lang2sql
1.0.0
يوفر هذا الريبو دليلًا خطوة بخطوة وقالب لإعداد لغة طبيعية لمولد رمز SQL باستخدام API Opneai.
البرنامج التعليمي متاح أيضًا على المتوسط.
التحديث الأخير: 7 يناير ، 2024
قدم التطور السريع لنماذج اللغة الطبيعية ، وخاصة نماذج اللغة الكبيرة (LLMS) ، إمكانيات عديدة لمختلف المجالات. أحد أكثر التطبيقات شيوعًا هو استخدام LLMs للترميز. على سبيل المثال ، تعتبر LLMA الخاصة بـ Openai's ChatGPT و META LLAMA LLMS التي توفر لغة طبيعية حديثة لمولدات التعليمات البرمجية. إحدى حالات الاستخدام المحتملة هي لغة طبيعية لمولد رمز SQL ، والتي يمكن أن تساعد المهنيين غير التقنيين الذين لديهم طلبات بيانات بسيطة ونأمل أن يمكّن فرق البيانات من التركيز على المزيد من المهام كثيفة البيانات. يركز هذا البرنامج التعليمي على إعداد لغة لمولد رمز SQL باستخدام API Openai.
أحد التطبيقات المحتملة هو chatbot يمكنه الاستجابة لاستفسارات المستخدم مع البيانات ذات الصلة (الشكل 1). يمكن دمج chatbot مع قناة الركود باستخدام تطبيق Python الذي يؤدي الخطوات التالية:
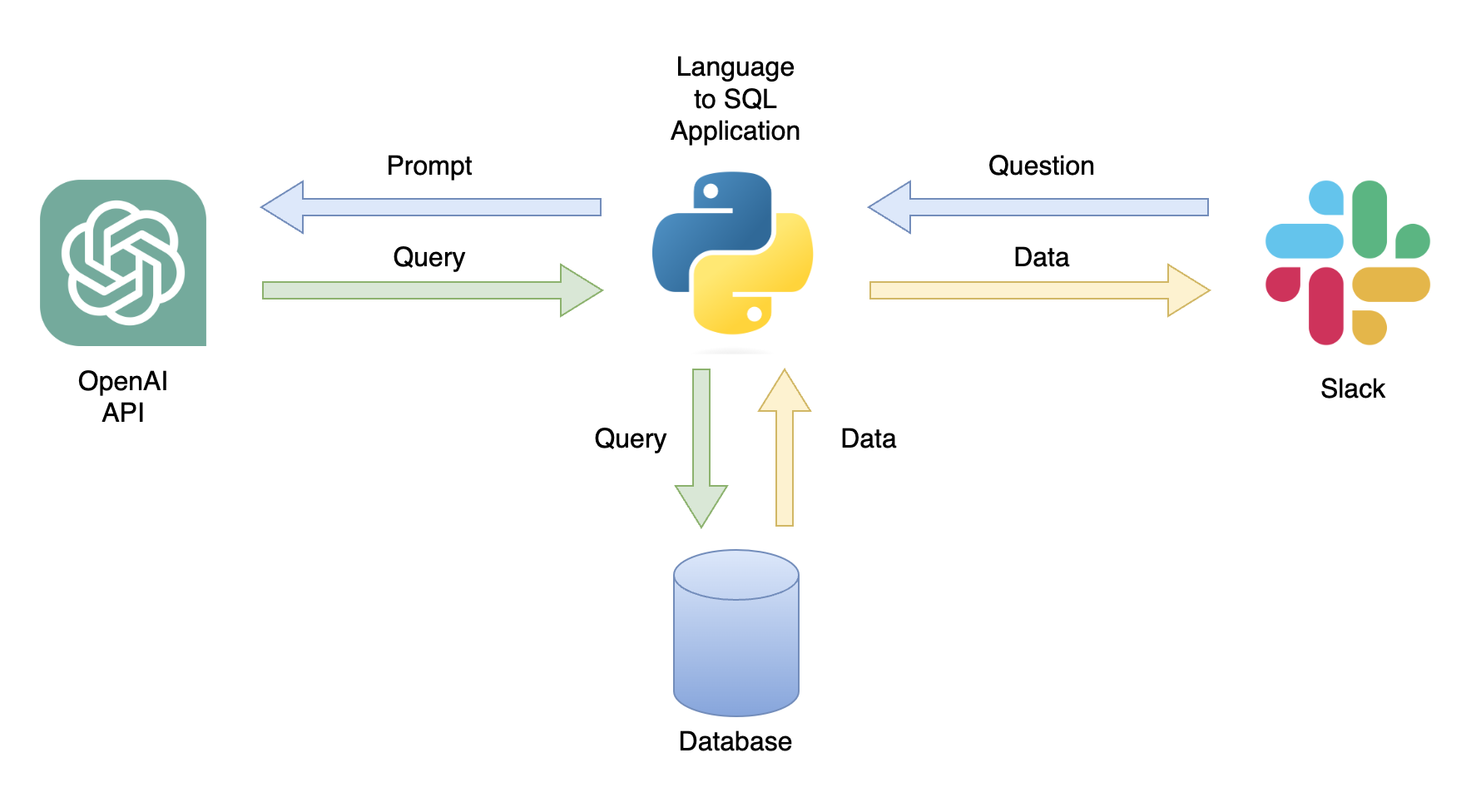
في هذا البرنامج التعليمي ، سنقوم بإنشاء تطبيق Python خطوة بخطوة يحول أسئلة المستخدم إلى استعلامات SQL.
يوفر هذا البرنامج التعليمي دليلًا خطوة بخطوة حول كيفية إعداد تطبيق Python الذي يحول الأسئلة العامة إلى استعلامات SQL باستخدام API Openai. يتضمن الوظيفة التالية:
يصف الشكل 2 أدناه البنية العامة للغة البسيطة إلى مولد رمز SQL.
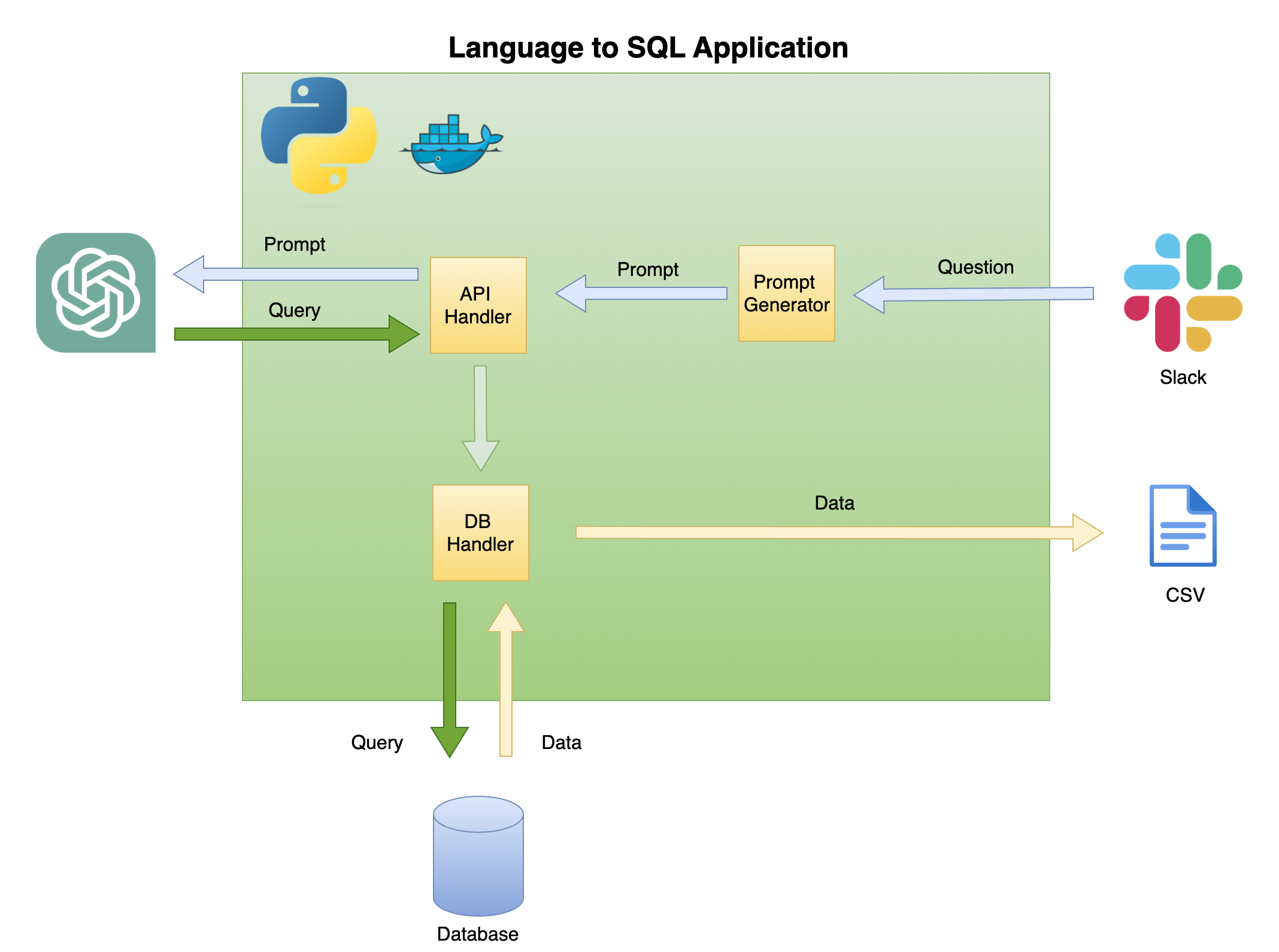
نطاق وتركيز هذا البرنامج التعليمي على المربع الأخضر - بناء الوظيفة التالية:
سؤال للمطالبة - تحويل السؤال إلى تنسيق موجه:
معالج API - وظيفة تعمل مع API Openai:
DB معالج - وظيفة ترسل استعلام SQL إلى قاعدة البيانات وإرجاع البيانات المطلوبة
الشرط الرئيسي الرئيسي لهذا البرنامج التعليمي هو المعرفة الأساسية للبيثون. يتضمن الوظيفة التالية:
بالإضافة إلى ذلك ، هناك حاجة إلى المعرفة الأساسية لـ SQL والوصول إلى API Openai.
على الرغم من أنه ليس ضروريًا ، إلا أن وجود معرفة أساسية لـ Docker مفيد ، حيث تم إنشاء البرنامج التعليمي في بيئة مقيد باستخدام امتداد حاويات Dev's VSCODE. إذا لم يكن لديك خبرة مع Docker أو Extension ، فلا يزال بإمكانك تشغيل البرنامج التعليمي عن طريق إنشاء بيئة افتراضية وتثبيت المكتبات المطلوبة (كما هو موضح أدناه). معرفة الهندسة الفوري و API Openai مفيدة أيضا.
لقد قمت بإنشاء برنامج تعليمي مفصل حول تعيين بيئة مدبوزة Python مع VSCODE وتمديد حاويات DEV:
https://github.com/ramikrispin/vscode-python
لإعداد لغة طبيعية لتوليد رمز SQL ، سنستخدم مكتبات Python التالية:
pandas - لمعالجة البيانات خلال العمليةduckdb - لمحاكاة العمل مع قاعدة البياناتopenai - للعمل مع API Openaitime and os - لتحميل ملفات CSV وحقول التنسيقيحتوي هذا المستودع على الإعدادات اللازمة لإطلاق بيئة مقيد مع متطلبات البرنامج التعليمي في VSCODE وتمديد حاويات DEV. مزيد من التفاصيل متوفرة في القسم التالي.
بدلاً من ذلك ، يمكنك إعداد بيئة افتراضية وتثبيت متطلبات البرنامج التعليمي باتباع الإرشادات أدناه باستخدام التعليمات في قسم البيئة الافتراضية.
تم بناء هذا البرنامج التعليمي داخل بيئة مقيد مع VSCODE وتمديد حاويات DEV. لتشغيله باستخدام VSCode ، ستحتاج إلى تثبيت امتداد حاويات Dev وفتح سطح مكتب Docker (أو ما يعادله). تتوفر إعدادات البيئة تحت مجلد .devcontainer :
.── .devcontainer
├── Dockerfile
├── Dockerfile.dev
├── devcontainer.json
├── install_dependencies_core.sh
├── install_dependencies_other.sh
├── install_quarto.sh
├── requirements_core.txt
├── requirements_openai.txt
└── requirements_transformers.txt
لدى devcontainer.json تعليمات الإنشاء وإعدادات VSCode لهذه البيئة المقيد:
{
"name" : " lang2sql " ,
"build" : {
"dockerfile" : " Dockerfile " ,
"args" : {
"ENV_NAME" : " lang2sql " ,
"PYTHON_VER" : " 3.10 " ,
"METHOD" : " openai " ,
"QUARTO_VER" : " 1.3.450 "
},
"context" : " . "
},
"customizations" : {
"settings" : {
"python.defaultInterpreterPath" : " /opt/conda/envs/lang2sql/bin/python " ,
"python.selectInterpreter" : " /opt/conda/envs/lang2sql/bin/python "
},
"vscode" : {
"extensions" : [
" quarto.quarto " ,
" ms-azuretools.vscode-docker " ,
" ms-python.python " ,
" ms-vscode-remote.remote-containers " ,
" yzhang.markdown-all-in-one " ,
" redhat.vscode-yaml " ,
" ms-toolsai.jupyter "
]
}
},
"remoteEnv" : {
"OPENAI_KEY" : " ${localEnv:OPENAI_KEY} "
}
}
حيث تحدد وسيطة build طريقة docker build وتعيين وسيطات الإنشاء. في هذه الحالة ، قمنا بتعيين إصدار Python على 3.10 ، والبيئة الافتراضية Conda إلى ang2sql . تحدد وسيطة METHOD نوع البيئة - إما openai لتثبيت مكتبات المتطلبات لهذا البرنامج التعليمي باستخدام API Openai أو transformers لتعيين البيئة لاتصالات API (التي هي خارج نطاق هذا البرنامج التعليمي).
تتيح وسيطة remoteEnv ضبط متغيرات البيئة. سوف نستخدمه لتعيين مفتاح Openai API. في هذه الحالة ، قمت بتعيين المتغير محليًا على أنه OPENAI_KEY ، وأنا أقوم بتحميله باستخدام وسيطة localEnv .
إذا كنت ترغب في معرفة المزيد حول إعداد بيئة تطوير Python مع VSCode و Docker ، فتحقق من هذا البرنامج التعليمي.
إذا كنت لا تستخدم البيئة التعليمية المقيد ، فيمكنك إنشاء بيئة افتراضية محلية من سطر الأوامر باستخدام البرنامج النصي أدناه:
ENV_NAME=openai_api
PYTHON_VER=3.10
conda create -y --name $ENV_NAME python= $PYTHON_VER
conda activate $ENV_NAME
pip3 install -r ./.devcontainer/requirements_core.txt
pip3 install -r ./.devcontainer/requirements_openai.txt
ملاحظة: لقد استخدمت conda ويجب أن تعمل بشكل جيد مع أي طريقة بيئة فيروس أخرى.
نستخدم متغيرات ENV_NAME و PYTHON_VER لتعيين البيئة الافتراضية وإصدار Python ، على التوالي.
للتأكيد على أن بيئتك تم تعيينها بشكل صحيح ، استخدم conda list لتأكيد تثبيت مكتبات Python المطلوبة. يجب أن تتوقع الإخراج أدناه:
(openai_api) root@0ca5b8000cd5:/workspaces/lang2sql# conda list
# packages in environment at /opt/conda/envs/openai_api:
#
# Name Version Build Channel
_libgcc_mutex 0.1 main
_openmp_mutex 5.1 51_gnu
aiohttp 3.9.0 pypi_0 pypi
aiosignal 1.3.1 pypi_0 pypi
asttokens 2.4.1 pypi_0 pypi
async-timeout 4.0.3 pypi_0 pypi
attrs 23.1.0 pypi_0 pypi
bzip2 1.0.8 hfd63f10_2
ca-certificates 2023.08.22 hd43f75c_0
certifi 2023.11.17 pypi_0 pypi
charset-normalizer 3.3.2 pypi_0 pypi
comm 0.2.0 pypi_0 pypi
contourpy 1.2.0 pypi_0 pypi
cycler 0.12.1 pypi_0 pypi
debugpy 1.8.0 pypi_0 pypi
decorator 5.1.1 pypi_0 pypi
duckdb 0.9.2 pypi_0 pypi
exceptiongroup 1.2.0 pypi_0 pypi
executing 2.0.1 pypi_0 pypi
fonttools 4.45.1 pypi_0 pypi
frozenlist 1.4.0 pypi_0 pypi
gensim 4.3.2 pypi_0 pypi
idna 3.5 pypi_0 pypi
ipykernel 6.26.0 pypi_0 pypi
ipython 8.18.0 pypi_0 pypi
jedi 0.19.1 pypi_0 pypi
joblib 1.3.2 pypi_0 pypi
jupyter-client 8.6.0 pypi_0 pypi
jupyter-core 5.5.0 pypi_0 pypi
kiwisolver 1.4.5 pypi_0 pypi
ld_impl_linux-aarch64 2.38 h8131f2d_1
libffi 3.4.4 h419075a_0
libgcc-ng 11.2.0 h1234567_1
libgomp 11.2.0 h1234567_1
libstdcxx-ng 11.2.0 h1234567_1
libuuid 1.41.5 h998d150_0
matplotlib 3.8.2 pypi_0 pypi
matplotlib-inline 0.1.6 pypi_0 pypi
multidict 6.0.4 pypi_0 pypi
ncurses 6.4 h419075a_0
nest-asyncio 1.5.8 pypi_0 pypi
numpy 1.26.2 pypi_0 pypi
openai 0.28.1 pypi_0 pypi
openssl 3.0.12 h2f4d8fa_0
packaging 23.2 pypi_0 pypi
pandas 2.0.0 pypi_0 pypi
parso 0.8.3 pypi_0 pypi
pexpect 4.8.0 pypi_0 pypi
pillow 10.1.0 pypi_0 pypi
pip 23.3.1 py310hd43f75c_0
platformdirs 4.0.0 pypi_0 pypi
prompt-toolkit 3.0.41 pypi_0 pypi
psutil 5.9.6 pypi_0 pypi
ptyprocess 0.7.0 pypi_0 pypi
pure-eval 0.2.2 pypi_0 pypi
pygments 2.17.2 pypi_0 pypi
pyparsing 3.1.1 pypi_0 pypi
python 3.10.13 h4bb2201_0
python-dateutil 2.8.2 pypi_0 pypi
pytz 2023.3.post1 pypi_0 pypi
pyzmq 25.1.1 pypi_0 pypi
readline 8.2 h998d150_0
requests 2.31.0 pypi_0 pypi
scikit-learn 1.3.2 pypi_0 pypi
scipy 1.11.4 pypi_0 pypi
setuptools 68.0.0 py310hd43f75c_0
six 1.16.0 pypi_0 pypi
smart-open 6.4.0 pypi_0 pypi
sqlite 3.41.2 h998d150_0
stack-data 0.6.3 pypi_0 pypi
threadpoolctl 3.2.0 pypi_0 pypi
tk 8.6.12 h241ca14_0
tornado 6.3.3 pypi_0 pypi
tqdm 4.66.1 pypi_0 pypi
traitlets 5.13.0 pypi_0 pypi
tzdata 2023.3 pypi_0 pypi
urllib3 2.1.0 pypi_0 pypi
wcwidth 0.2.12 pypi_0 pypi
wheel 0.41.2 py310hd43f75c_0
xz 5.4.2 h998d150_0
yarl 1.9.3 pypi_0 pypi
zlib 1.2.13 h998d150_0
سوف نستخدم API Openai للوصول إلى ChatGPT باستخدام محرك Text-Davinci-003. هذا يتطلب حساب Openai النشط ومفتاح API. من السهل تعيين حساب ومفتاح API بعد الإرشادات الواردة في الرابط أدناه:
https://openai.com/product
بمجرد تعيين الوصول إلى واجهة برمجة التطبيقات والمفتاح ، أوصي بإضافة المفتاح كمتغير بيئة إلى ملف .zshrc الخاص بك (أو أي تنسيق آخر تستخدمه لتخزين متغيرات البيئة على نظام الصدفة الخاص بك). لقد قمت بتخزين مفتاح API الخاص بي تحت متغير بيئة OPENAI_KEY . لأسباب مقنعة ، أوصيك باستخدام نفس اتفاقية التسمية.
لتعيين المتغير على ملف .zshrc (أو ما يعادله) ، أضف السطر أدناه إلى الملف:
export OPENAI_KEY= " YOUR_API_KEY " إذا كنت تستخدم VSCode أو تشغيل من المحطة ، فيجب عليك إعادة تشغيل جلستك بعد إضافة المتغير إلى ملف .zshrc .
من أجل محاكاة وظائف قاعدة البيانات ، سنستخدم مجموعة بيانات شيكاغو للجريمة. توفر مجموعة البيانات هذه معلومات متعمقة فيما يتعلق بالجرائم المسجلة في مدينة شيكاغو منذ عام 2001. مع ما يقرب من 8 ملايين سجل و 22 عمودًا ، تتضمن مجموعة البيانات معلومات مثل تصنيف الجريمة والموقع والوقت والنتائج ، إلخ. تتوفر البيانات للتنزيل من بوابة بيانات شيكاغو. نظرًا لأننا نقوم بتخزين البيانات محليًا كإطار بيانات Pandas ونستخدم DuckDB لمحاكاة استعلام SQL ، سنقوم بتنزيل مجموعة فرعية من البيانات باستخدام السنوات الثلاث الماضية.
يمكنك سحب البيانات من API أو تنزيل ملف CSV. لتجنب استدعاء واجهة برمجة التطبيقات في كل مرة أقوم فيها بتشغيل البرنامج النصي ، أقوم بتنزيل الملفات وتخزينها تحت مجلد البيانات. فيما يلي الروابط إلى مجموعات البيانات حسب السنة:
لتنزيل البيانات ، استخدم زر Export في الجانب العلوي الأيمن ، وحدد خيار CSV ، وانقر فوق زر Download ، كما هو موضح في الشكل 4.
لقد استخدمت اتفاقية التسمية التالية - Chicago_crime_year.csv وحفظت الملفات في مجلد data . كل حجم ملف يقترب من 50 ميغابايت. لذلك ، أضفتها إلى GIT تجاهل الملف ضمن مجلد data ، وهي غير متوفرة في هذا الريبو. بعد تنزيل الملفات ووضع أسماءها ، يجب أن يكون لديك الملفات التالية في المجلد:
| ── data
├── chicago_crime_2021.csv
├── chicago_crime_2022.csv
└── chicago_crime_2023.csv
ملاحظة: اعتبارًا من وقت إنشاء هذا البرنامج التعليمي ، لا تزال البيانات لعام 2023 يتم تحديثها. لذلك ، قد تتلقى نتائج مختلفة قليلاً عند تشغيل بعض الاستعلامات في القسم التالي.
دعنا ننتقل إلى الجزء المثير ، الذي يقوم بإعداد مولد رمز SQL. في هذا القسم ، سنقوم بإنشاء وظيفة Python التي تأخذ سؤال المستخدم ، وجدول SQL المرتبط به ، ومفتاح Openai API وإخراج استعلام SQL الذي يجيب على سؤال المستخدم.
لنبدأ بتحميل مجموعة بيانات شيكاغو للجريمة ومكتبات بيثون المطلوبة.
أول شيء أولاً - دعنا نحمل مكتبات Python المطلوبة:
import pandas as pd
import duckdb
import openai
import time
import osسنستخدم مكتبات نظام التشغيل والوقت لتحميل ملفات CSV وإعادة تهيئة بعض الحقول. ستتم معالجة البيانات باستخدام مكتبة Pandas ، وسنقوم بمحاكاة أوامر SQL مع مكتبة DuckDB . أخيرًا ، سنقوم بإنشاء اتصال إلى API Openai باستخدام مكتبة Openai .
بعد ذلك ، سنقوم بتحميل ملفات CSV من مجلد البيانات. يقرأ الرمز أدناه جميع ملفات CSV المتاحة في مجلد البيانات:
path = "./data"
files = [ x for x in os . listdir ( path = path ) if ".csv" in x ]إذا قمت بتنزيل الملفات المقابلة للسنوات من 2021 إلى 2023 واستخدمت نفس اتفاقية التسمية ، فيجب أن تتوقع الإخراج التالي:
print ( files )
[ 'chicago_crime_2022.csv' , 'chicago_crime_2023.csv' , 'chicago_crime_2021.csv' ]بعد ذلك ، سنقرأ وتحميل جميع الملفات وإلحاحها في إطار بيانات Pandas:
chicago_crime = pd . concat (( pd . read_csv ( path + "/" + f ) for f in files ), ignore_index = True )
chicago_crime . headإذا قمت بتحميل الملفات بشكل صحيح ، فيجب أن تتوقع الإخراج التالي:
< bound method NDFrame . head of ID Case Number Date Block
0 12589893 JF109865 01 / 11 / 2022 03 : 00 : 00 PM 087 XX S KINGSTON AVE
1 12592454 JF113025 01 / 14 / 2022 03 : 55 : 00 PM 067 XX S MORGAN ST
2 12601676 JF124024 01 / 13 / 2022 04 : 00 : 00 PM 031 XX W AUGUSTA BLVD
3 12785595 JF346553 08 / 05 / 2022 09 : 00 : 00 PM 072 XX S UNIVERSITY AVE
4 12808281 JF373517 08 / 14 / 2022 02 : 00 : 00 PM 055 XX W ARDMORE AVE
... ... ... ... ...
648826 26461 JE455267 11 / 24 / 2021 12 : 51 : 00 AM 107 XX S LANGLEY AVE
648827 26041 JE281927 06 / 28 / 2021 01 : 12 : 00 AM 117 XX S LAFLIN ST
648828 26238 JE353715 08 / 29 / 2021 03 : 07 : 00 AM 010 XX N LAWNDALE AVE
648829 26479 JE465230 12 / 03 / 2021 08 : 37 : 00 PM 000 XX W 78 TH PL
648830 11138622 JA495186 05 / 21 / 2021 12 : 01 : 00 AM 019 XX N PULASKI RD
IUCR Primary Type
0 1565 SEX OFFENSE
1 2826 OTHER OFFENSE
2 1752 OFFENSE INVOLVING CHILDREN
3 1544 SEX OFFENSE
4 1562 SEX OFFENSE
... ... ...
648826 0110 HOMICIDE
648827 0110 HOMICIDE
648828 0110 HOMICIDE
648829 0110 HOMICIDE
648830 1752 OFFENSE INVOLVING CHILDREN
...
648828 41.899709 - 87.718893 ( 41.899709327 , - 87.718893208 )
648829 41.751832 - 87.626374 ( 41.751831742 , - 87.626373808 )
648830 41.915798 - 87.726524 ( 41.915798196 , - 87.726524412 ) ملاحظة: عند إنشاء هذا البرنامج التعليمي ، كانت البيانات الجزئية لعام 2023 متاحة. إن إلحاق الملفات الثلاثة سيؤدي إلى صفوف أكثر من الموضح (648830 صفًا).
قبل أن نصل إلى رمز Python ، دعنا نتوقف ونراجع كيفية عمل الهندسة الفورية وكيف يمكننا المساعدة في ChatGPT (وعموما أي LLM) لتحقيق أفضل النتائج. سوف نستخدم في هذا القسم واجهة ويب ChatGPT.
أحد العوامل الرئيسية في نماذج التعلم الإحصائي والآلي هو أن جودة الإخراج تعتمد على جودة الإدخال. كما تقول العبارة الشهيرة- غير المرغوب فيها . وبالمثل ، تعتمد جودة إخراج LLM على جودة المطالبة.
على سبيل المثال ، لنفترض أننا نريد حساب عدد الحالات التي انتهى بها الأمر بالاعتقال.
إذا استخدمنا المطالبة التالية:
Create an SQL query that counts the number of records that ended up with an arrest.
هنا هو الإخراج من chatgpt:
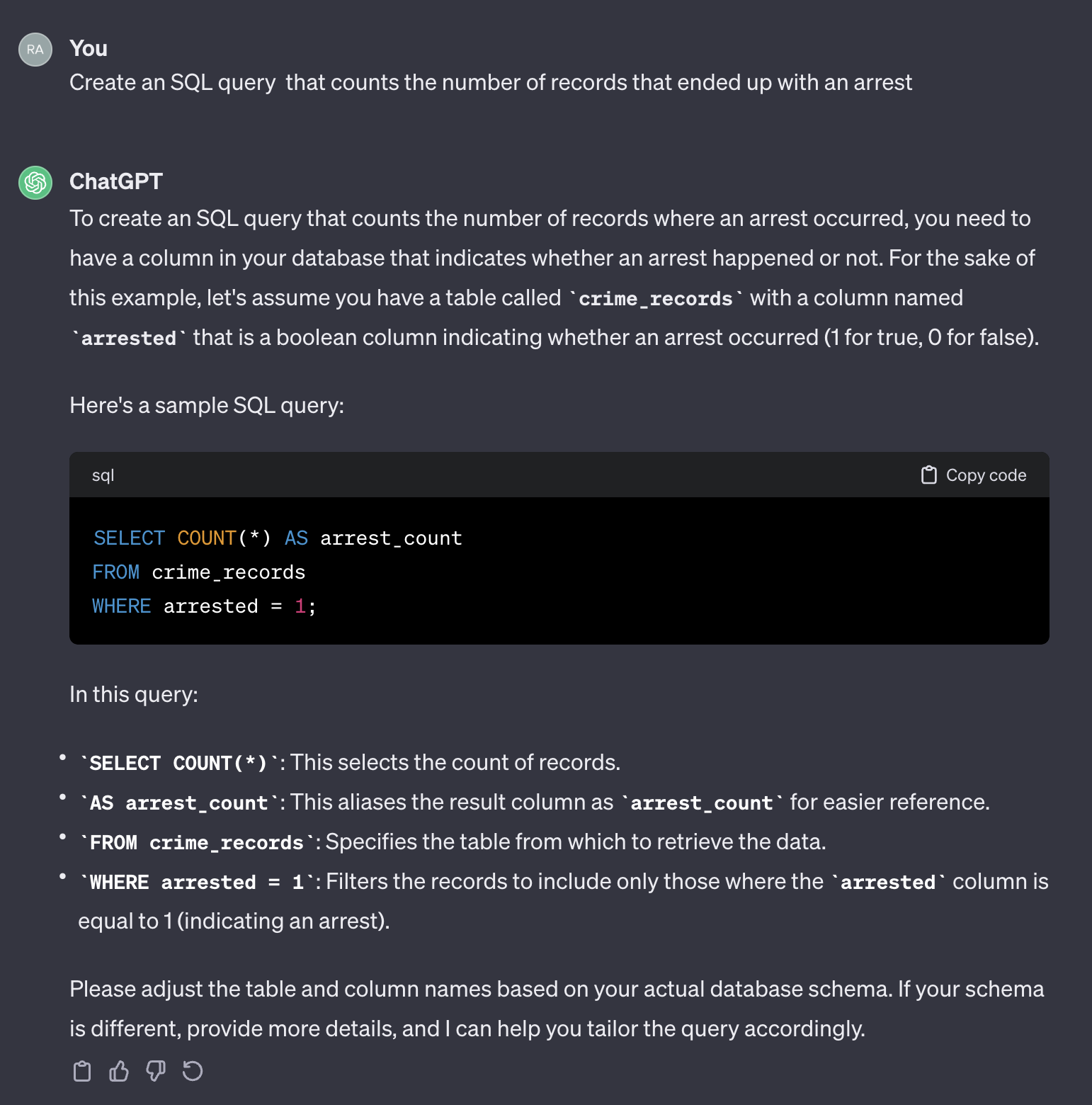
تجدر الإشارة إلى أن ChatGPT يوفر استجابة عامة. على الرغم من أنه صحيح بشكل عام ، إلا أنه قد لا يكون من العملي استخدامه في عملية آلية. أولاً ، لا تتطابق أسماء الحقل في الاستجابة مع الجدول الفعلي الذي نحتاجه للاستعلام. ثانياً ، الحقل الذي يمثل نتيجة الاعتقال هو منطقية ( true أو false ) بدلاً من عدد صحيح ( 0 أو 1 ).
chatgpt ، بهذا المعنى ، يتصرف مثل الإنسان. من غير المرجح أن تتلقى إجابة أكثر دقة من الإنسان من خلال نشر نفس السؤال على نموذج الترميز مثل Stack Overflow أو أي منصة أخرى مماثلة. بالنظر إلى أننا لم نقدم أي سياق أو معلومات إضافية حول خصائص الجدول ، نتوقع أن تخمن ChatGPT أسماء الحقول وقيمها ستكون غير معقولة. السياق عامل حاسم في أي موجه. لتوضيح هذه النقطة ، دعونا نرى كيف تتعامل ChatGpt مع المطالبة التالية:
I have a table named chicago_crime with the crime records in Chicago City since 2021. The Arrest field defines if the case ended up with arrest or not, and it is a boolean (true or false).
I want to create an SQL query that counts the number of records that ended up with an arrest.
هنا هو الإخراج من chatgpt:
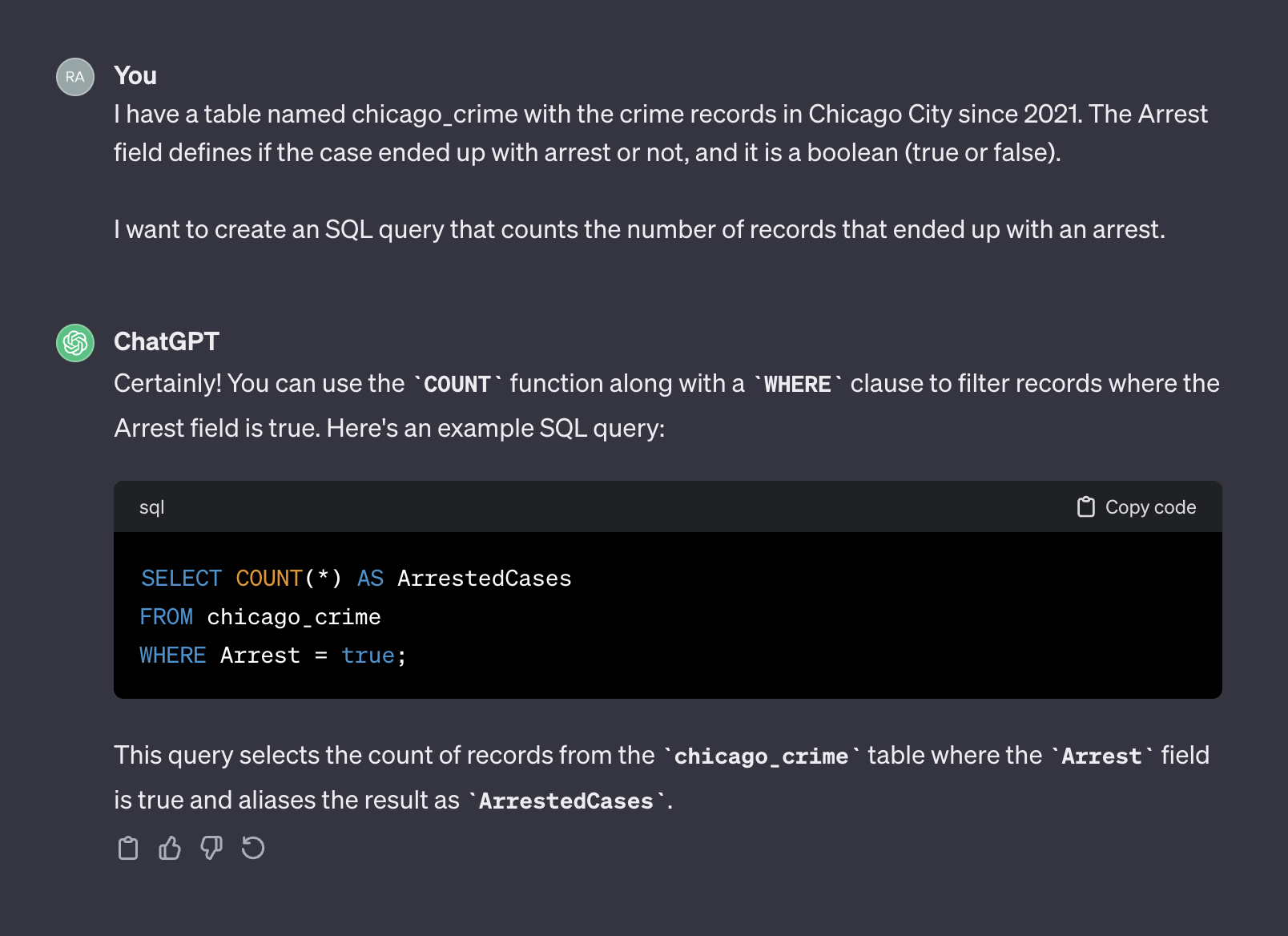
هذه المرة ، بعد إضافة سياق ، أعاد ChatGPT استعلامًا صحيحًا يمكننا استخدامه كما هو. بشكل عام ، عند العمل مع مولد نص ، يجب أن تتضمن المطالبة مكونين - السياق والطلب. في المطالبة أعلاه ، تمثل الفقرة الأولى سياق الموجه:
I have a table named chicago_crime with the crime records in Chicago City since 2021. The Arrest field defines if the case ended up with arrest or not, and it is a boolean (true or false).
حيث الفقرة الثانية ، تمثل الطلب:
I want to create an SQL query that counts the number of records that ended up with an arrest.
يشير API Openai إلى السياق system وطلب user .
توفر وثائق Openai API توصية حول كيفية تعيين مكونات system user في مطالبة عند طلب إنشاء رمز SQL:
System
Given the following SQL tables, your job is to write queries given a user’s request.
CREATE TABLE Orders (
OrderID int,
CustomerID int,
OrderDate datetime,
OrderTime varchar(8),
PRIMARY KEY (OrderID)
);
CREATE TABLE OrderDetails (
OrderDetailID int,
OrderID int,
ProductID int,
Quantity int,
PRIMARY KEY (OrderDetailID)
);
CREATE TABLE Products (
ProductID int,
ProductName varchar(50),
Category varchar(50),
UnitPrice decimal(10, 2),
Stock int,
PRIMARY KEY (ProductID)
);
CREATE TABLE Customers (
CustomerID int,
FirstName varchar(50),
LastName varchar(50),
Email varchar(100),
Phone varchar(20),
PRIMARY KEY (CustomerID)
);
User
Write a SQL query which computes the average total order value for all orders on 2023-04-01.
في القسم التالي ، سنستخدم مثال Openai أعلاه وتعميمه في قالب للأغراض العامة.
في القسم السابق ، ناقشنا أهمية الهندسة السريعة وكيف يمكن لتوفير سياق جيد تحسين دقة استجابة LLM. بالإضافة إلى ذلك ، رأينا هيكل موجه Openai الموصى به لتوليد رمز SQL. في هذا القسم ، سوف نركز على تعميم عملية إنشاء مطالبات لتوليد SQL بناءً على تلك المبادئ. الهدف من ذلك هو إنشاء وظيفة Python التي تتلقى اسم الجدول وسؤال المستخدم وإنشاء المطالبة وفقًا لذلك. على سبيل المثال ، بالنسبة لجدول Table chicago_crime ، قمنا بتحميله من قبل والسؤال الذي طرحناه في القسم السابق ، يجب على الوظيفة إنشاء موجه أدناه:
Given the following SQL table, your job is to write queries given a user’s request.
CREATE TABLE chicago_crime (ID BIGINT, Case Number VARCHAR, Date VARCHAR, Block VARCHAR, IUCR VARCHAR, Primary Type VARCHAR, Description VARCHAR, Location Description VARCHAR, Arrest BOOLEAN, Domestic BOOLEAN, Beat BIGINT, District BIGINT, Ward DOUBLE, Community Area BIGINT, FBI Code VARCHAR, X Coordinate DOUBLE, Y Coordinate DOUBLE, Year BIGINT, Updated On VARCHAR, Latitude DOUBLE, Longitude DOUBLE, Location VARCHAR)
Write a SQL query that returns - How many cases ended up with arrest?
لنبدأ بالهيكل السريع. سوف نعتمد تنسيق Openai ونستخدم القالب التالي:
system_template = """
Given the following SQL table, your job is to write queries given a user’s request. n
CREATE TABLE {} ({}) n
"""
user_template = "Write a SQL query that returns - {}" حيث تلقى system_template عنصرين:
بالنسبة لهذا البرنامج التعليمي ، سنستخدم مكتبة DuckDB للتعامل مع إطار بيانات Pandas لأنه كان جدول SQL واستخراج أسماء حقل الجدول وسماتها باستخدام وظيفة duckdb.sql . على سبيل المثال ، دعنا نستخدم أمر DESCRIBE SQL لاستخراج معلومات حقول جدول chicago_crime :
duckdb . sql ( "DESCRIBE SELECT * FROM chicago_crime;" )الذي يجب أن يعيد الجدول أدناه:
┌──────────────────────┬─────────────┬─────────┬─────────┬─────────┬─────────┐
│ column_name │ column_type │ null │ key │ default │ extra │
│ varchar │ varchar │ varchar │ varchar │ varchar │ varchar │
├──────────────────────┼─────────────┼─────────┼─────────┼─────────┼─────────┤
│ ID │ BIGINT │ YES │ NULL │ NULL │ NULL │
│ Case Number │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ Date │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ Block │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ IUCR │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ Primary Type │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ Description │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ Location Description │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ Arrest │ BOOLEAN │ YES │ NULL │ NULL │ NULL │
│ Domestic │ BOOLEAN │ YES │ NULL │ NULL │ NULL │
│ Beat │ BIGINT │ YES │ NULL │ NULL │ NULL │
│ District │ BIGINT │ YES │ NULL │ NULL │ NULL │
│ Ward │ DOUBLE │ YES │ NULL │ NULL │ NULL │
│ Community Area │ BIGINT │ YES │ NULL │ NULL │ NULL │
│ FBI Code │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ X Coordinate │ DOUBLE │ YES │ NULL │ NULL │ NULL │
│ Y Coordinate │ DOUBLE │ YES │ NULL │ NULL │ NULL │
│ Year │ BIGINT │ YES │ NULL │ NULL │ NULL │
│ Updated On │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ Latitude │ DOUBLE │ YES │ NULL │ NULL │ NULL │
│ Longitude │ DOUBLE │ YES │ NULL │ NULL │ NULL │
│ Location │ VARCHAR │ YES │ NULL │ NULL │ NULL │
├──────────────────────┴─────────────┴─────────┴─────────┴─────────┴─────────┤
│ 22 rows 6 columns │
└────────────────────────────────────────────────────────────────────────────┘ملاحظة: المعلومات التي نحتاجها - تتوفر اسم العمود وسمةه في العمودين الأولين. لذلك ، سنحتاج إلى تحليل تلك الأعمدة ودمجها معًا في التنسيق التالي:
Column_Name Column_Attribute
على سبيل المثال ، يجب أن ينقل عمود Case Number إلى التنسيق التالي:
Case Number VARCHAR
تقوم وظيفة create_message أدناه بتنظيم عملية أخذ اسم الجدول والسؤال وإنشاء المطالبة باستخدام المنطق أعلاه:
def create_message ( table_name , query ):
class message :
def __init__ ( message , system , user , column_names , column_attr ):
message . system = system
message . user = user
message . column_names = column_names
message . column_attr = column_attr
system_template = """
Given the following SQL table, your job is to write queries given a user’s request. n
CREATE TABLE {} ({}) n
"""
user_template = "Write a SQL query that returns - {}"
tbl_describe = duckdb . sql ( "DESCRIBE SELECT * FROM " + table_name + ";" )
col_attr = tbl_describe . df ()[[ "column_name" , "column_type" ]]
col_attr [ "column_joint" ] = col_attr [ "column_name" ] + " " + col_attr [ "column_type" ]
col_names = str ( list ( col_attr [ "column_joint" ]. values )). replace ( '[' , '' ). replace ( ']' , '' ). replace ( ' ' ' , '' )
system = system_template . format ( table_name , col_names )
user = user_template . format ( query )
m = message ( system = system , user = user , column_names = col_attr [ "column_name" ], column_attr = col_attr [ "column_type" ])
return m تقوم الوظيفة بإنشاء القالب المطالبات وإرجاع system المطالبة ومكونات user وأسماء الأعمدة والسمات. على سبيل المثال ، دعنا ندير عدد سؤال الاعتقال:
query = "How many cases ended up with arrest?"
msg = create_message ( table_name = "chicago_crime" , query = query )هذا سيعود:
print ( msg . system )
Given the following SQL table , your job is to write queries given a user ’ s request .
CREATE TABLE chicago_crime ( ID BIGINT , Case Number VARCHAR , Date VARCHAR , Block VARCHAR , IUCR VARCHAR , Primary Type VARCHAR , Description VARCHAR , Location Description VARCHAR , Arrest BOOLEAN , Domestic BOOLEAN , Beat BIGINT , District BIGINT , Ward DOUBLE , Community Area BIGINT , FBI Code VARCHAR , X Coordinate DOUBLE , Y Coordinate DOUBLE , Year BIGINT , Updated On VARCHAR , Latitude DOUBLE , Longitude DOUBLE , Location VARCHAR )
print ( msg . user )
Write a SQL query that returns - How many cases ended up with arrest ?
print ( msg . column_names )
0 ID
1 Case Number
2 Date
3 Block
4 IUCR
5 Primary Type
6 Description
7 Location Description
8 Arrest
9 Domestic
10 Beat
11 District
12 Ward
13 Community Area
14 FBI Code
15 X Coordinate
16 Y Coordinate
17 Year
18 Updated On
19 Latitude
20 Longitude
21 Location
Name : column_name , dtype : object
print ( msg . column_attr )
0 BIGINT
1 VARCHAR
2 VARCHAR
3 VARCHAR
4 VARCHAR
5 VARCHAR
6 VARCHAR
7 VARCHAR
8 BOOLEAN
9 BOOLEAN
10 BIGINT
11 BIGINT
12 DOUBLE
13 BIGINT
14 VARCHAR
15 DOUBLE
16 DOUBLE
17 BIGINT
18 VARCHAR
19 DOUBLE
20 DOUBLE
21 VARCHAR
Name : column_type , dtype : object تم تصميم إخراج وظيفة create_message لتناسب ChatCompletion.create وظيفة Openai API.
يركز هذا القسم على وظيفة مكتبة Openai Python. تتيح مكتبة Openai الوصول السلس إلى API Openai Rest. سوف نستخدم المكتبة للاتصال بآبار واجهة برمجة التطبيقات وإرسال طلبات الحصول على مطالبة لدينا.
لنبدأ بالاتصال بأجهزة واجهة برمجة التطبيقات عن طريق تغذية واجهة برمجة التطبيقات (API) بوظيفة openai.api_key :
openai . api_key = os . getenv ( 'OPENAI_KEY' ) ملاحظة: استخدمنا وظيفة getenv من مكتبة os لتحميل متغير بيئة OpenAI_Key. بدلاً من ذلك ، يمكنك إطعام مفتاح API الخاص بك مباشرة:
openai . api_key = "YOUR_OPENAI_API_KEY"يوفر Openai API الوصول إلى مجموعة متنوعة من LLMs مع وظائف مختلفة. يمكنك استخدام وظيفة Openai.model.list للحصول على قائمة بالنماذج المتاحة:
openai . Model . list () لتحويله إلى تنسيق جميل ، يمكنك لفه في إطار بيانات pandas :
openai_api_models = pd . DataFrame ( openai . Model . list ()[ "data" ])
openai_api_models . headويجب أن تتوقع الإخراج التالي:
<bound method NDFrame.head of id object created owned_by
0 text-search-babbage-doc-001 model 1651172509 openai-dev
1 gpt-4 model 1687882411 openai
2 curie-search-query model 1651172509 openai-dev
3 text-davinci-003 model 1669599635 openai-internal
4 text-search-babbage-query-001 model 1651172509 openai-dev
.. ... ... ... ...
65 gpt-3.5-turbo-instruct-0914 model 1694122472 system
66 dall-e-2 model 1698798177 system
67 tts-1-1106 model 1699053241 system
68 tts-1-hd-1106 model 1699053533 system
69 gpt-3.5-turbo-16k model 1683758102 openai-internal
[70 rows x 4 columns]>
لحالة الاستخدام الخاصة بنا ، توليد النص ، سنستخدم نموذج gpt-3.5-turbo ، وهو تحسين لنموذج GPT3. يمثل طراز gpt-3.5-turbo سلسلة من النماذج التي تستمر في التحديث ، وإلى افتراضي ، إذا لم يتم تحديد إصدار النموذج ، فسيشير واجهة برمجة التطبيقات إلى أحدث إصدار مستقر. عند إنشاء هذا البرنامج التعليمي ، كان نموذج 3.5 الافتراضي gpt-3.5-turbo-0613 ، باستخدام 4،096 رمزًا ، وتم تدريبه مع بيانات حتى سبتمبر 2021.
لإرسال طلب GET مطالبة لدينا ، سوف نستخدم وظيفة ChatCompletion.create . تحتوي الوظيفة على العديد من الوسائط ، وسنستخدم الحالات التالية:
model - معرف النموذج للاستخدام ، قائمة كاملة متوفرة هناmessages - قائمة بالرسائل التي تضم المحادثة حتى الآن (على سبيل المثال المطالبة)temperature - إدارة العشوائية أو الحتمية لإخراج العملية عن طريق تحديد مستوى درجة حرارة أخذ العينات. يقبل مستوى درجة الحرارة القيم بين 0 و 2. عندما تكون قيمة الوسيطة أعلى ، يصبح الإخراج أكثر عشوائيًا. على العكس ، عندما تكون قيمة الوسيطة أقرب إلى 0 ، يصبح الإخراج أكثر حتمية (قابلة للتكرار)max_tokens - الحد الأقصى لعدد الرموز المميزة التي يجب توليدها في الانتهاءالقائمة الكاملة لوسائط الوظيفة المتاحة على وثيقة API.
في المثال أدناه ، سوف نستخدم نفس موجه مثل تلك المستخدمة في واجهة ويب ChatGPT (أي الشكل 5) ، هذه المرة باستخدام واجهة برمجة التطبيقات. سنقوم بإنشاء المطالبة مع وظيفة create_message :
query = "How many cases ended up with arrest?"
prompt = create_message ( table_name = "chicago_crime" , query = query ) دعونا نحول الموجه أعلاه إلى بنية ChatCompletion.create messages الوسيطة:
message = [
{
"role" : "system" ,
"content" : prompt . system
},
{
"role" : "user" ,
"content" : prompt . user
}
] بعد ذلك ، سنرسل المطالبة (أي كائن message ) إلى واجهة برمجة التطبيقات (API) باستخدام وظيفة ChatCompletion.create :
response = openai . ChatCompletion . create (
model = "gpt-3.5-turbo" ,
messages = message ,
temperature = 0 ,
max_tokens = 256 ) سنقوم بتعيين وسيطة temperature على 0 لضمان استنساخ مرتفع والحد من عدد الرموز في إكمال النص إلى 256. تُرجع الوظيفة كائن JSON مع إكمال النص ، والبيانات الوصفية ، وغيرها من المعلومات:
print ( response )
< OpenAIObject chat . completion id = chatcmpl - 8 PzomlbLrTOTx1uOZm4WQnGr4JwU7 at 0xffff4b0dcb80 > JSON : {
"id" : "chatcmpl-8PzomlbLrTOTx1uOZm4WQnGr4JwU7" ,
"object" : "chat.completion" ,
"created" : 1701206520 ,
"model" : "gpt-3.5-turbo-0613" ,
"choices" : [
{
"index" : 0 ,
"message" : {
"role" : "assistant" ,
"content" : "SELECT COUNT(*) FROM chicago_crime WHERE Arrest = true;"
},
"finish_reason" : "stop"
}
],
"usage" : {
"prompt_tokens" : 137 ,
"completion_tokens" : 12 ,
"total_tokens" : 149
}
}باستخدام جزر الهند ، يمكننا استخراج استعلام SQL:
sql = response [ "choices" ][ 0 ][ "message" ][ "content" ]
print ( sql ) ' SELECT COUNT(*) FROM chicago_crime WHERE Arrest = true; ' باستخدام دالة duckdb.sql لتشغيل رمز SQL:
duckdb . sql ( sql ). show ()
┌──────────────┐
│ count_star () │
│ int64 │
├──────────────┤
│ 77635 │
└──────────────┘في القسم التالي ، سنعمل على تعميم جميع الخطوات ونطالها.
في الأقسام السابقة ، قدمنا تنسيق المطالبة ، وقمنا بتعيين وظيفة create_message ، وقمنا بمراجعة وظيفة وظيفة ChatCompletion.create . في هذا القسم ، نخطي كل شيء معًا.
شيء واحد يجب ملاحظته حول رمز SQL الذي تم إرجاعه من وظيفة ChatCompletion.create هو أن المتغير لا يعود مع عروض الأسعار. قد تكون هذه مشكلة عندما يجمع الاسم المتغير في الاستعلام بين كلمتين أو أكثر. على سبيل المثال ، سيؤدي استخدام متغير مثل Case Number أو Primary Type من chicago_crime داخل استعلام دون استخدام علامات الاقتباس إلى خطأ.
سنستخدم وظيفة المساعد أدناه لإضافة علامات اقتباس إلى المتغيرات في الاستعلام إذا كان الاستعلام الذي تم إرجاعه لا يحتوي على واحدة:
def add_quotes ( query , col_names ):
for i in col_names :
if i in query :
l = query . find ( i )
if query [ l - 1 ] != "'" and query [ l - 1 ] != '"' :
query = str ( query ). replace ( i , '"' + i + '"' )
return ( query ) مدخلات الوظيفة هي الاستعلام وأسماء أعمدة الجدول المقابل. إنه يحلق فوق أسماء الأعمدة ويضيف عروض أسعار إذا كان يجد تطابقًا داخل الاستعلام. على سبيل المثال ، يمكننا تشغيله باستخدام استعلام SQL الذي قمنا بتحليله من ChatCompletion.create الوظيفة الإخراج:
add_quotes ( query = sql , col_names = prompt . column_names )
'SELECT COUNT(*) FROM chicago_crime WHERE "Arrest" = true;' يمكنك أن تلاحظ أنه أضاف عروض أسعار إلى متغير Arrest .
يمكننا الآن تقديم وظيفة lang2sql التي تستفيد من الوظائف الثلاث التي قدمناها حتى الآن - create_message و ChatCompletion.create و add_quotes لترجمة سؤال المستخدم إلى رمز SQL:
def lang2sql ( api_key , table_name , query , model = "gpt-3.5-turbo" , temperature = 0 , max_tokens = 256 , frequency_penalty = 0 , presence_penalty = 0 ):
class response :
def __init__ ( output , message , response , sql ):
output . message = message
output . response = response
output . sql = sql
openai . api_key = api_key
m = create_message ( table_name = table_name , query = query )
message = [
{
"role" : "system" ,
"content" : m . system
},
{
"role" : "user" ,
"content" : m . user
}
]
openai_response = openai . ChatCompletion . create (
model = model ,
messages = message ,
temperature = temperature ,
max_tokens = max_tokens ,
frequency_penalty = frequency_penalty ,
presence_penalty = presence_penalty )
sql_query = add_quotes ( query = openai_response [ "choices" ][ 0 ][ "message" ][ "content" ], col_names = m . column_names )
output = response ( message = m , response = openai_response , sql = sql_query )
return output تستقبل الوظيفة ، كمدخلات ، ومفتاح API Openai ، واسم الجدول ، والمعلمات الأساسية لوظيفة ChatCompletion.create وإرجاع كائن باستخدام المطالبة ، واستجابة API ، والاستعلام المحسّن. على سبيل المثال ، لنحاول إعادة تشغيل نفس الاستعلام الذي استخدمناه في القسم السابق مع وظيفة lang2sql :
query = "How many cases ended up with arrest?"
response = lang2sql ( api_key = api_key , table_name = "chicago_crime" , query = query )يمكننا استخراج استعلام SQL من كائن الإخراج:
print ( response . sql ) SELECT COUNT ( * ) FROM chicago_crime WHERE " Arrest " = true;يمكننا اختبار الإخراج فيما يتعلق بالنتائج التي تلقيناها في القسم السابق:
duckdb . sql ( response . sql ). show ()
┌──────────────┐
│ count_star () │
│ int64 │
├──────────────┤
│ 77635 │
└──────────────┘دعنا الآن نضيف تعقيدًا إضافيًا إلى السؤال ونسأل عن الحالات التي انتهى بها الأمر مع اعتقال خلال عام 2022:
query = "How many cases ended up with arrest during 2022"
response = lang2sql ( api_key = api_key , table_name = "chicago_crime" , query = query ) كما ترون ، حدد النموذج بشكل صحيح الحقل ذي الصلة على أنه Year وإنشاء الاستعلام الصحيح:
print ( response . sql )رمز SQL:
SELECT COUNT ( * ) FROM chicago_crime WHERE " Arrest " = TRUE AND " Year " = 2022 ;اختبار الاستعلام في الجدول:
duckdb . sql ( response . sql ). show ()
┌──────────────┐
│ count_star () │
│ int64 │
├──────────────┤
│ 27805 │
└──────────────┘فيما يلي مثال على سؤال بسيط يتطلب تجميعًا بواسطة متغير محدد:
query = "Summarize the cases by primary type"
response = lang2sql ( api_key = api_key , table_name = "chicago_crime" , query = query )
print ( response . sql )يمكنك أن ترى من إخراج الاستجابة أن رمز SQL في هذه الحالة صحيح:
SELECT " Primary Type " , COUNT ( * ) as TotalCases
FROM chicago_crime
GROUP BY " Primary Type "هذا هو إخراج الاستعلام:
duckdb . sql ( response . sql ). show ()
┌───────────────────────────────────┬────────────┐
│ Primary Type │ TotalCases │
│ varchar │ int64 │
├───────────────────────────────────┼────────────┤
│ MOTOR VEHICLE THEFT │ 54934 │
│ ROBBERY │ 25082 │
│ WEAPONS VIOLATION │ 24672 │
│ INTERFERENCE WITH PUBLIC OFFICER │ 1161 │
│ OBSCENITY │ 127 │
│ STALKING │ 1206 │
│ BATTERY │ 115760 │
│ OFFENSE INVOLVING CHILDREN │ 5177 │
│ CRIMINAL TRESPASS │ 11255 │
│ PUBLIC PEACE VIOLATION │ 1980 │
│ · │ · │
│ · │ · │
│ · │ · │
│ ASSAULT │ 58685 │
│ CRIMINAL DAMAGE │ 75611 │
│ DECEPTIVE PRACTICE │ 46377 │
│ NARCOTICS │ 13931 │
│ BURGLARY │ 19898 │
...
├───────────────────────────────────┴────────────┤
│ 31 rows ( 20 shown ) 2 columns │
└────────────────────────────────────────────────┘أخيرًا وليس آخرًا ، يمكن لـ LLM تحديد السياق (على سبيل المثال ، وهو المتغير) حتى عندما نقدم اسم متغير جزئي:
query = "How many cases is the type of robbery?"
response = lang2sql ( api_key = api_key , table_name = "chicago_crime" , query = query )
print ( response . sql )يعيد رمز SQL أدناه:
SELECT COUNT ( * ) FROM chicago_crime WHERE " Primary Type " = ' ROBBERY ' ;هذا هو إخراج الاستعلام:
duckdb . sql ( response . sql ). show ()
┌──────────────┐
│ count_star () │
│ int64 │
├──────────────┤
│ 25082 │
└──────────────┘في هذا البرنامج التعليمي ، أوضحنا كيفية إنشاء مولد رمز SQL مع بضعة أسطر من رمز Python واستخدام API Openai. لقد رأينا أن جودة المطالبة أمر بالغ الأهمية لنجاح رمز SQL الناتج. بالإضافة إلى السياق الذي توفره المطالبة ، يجب أن توفر أسماء الحقول أيضًا معلومات حول خصائص الحقل لمساعدة LLM على تحديد أهمية الحقل لسؤال المستخدم.
على الرغم من أن هذا البرنامج التعليمي كان يقتصر على العمل مع جدول واحد (على سبيل المثال ، لا يوجد أي صلة بين الجداول) ، يمكن لبعض LLMs ، مثل تلك المتوفرة في Openai ، التعامل مع حالات أكثر تعقيدًا ، بما في ذلك العمل مع جداول متعددة وتحديد عمليات الوصلة الصحيحة. قد يكون ضبط وظيفة Lang2SQL للتعامل مع جداول متعددة الخطوة التالية لطيفة.
تم ترخيص هذا البرنامج التعليمي بموجب ترخيص Creative Commons Noncommercial-Sharealike 4.0 الدولي.


