ainovelprompter
1.0.0
يمكن لـ AI Novel Prompter إنشاء مطالبات كتابة للروايات بناءً على الخصائص المحددة للمستخدم.
AI Novel Prompter هو تطبيق سطح مكتب مصمم لمساعدة الكتاب على إنشاء مطالبات متسقة ومنظمة لمنظمة AI مثل ChatGpt و Claude. تساعد الأداة في إدارة عناصر القصة وتفاصيل الشخصية وإنشاء مطالبات منسقة بشكل صحيح لمواصلة روايتك.
القابلة للتنفيذ على بناء/بن قابلة للتنفيذ
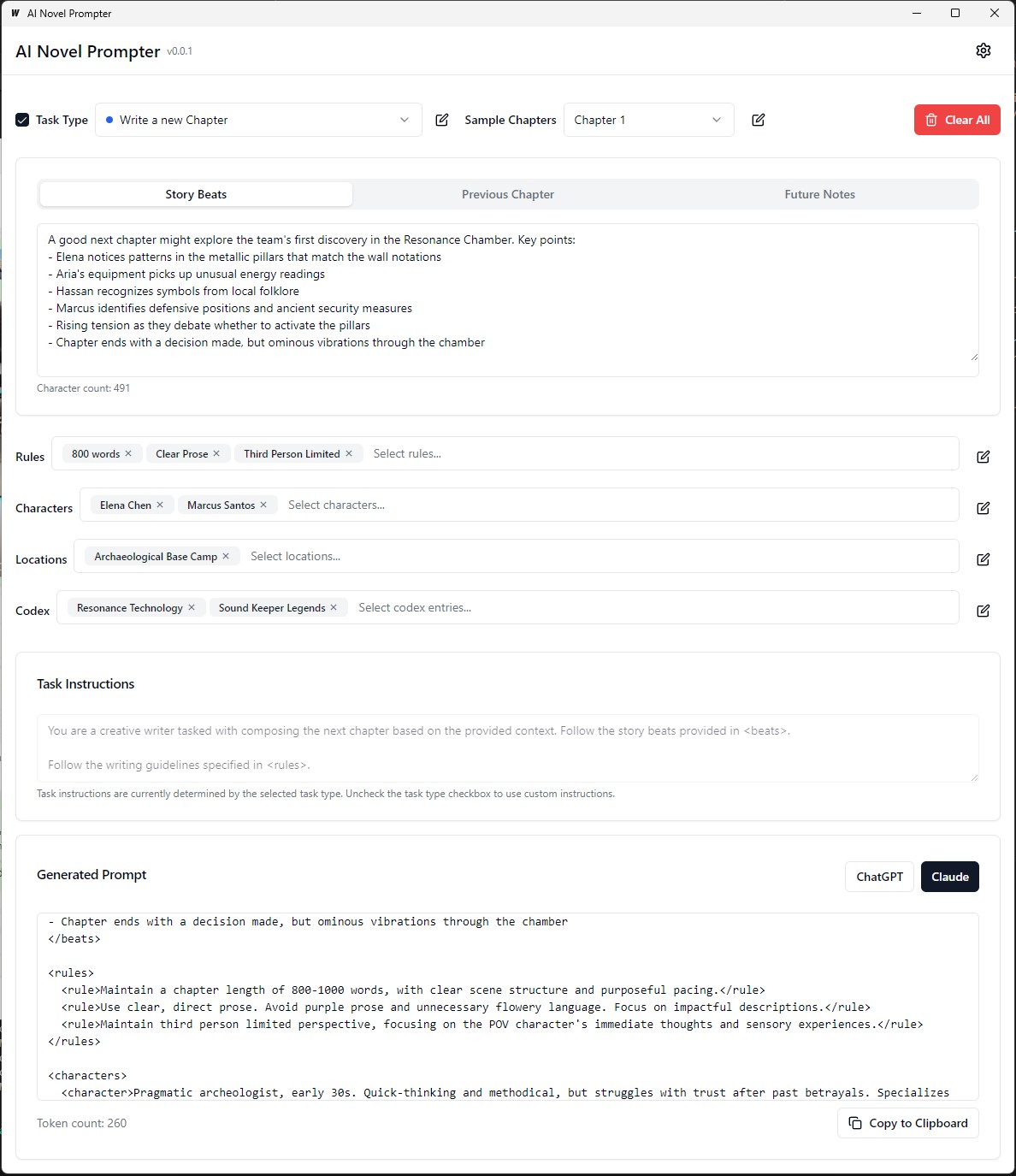
يمكن تحرير كل فئة وحفظها وإعادة استخدامها عبر مطالبات مختلفة:
الواجهة الأمامية :
الخلفية :
.ai-novel-prompter # Clone the repository
git clone [repository-url]
# Install frontend dependencies
cd frontend
npm install
# Build and run the application
cd ..
wails dev لإنشاء حزمة وضع الإنتاج القابلة لإعادة التوزيع ، استخدم wails build .
wails buildالقابلة للتنفيذ على بناء/بن قابلة للتنفيذ
أو توليدها مع:
wails build -nsisيمكن القيام بذلك لنظام التشغيل Mac وكذلك شاهد الجزء الأخير من هذا الدليل
سيكون التطبيق المبني متاحًا في دليل build .
الإعداد الأولي :
إنشاء موجه :
توليد الإخراج :
قبل تشغيل التطبيق ، تأكد من تثبيت ما يلي:
git clone https://github.com/danielsobrado/ainovelprompter.git
cd ainovelprompter
انتقل إلى دليل server :
cd server
تثبيت تبعيات GO:
go mod download
قم بتحديث ملف config.yaml بتكوين قاعدة البيانات الخاصة بك.
قم بتشغيل ترحيل قاعدة البيانات:
go run cmd/main.go migrate
ابدأ خادم الواجهة الخلفية:
go run cmd/main.go
انتقل إلى دليل client :
cd ../client
تثبيت تبعيات الواجهة الأمامية:
npm install
ابدأ خادم تطوير الواجهة الأمامية:
npm start
http://localhost:3000 للوصول إلى التطبيق. git clone https://github.com/danielsobrado/ainovelprompter.git
cd ainovelprompter
قم بتحديث ملف docker-compose.yml بتكوين قاعدة البيانات الخاصة بك.
ابدأ التطبيق باستخدام Docker Compose:
docker-compose up -d
http://localhost:3000 للوصول إلى التطبيق. server/config.yaml .client/src/config.ts . لبناء الواجهة الأمامية للإنتاج ، قم بتشغيل الأمر التالي في دليل client :
npm run build
سيتم إنشاء ملفات جاهزة للإنتاج في دليل client/build .
يوفر هذا الدليل الصغير إرشادات حول كيفية تثبيت postgreSQL على النظام الفرعي لـ Windows لـ Linux (WSL) ، إلى جانب خطوات لإدارة أذونات المستخدم واستكشاف المشكلات الشائعة.
Open WSL Terminal : قم بتشغيل توزيع WSL الخاص بك (الموصى به Ubuntu).
تحديث الحزم :
sudo apt updateتثبيت postgresql :
sudo apt install postgresql postgresql-contribتحقق من التثبيت :
psql --versionاضبط كلمة مرور المستخدم postgresql :
sudo passwd postgresإنشاء قاعدة بيانات :
createdb mydbقاعدة بيانات الوصول :
psql mydbاستيراد الجداول من ملف SQL :
psql -U postgres -q mydb < /path/to/file.sqlقائمة قواعد البيانات والجداول :
l # List databases
dt # List tables in the current databaseتبديل قاعدة البيانات :
c dbnameإنشاء مستخدم جديد :
CREATE USER your_db_user WITH PASSWORD ' your_db_password ' ;امتيازات المنح :
ALTER USER your_db_user CREATEDB;الدور غير موجود خطأ : التبديل إلى مستخدم "postgres":
sudo -i -u postgres
createdb your_db_nameتم رفض الإذن بإنشاء تمديد : تسجيل الدخول كـ "postgres" وتنفيذ:
CREATE EXTENSION IF NOT EXISTS pg_trgm; خطأ غير معروف للمستخدم : تأكد من أنك تستخدم مستخدم نظام معترف به أو الرجوع بشكل صحيح إلى مستخدم postgresql داخل بيئة SQL ، وليس عبر sudo .
لإنشاء بيانات تدريب مخصصة لضبط نموذج اللغة لمحاكاة أسلوب الكتابة لجورج ماكدونالد ، تبدأ العملية بالحصول على النص الكامل لأحد رواياته ، "The Princess and the Goblin" ، من Project Gutenberg. ثم يتم تقسيم النص إلى دقات قصة فردية أو لحظات رئيسية باستخدام مطالبة ترشد الذكاء الاصطناعي لإنشاء كائن JSON لكل إيقاع ، والتقاط المؤلف ، والنغمة العاطفية ، ونوع الكتابة ، والمقتطفات النصية الفعلية.
بعد ذلك ، يتم استخدام GPT-4 لإعادة كتابة كل من هذه القصة في كلماتها الخاصة ، مما يولد مجموعة موازية من بيانات JSON مع معرفات فريدة تربط كل إيقاع معاد كتابته إلى نظيره الأصلي. لتبسيط البيانات وجعلها أكثر فائدة للتدريب ، يتم تعيين مجموعة واسعة من النغمات العاطفية إلى مجموعة أصغر من النغمات الأساسية باستخدام وظيفة Python. ثم يتم استخدام ملفين JSON (الإيقاعات الأصلية وإعادة الكتابة) لإنشاء مطالبات تدريب ، حيث يُطلب من النموذج إعادة صياغة النص الذي تم إنشاؤه GPT-4 بأسلوب المؤلف الأصلي. أخيرًا ، يتم تنسيق هذه المطالبات ومخرجاتها المستهدفة في ملفات JSONL و JSON ، وهي جاهزة لاستخدامها في صياغة نموذج اللغة لالتقاط أسلوب الكتابة المميز لـ MacDonald.
في المثال السابق ، تضمنت عملية توليد النص المعاد صياغتها باستخدام نموذج لغة بعض المهام اليدوية. كان على المستخدم توفير نص الإدخال يدويًا ، وتشغيل البرنامج النصي ، ثم مراجعة الإخراج الذي تم إنشاؤه لضمان جودته. إذا لم يستوفي الإخراج المعايير المطلوبة ، فسيحتاج المستخدم إلى إعادة إعادة عملية التوليد يدويًا بمعلمات مختلفة أو إجراء تعديلات على نص الإدخال.
ومع ذلك ، مع الإصدار المحدث من وظيفة process_text_file ، كانت العملية بأكملها مؤتمتة بالكامل. تهتم الوظيفة بقراءة الملف النصي للإدخال ، وتقسيمه إلى فقرات ، وإرسال كل فقرة تلقائيًا إلى نموذج اللغة لإعادة الصياغة. إنه يشتمل على مختلف عمليات الفحص وآليات إعادة المحاولة للتعامل مع الحالات التي لا يفي فيها الإخراج الذي تم إنشاؤه بالمعايير المحددة ، مثل احتواء العبارات غير المرغوب فيها ، أو كونها قصيرة جدًا أو طويلة جدًا ، أو تتكون من فقرات متعددة.
تتضمن عملية الأتمتة العديد من الميزات الرئيسية:
استئنافًا من الفقرة الأخيرة التي تمت معالجتها: إذا تم مقاطعة البرنامج النصي أو يحتاج إلى تشغيل عدة مرات ، فإنه يتحقق تلقائيًا من ملف الإخراج ويستأنف المعالجة من الفقرة الأخيرة التي نجحت. هذا يضمن عدم فقد التقدم ويمكن أن يلتقط البرنامج النصي من حيث توقف.
آلية إعادة المحاولة مع البذور العشوائية ودرجة الحرارة: إذا فشلت إعادة صياغة تم إنشاؤها في تلبية المعايير المحددة ، فإن البرنامج النصي يعيد تلقائيًا عملية التوليد إلى عدد محدد من المرات. مع كل إعادة المحاولة ، يغير بشكل عشوائي قيم البذور ودرجة الحرارة لإدخال التباين في الاستجابات التي تم إنشاؤها ، مما يزيد من فرص الحصول على ناتج مرضي.
حفظ التقدم: يحفظ البرنامج النصي التقدم إلى ملف الإخراج كل عدد محدد من الفقرات (على سبيل المثال ، كل 500 فقرات). هذه الحماية من فقدان البيانات في حالة وجود أي انقطاع أو أخطاء أثناء معالجة ملف نصي كبير.
التسجيل التفصيلي والملخص: يوفر البرنامج النصي معلومات تسجيل مفصلة ، بما في ذلك فقرة الإدخال ، والإخراج المولدة ، ومحاولات إعادة المحاولة ، وأسباب الفشل. كما أنه يولد ملخصًا في النهاية ، حيث يعرض العدد الإجمالي للفقرات ، والفقرات التي تم تجديدها بنجاح ، وفقرات تخطيت ، وإجمالي العدد من إعادة المحاولة.
لإنشاء بيانات تدريب مخصصة لـ ORPO لصقل نموذج اللغة لمحاكاة أسلوب الكتابة لجورج ماكدونالد.
يجب أن تكون بيانات الإدخال بتنسيق JSONL ، مع كل سطر يحتوي على كائن JSON يتضمن المستثيل والمختار. (من الضبط الدقيق السابق) لاستخدام البرنامج النصي ، تحتاج إلى إعداد عميل Openai باستخدام مفتاح API الخاص بك وتحديد مسارات ملفات الإدخال والإخراج. سيقوم تشغيل البرنامج النصي بمعالجة ملف JSONL وإنشاء ملف CSV مع أعمدة للاستجابة المطالبة والاستجابة المختارة ، واستجابة مرفوضة تم إنشاؤها. يوفر البرنامج النصي التقدم كل 100 خط ويمكن أن يستأنف من حيث توقف إذا توقف. عند الانتهاء ، يوفر ملخصًا لإجمالي الخطوط المعالجة والخطوط المكتوبة والخطوط المتخطئة وتفاصيل إعادة المحاولة.
جودة مجموعة البيانات: 95 ٪ من النتائج تعتمد على جودة مجموعة البيانات. تعد مجموعة البيانات النظيفة ضرورية لأن بعض البيانات السيئة التي يمكن أن تؤذي النموذج.
مراجعة البيانات اليدوية: يمكن لتنظيف وتقييم مجموعة البيانات تحسين النموذج بشكل كبير. هذه خطوة تستغرق وقتًا طويلاً ولكنها ضرورية لأنه لا يمكن لأي قدر من ضبط المعلمات إصلاح مجموعة بيانات معيبة.
يجب ألا تتحسن معلمات التدريب ولكن منع تدهور النموذج. في مجموعات البيانات القوية ، يجب أن يكون الهدف هو تجنب التداعيات السلبية أثناء توجيه النموذج. لا يوجد معدل التعلم الأمثل.
قيود النماذج وقيود الأجهزة: قد تتيح النماذج الأكبر (33B المعلمات) التمكين بشكل أفضل ولكن تتطلب ما لا يقل عن 48 جيجا بايت VRAM ، مما يجعلها غير عملية لغالبية الإعدادات المنزلية.
تراكم التدرج وحجم الدُفعة: يساعد تراكم التدرج على تقليل التورط من خلال تعزيز التعميم عبر مجموعات البيانات المختلفة ، ولكنه قد يقلل من الجودة بعد بضع دفعات.
يعد حجم مجموعة البيانات أكثر أهمية لضبط نموذج الأساس من النموذج الذي تم ضبطه جيدًا. قد يؤدي التحميل الزائد للنموذج المدفوع جيدًا مع البيانات المفرطة إلى تخفيض صقله السابق.
يبدأ جدول معدل التعلم المثالي بمرحلة الاحماء ، ويحمل ثابتًا لعصر ، ثم يتناقص تدريجياً باستخدام جدول جيب التمام.
رتبة النموذج والتعميم: يؤثر مقدار المعلمات القابلة للتدريب على تفاصيل النموذج وتعميمه. تعميم النماذج ذات الرتبة المنخفضة بشكل أفضل ولكن تفقد التفاصيل.
قابلية تطبيق LORA: ينطبق صقل المعلمة الموفرة للمعلمة (PEFT) على نماذج اللغة الكبيرة (LLMS) وأنظمة مثل الانتشار المستقر (SD) ، مما يدل على تعدد استخداماته.
ساعد مجتمع Unloth في حل العديد من القضايا مع Llama3 Finetuning. فيما يلي بعض النقاط الرئيسية التي يجب وضعها في الاعتبار:
الرموز المزدوجة BOS : الرموز المزدوجة BOS أثناء العصر الجليدي يمكن أن يكسر الأشياء. Unloth يعمل تلقائيًا على إصلاح هذه المشكلة.
تحويل GGUF : تحويل GGUF مكسور. كن حذرًا من BOS المزدوج واستخدم وحدة المعالجة المركزية بدلاً من GPU للتحويل. يحتوي Unloth على تحويلات GGUF التلقائية المدمجة.
أوزان قاعدة عربات التي تجرها الدواب : بعض أوزان قاعدة Llama 3 (وليس الإرشادات) هي "عربات التي تجرها الدواب" (غير مدربة): <|reserved_special_token_{0->250}|> <|eot_id|> <|start_header_id|> <|end_header_id|> هذا يمكن أن يسبب نتائج NANS و DUGGY. Unloth يصلح هذا تلقائيا.
مطالبة النظام : وفقًا لمجتمع Unloth ، فإن إضافة موجه النظام يجعل من الإقامة في إصدار Enstruct (وربما الإصدار الأساسي) أفضل بكثير.
قضايا القياس : قضايا القياس شائعة. راجع هذه المقارنة التي توضح أنه يمكنك الحصول على أداء جيد مع LLAMA3 ، ولكن استخدام القياس الكمي الخاطئ يمكن أن يضر الأداء. للتأليف ، استخدم bitsandbytes NF4 لتعزيز الدقة. بالنسبة إلى GGUF ، استخدم إصدارات I قدر الإمكان.
نماذج السياق الطويلة : نماذج السياق الطويلة مدربة تدريباً سيئًا. إنهم ببساطة يمتدون الحبل theta ، وأحيانًا بدون أي تدريب ، ثم يتدربون على مجموعة بيانات متسلسلة غريبة لجعلها مجموعة بيانات طويلة. هذا النهج لا يعمل بشكل جيد. كان قياس السياق الطويل الناعم والمستمر أفضل بكثير إذا كان التحجيم من 8K إلى 1M طول السياق.
لحل بعض هذه المشكلات ، استخدم Unloth ل llama3 finetuning.
عند صياغة نموذج لغة لإعادة الصياغة بأسلوب المؤلف ، من المهم تقييم جودة وفعالية إعادة صياغة تم إنشاؤها.
يمكن استخدام مقاييس التقييم التالية لتقييم أداء النموذج:
Bleu (تقييم ثنائي اللغة):
sacrebleu في Python.from sacrebleu import corpus_bleu; bleu_score = corpus_bleu(generated_paraphrases, [original_paragraphs])Rouge (defrendy الموجه نحو الاستدعاء لتقييم gisting):
rouge في Python.from rouge import Rouge; rouge = Rouge(); scores = rouge.get_scores(generated_paraphrases, original_paragraphs)الحيرة:
perplexity = model.perplexity(generated_paraphrases)تدابير stylometric:
stylometry في بيثون.from stylometry import extract_features; features = extract_features(generated_paraphrases)لدمج مقاييس التقييم هذه في خط أنابيب Axolotl ، اتبع هذه الخطوات:
قم بإعداد بيانات التدريب الخاصة بك عن طريق إنشاء مجموعة بيانات من الفقرات من أعمال المؤلف المستهدف وتقسيمها إلى مجموعات التدريب والتحقق من الصحة.
صقل نموذج لغتك باستخدام مجموعة التدريب ، وبعد النهج الذي تمت مناقشته سابقًا.
قم بإنشاء إعادة صياغة للفقرات في مجموعة التحقق من الصحة باستخدام النموذج الذي تم ضبطه.
قم بتنفيذ مقاييس التقييم باستخدام المكتبات المعنية ( sacrebleu و rouge و stylometry ) وحساب الدرجات لكل إعادة صياغة تم إنشاؤها.
إجراء التقييم البشري من خلال جمع التصنيفات والتعليقات من المقيمين البشريين.
قم بتحليل نتائج التقييم لتقييم جودة وأسلوب إعادة صياغة تم إنشاؤها واتخاذ قرارات مستنيرة لتحسين عملية ضبطك.
إليك مثال على كيفية دمج هذه المقاييس في خط أنابيبك:
from sacrebleu import corpus_bleu
from rouge import Rouge
from stylometry import extract_features
# Fine-tune the model using the training set
fine_tuned_model = train_model ( training_data )
# Generate paraphrases for the validation set
generated_paraphrases = generate_paraphrases ( fine_tuned_model , validation_data )
# Calculate evaluation metrics
bleu_score = corpus_bleu ( generated_paraphrases , [ original_paragraphs ])
rouge = Rouge ()
rouge_scores = rouge . get_scores ( generated_paraphrases , original_paragraphs )
perplexity = fine_tuned_model . perplexity ( generated_paraphrases )
stylometric_features = extract_features ( generated_paraphrases )
# Perform human evaluation
human_scores = collect_human_evaluations ( generated_paraphrases )
# Analyze and interpret the results
analyze_results ( bleu_score , rouge_scores , perplexity , stylometric_features , human_scores )تذكر تثبيت المكتبات اللازمة (Sacrebleu و Rouge و Stylometry) وتكييف الكود لتناسب تنفيذك في Axolotl أو ما شابه.
في هذه التجربة ، استكشفت القدرات والاختلافات بين نماذج الذكاء الاصطناعى المختلفة في إنشاء نص مكون من 1500 كلمة استنادًا إلى مطالبة مفصلة. لقد اختبرت النماذج من https://chat.lmsys.org/ ، chatgpt4 ، كلود 3 opus ، وبعض الطرز المحلية في استوديو LM. قام كل نموذج بإنشاء النص ثلاث مرات لمراقبة التباين في مخرجاته. قمت أيضًا بإنشاء موجه منفصل لتقييم كتابة التكرار الأول من كل نموذج وطلبت ChatGPT 4 و كلود أوبوس 3 تقديم ملاحظات.
من خلال هذه العملية ، لاحظت أن بعض النماذج تظهر تباينًا أعلى بين عمليات الإعدام ، بينما يميل البعض الآخر إلى استخدام صيغة مماثلة. كانت هناك أيضًا اختلافات كبيرة في عدد الكلمات التي تم إنشاؤها وكمية الحوار والأوصاف والفقرات التي ينتجها كل نموذج. كشفت ردود الفعل التقييم أن ChatGPT تقترح نثرًا أكثر "صقلًا" ، بينما يوصي كلود بدرجة أقل من النثر الأرجواني. استنادًا إلى هذه النتائج ، قمت بتجميع قائمة من الوجبات السريعة لدمجها في المطالبة التالية ، مع التركيز على هياكل الجملة المتنوعة ، والأفعال القوية ، والتحولات الفريدة على الزخارف الخيالية ، ونغمة متسقة ، وصوت الراوي المتميز ، وسرعة الانخراط. تقنية أخرى يجب مراعاتها وهي طلب التعليقات ثم إعادة كتابة النص بناءً على تلك التعليقات.
أنا منفتح على التعاون مع الآخرين لمزيد من المطالبات المميزة لكل نموذج واستكشاف قدراتهم في مهام الكتابة الإبداعية.
النماذج لها تحيزات تنسيق متأصلة. بعض النماذج تفضل الواصلات في القوائم ، والبعض الآخر العلامات النجمية. عند استخدام هذه النماذج ، من المفيد عكس تفضيلاتها للمخرجات المتسقة.
ميول التنسيق:
يفضل Llama 3 قوائم بعناوين وعلامات جريئة.
مثال: عنوان حالة العنوان الجريء
سرد العناصر مع النجمة بعد اثنين من الخطوط الجديدة
قائمة العناصر مفصولة بخط جديد
القائمة التالية
المزيد من عناصر قائمة
إلخ...
أمثلة قليلة:
الالتزام السريع للنظام:
نافذة السياق:
الرقابة:
ذكاء:
تناسق:
القوائم والتنسيق:
إعدادات الدردشة:
إعدادات خط الأنابيب:
Llama 3 مرن وذكي ولكن لديه سياق وتقتبس القيود. ضبط طرق الطالب وفقا لذلك.
جميع التعليقات موضع ترحيب. افتح مشكلة أو إرسال طلب سحب إذا وجدت أي أخطاء أو لديك توصيات للتحسين.
تم ترخيص هذا المشروع بموجب: ترخيص الإسناد-noncommercial-noderivivities (BY-NC-ND) راجع: https://creativecommons.org/licenses/by-nc-nd/4.0/deed.en


