paper2slides
1.0.0
تحويل أي أوراق arxiv إلى شرائح باستخدام نماذج لغة كبيرة (LLMS)! هذه الأداة مفيدة لإمساك الأفكار الرئيسية للأوراق البحثية بسرعة.
بعض الأمثلة على الشرائح التي تم إنشاؤها هي: Word2Vec ، GAN ، Transformer ، VIT ، سلسلة الفكرة ، النجمة ، DPO ، وعلم الذكاء الاصطناعي. انظر العديد من الأمثلة الأخرى للشرائح التي تم إنشاؤها في العرض التجريبي.
سيقوم البرنامج النصي بتنزيل الملفات من الإنترنت (ARXIV) ، وإرسال المعلومات إلى API Openai ، وتجميعها محليًا. يرجى توخي الحذر بشأن المحتوى الذي يتم مشاركته والمخاطر المحتملة. إذا كان لديك معرف Arxiv محدد تهتم به ولا ترغب في تشغيل الكود بنفسك ، فأخبرني في "المناقشات" وسأكون سعيدًا بإضافة الشرائح إلى القائمة التجريبية.
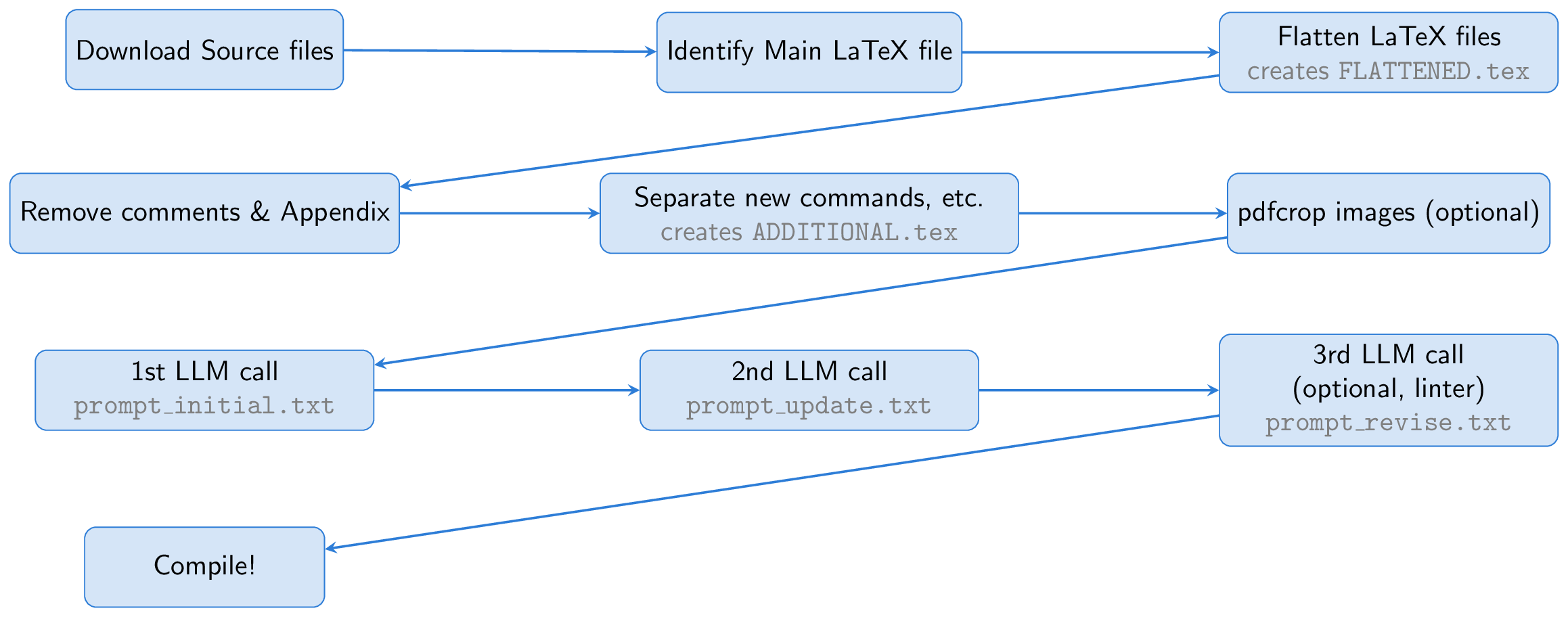
تبدأ العملية بتنزيل الملفات المصدر لورقة Arxiv. يتم تحديد ملف اللاتكس الرئيسي وتسويته ، ودمج جميع ملفات الإدخال في مستند واحد ( FLATTENED.tex ). نقوم بتعامل مع هذا الملف المدمج عن طريق إزالة التعليقات والملحق. يشكل هذا الملف المعالجة مسبقًا ، إلى جانب تعليمات لإنشاء شرائح جيدة ، أساسًا للمطالبة.
تتمثل إحدى الأفكار الرئيسية في استخدام Beamer لإنشاء الشرائح ، مما يتيح لنا البقاء بالكامل داخل النظام البيئي اللاتكس. يحول هذا النهج المهمة بشكل أساسي إلى تمرين تلخيص: تحويل ورقة مطاطية طويلة إلى LaTex Beamer Beamer. يمكن لـ LLM استنتاج محتوى الأرقام من التسميات التوضيحية الخاصة بها وإدراجها في الشرائح ، مما يلغي الحاجة إلى قدرات الرؤية.
للمساعدة في LLM ، نقوم بإنشاء ملف يسمى ADDITIONAL.tex ، والذي يحتوي على جميع الحزم اللازمة ، تعريفات NewCommand ، وغيرها من إعدادات اللاتكس المستخدمة في الورقة. بما في ذلك هذا الملف مع input{ADDITIONAL.tex} في المقدمة تقصره ويجعل إنشاء الشرائح أكثر موثوقية ، خاصة بالنسبة للأوراق النظرية مع العديد من الأوامر المخصصة.
تقوم LLM بإنشاء رمز Beamer من مصدر LaTeX ، ولكن نظرًا لأن الجولة الأولى قد تواجه مشكلات ، فإننا نطلب من LLM أن يحدد الناتج ذاتيًا وصقله. اختياريًا ، تتضمن الخطوة الثالثة استخدام Linter للتحقق من الكود الذي تم إنشاؤه ، مع إعادة النتائج إلى LLM لمزيد من التصحيحات (كانت هذه الخطوة المبتذلة مستوحاة من عالم الذكاء الاصطناعي). أخيرًا ، يتم تجميع رمز Beamer في عرض تقديمي لـ PDF باستخدام pdflatex.
يقوم برنامج all.zsh بأتمتة العملية بأكملها ، وعادةً ما يكمل في أقل من بضع دقائق مع GPT-4O لورقة واحدة.
المتطلبات هي:
requestsarxivopenaiarxiv-latex-cleanerpdflatexخطوات للتثبيت:
استنساخ هذا المستودع:
git clone https://github.com/takashiishida/paper2slides.git
cd paper2slidesتثبيت حزم بيثون المطلوبة:
pip install requests arxiv openai arxiv-latex-cleaner تأكد من تثبيت pdflatex ومتاح في مسار نظامك. تحقق اختياريا ما إذا كان يمكنك تجميع عينة test.tex بواسطة pdflatex test.tex . تحقق مما إذا كان test.pdf يتم توليده بشكل صحيح. تحقق اختياريا chktex و pdfcrop تعمل.
قم بإعداد مفتاح API Openai:
export OPENAI_API_KEY= ' your-api-key ' all.shيقوم هذا البرنامج النصي بأتمتة عملية تنزيل ورقة Arxiv ومعالجتها وتحويلها إلى عرض تقديمي Beamer.
bash all.sh < arxiv_id > استبدل <arxiv_id> بمعرف ورقة Arxiv المطلوب. يمكن تحديد المعرف من عنوان URL: معرف https://arxiv.org/abs/xxxx.xxxx هو xxxx.xxxx .
يمكنك أيضًا تشغيل البرامج النصية Python بشكل فردي لمزيد من التحكم.
قم بتنزيل ومعالجة ملفات مصدر Arxiv
python arxiv2tex.py < arxiv_id > يقوم هذا البرنامج النصي بتنزيل الملفات المصدر لورقة Arxiv المحددة ، ويستخرجها ، ويعالج ملف اللاتكس الرئيسي. سيتم حفظ النتائج في source/<arxiv_id>/FLATTENED.tex و source/<arxiv_id>/ADDITIONAL.tex .
تحويل اللاتكس إلى Beamer
python tex2beamer.py --arxiv_id < arxiv_id > يقرأ هذا البرنامج النصي ملفات اللاتكس المصنعة ويعد شرائح Beamer. هذا هو المكان الذي نستخدم فيه API Openai. ندعو مرتين ، أولاً لإنشاء رمز Beamer ، ثم لتفسير رمز Beamer ذاتيًا. اختياريا استخدم الأعلام التالية: --use_linter و --use_pdfcrop . سيتم حفظ المطالبات المرسلة إلى LLM وسيتم حفظ الرد من LLM في tex2beamer.log . سيتم حفظ سجل linter في source/<arxiv_id>/linter.log .
تحويل Beamer إلى PDF
python beamer2pdf.py < arxiv_id >يقوم هذا البرنامج النصي بتجميع ملف Beamer في عرض تقديمي لـ PDF.
يتم حفظ المطالبات في prompt_initial.txt و prompt_update.txt و prompt_revise.txt ولكن لا تتردد في ضبطها على احتياجاتك. أنها تحتوي على عنصر نائب يسمى PLACEHOLDER_FOR_FIGURE_PATHS . سيتم استبدال هذا بمسارات الشكل المستخدمة في الورقة. نريد التأكد من استخدام المسارات بشكل صحيح في رمز Beamer. غالبًا ما يرتكب LLM أخطاء ، لذلك نقوم بتضمين هذا بشكل صريح في المطالبة.
يبلغ معدل النجاح حوالي 90 في المائة في تجربتي (قد تفشل التجميع أو قد يكون مسار الصورة خاطئًا في بعض الحالات). إذا واجهت أي مشاكل أو لديك أي اقتراحات للتحسينات ، فلا تتردد في إخباري!


