مقلوب المصفوفة باستخدام شبكة عصبية.
يمثل المصفوفات العكسية تحديات فريدة للشبكات العصبية ، ويرجع ذلك في المقام الأول إلى القيود المتأصلة في أداء العمليات الحسابية الدقيقة مثل الضرب والانقسام على التنشيطات. غالبًا ما تحتاج الشبكات الكثيفة التقليدية إلى مساعدة في هذه المهام ، لأنها ليست مصممة بشكل صريح للتعامل مع التعقيدات التي تنطوي عليها انعكاس المصفوفة. أظهرت التجارب التي أجريت مع الشبكات العصبية الكثيفة البسيطة صعوبات كبيرة في تحقيق انقلابات مصفوفة دقيقة. على الرغم من المحاولات المختلفة لتحسين عملية الهندسة المعمارية والتدريب ، غالبًا ما تحتاج النتائج إلى تحسين. ومع ذلك ، فإن الانتقال إلى بنية أكثر تعقيدًا-شبكة متبقية من 7 طبقات (RESNET)-يمكن أن يؤدي إلى تحسينات ملحوظة في الأداء.
أثبتت بنية RESNET ، المعروفة بقدرتها على تعلم التمثيلات العميقة من خلال الاتصالات المتبقية ، فعاليتها في معالجة انقلاب المصفوفة. مع الملايين من المعلمات ، يمكن لهذه الشبكة التقاط أنماط معقدة داخل البيانات التي لا يمكن أن تكون النماذج البسيطة. ومع ذلك ، يأتي هذا التعقيد بتكلفة: هناك حاجة إلى بيانات تدريب كبيرة للتعميم الفعال.
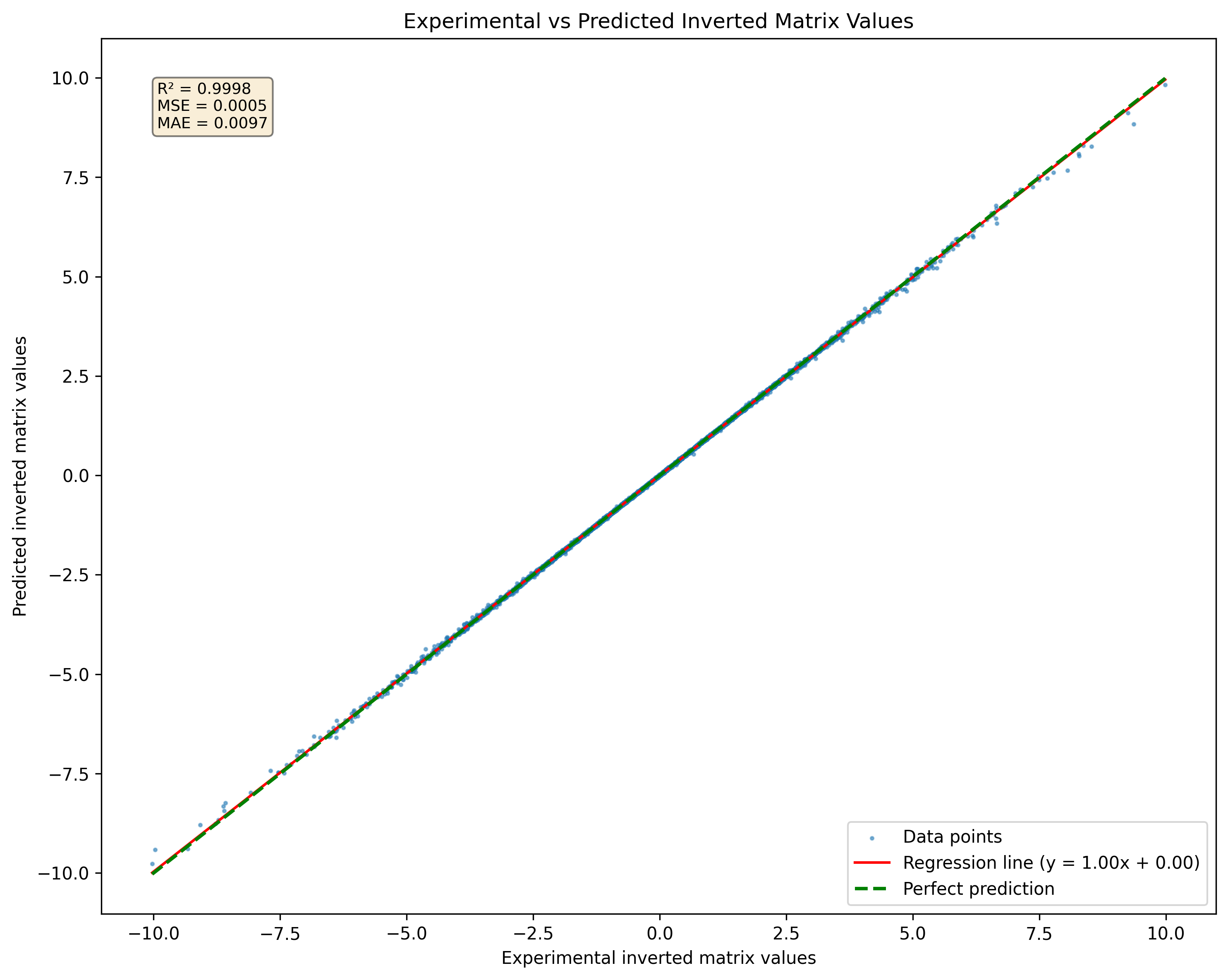 الشكل 1: تصور شبكة عصبية تنبأت مصفوفة مقلوبة لمجموعة من المصفوفات 3x3 لم يسبق لها مثيل في مجموعة البيانات
الشكل 1: تصور شبكة عصبية تنبأت مصفوفة مقلوبة لمجموعة من المصفوفات 3x3 لم يسبق لها مثيل في مجموعة البيانات
لتقييم أداء الشبكة العصبية في التنبؤ بانقلابات المصفوفة ، يتم استخدام وظيفة خسارة محددة:
في هذه المعادلة:
الهدف من ذلك هو تقليل الفرق بين مصفوفة الهوية ومنتج المصفوفة الأصلية وعكسها المتوقع. تعمل وظيفة الخسارة هذه بشكل فعال على قرب العكسي المتوقع من أن تكون دقيقة.
بالإضافة إلى ذلك ، إذا
توفر وظيفة الخسارة هذه مزايا مميزة على وظائف الخسارة التقليدية مثل متوسط الخطأ التربيعي (MSE) أو الخطأ المطلق (MAE).
القياس المباشر لدقة الانعكاس الهدف الأساسي لانعكاس المصفوفة هو التأكد من أن ناتج المصفوفة وعكسها يعطي مصفوفة الهوية. تلتقط وظيفة الخسارة هذا المطلب مباشرة عن طريق قياس الانحراف عن مصفوفة الهوية. في المقابل ، تركز MSE و MAE على الاختلافات بين القيم المتوقعة والقيم الحقيقية دون معالجة الخاصية بشكل صريح للخاصية الأساسية لانعكاس المصفوفة.
التركيز على النزاهة الهيكلية باستخدام وظيفة الخسارة التي تقيم مدى قرب المنتج AA - 1AA - 1 إلى II ، فإنه يؤكد الحفاظ على السلامة الهيكلية للمصفوفات المعنية. هذا مهم بشكل خاص في التطبيقات التي يكون فيها الحفاظ على العلاقات الخطية أمرًا بالغ الأهمية. لا تفسر وظائف الخسارة التقليدية مثل MSE و MAE هذا الجانب الهيكلي ، مما قد يؤدي إلى حلول تقلل من الخطأ ولكنها تفشل في تلبية المتطلبات الرياضية لانعكاس المصفوفة.
قابلية التطبيق على المصفوفات غير المنحسية ، تفترض وظيفة الخسارة بطبيعتها أن المصفوفات المقلوبة غير فرعية (أي قابلة للانقلاب). في السيناريوهات التي توجد فيها المصفوفات الفردية ، قد تؤدي وظائف الخسارة التقليدية إلى نتائج مضللة لأنها لا تفسر استحالة الحصول على عكس صحيح. تبرز وظيفة الخسارة المقترحة هذا القيد من خلال إنتاج أخطاء أكبر عند محاولة عكس المصفوفات الفردية.
أحد القيود المهمة عند استخدام الشبكات العصبية لانعكاس المصفوفة هو عدم قدرتها على التعامل مع المصفوفات المفرد بشكل فعال. المصفوفة الفردية ليس لها عكس. وبالتالي ، فإن أي محاولة من شبكة عصبية للتنبؤ بعكس هذه المصفوفات ستؤدي إلى نتائج غير صحيحة. في الممارسة العملية ، إذا تم تقديم مصفوفة فريدة أثناء التدريب أو الاستدلال ، فقد تظل الشبكة إخراج نتيجة ، لكن هذا الإخراج لن يكون صالحًا أو ذا معنى. يؤكد هذا القيد على أهمية ضمان أن بيانات التدريب تتكون من المصفوفات غير المنحدرة كلما كان ذلك ممكنًا.
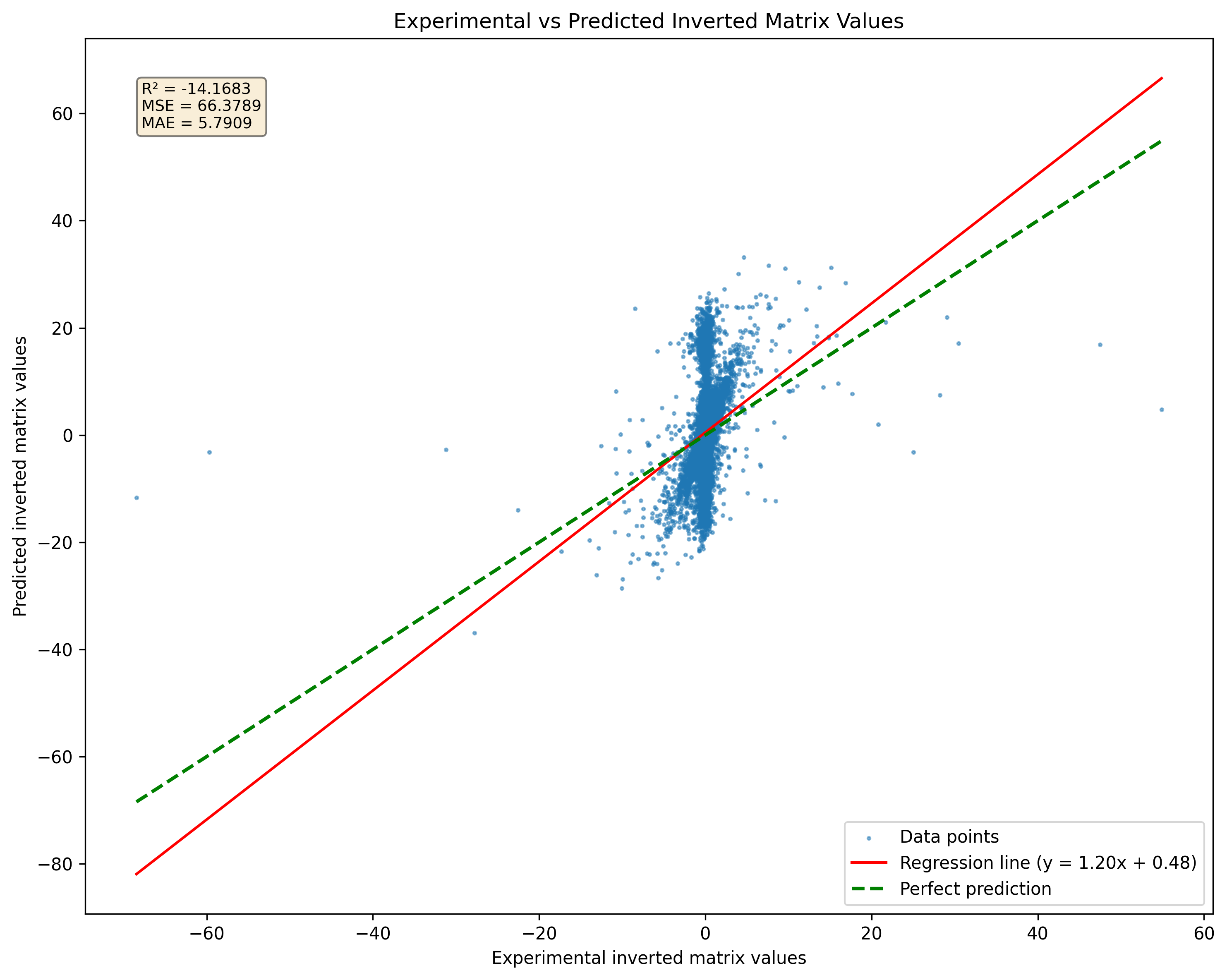 الشكل 2: مقارنة بين التنبؤ النموذجية للمصفوفات المفرد مقابل الزائفة. لاحظ أن النموذج سيؤدي إلى نتائج بغض النظر عن تفرد المصفوفة.
الشكل 2: مقارنة بين التنبؤ النموذجية للمصفوفات المفرد مقابل الزائفة. لاحظ أن النموذج سيؤدي إلى نتائج بغض النظر عن تفرد المصفوفة.
تشير الأبحاث إلى أن نموذج RESNET يمكنه حفظ كمية جيدة من العينات دون فقدان كبير في الدقة. ومع ذلك ، فإن زيادة حجم مجموعة البيانات إلى 10 ملايين عينة قد تؤدي إلى تكاليف شديدة. يحدث هذا التورط على الرغم من الحجم الكبير للبيانات ، مما يبرز أن زيادة حجم مجموعة البيانات ببساطة لا يضمن تحسين التعميم للنماذج المعقدة. لمعالجة هذا التحدي ، يمكن اعتماد استراتيجية توليد البيانات المستمرة. بدلاً من الاعتماد على مجموعة بيانات ثابتة ، يمكن إنشاء عينات على الطيران وتغذيها على الشبكة عند إنشائها. لا يوفر هذا النهج ، وهو أمر بالغ الأهمية في التخفيف من التورط ، مجموعة متنوعة من أمثلة التدريب فحسب ، بل يضمن أيضًا تعرض النموذج لمجموعة بيانات متطورة باستمرار.
باختصار ، على الرغم من أن انعكاس المصفوفة يمثل تحديًا بطبيعته للشبكات العصبية بسبب القيود في العمليات الحسابية ، إلا أن الاستفادة من البنية المتقدمة مثل RESNET يمكن أن تحقق نتائج أفضل. ومع ذلك ، يجب النظر بعناية في متطلبات البيانات والمخاطر المفرطة. يمكن أن يؤدي توليد عينات التدريب بشكل مستمر إلى تعزيز عملية التعلم للنموذج وتحسين الأداء في مهام انعكاس المصفوفة. يحافظ هذا الإصدار على نغمة غير شخصية أثناء مناقشة التحديات والاستراتيجيات في تدريب الشبكات العصبية لانعكاس المصفوفة.
يتم توزيع الانتقالات العميقة بموجب ترخيص LGPLV3
لمعرفة المزيد بالتفصيل كيف تعمل المرخصة ، يرجى قراءة الملف "ترخيص" أو الانتقال إلى "http://www.gnu.org/licenses/lgpl-3.0.html"
DeepMatrixinversion حاليًا ملك لـ Giuseppe Marco Randazzo.
لتثبيت مستودع DeepMatrixInversion ، يمكنك الاختيار بين استخدام الشعر أو PIP أو PIPX أدناه هي التعليمات لكلا الطريقتين.
git clone https://github.com/gmrandazzo/DeepMatrixInversion.git
cd DeepMatrixInversion
python3 -m venv .venv
. .venv/bin/activate
pip install poetry
poetry install
سيؤدي ذلك إلى إعداد بيئتك مع جميع الحزم اللازمة لتشغيل DeepMatrixinversion.
قم بإنشاء بيئة افتراضية وتثبيت DePppmatrixinversion مع PIP
python3 -m venv .venv
. .venv/bin/activate
pip install git+https://github.com/gmrandazzo/DeepMatrixInversion.git
إذا كنت تفضل استخدام PIPX ، مما يسمح لك بتثبيت تطبيقات Python في بيئات معزولة ، اتبع هذه الخطوات:
python3 -m pip install --user pipx
apt-get install pipx
brew install pipx
sudo dnf install pipx
PIPX تثبيت git+https: //github.com/gmrandazzo/deepmatrixinversion.git
لتدريب نموذج يمكن أن يؤدي انعكاس المصفوفة ، سوف تستخدم الأمر dmxtrain. يتيح لك هذا الأمر تحديد المعلمات المختلفة التي تتحكم في عملية التدريب ، مثل حجم المصفوفات ونطاق القيم ومدة التدريب.
dmxtrain --msize < matrix_size > --rmin < min_value > --rmax < max_value > --epochs < number_of_epochs > --batch_size < size_of_batches > --n_repeats < number_of_repeats > --mout < output_model_path > dmxtrain --msize --rmin -1 --rmax 1 --epochs 5000 --batch_size 1024 --n_repeats 3 --mout ./Model_3x3
--msize <matrix_size>: Specifies the size of the square matrices to be generated for training. For example, 3 for 3x3 matrices.
--rmin <min_value>: Sets the minimum value for the random elements in the matrices. For instance, -1 will allow negative values.
--rmax <max_value>: Sets the maximum value for the random elements in the matrices. For example, 1 will limit values to a maximum of 1.
--epochs <number_of_epochs>: Defines how many epochs (complete passes through the training dataset) to run during training. A higher number typically leads to better performance; in this case, 5000.
--batch_size <size_of_batches>: Determines how many samples are processed before the model is updated. A batch size of 1024 means that 1024 samples are used in each iteration.
--n_repeats <number_of_repeats>: Indicates how many times to repeat the training process with different random seeds or initializations. This can help ensure robustness; for instance, repeating 3 times.
--mout <output_model_path>: Specifies where to save the trained model. In this example, it saves to ./Model_3x3.
بمجرد تدريب النموذج الخاص بك ، يمكنك استخدامه لإجراء انعكاس المصفوفة على مصفوفات الإدخال الجديدة. أمر الاستدلال هو dmxinvert ، والذي يأخذ مصفوفة الإدخال ويؤدي إلى عكسه.
تحذير: يمكن لـ Dmxinvert عكس مصفوفة أكبر من تلك المستخدمة لتدريب النموذج من خلال صيغة انعكاس كتلة مصفوفة Sherman-Morrison-Woodbury. تعمل هذه الميزة فقط مع المصفوفات التي يمكن تقسيم حجم الكتلة على حجم كتلة التدريب النموذجية دون تذكير. الميزة تجريبية للغاية وقد تحتاج إلى مراجعة.
dmxinvert --inputmx <input_matrix_file> --inverseout <output_csv_file> --model <model_path>
dmxinvert --inputmx input_matrix.csv --inverseout output_inverse.csv --model ./Model_3x3_*
--inputmx <input_matrix_file>: Specifies the path to the input matrix file that you want to invert. This file should contain a valid matrix format (e.g., CSV).
--inverseout <output_csv_file>: Indicates where to save the resulting inverted matrix. The output will be saved in CSV format.
--model <model_path>: Provides the path to the trained model that will be used for performing the inversion.
يتم إنشاء مجموعة بيانات اصطناعية مع مصفوفة الإدخال ومقلوب الإخراج Trough DMX DMXDatAsetGenerator
dmxdatasetgenerator 3 10 -1 1 test_3x3_range_-1+1
سيؤدي ذلك إلى توليد 10 مصفوفات بحجم 3 × 3 مع أرقام في نطاق من -1 إلى +1.
dmxdatasetgenerator [matrix size] [number of samples] [range min] [range max] [outname_prefix]
ثم يمكن التحقق من صحة مجموعة البيانات باستخدام dmxDatAsetVerify
dmxdatasetverify test_3x3_range_-1+1_matrices_3x3.mx test_3x3_range_-1+1_matrices_inverted_3x3.mx invertible
Dataset valid.
dmxdatasetverify [dataset matrix to invert] [dataset matrix inverted] [type: invertible or singular]
يجب تنسيق ملف مصفوفة الإدخال على النحو التالي:
0.24077047370124594,-0.5012474139608847,-0.5409542929032876
-0.6257864520097793,-0.030705148203584942,-0.13723920334288975
-0.48095686716222064,0.19220406568380666,-0.34750000491973854
END
0.4575368007107925,0.9627977617090073,-0.4115240560547333
0.5191433428806012,0.9391491187187144,-0.000952683255491138
-0.17757763984424968,-0.7696584771443977,-0.9619759413623306
END
-0.49823271153034154,0.31993947803488587,0.9380291202366384
0.443652116558352,0.16745965310481048,-0.267270356721347
0.7075720067281346,-0.3310912886946993,-0.12013367141105102
END
تمثل كل كتلة من الأرقام مصفوفة منفصلة تليها علامة نهاية تشير إلى نهاية تلك المصفوفة.


