LLaMA Omni
1.0.0
المؤلفون: Qingkai Fang ، Shoutao Guo ، Yan Zhou ، Zhengrui MA ، Shaolei Zhang ، Yang Feng*
Llama-Omni هو نموذج باللغة الكلام التي تم بناؤها على Llama-3.1-8b-instruct. وهو يدعم تفاعلات الكلام منخفضة الجودة وعالية الجودة ، مما يولد في وقت واحد كل من استجابات النص والكلام بناءً على تعليمات الكلام.
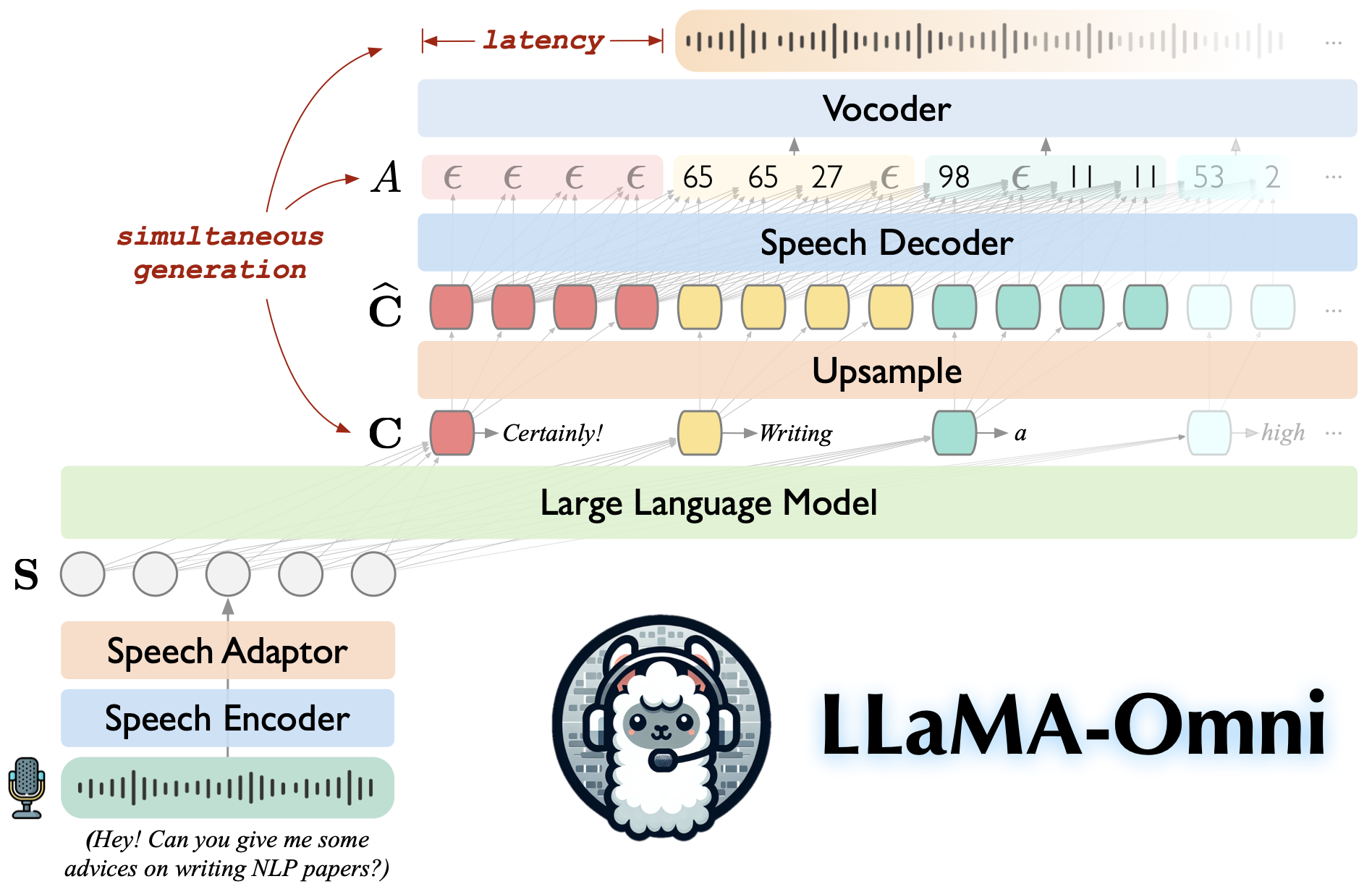
بنيت على Llama-3.1-8b-instruct ، مما يضمن استجابات عالية الجودة.
تفاعل الكلام منخفضة الكلية مع زمن انتقال يصل إلى 226 مللي ثانية.
الجيل المتزامن من كل من الاستجابات النصية والكلام.
♻ تدرب في أقل من 3 أيام باستخدام 4 وحدات معالجة الرسومات فقط.
استنساخ هذا المستودع.
git clone https://github.com/ictnlp/llama-omnicd llama-omni
تثبيت الحزم.
كوندا Create -N Llama -Omni Python = 3.10 كوندا تفعيل لاما أومني PIP تثبيت PIP == 24.0 تثبيت PIP -e.
تثبيت fairseq .
git clone https://github.com/pytorch/fairseqcd fairseq تثبيت PIP -e. -لا البناء
تثبيت flash-attention .
PIP تثبيت Flash-attn-لا بنية-معزلة
قم بتنزيل طراز Llama-3.1-8B-Omni من؟ Huggingface.
قم بتنزيل نموذج Whisper-large-v3 .
استيراد الهمس
model = whisper.load_model ("BARGE-V3" ، download_root = "models/keep_encoder/")قم بتنزيل Vocoder HIFI-Gan المستندة إلى الوحدة.
wget https://dl.fbaipublicfiles.com/fairseq/speech_to_speech/vocoder/code_hifigan/mhubert_vp_en_es_fr_it3_400k_layer11_km1000_lj/g_00500000 -p vocoder/ wget https://dl.fbaipublicfiles.com/fairseq/speech_to_speech/vocoder/code_hifigan/mhubert_vp_en_es_fr_it3_400k_layer11_km1000_lj/config.json -p vocoder/
إطلاق وحدة تحكم.
Python -M omni_speade.serve.controller -Hostral 0.0.0.0 -PORT 10000
قم بتشغيل خادم الويب Gradio.
Python -M omni_speesh.serve.gradio_web_server-controller http: // localhost: 10000-port 8000-model-list-mod
إطلاق عامل نموذج.
Python -M omni_speade.serve.model_worker-host 0.0.0.0-controller http: // localhost: 10000-Port 40000-Worker http: // localhost: 40000-model-path llama-33.1-8b- omni -Model-Name Llama-3.1-8b-Omni-S2S
تفضل بزيارة http: // localhost: 8000/وتفاعل مع llama-3.1-8b-omni!
ملاحظة: نظرًا لعدم استقرار تشغيل تشغيل الصوت في Gradio ، قمنا فقط بتنفيذ تخليق الصوت البث دون تمكين التشغيل التلقائي. إذا كان لديك حل جيد ، فلا تتردد في تقديم العلاقات العامة. شكرًا!
لتشغيل الاستدلال محليًا ، يرجى تنظيم ملفات تعليمات الكلام وفقًا للتنسيق في دليل omni_speech/infer/examples ، ثم الرجوع إلى البرنامج النصي التالي.
bash omni_speech/استنتاج/run.sh omni_speech/استنتاج/أمثلة
يتم إصدار الكود الخاص بنا تحت ترخيص Apache-2.0. نموذجنا مخصص لأغراض البحث الأكاديمي فقط ولا يمكن استخدامه للأغراض التجارية.
أنت حر في استخدام هذا النموذج وتعديله وتوزيعه في الإعدادات الأكاديمية ، شريطة استيفاء الشروط التالية:
الاستخدام غير التجاري : لا يجوز استخدام النموذج لأي أغراض تجارية.
الاقتباس : إذا كنت تستخدم هذا النموذج في بحثك ، فيرجى الاستشهاد بالعمل الأصلي.
لأي استفسارات الاستخدام التجاري أو للحصول على ترخيص تجاري ، يرجى الاتصال بـ [email protected] .
llava: قاعدة الشفرة التي بنيت عليها.
SLAM-LLM: نقترض بعض التعليمات البرمجية حول تشفير الكلام ومحول الكلام.
إذا كان لديك أي أسئلة ، فلا تتردد في تقديم مشكلة أو الاتصال بـ [email protected] .
إذا كان عملنا مفيدًا لك ، فيرجى الإشارة إلى:
@article{fang-etal-2024-llama-omni,
title={LLaMA-Omni: Seamless Speech Interaction with Large Language Models},
author={Fang, Qingkai and Guo, Shoutao and Zhou, Yan and Ma, Zhengrui and Zhang, Shaolei and Feng, Yang},
journal={arXiv preprint arXiv:2409.06666},
year={2024}
} 

