التي تمت ملاحظتها في هذا الإطار المعني. هنا يتم حساب المكافأة r_t في الإطار t بواسطة المنتج النقطي لمتجه الوزن w مع متجه قيم الميزة في الإطار t، وهو متجه الحالة phi_t. بحيث r_t = w^T x phi_t.
الإجراءات المتاحة: مع كل إطار جديد، يتخذ الوكيل خطوة للأمام تلقائيًا، ويمكن للإجراءات المتاحة إما تحويل الوكيل إلى اليسار أو اليمين أو عدم القيام بأي شيء يمثل خطوة بسيطة للأمام، لاحظ أن إجراءات الدوران تتضمن الحركة للأمام أيضًا، ليس التناوب في المكان.
العوائق: تتكون البيئة من جدران صلبة ملونة عمداً بألوان مختلفة. يتمتع الوكيل بقدرات استشعار الألوان التي تساعده على التمييز بين أنواع العوائق. تم تصميم البيئة بهذه الطريقة لسهولة اختبار خوارزمية IRL.
تم إصلاح موضع (حالة) البداية للروبوت، لأنه وفقًا لخوارزمية IRL، من الضروري أن تكون حالة البداية هي نفسها لجميع التكرارات.
لاحظ أن خوارزمية RL تم اعتمادها بالكامل من هذا المنشور بواسطة Matt Harvey مع تغييرات طفيفة، وبالتالي فمن المنطقي تمامًا التحدث عن التغييرات التي أجريتها، وأيضًا حتى إذا كان القارئ مرتاحًا مع RL، فإنني أوصي بشدة بإلقاء نظرة سريعة عليها هذا المنشور من أجل فهم كيفية حدوث التعلم المعزز.
تم تغيير البيئة بشكل كبير، حيث أصبح العميل قادرًا ليس فقط على استشعار المسافة من المستشعرات الثلاثة ولكن أيضًا استشعار لون العوائق، مما يمكنه من التمييز بين العوائق. كما أصبح الوكيل الآن أصغر حجمًا وأصبحت نقاط الاستشعار الخاصة به أقرب للحصول على دقة أكبر وأداء أفضل. كان لا بد من جعل العوائق ثابتة في الوقت الحالي، من أجل تبسيط عملية اختبار خوارزمية IRL، وقد يؤدي هذا إلى الإفراط في تجهيز البيانات، لكنني لست قلقًا بشأن ذلك في الوقت الحالي. كما تمت مناقشته أعلاه، تمت زيادة مجموعة المراقبة أو حالة الوكيل من 3 إلى 8، مع تضمين ميزة التعطل في حالة الوكيل. تم تغيير هيكل المكافأة بالكامل، وأصبحت المكافأة الآن عبارة عن مجموعة خطية مرجحة من هذه الميزات الثمانية، ولم يعد الوكيل يتلقى مكافأة -500 عند الاصطدام بالعوائق، بل أصبحت قيمة ميزة الاصطدام هي +1 وعدم الاصطدام هي 0 و يتعين على الخوارزمية تحديد الوزن الذي يجب تخصيصه لهذه الميزة بناءً على سلوك الخبير.
كما هو مذكور في مدونة مات، الهدف هنا ليس فقط تعليم وكيل RL كيفية تجنب العقبات، أعني لماذا نفترض أي شيء عن بنية المكافأة، دع بنية المكافأة يتم تحديدها بالكامل بواسطة الخوارزمية من عروض الخبراء ومعرفة السلوك يتم تحقيق إعداد معين من المكافآت!
الميزات أو الوظائف الأساسية phi_i والتي يمكن ملاحظتها بشكل أساسي في الحالة. تمت مناقشة الميزات الموجودة في المشكلة الحالية أعلاه في قسم مساحة الحالة. نحن نحدد phi(s_t) ليكون مجموع كل توقعات الميزات phi_i بحيث:
المكافآت r_t - مجموعة خطية من قيم الميزات التي تمت ملاحظتها في كل حالة s_t.
توقعات الميزة mu(pi) للسياسة pi هي مجموع قيم الميزات المخصومة phi(s_t).
توقعات ميزة السياسة مستقلة عن الأوزان، فهي تعتمد فقط على الولايات التي تمت زيارتها أثناء التشغيل (وفقًا للسياسة) وعلى عامل الخصم جاما رقم بين 0 و1 (على سبيل المثال 0.9 في حالتنا). للحصول على توقعات الميزات الخاصة بالسياسة، يتعين علينا تنفيذ السياسة في الوقت الفعلي مع الوكيل وتسجيل الحالات التي تمت زيارتها وقيم الميزات التي تم الحصول عليها.
يتم الحصول على توقعات ميزات سياسة الخبراء أو توقعات ميزات الخبراء mu(pi_E) من خلال الإجراءات التي يتم اتخاذها وفقًا لسلوك الخبراء. نحن ننفذ هذه السياسة بشكل أساسي ونحصل على توقعات الميزات كما نفعل مع أي سياسة أخرى. يتم إعطاء توقعات ميزة الخبير إلى خوارزمية IRL للعثور على الأوزان بحيث تشبه وظيفة المكافأة المقابلة للأوزان وظيفة المكافأة الأساسية التي يحاول الخبير تعظيمها (بلغة RL المعتادة).
توقعات ميزات السياسة العشوائية - قم بتنفيذ سياسة عشوائية واستخدم توقعات الميزات التي تم الحصول عليها لتهيئة IRL.
احتفظ بقائمة توقعات ميزات السياسة التي نحصل عليها بعد كل تكرار.
في البداية لدينا فقط pi^1 -> توقعات ميزات السياسة العشوائية.
ابحث عن المجموعة الأولى من أوزان w^1 عن طريق التحسين المحدب، والمشكلة مشابهة لمصنف SVM الذي يحاول إعطاء علامة 1+ لميزة الخبراء المتوقعة. و -1 تسمية لجميع ميزات السياسة الأخرى المتوقعة.-
بحيث،
شرط الإنهاء:
الآن، بمجرد أن نحصل على الأوزان بعد تكرار واحد للتحسين، أي بمجرد أن نحصل على وظيفة مكافأة جديدة، علينا أن نتعلم السياسة التي تؤدي إليها وظيفة المكافأة هذه. هذا هو نفس القول، ابحث عن سياسة تحاول تعظيم وظيفة المكافأة التي تم الحصول عليها. للعثور على هذه السياسة الجديدة، يتعين علينا تدريب خوارزمية التعلم المعزز باستخدام وظيفة المكافأة الجديدة هذه، وتدريبها حتى تتقارب قيم Q، للحصول على تقدير مناسب للسياسة.
بعد أن تعلمنا سياسة جديدة، يتعين علينا اختبار هذه السياسة عبر الإنترنت، من أجل الحصول على توقعات الميزات المقابلة لهذه السياسة الجديدة. ثم نضيف توقعات الميزات الجديدة هذه إلى قائمة توقعات الميزات لدينا ونستمر في التكرار التالي لخوارزمية IRL حتى التقارب.
دعونا الآن نحاول الحصول على تعليق من التعليمات البرمجية. يرجى العثور على الكود الكامل في git repo هذا. هناك بشكل أساسي 3 ملفات يجب أن تقلق بشأنها -
manualControl.py - للحصول على توقعات الميزات للخبير عن طريق تحريك الوكيل يدويًا. قم بتشغيل "python3 manualControl.py"، وانتظر حتى يتم تحميل واجهة المستخدم الرسومية ثم استخدم مفاتيح الأسهم لبدء التحرك. امنحه السلوك الذي تريد نسخه (لاحظ أن السلوك الذي تتوقع نسخه يجب أن يكون معقولاً مع مساحة الحالة المحددة). قد تكون الحيلة الجيدة هي أن تفترض نفسك بدلاً من الوكيل وتفكر فيما إذا كنت ستتمكن من تمييز السلوك المحدد في ضوء مساحة الحالة الحالية فقط. راجع الملف المصدر لمزيد من التفاصيل.
Toy_car_IRL.py - الملف الرئيسي، حيث يوجد رمز IRL. دعونا نلقي نظرة على الكود خطوة بخطوة-
{% جوهر 51542f27e97eac1559a00f06b757df1a %}
قم باستيراد التبعيات وتحديد المعلمات المهمة، وتغيير السلوك كما هو مطلوب. الإطارات هي عدد الإطارات التي تريد تشغيل خوارزمية RL. 100 ألف جيد ويستغرق حوالي ساعتين.
{% جوهر 49b602b9a3090773d492310175bb2e3f %}
قم بإنشاء فئة irlAgent سهلة الاستخدام، والتي تأخذ في الاعتبار السلوكيات العشوائية والخبيرة، والمعلمات المهمة الأخرى كما هو موضح.
{% جوهر bc17c06a07ea3b915827e89f3c13a2ae %}
تستخدم وظيفة getRLAgentFE IRL_helper من المتعلم المعزز لتدريب نموذج جديد والحصول على توقعات الميزات من خلال تشغيل هذا النموذج لـ 2000 تكرار. إنها تُرجع بشكل أساسي توقعات الميزات لكل مجموعة من الأوزان (W) التي تحصل عليها.
{% جوهر ce0ef99adc652c7469f1bc4303a3af41 %}
لتحديث القاموس الذي نحتفظ فيه بسياساتنا التي حصلنا عليها وقيمها الخاصة. حيث t = (weights.tanspose)x(expert-newPolicy).
{% الجوهر be55a5d44e5b1ff13dfa68cc96f6b1b1 %}
تنفيذ خوارزمية IRL الرئيسية التي تمت مناقشتها أعلاه. {% جوهر 9faee18596467ee33ac5d91fd0cb675f %}
التحسين المحدب لتحديث الأوزان عند استلام سياسة جديدة، يقوم بشكل أساسي بتعيين علامة +1 لسياسة الخبراء وعلامة -1 لجميع السياسات الأخرى وتحسين الأوزان تحت القيود المذكورة. لمعرفة المزيد عن موقع التحسين هذا، قم بزيارة الموقع
{% جوهر 30cf6c59b9915054f3cf6d278f8f8a11 %}
قم بإنشاء irlAgent وقم بتمرير المعلمات المطلوبة، ثم اختر من بين نوع سلوك الخبير الذي ترغب في معرفة أوزانه، ثم قم بتشغيل وظيفة optimWeightFinder(). لاحظ أنني حصلت بالفعل على توقعات الميزات للسلوكيات الحمراء والصفراء والبنية. بعد انتهاء الخوارزمية، سوف تحصل على قائمة بالأوزان في ملف 'weights-red/yellow/brown.txt'، مع السلوك المحدد المعني. الآن، لاختيار أفضل سلوك ممكن من جميع الأوزان التي تم الحصول عليها، قم بتشغيل النماذج المحفوظة في الدليل save-models_BEHAVIOR/evaluatedPolicies/، يتم حفظ النماذج بالتنسيق التالي 'saved-models_'+ BEHAVIOR +'/evaluatedPolicies/'+ رقم التكرار+ '-164-150-100-50000-100000' + '.h5' . في الأساس، ستحصل على أوزان مختلفة لتكرارات مختلفة، قم أولاً بتشغيل النماذج لمعرفة النموذج الذي يحقق أفضل أداء، ثم لاحظ رقم التكرار لهذا النموذج، والأوزان التي تم الحصول عليها المقابلة لرقم التكرار هذا هي الأوزان التي تجعلك أقرب إلى الخبير سلوك.
ثم هناك ملفات ربما لا تحتاج إلى تحديثها/تعديلها، على الأقل بالنسبة للمحتوى الموجود في هذه المقالة -
بعد حوالي 10-15 تكرارًا، تتقارب الخوارزمية في جميع السلوكيات الأربعة المختلفة المختارة، وحصلت على النتائج التالية:
| الأوزان | أنا أحب الأصفر | أنا أحب براون | أنا أحب الأحمر | أنا أحب الاصطدام |
|---|---|---|---|---|
| w1 (منطقة الاستشعار اليسرى) | -0.0880 | -0.2627 | 0.2816 | -0.5892 |
| W2 (منطقة الاستشعار الأوسط) | -0.0624 | 0.0363 | -0.5547 | -0.3672 |
| W3 (منطقة المستشعر الأيمن) | 0.0914 | 0.0931 | -0.2297 | -0.4660 |
| W4 (اللون الأسود) | -0.0114 | 0.0046 | 0.6824 | -0.0299 |
| W5 (اللون الأصفر) | 0.6690 | -0.1829 | -0.3025 | -0.1528 |
| W6 (اللون البني) | -0.0771 | 0.6987 | 0.0004 | -0.0368 |
| W7 (اللون الأحمر) | -0.6650 | -0.5922 | 0.0525 | -0.5239 |
| W8 (تحطم) | -0.2897 | -0.2201 | -0.0075 | 0.0256 |
يتم تعيين قيمة سلبية عالية للوزن الذي ينتمي إلى ميزة الارتطام في السلوكيات الثلاثة الأولى، لأن سلوكيات الخبراء الثلاثة هذه لا تريد أن يصطدم الوكيل بالعوائق. في حين أن وزن نفس الميزة في السلوك الأخير، أي Nasty bot، يكون إيجابيًا، حيث يدعو سلوك الخبراء إلى الاصطدام.
من الواضح أن أوزان ميزات اللون تتعلق بسلوك الخبير، وتكون مرتفعة عندما يكون هذا اللون مرغوبًا، وإلا تكون قيمة منخفضة/سلبية إلى حد ما للحصول على سلوك مميز.
تعتبر أوزان ميزة المسافة غامضة جدًا (غير بديهية) ومن الصعب جدًا اكتشاف بعض الأنماط ذات المغزى في الأوزان. الشيء الوحيد الذي أود الإشارة إليه هو أنه من الممكن أيضًا التمييز بين السلوكيات في اتجاه عقارب الساعة وعكس اتجاه عقارب الساعة في الإعداد الحالي، وستحمل ميزات المسافة هذه المعلومات.
لاحظ أنه من المهم جدًا أن تفكر أولاً فيما إذا كنت كإنسان ستتمكن من التمييز بين السلوكيات المحددة مع توفر مجموعة الحالة الحالية (الملاحظات) أثناء تصميم هيكل المشكلة. وإلا فإنك قد تجبر الخوارزمية على العثور على أوزان مختلفة دون تزويدها بالمعلومات الضرورية بشكل كامل.
إذا كنت تريد حقًا الدخول إلى IRL، فإنني أوصي بأن تحاول فعليًا تعليم الوكيل سلوكًا جديدًا (قد يتعين عليك تعديل البيئة لذلك، نظرًا لأن السلوكيات المميزة المحتملة لمجموعة الحالة الحالية قد تم استغلالها بالفعل، حسنًا على الأقل بالنسبة لي).
قم بتثبيت تبعيات Pygame باستخدام:
sudo apt install mercurial libfreetype6-dev libsdl-dev libsdl-image1.2-dev libsdl-ttf2.0-dev libsmpeg-dev libportmidi-dev libavformat-dev libsdl-mixer1.2-dev libswscale-dev libjpeg-dev
ثم قم بتثبيت Pygame نفسه:
pip3 install hg+http://bitbucket.org/pygame/pygame
هذا هو المحرك الفيزيائي الذي تستخدمه المحاكاة. لقد مرت للتو بعملية إعادة كتابة مهمة جدًا (الإصدار 5) لذا تحتاج إلى الحصول على الإصدار 4 الأقدم. تمت كتابة الإصدار 4 من أجل Python 2 لذا هناك بضع خطوات إضافية.
ارجع إلى منزلك أو التنزيلات واحصل على Pymunk 4:
wget https://github.com/viblo/pymunk/archive/pymunk-4.0.0.tar.gz
فكها:
tar zxvf pymunk-4.0.0.tar.gz
التحديث من بايثون 2 إلى 3:
cd pymunk-pymukn-4.0.0/pymunk
2to3 -w *.py
تثبيته:
cd .. python3 setup.py install
عد الآن إلى المكان الذي قمت فيه باستنساخ reinforcement-learning-car وتأكد من أن كل شيء يعمل باستخدام python3 learning.py السريع. إذا رأيت شاشة تظهر بها نقطة صغيرة تطير حول الشاشة، فأنت جاهز للانطلاق!
أولا، تحتاج إلى تدريب نموذج. سيؤدي هذا إلى حفظ الأوزان في مجلد saved-models . قد تحتاج إلى إنشاء هذا المجلد قبل تشغيل . يمكنك تدريب النموذج عن طريق تشغيل:
python3 learning.py
قد يستغرق الأمر من ساعة إلى 36 ساعة لتدريب النموذج، اعتمادًا على مدى تعقيد الشبكة وحجم عينتك. ومع ذلك، فإنه سيخرج أوزانًا كل 25000 إطار، حتى تتمكن من الانتقال إلى الخطوة التالية في وقت أقل بكثير.
قم بتحرير ملف playing.py لتغيير اسم المسار للنموذج الذي تريد تحميله. آسف لذلك، أعلم أنه يجب أن يكون وسيطة سطر الأوامر.
ثم شاهد السيارة وهي تقود نفسها حول العوائق!
python3 playing.py
هذا كل ما في الأمر.


