system design 101
1.0.0
【 ?? YouTube | ? Newsletter 】
Erklären Sie komplexe Systeme anhand von Bildern und einfachen Begriffen.
Egal, ob Sie sich auf ein Systemdesign-Interview vorbereiten oder einfach nur verstehen möchten, wie Systeme unter der Oberfläche funktionieren, wir hoffen, dass dieses Repository Ihnen dabei hilft.
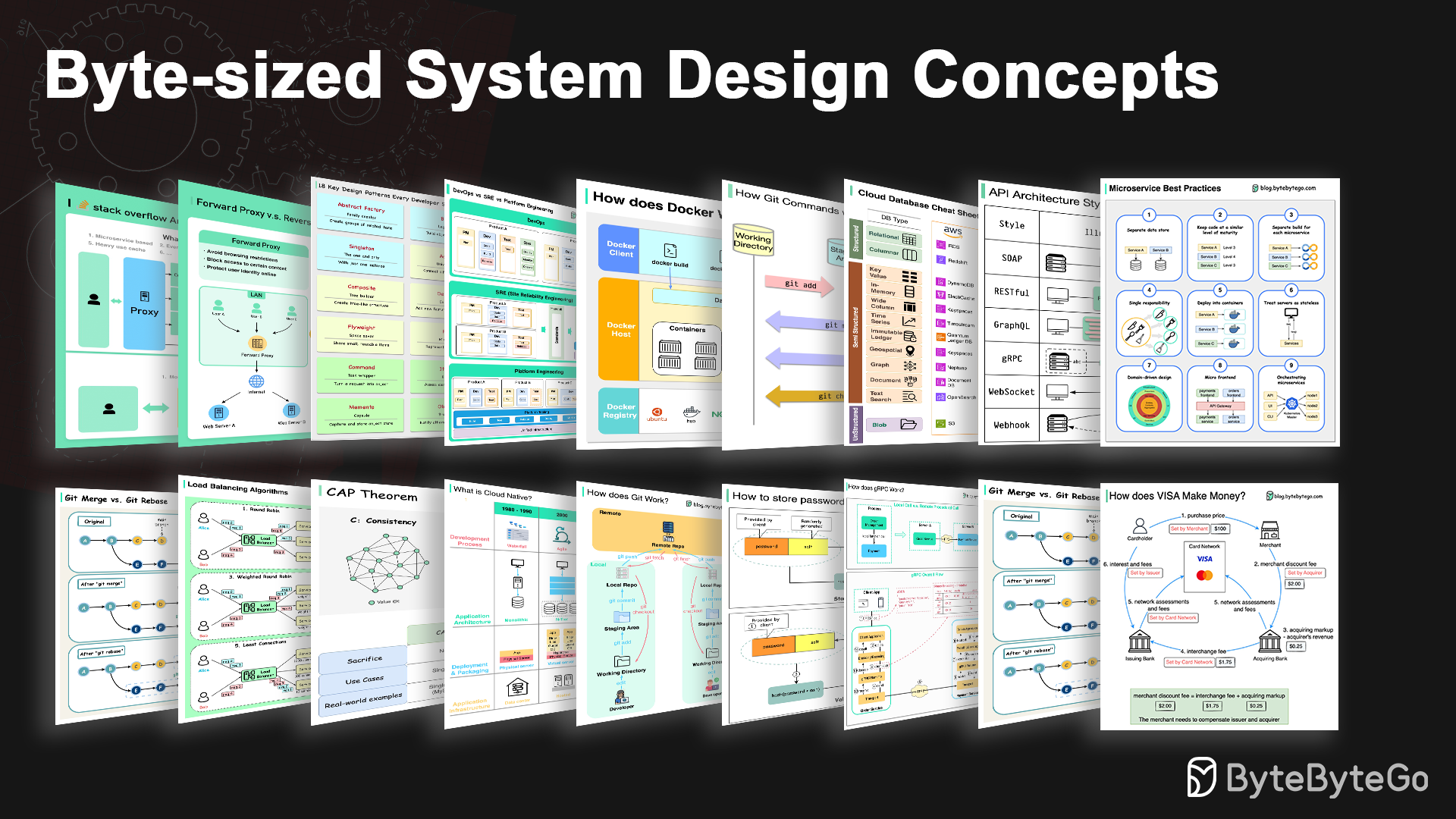
Architekturstile definieren, wie verschiedene Komponenten einer Anwendungsprogrammierschnittstelle (API) miteinander interagieren. Dadurch gewährleisten sie Effizienz, Zuverlässigkeit und einfache Integration mit anderen Systemen, indem sie einen Standardansatz für den Entwurf und die Erstellung von APIs bieten. Hier sind die am häufigsten verwendeten Stile:
SEIFE:
Ausgereift, umfassend, XML-basiert
Am besten für Unternehmensanwendungen geeignet
RUHIG:
Beliebte, einfach zu implementierende HTTP-Methoden
Ideal für Webdienste
GraphQL:
Abfragesprache, spezifische Daten anfordern
Reduziert den Netzwerk-Overhead und schnellere Antworten
gRPC:
Moderne, leistungsstarke Protokollpuffer
Geeignet für Microservices-Architekturen
WebSocket:
Bidirektionale, dauerhafte Verbindungen in Echtzeit
Perfekt für den Datenaustausch mit geringer Latenz
Webhook:
Ereignisgesteuert, HTTP-Rückrufe, asynchron
Benachrichtigt Systeme, wenn Ereignisse auftreten
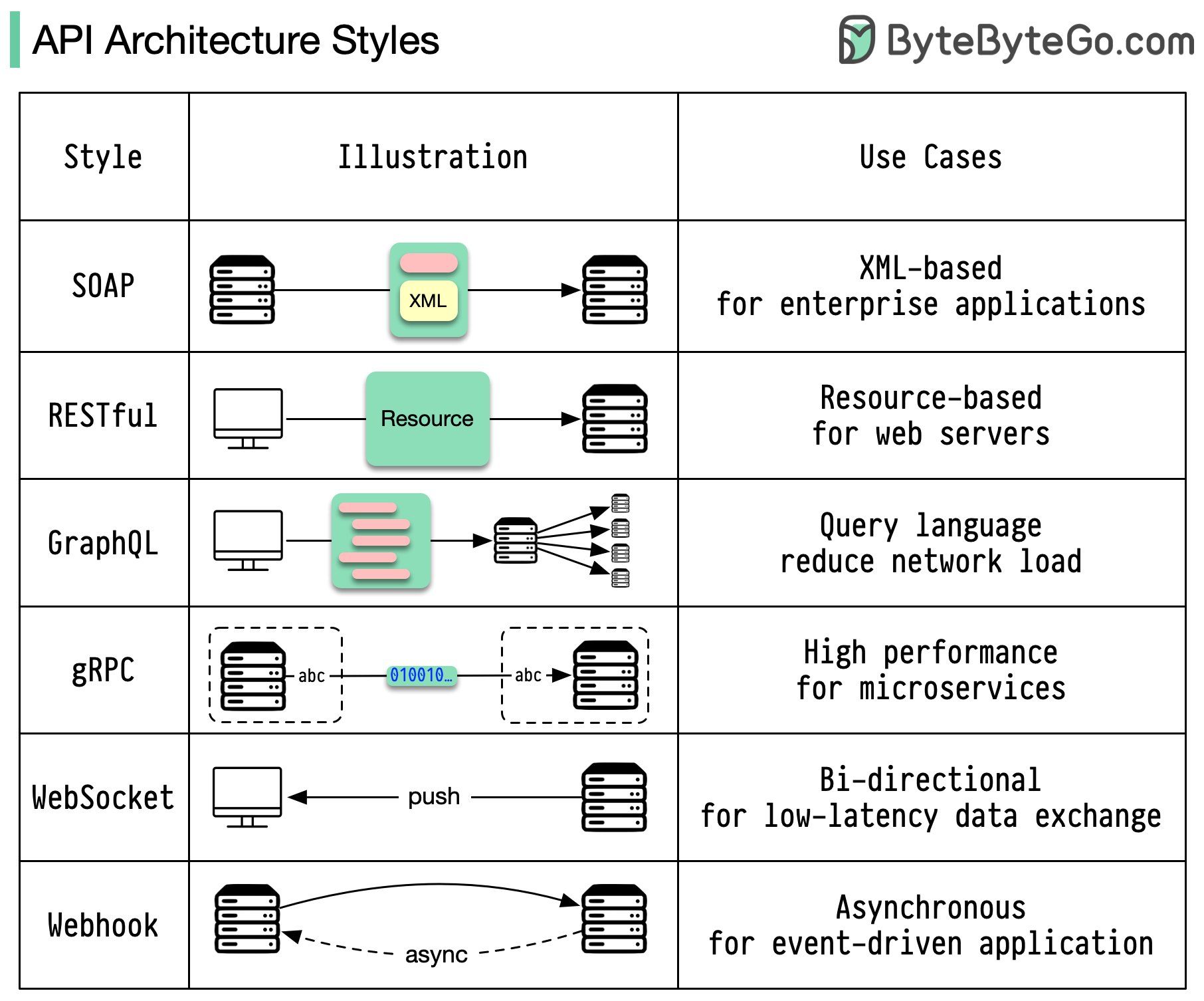
Wenn es um API-Design geht, haben REST und GraphQL jeweils ihre eigenen Stärken und Schwächen.
Das Diagramm unten zeigt einen schnellen Vergleich zwischen REST und GraphQL.
AUSRUHEN
GraphQL
Die beste Wahl zwischen REST und GraphQL hängt von den spezifischen Anforderungen des Anwendungs- und Entwicklungsteams ab. GraphQL eignet sich gut für komplexe oder sich häufig ändernde Frontend-Anforderungen, während REST für Anwendungen geeignet ist, bei denen einfache und konsistente Verträge bevorzugt werden.
Keiner der beiden API-Ansätze ist ein Allheilmittel. Um den richtigen Stil auszuwählen, ist es wichtig, die Anforderungen und Kompromisse sorgfältig abzuwägen. Sowohl REST als auch GraphQL sind gültige Optionen zum Offenlegen von Daten und zum Betrieb moderner Anwendungen.
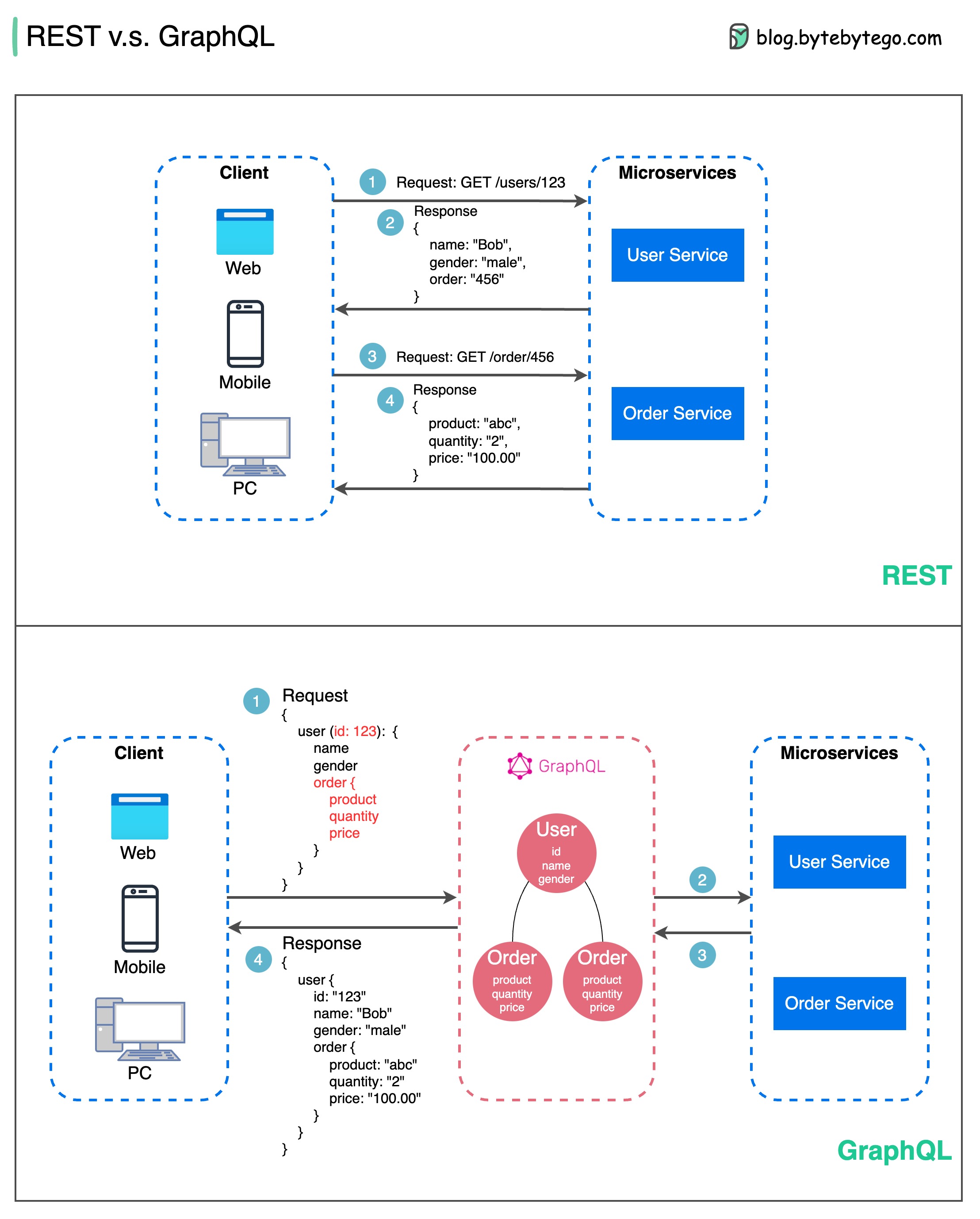
RPC (Remote Procedure Call) wird „ Remote “ genannt, weil es die Kommunikation zwischen Remote-Diensten ermöglicht, wenn Dienste auf verschiedenen Servern im Rahmen einer Microservice-Architektur bereitgestellt werden. Aus Benutzersicht verhält es sich wie ein lokaler Funktionsaufruf.
Das folgende Diagramm veranschaulicht den gesamten Datenfluss für gRPC .
Schritt 1: Vom Client aus erfolgt ein REST-Aufruf. Der Anforderungstext liegt normalerweise im JSON-Format vor.
Schritte 2–4: Der Bestelldienst (gRPC-Client) empfängt den REST-Aufruf, wandelt ihn um und führt einen RPC-Aufruf an den Zahlungsdienst durch. gRPC kodiert den Client-Stub in ein Binärformat und sendet ihn an die Low-Level-Transportschicht.
Schritt 5: gRPC sendet die Pakete über HTTP2 über das Netzwerk. Aufgrund der binären Kodierung und Netzwerkoptimierungen soll gRPC fünfmal schneller sein als JSON.
Schritte 6–8: Der Zahlungsdienst (gRPC-Server) empfängt die Pakete vom Netzwerk, dekodiert sie und ruft die Serveranwendung auf.
Schritte 9–11: Das Ergebnis wird von der Serveranwendung zurückgegeben, codiert und an die Transportschicht gesendet.
Schritte 12–14: Der Bestelldienst empfängt die Pakete, dekodiert sie und sendet das Ergebnis an die Client-Anwendung.
Das folgende Diagramm zeigt einen Vergleich zwischen Polling und Webhook.
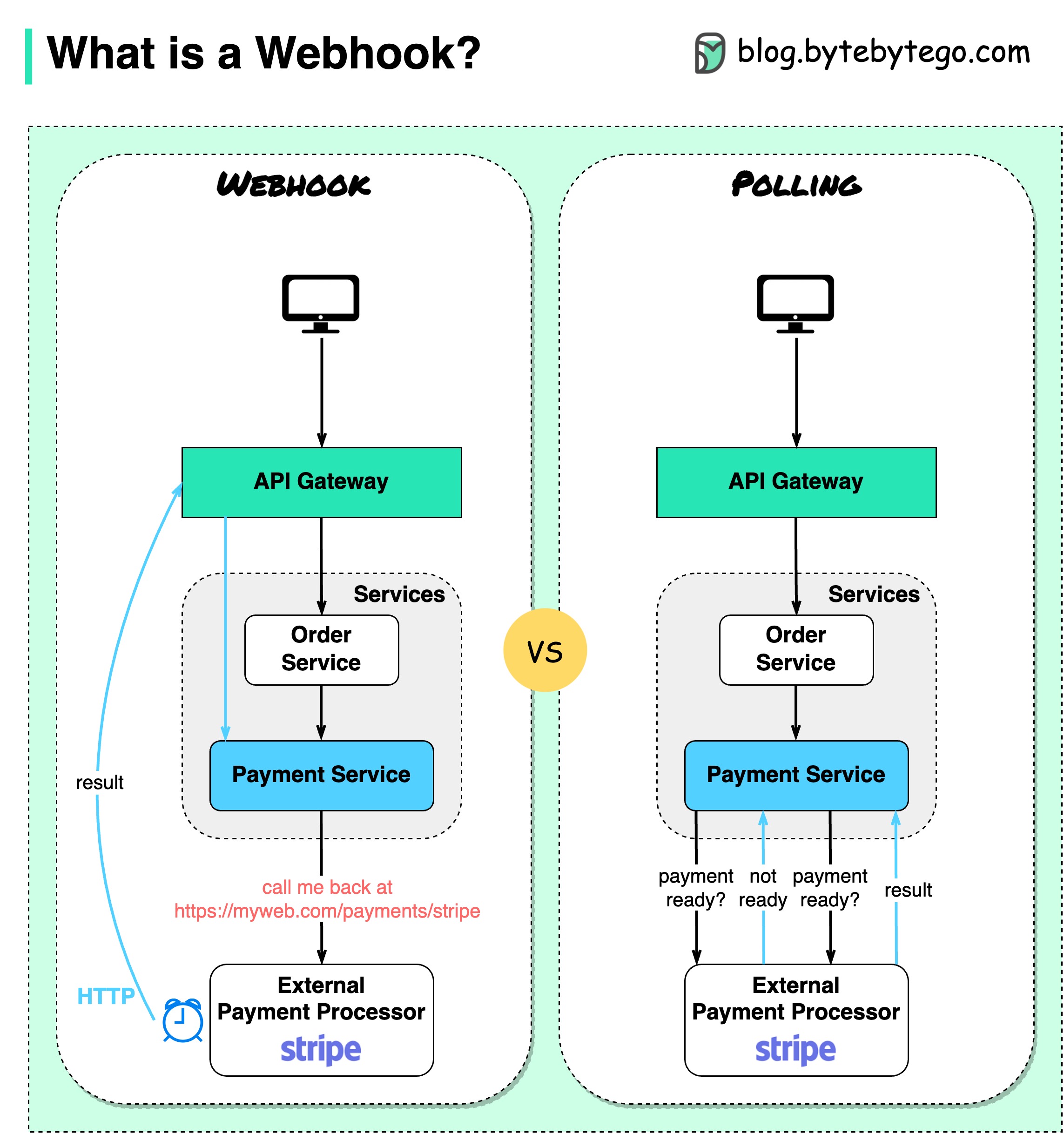
Angenommen, wir betreiben eine E-Commerce-Website. Über das API-Gateway senden die Kunden Bestellungen an den Bestelldienst, der für den Zahlungsverkehr an den Zahlungsdienst geht. Der Zahlungsdienst kommuniziert dann mit einem externen Zahlungsdienstleister (PSP), um die Transaktionen abzuschließen.
Es gibt zwei Möglichkeiten, die Kommunikation mit dem externen PSP abzuwickeln.
1. Kurze Umfrage
Nach dem Senden der Zahlungsanforderung an den PSP fragt der Zahlungsdienst den PSP immer wieder nach dem Zahlungsstatus. Nach mehreren Runden meldet sich die PSP schließlich mit dem Status zurück.
Kurzabfragen haben zwei Nachteile:
2. Webhook
Wir können einen Webhook beim externen Dienst registrieren. Das bedeutet: Rufen Sie mich unter einer bestimmten URL zurück, wenn Sie Updates zu der Anfrage haben. Wenn der PSP die Verarbeitung abgeschlossen hat, ruft er die HTTP-Anfrage auf, um den Zahlungsstatus zu aktualisieren.
Auf diese Weise wird das Programmierparadigma geändert und der Zahlungsdienst muss keine Ressourcen mehr verschwenden, um den Zahlungsstatus abzufragen.
Was passiert, wenn die PSP nie zurückruft? Wir können einen Reinigungsauftrag einrichten, um den Zahlungsstatus stündlich zu überprüfen.
Webhooks werden oft als Reverse-APIs oder Push-APIs bezeichnet, da der Server HTTP-Anfragen an den Client sendet. Bei der Verwendung eines Webhooks müssen wir auf drei Dinge achten:
Das folgende Diagramm zeigt 5 gängige Tricks zur Verbesserung der API-Leistung.
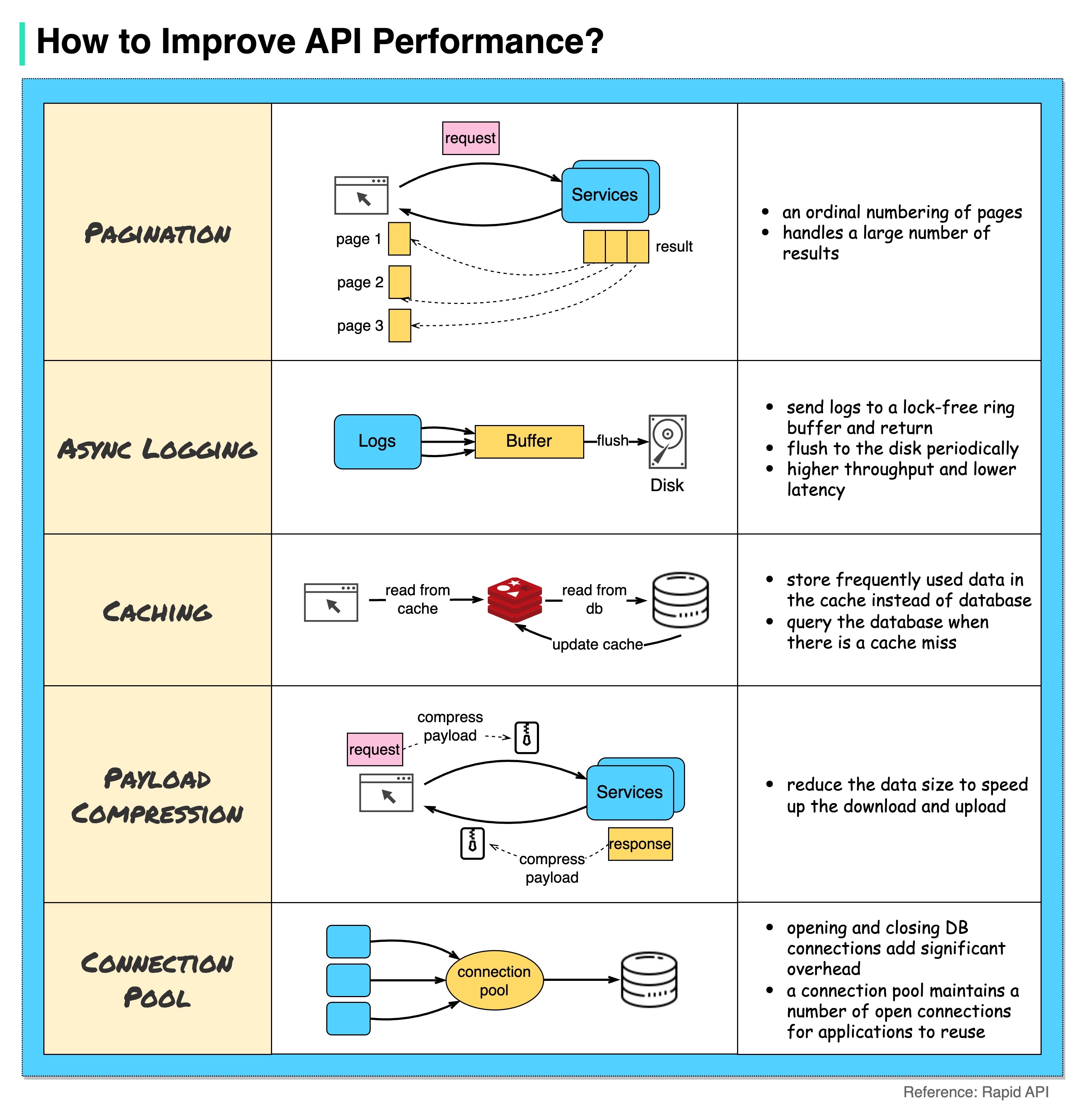
Pagination
Dies ist eine häufige Optimierung, wenn das Ergebnis groß ist. Die Ergebnisse werden an den Client zurückgestreamt, um die Reaktionsfähigkeit des Dienstes zu verbessern.
Asynchrone Protokollierung
Die synchrone Protokollierung beschäftigt sich bei jedem Aufruf mit der Festplatte und kann das System verlangsamen. Bei der asynchronen Protokollierung werden Protokolle zunächst an einen sperrfreien Puffer gesendet und sofort zurückgegeben. Die Protokolle werden regelmäßig auf die Festplatte geschrieben. Dadurch wird der I/O-Overhead deutlich reduziert.
Caching
Wir können häufig aufgerufene Daten in einem Cache speichern. Der Client kann zuerst den Cache abfragen, anstatt die Datenbank direkt zu besuchen. Bei einem Cache-Fehler kann der Client eine Abfrage aus der Datenbank durchführen. Caches wie Redis speichern Daten im Speicher, sodass der Datenzugriff viel schneller ist als der der Datenbank.
Nutzlastkomprimierung
Die Anfragen und Antworten können mit gzip etc. komprimiert werden, sodass die übertragene Datengröße deutlich kleiner ist. Dies beschleunigt den Upload und Download.
Verbindungspool
Beim Zugriff auf Ressourcen müssen wir häufig Daten aus der Datenbank laden. Das Öffnen der schließenden Datenbankverbindungen verursacht einen erheblichen Mehraufwand. Wir sollten uns also über einen Pool offener Verbindungen mit der Datenbank verbinden. Der Verbindungspool ist für die Verwaltung des Verbindungslebenszyklus verantwortlich.
Welches Problem löst jede HTTP-Generation?
Das folgende Diagramm veranschaulicht die wichtigsten Funktionen.
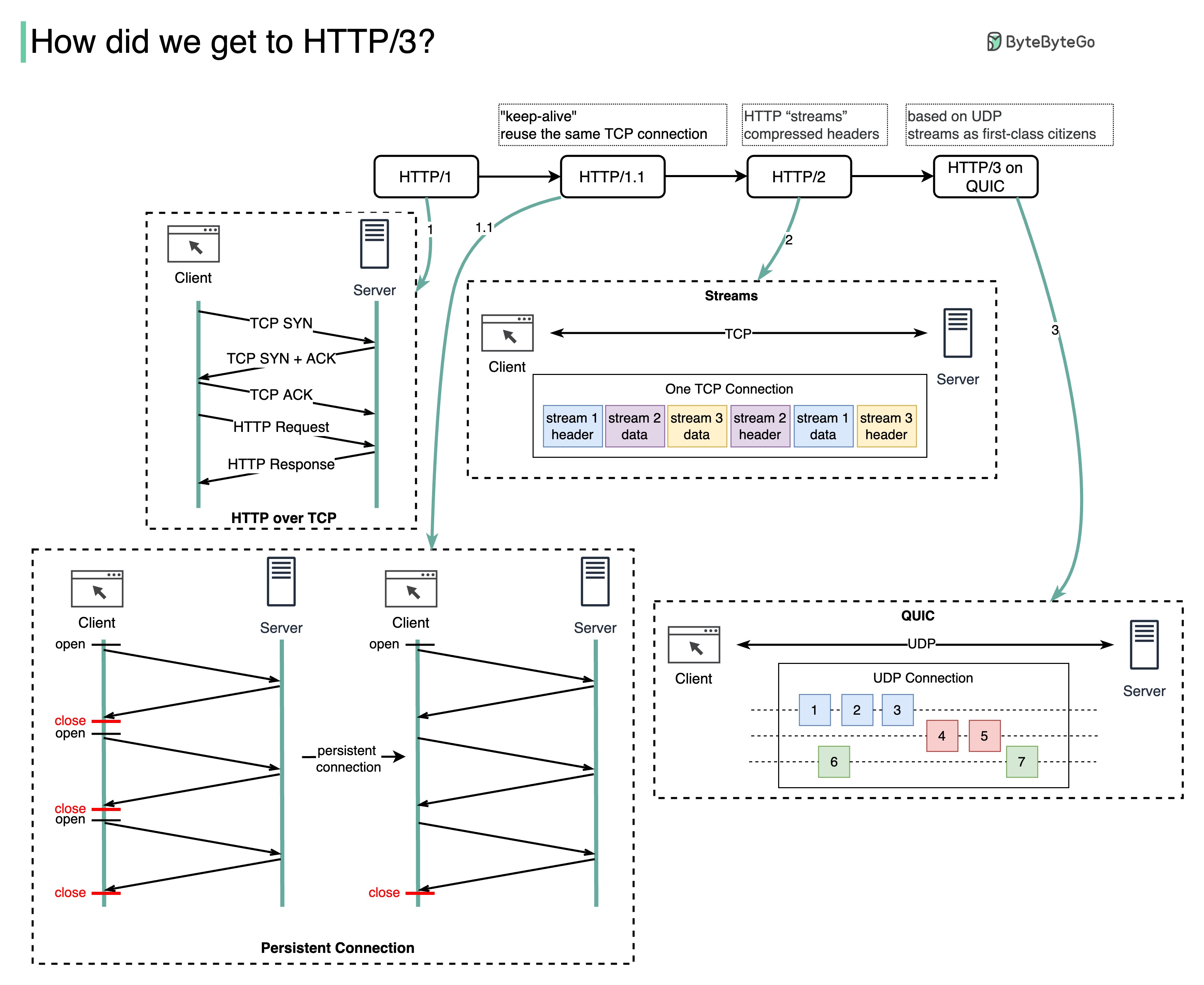
HTTP 1.0 wurde 1996 fertiggestellt und vollständig dokumentiert. Jede Anfrage an denselben Server erfordert eine separate TCP-Verbindung.
HTTP 1.1 wurde 1997 veröffentlicht. Eine TCP-Verbindung kann zur Wiederverwendung offen gelassen werden (persistente Verbindung), löst jedoch nicht das Problem der HOL-Blockierung (Head-of-Line).
HOL-Blockierung – wenn die Anzahl der zulässigen parallelen Anfragen im Browser aufgebraucht ist, müssen nachfolgende Anfragen warten, bis die vorherigen abgeschlossen sind.
HTTP 2.0 wurde 2015 veröffentlicht. Es behebt das HOL-Problem durch Anforderungsmultiplexing, wodurch die HOL-Blockierung auf der Anwendungsebene beseitigt wird, HOL jedoch weiterhin auf der Transportebene (TCP) vorhanden ist.
Wie Sie im Diagramm sehen können, führte HTTP 2.0 das Konzept der HTTP-„Streams“ ein: eine Abstraktion, die das Multiplexen verschiedener HTTP-Austausche auf derselben TCP-Verbindung ermöglicht. Es muss nicht jeder Stream der Reihe nach gesendet werden.
Der erste Entwurf von HTTP 3.0 wurde 2020 veröffentlicht. Es handelt sich um den vorgeschlagenen Nachfolger von HTTP 2.0. Es verwendet QUIC anstelle von TCP für das zugrunde liegende Transportprotokoll und beseitigt so die HOL-Blockierung in der Transportschicht.
QUIC basiert auf UDP. Es führt Streams als erstklassige Bürger auf der Transportebene ein. QUIC-Streams teilen sich die gleiche QUIC-Verbindung, sodass keine zusätzlichen Handshakes und langsamen Starts erforderlich sind, um neue Streams zu erstellen. QUIC-Streams werden jedoch unabhängig voneinander bereitgestellt, sodass sich Paketverluste, die einen Stream betreffen, in den meisten Fällen nicht auf andere auswirken.
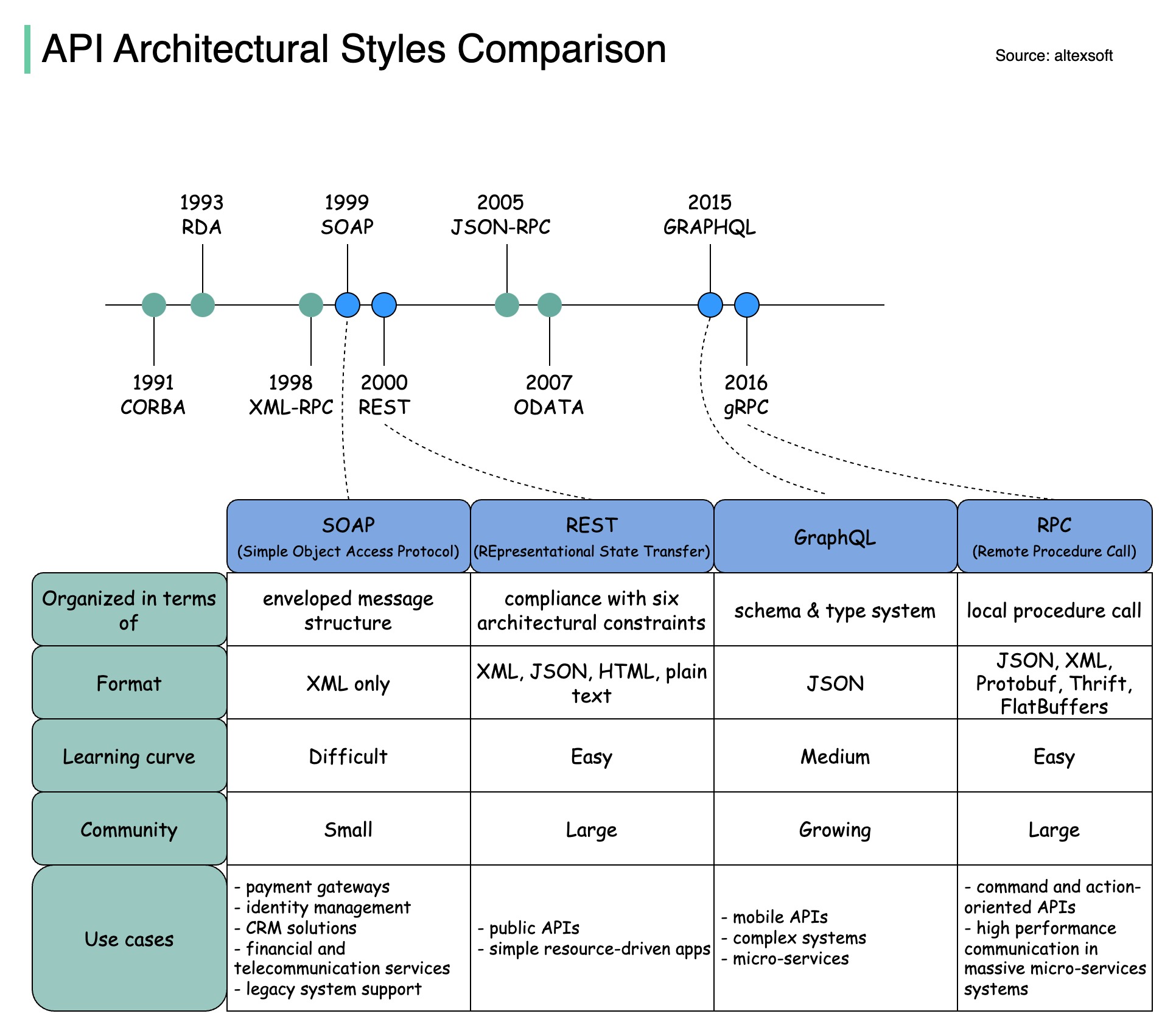
Das folgende Diagramm veranschaulicht den Vergleich der API-Zeitleiste und der API-Stile.
Im Laufe der Zeit werden verschiedene API-Architekturstile veröffentlicht. Jeder von ihnen hat seine eigenen Muster zur Standardisierung des Datenaustauschs.
Sie können die Anwendungsfälle jedes Stils im Diagramm überprüfen.
Das folgende Diagramm zeigt die Unterschiede zwischen Code-First-Entwicklung und API-First-Entwicklung. Warum möchten wir das API-First-Design in Betracht ziehen?
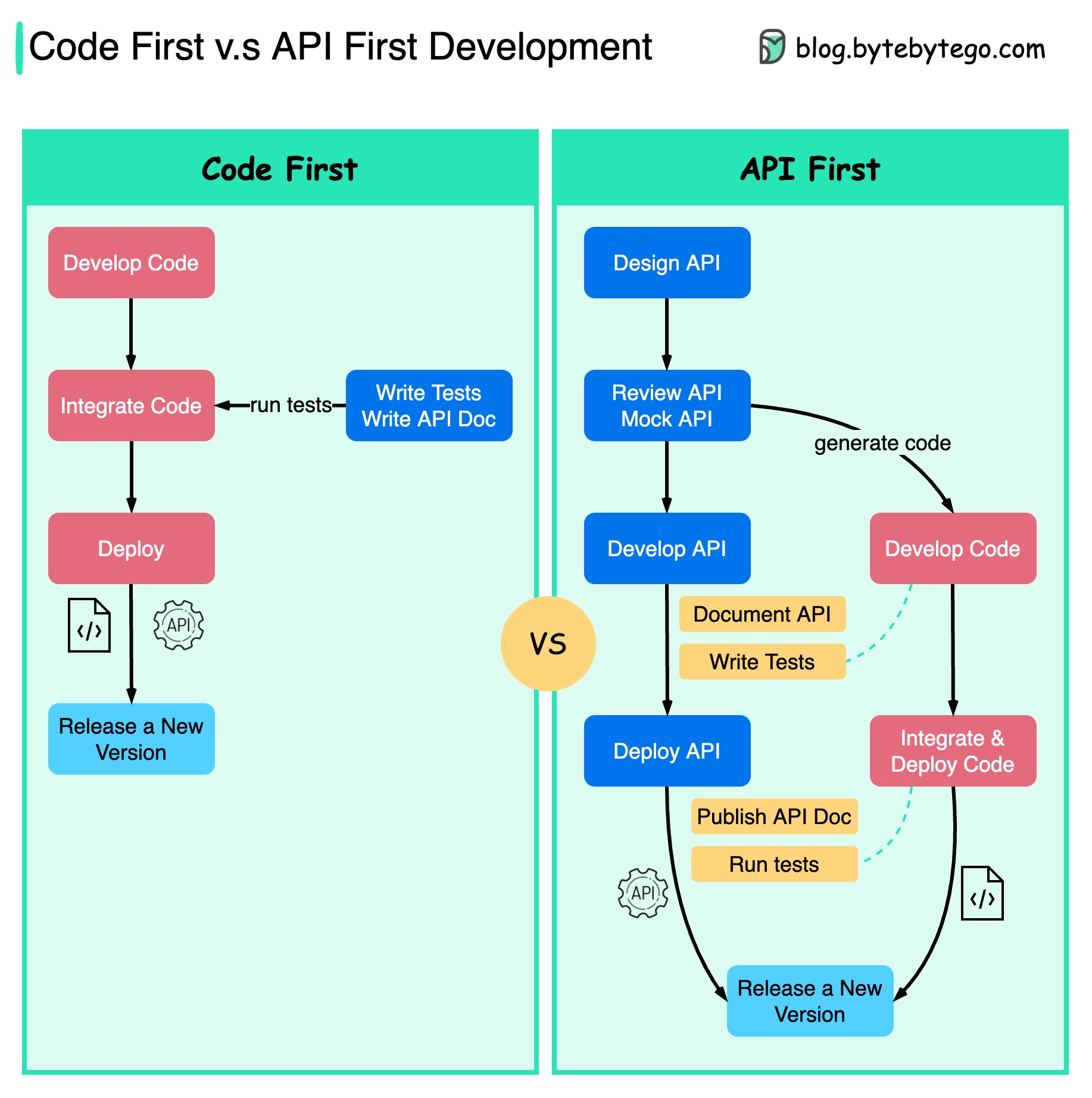
Es ist besser, die Komplexität des Systems zu durchdenken, bevor Sie den Code schreiben und die Grenzen der Dienste sorgfältig definieren.
Wir können Anfragen und Antworten simulieren, um das API-Design zu validieren, bevor wir Code schreiben.
Auch Entwickler freuen sich über den Prozess, da sie sich auf die funktionale Entwicklung konzentrieren können, anstatt plötzliche Änderungen auszuhandeln.
Die Wahrscheinlichkeit von Überraschungen gegen Ende des Projektlebenszyklus wird verringert.
Da wir zuerst die API entworfen haben, können die Tests entworfen werden, während der Code entwickelt wird. In gewisser Weise verfügen wir auch über TDD (Test Driven Design), wenn wir die API-Erstentwicklung verwenden.
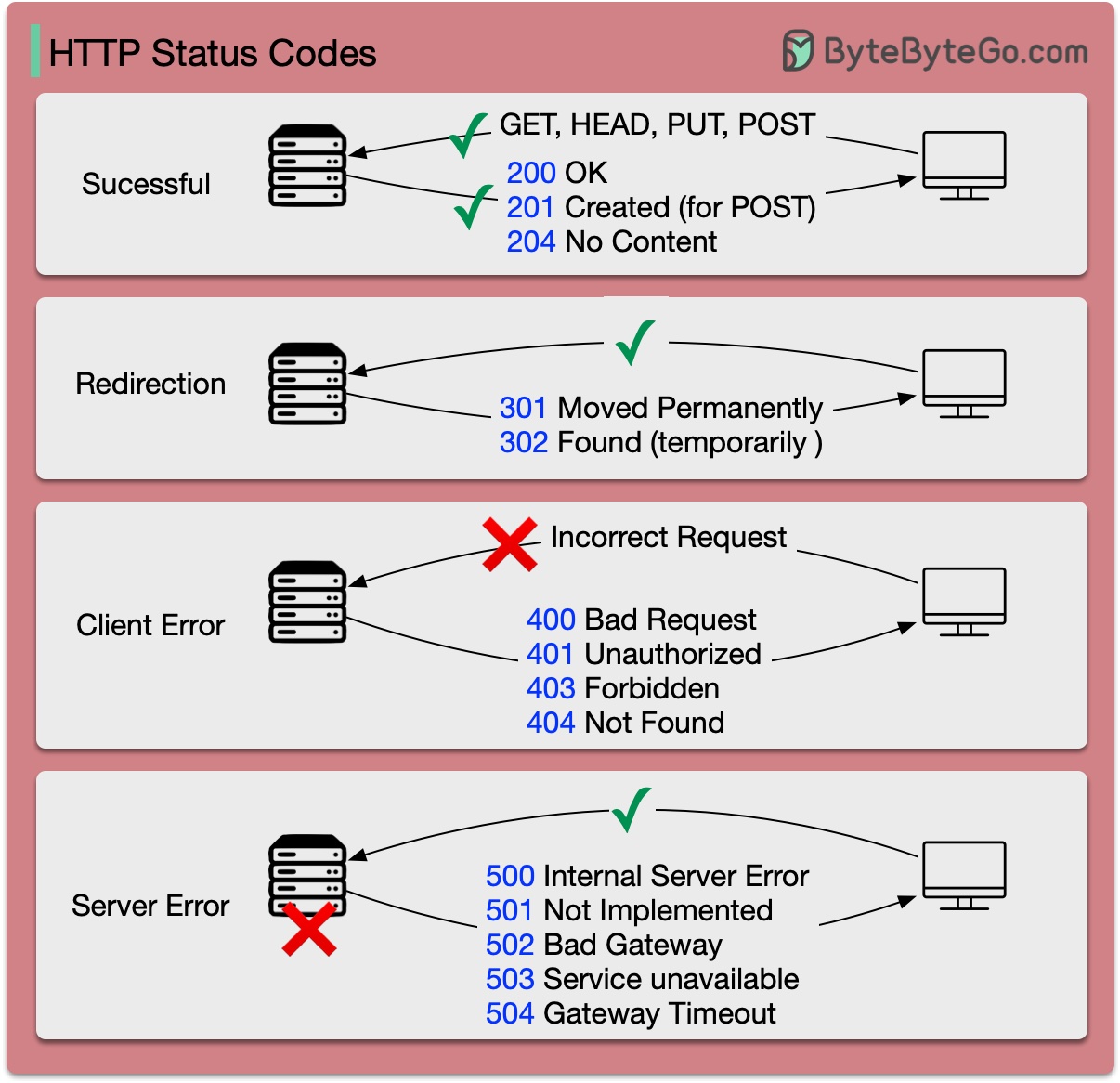
Die Antwortcodes für HTTP sind in fünf Kategorien unterteilt:
Informativ (100–199) Erfolgreich (200–299) Umleitung (300–399) Clientfehler (400–499) Serverfehler (500–599)
Das Diagramm unten zeigt die Details.
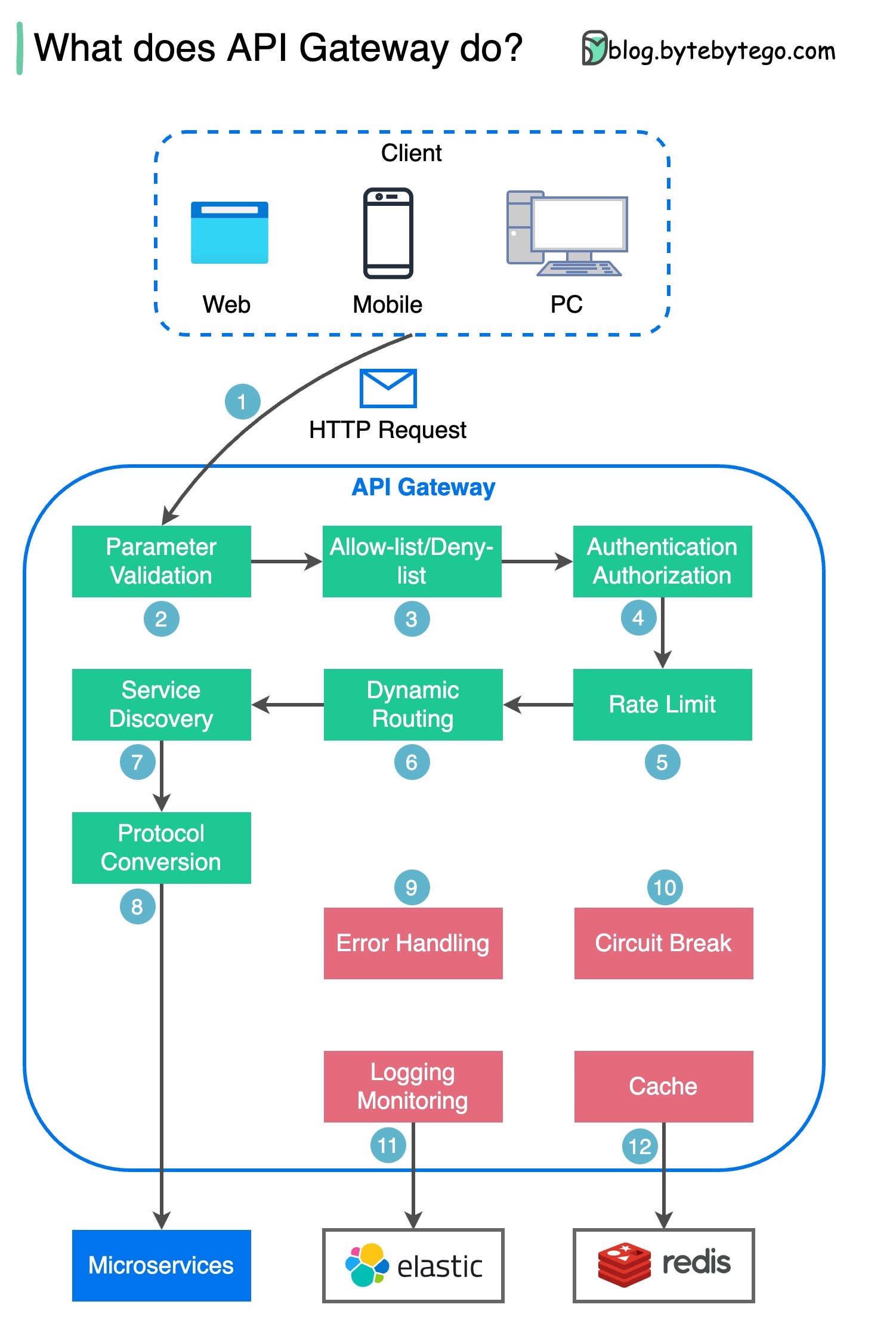
Schritt 1 – Der Client sendet eine HTTP-Anfrage an das API-Gateway.
Schritt 2 – Das API-Gateway analysiert und validiert die Attribute in der HTTP-Anfrage.
Schritt 3 – Das API-Gateway führt Zulassungslisten-/Verweigerungslistenprüfungen durch.
Schritt 4 – Das API-Gateway kommuniziert mit einem Identitätsanbieter zur Authentifizierung und Autorisierung.
Schritt 5 – Die Ratenbegrenzungsregeln werden auf die Anfrage angewendet. Bei Überschreitung des Limits wird die Anfrage abgelehnt.
Schritte 6 und 7 – Nachdem die Anfrage nun die grundlegenden Prüfungen bestanden hat, findet das API-Gateway den relevanten Dienst, zu dem die Weiterleitung erfolgen soll, durch Pfadabgleich.
Schritt 8 – Das API-Gateway wandelt die Anfrage in das entsprechende Protokoll um und sendet sie an Backend-Microservices.
Schritte 9–12: Das API-Gateway kann Fehler ordnungsgemäß verarbeiten und behandelt Fehler, wenn die Fehlerbeseitigung länger dauert (Stromkreisunterbrechung). Es kann auch den ELK-Stack (Elastic-Logstash-Kibana) für die Protokollierung und Überwachung nutzen. Manchmal zwischenspeichern wir Daten im API-Gateway.
Das folgende Diagramm zeigt typische API-Designs anhand eines Warenkorbbeispiels.
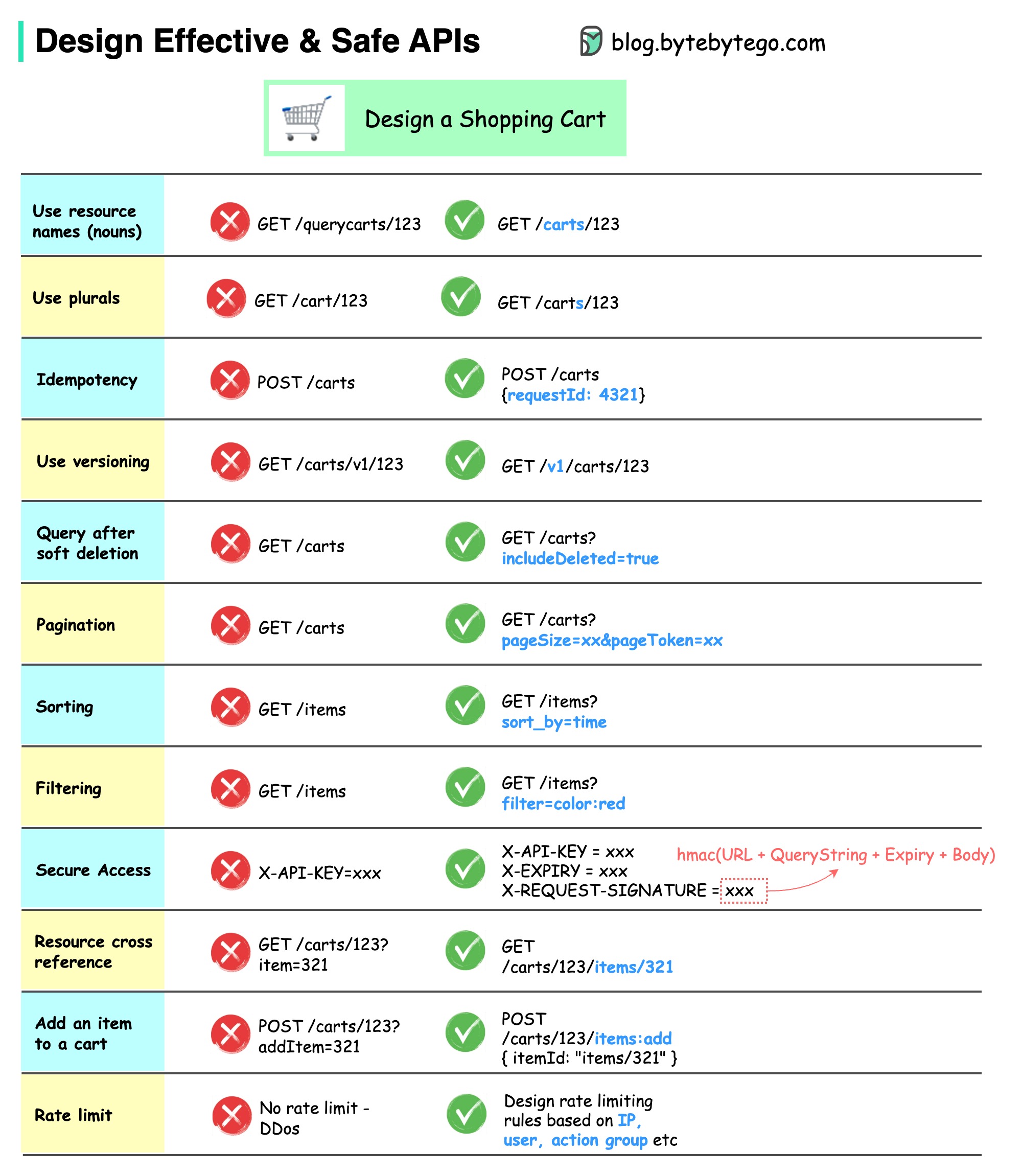
Beachten Sie, dass es sich beim API-Design nicht nur um das URL-Pfad-Design handelt. Meistens müssen wir die richtigen Ressourcennamen, Bezeichner und Pfadmuster auswählen. Ebenso wichtig ist es, geeignete HTTP-Header-Felder oder wirksame Regeln zur Ratenbegrenzung innerhalb des API-Gateways zu entwerfen.
Wie werden Daten über das Netzwerk gesendet? Warum brauchen wir so viele Schichten im OSI-Modell?
Das folgende Diagramm zeigt, wie Daten bei der Übertragung über das Netzwerk gekapselt und entkapselt werden.
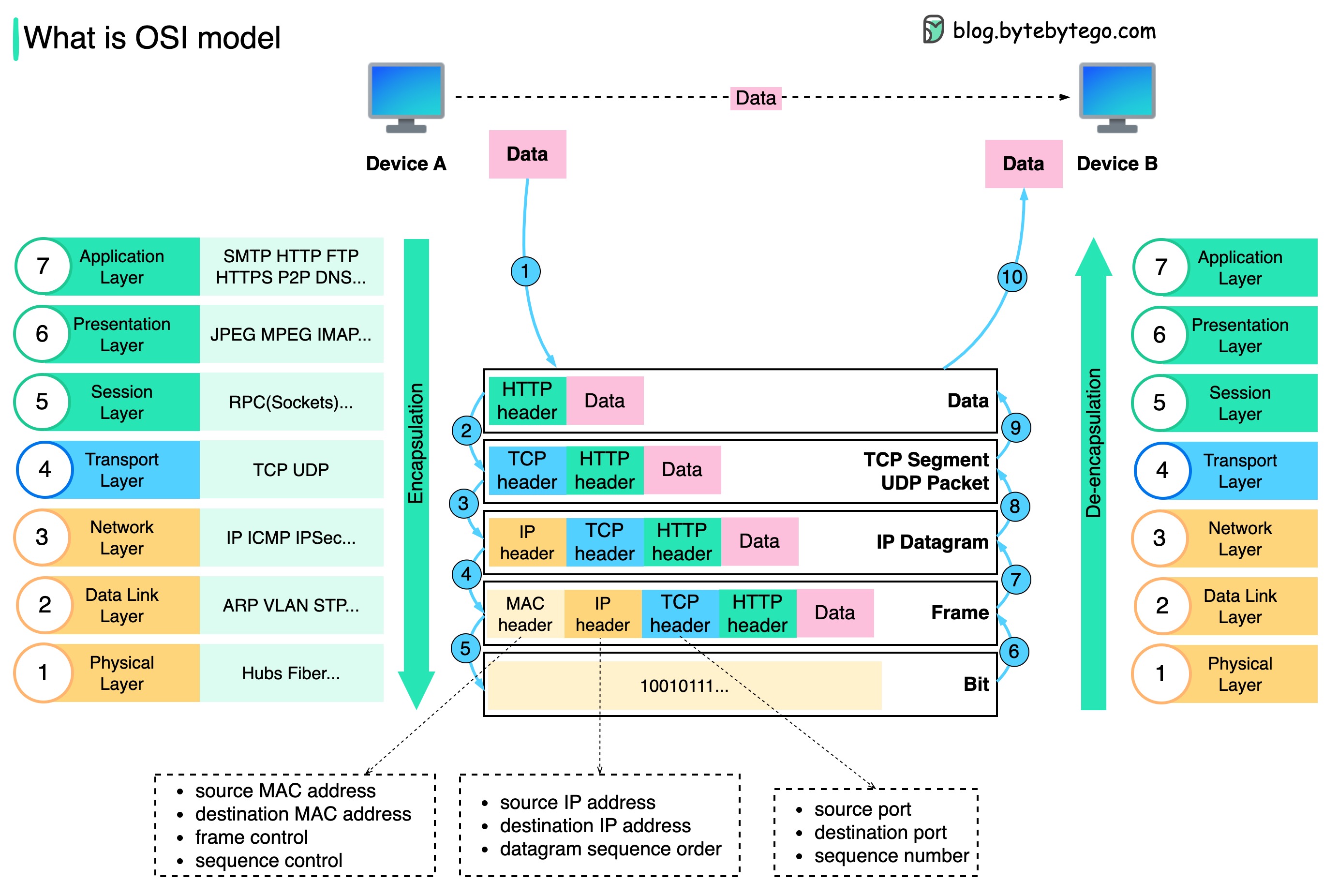
Schritt 1: Wenn Gerät A Daten über das Netzwerk über das HTTP-Protokoll an Gerät B sendet, wird ihm zunächst ein HTTP-Header auf der Anwendungsebene hinzugefügt.
Schritt 2: Anschließend wird den Daten ein TCP- oder UDP-Header hinzugefügt. Es ist auf der Transportschicht in TCP-Segmente gekapselt. Der Header enthält den Quellport, den Zielport und die Sequenznummer.
Schritt 3: Die Segmente werden dann mit einem IP-Header auf der Netzwerkebene gekapselt. Der IP-Header enthält die Quell-/Ziel-IP-Adressen.
Schritt 4: Dem IP-Datagramm wird auf der Datenverbindungsebene ein MAC-Header mit Quell-/Ziel-MAC-Adressen hinzugefügt.
Schritt 5: Die gekapselten Frames werden an die physikalische Schicht gesendet und in Binärbits über das Netzwerk gesendet.
Schritte 6–10: Wenn Gerät B die Bits vom Netzwerk empfängt, führt es den Entkapselungsprozess durch, bei dem es sich um eine umgekehrte Verarbeitung des Kapselungsprozesses handelt. Die Header werden Schicht für Schicht entfernt, und schließlich kann Gerät B die Daten lesen.
Wir brauchen Schichten im Netzwerkmodell, weil sich jede Schicht auf ihre eigenen Verantwortlichkeiten konzentriert. Jede Schicht kann sich bei der Verarbeitung von Anweisungen auf die Header verlassen und muss die Bedeutung der Daten der letzten Schicht nicht kennen.
Das folgende Diagramm zeigt die Unterschiede zwischen einem ??????? ????? und ein ??????? ?????.
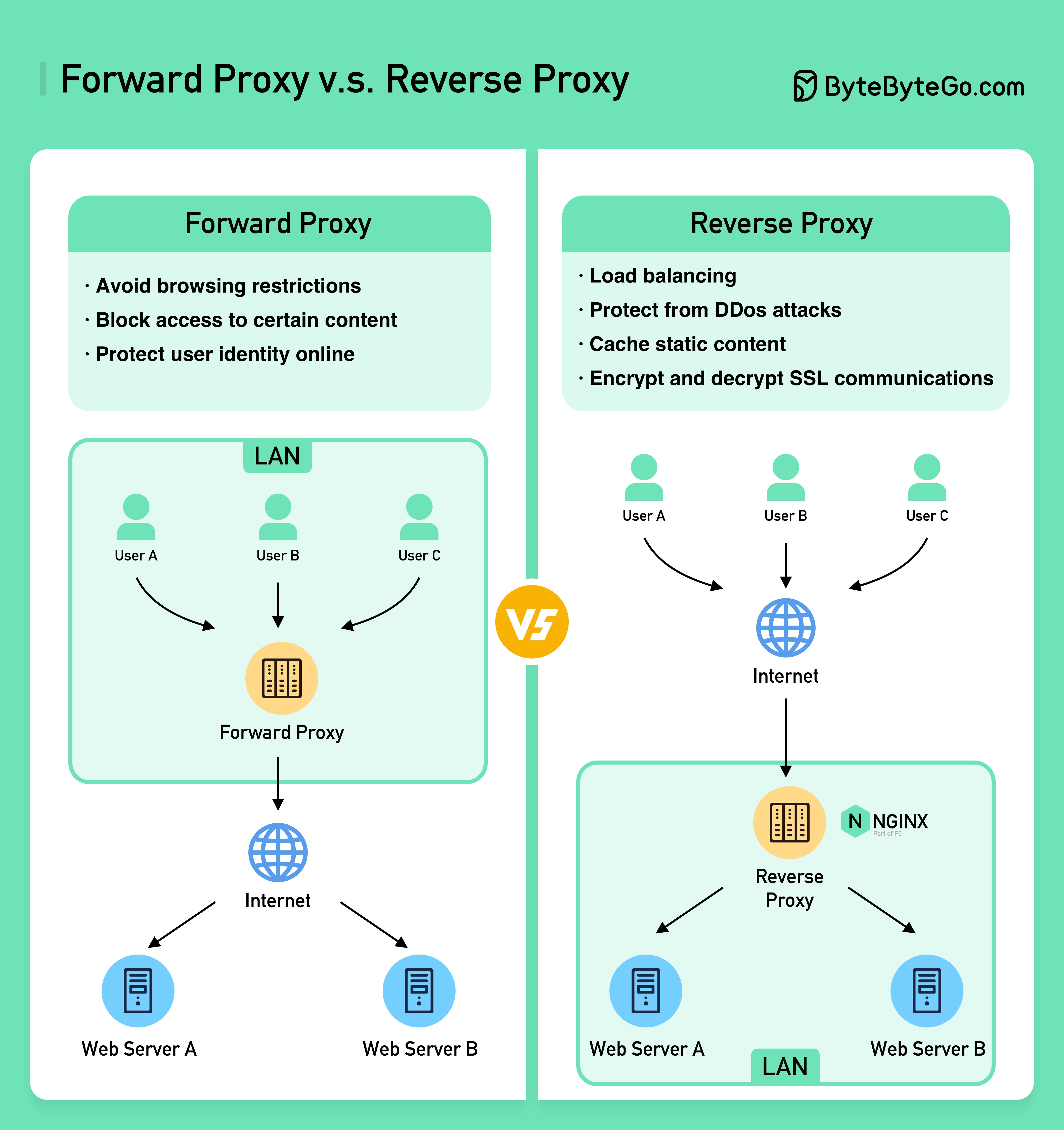
Ein Forward-Proxy ist ein Server, der zwischen Benutzergeräten und dem Internet sitzt.
Ein Forward-Proxy wird üblicherweise verwendet für:
Ein Reverse-Proxy ist ein Server, der eine Anfrage vom Client akzeptiert, die Anfrage an Webserver weiterleitet und die Ergebnisse an den Client zurückgibt, als ob der Proxyserver die Anfrage verarbeitet hätte.
Ein Reverse-Proxy eignet sich für:
Das Diagramm unten zeigt 6 gängige Algorithmen.
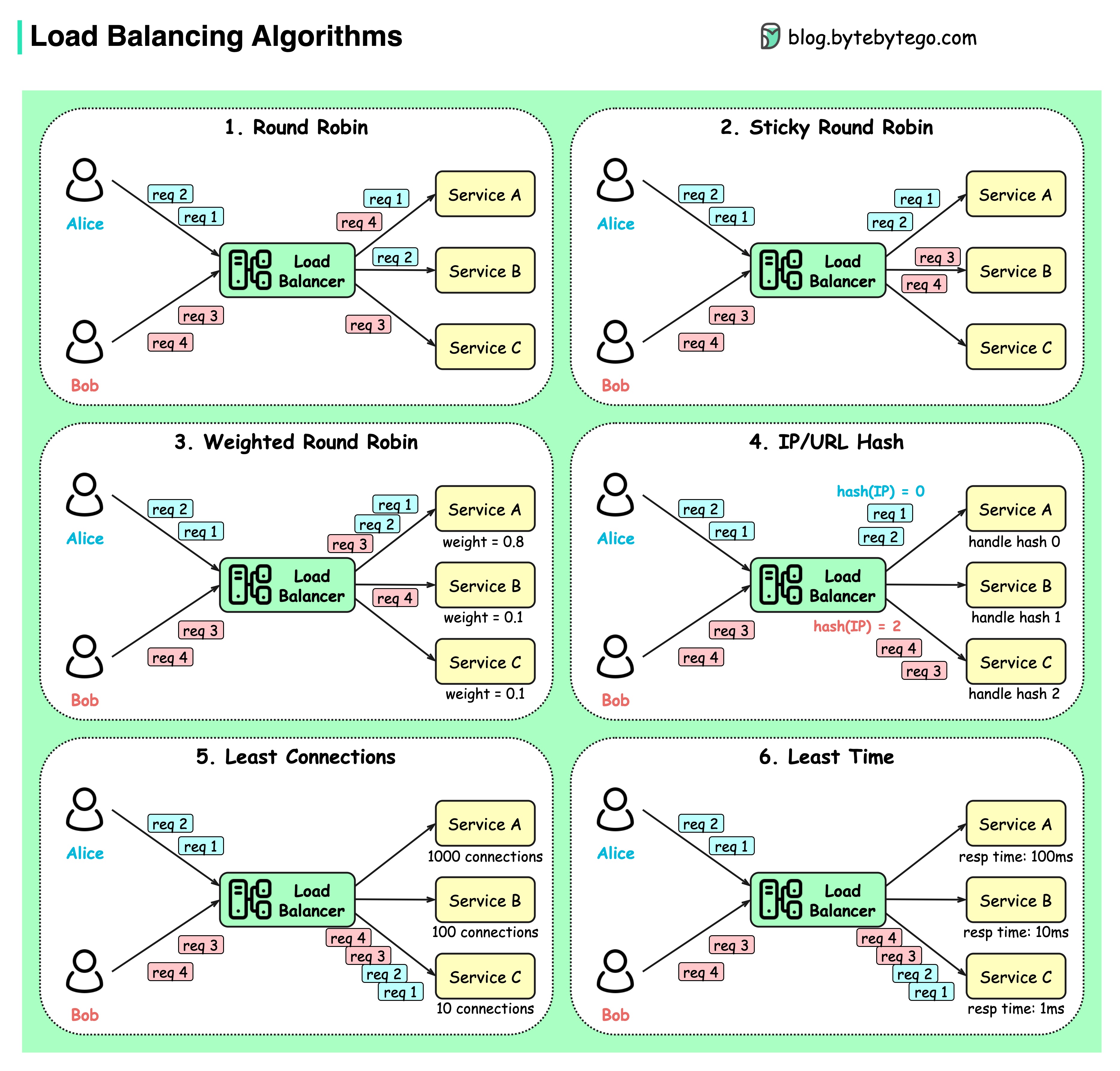
Round-Robin
Die Clientanfragen werden in sequentieller Reihenfolge an verschiedene Dienstinstanzen gesendet. Die Dienste müssen in der Regel staatenlos sein.
Klebriges Round-Robin
Dies ist eine Verbesserung des Round-Robin-Algorithmus. Wenn Alices erste Anfrage an Dienst A geht, gehen die folgenden Anfragen auch an Dienst A.
Gewichtetes Round-Robin
Der Administrator kann die Gewichtung für jeden Dienst festlegen. Diejenigen mit einem höheren Gewicht bearbeiten mehr Anfragen als andere.
Hash
Dieser Algorithmus wendet eine Hash-Funktion auf die IP oder URL der eingehenden Anfragen an. Die Anfragen werden basierend auf dem Ergebnis der Hash-Funktion an relevante Instanzen weitergeleitet.
Am wenigsten Verbindungen
Eine neue Anfrage wird an die Dienstinstanz mit den wenigsten gleichzeitigen Verbindungen gesendet.
Geringste Reaktionszeit
Eine neue Anfrage wird an die Dienstinstanz mit der schnellsten Antwortzeit gesendet.
Das folgende Diagramm zeigt einen Vergleich von URL, URI und URN.
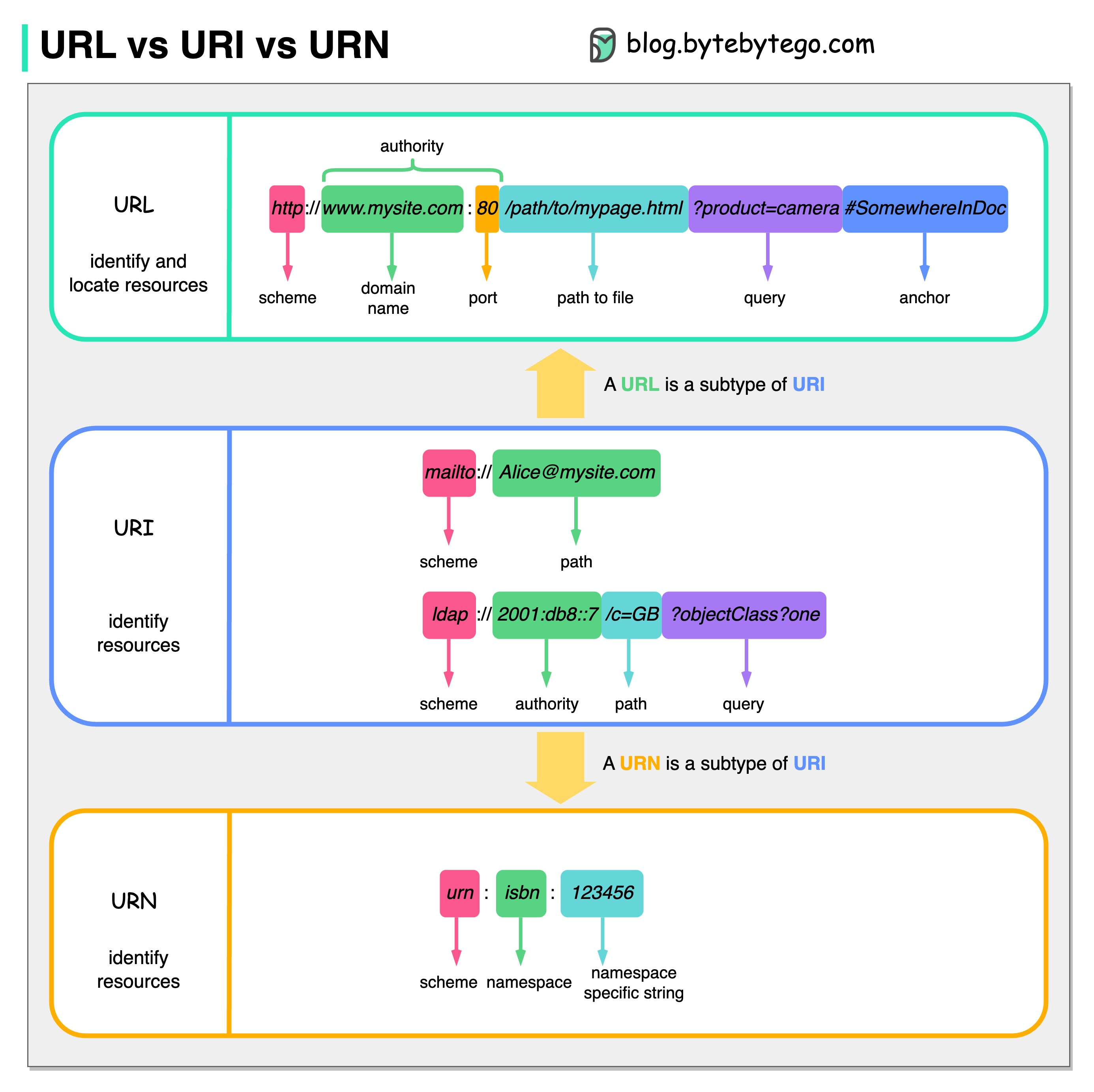
URI steht für Uniform Resource Identifier. Es identifiziert eine logische oder physische Ressource im Web. URL und URN sind Untertypen von URI. URL lokalisiert eine Ressource, während URN eine Ressource benennt.
Ein URI besteht aus den folgenden Teilen: Schema:[//Autorität]Pfad[?Abfrage][#Fragment]
URL steht für Uniform Resource Locator, das Schlüsselkonzept von HTTP. Es handelt sich um die Adresse einer einzigartigen Ressource im Web. Es kann mit anderen Protokollen wie FTP und JDBC verwendet werden.
URN steht für Uniform Resource Name. Es nutzt das Urnenschema. URNs können nicht zum Auffinden einer Ressource verwendet werden. Ein einfaches Beispiel im Diagramm besteht aus einem Namespace und einer namespacespezifischen Zeichenfolge.
Wenn Sie mehr Details zu diesem Thema erfahren möchten, würde ich die Klarstellung durch W3C empfehlen.
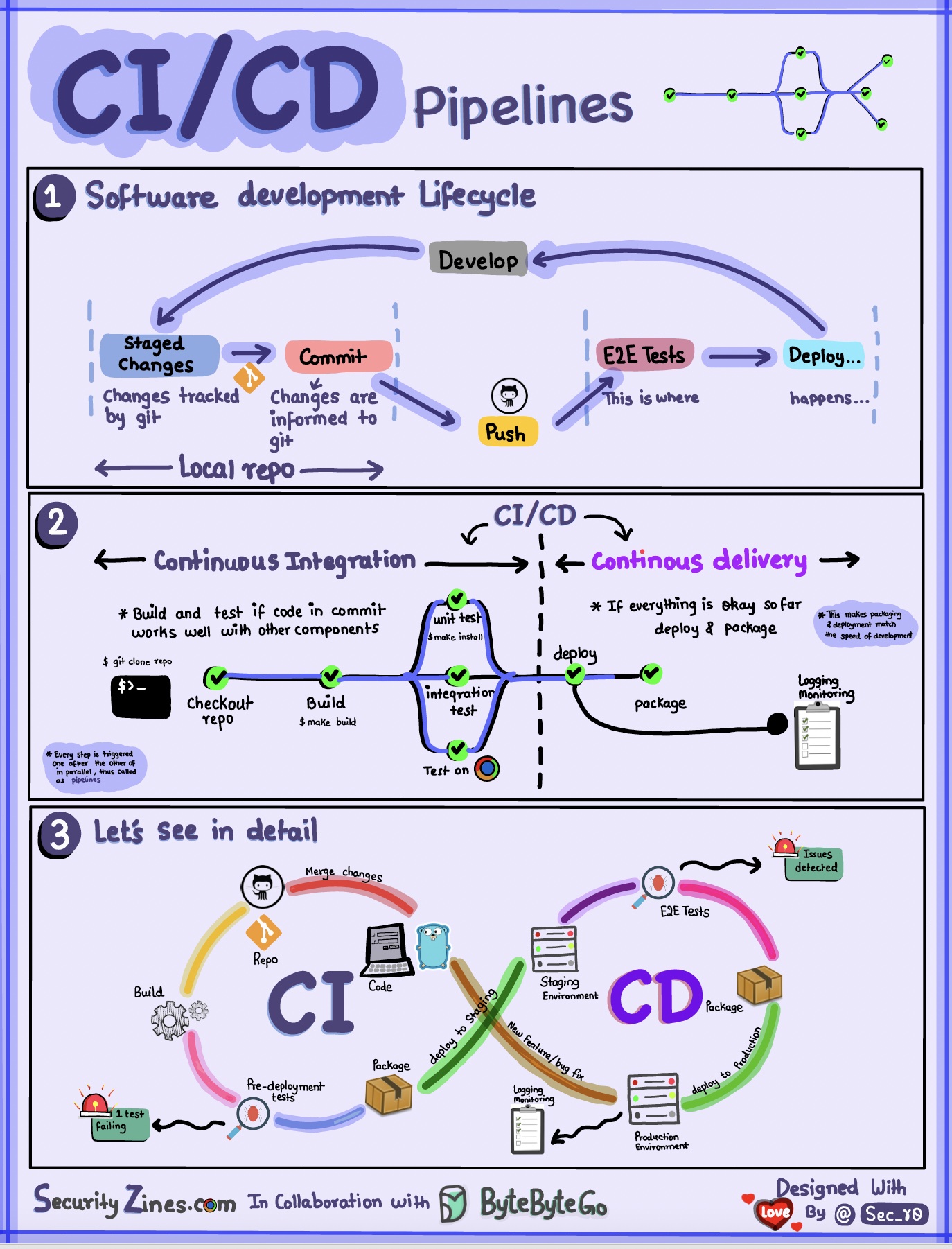
Abschnitt 1 – SDLC mit CI/CD
Der Softwareentwicklungslebenszyklus (SDLC) besteht aus mehreren Schlüsselphasen: Entwicklung, Tests, Bereitstellung und Wartung. CI/CD automatisiert und integriert diese Phasen, um schnellere und zuverlässigere Releases zu ermöglichen.
Wenn Code in ein Git-Repository übertragen wird, löst er einen automatisierten Build- und Testprozess aus. Zur Validierung des Codes werden End-to-End-Testfälle (E2E) ausgeführt. Wenn die Tests erfolgreich sind, kann der Code automatisch für die Bereitstellung/Produktion bereitgestellt werden. Wenn Probleme gefunden werden, wird der Code zur Fehlerbehebung an die Entwicklung zurückgesendet. Diese Automatisierung bietet Entwicklern schnelles Feedback und verringert das Risiko von Fehlern in der Produktion.
Abschnitt 2 – Unterschied zwischen CI und CD
Continuous Integration (CI) automatisiert den Build-, Test- und Merge-Prozess. Es führt Tests durch, wann immer Code festgeschrieben wird, um Integrationsprobleme frühzeitig zu erkennen. Dies fördert häufige Code-Commits und schnelles Feedback.
Continuous Delivery (CD) automatisiert Release-Prozesse wie Infrastrukturänderungen und Bereitstellung. Durch automatisierte Workflows wird sichergestellt, dass Software jederzeit zuverlässig freigegeben werden kann. CD kann auch die manuellen Test- und Genehmigungsschritte automatisieren, die vor der Produktionsbereitstellung erforderlich sind.
Abschnitt 3 – CI/CD-Pipeline
Eine typische CI/CD-Pipeline besteht aus mehreren verbundenen Phasen:
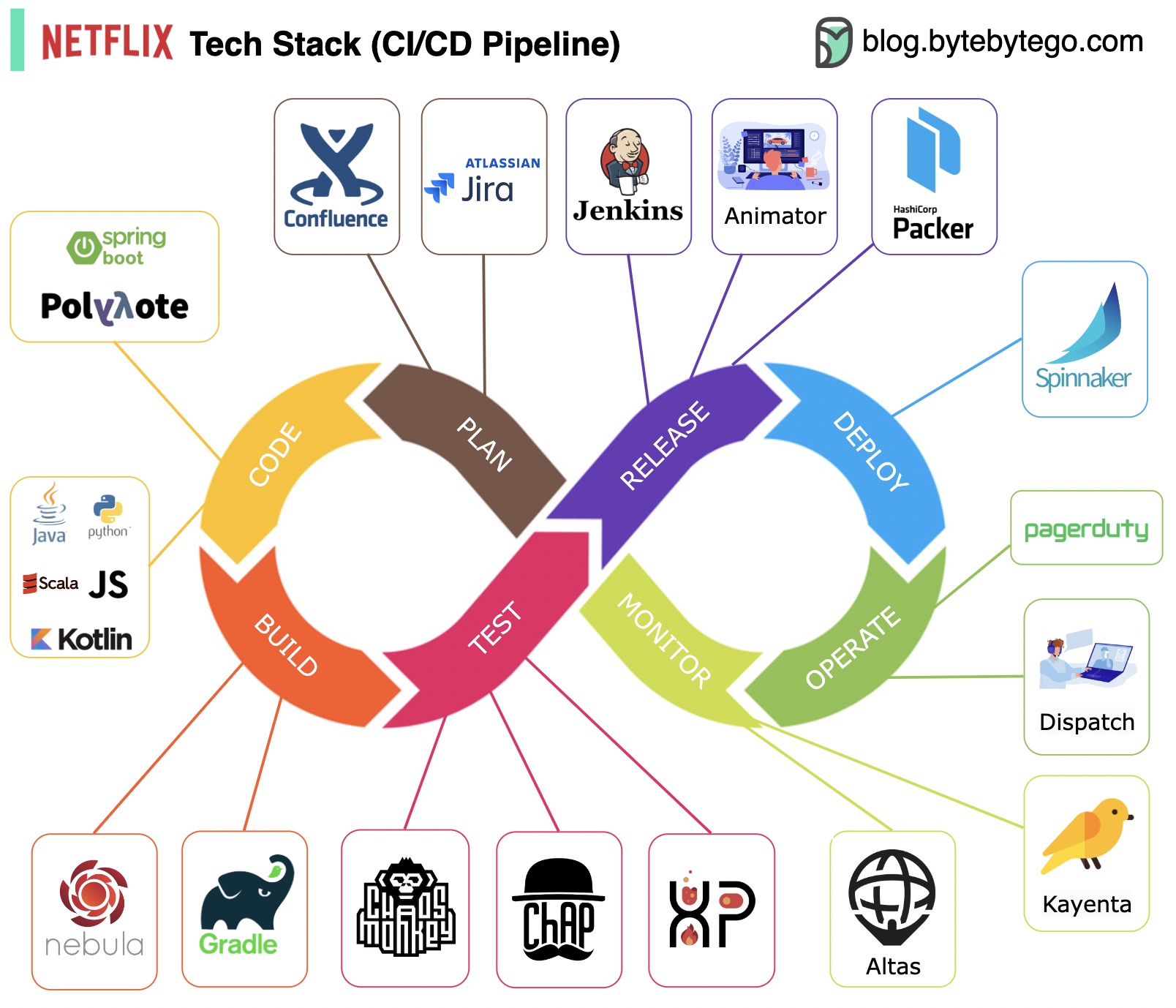
Planung: Netflix Engineering nutzt JIRA für die Planung und Confluence für die Dokumentation.
Codierung: Java ist die primäre Programmiersprache für den Backend-Dienst, während andere Sprachen für verschiedene Anwendungsfälle verwendet werden.
Erstellen: Gradle wird hauptsächlich zum Erstellen verwendet, und Gradle-Plugins sind für die Unterstützung verschiedener Anwendungsfälle konzipiert.
Verpackung: Paket und Abhängigkeiten werden zur Veröffentlichung in ein Amazon Machine Image (AMI) gepackt.
Testen: Beim Testen wird der Fokus der Produktionskultur auf die Entwicklung von Chaos-Tools betont.
Einsatz: Netflix nutzt seinen selbst entwickelten Spinnaker für den Canary-Rollout-Einsatz.
Überwachung: Die Überwachungsmetriken sind in Atlas zentralisiert und Kayenta wird zur Erkennung von Anomalien verwendet.
Vorfallbericht: Vorfälle werden nach Priorität weitergeleitet und PagerDuty wird für die Vorfallbearbeitung verwendet.
Diese Architekturmuster gehören zu den am häufigsten verwendeten in der App-Entwicklung, sei es auf iOS- oder Android-Plattformen. Entwickler haben sie eingeführt, um die Einschränkungen früherer Muster zu überwinden. Wie unterscheiden sie sich?
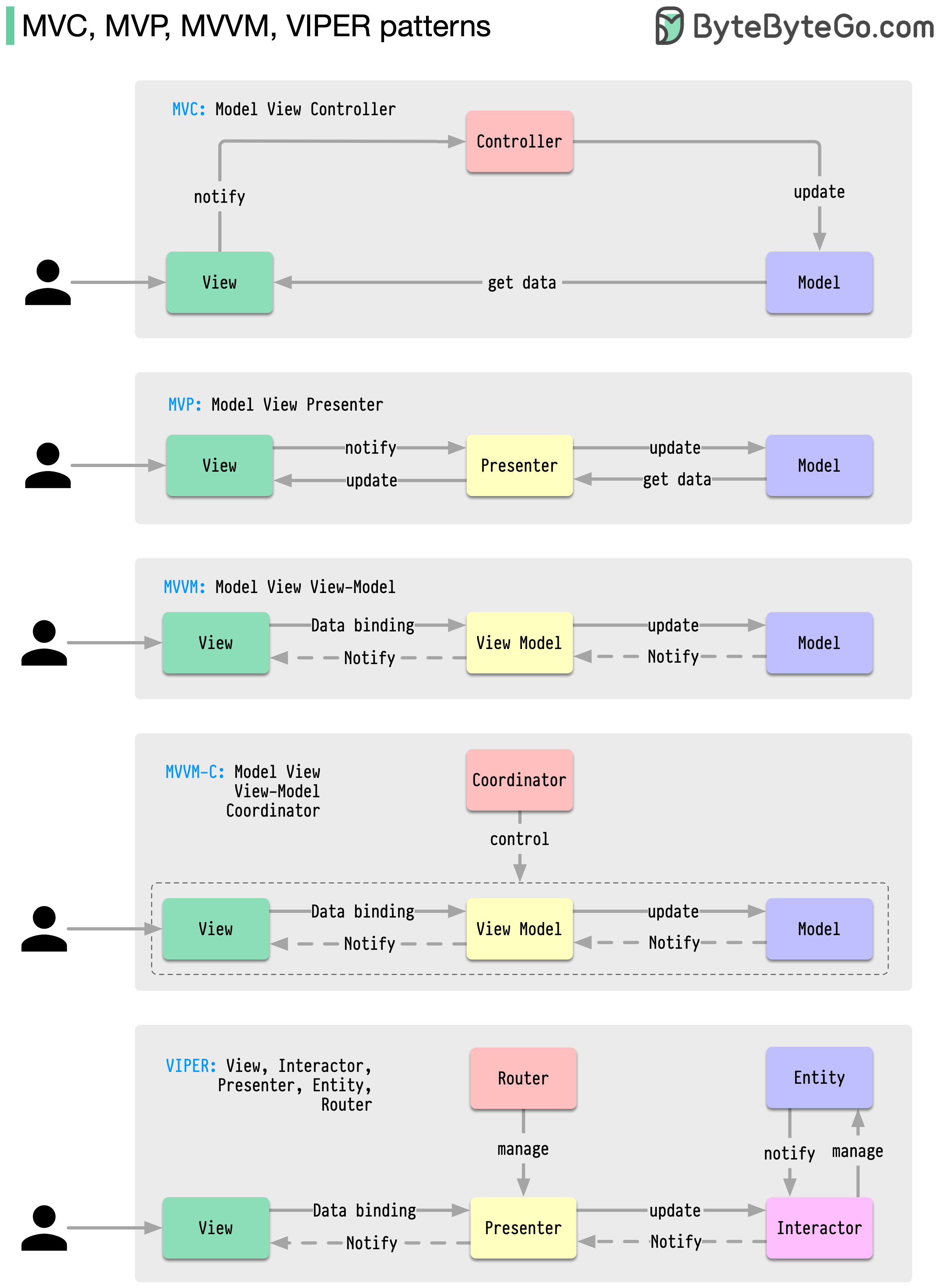
Muster sind wiederverwendbare Lösungen für häufig auftretende Designprobleme und führen zu einem reibungsloseren und effizienteren Entwicklungsprozess. Sie dienen als Blaupausen für den Aufbau besserer Softwarestrukturen. Dies sind einige der beliebtesten Muster:

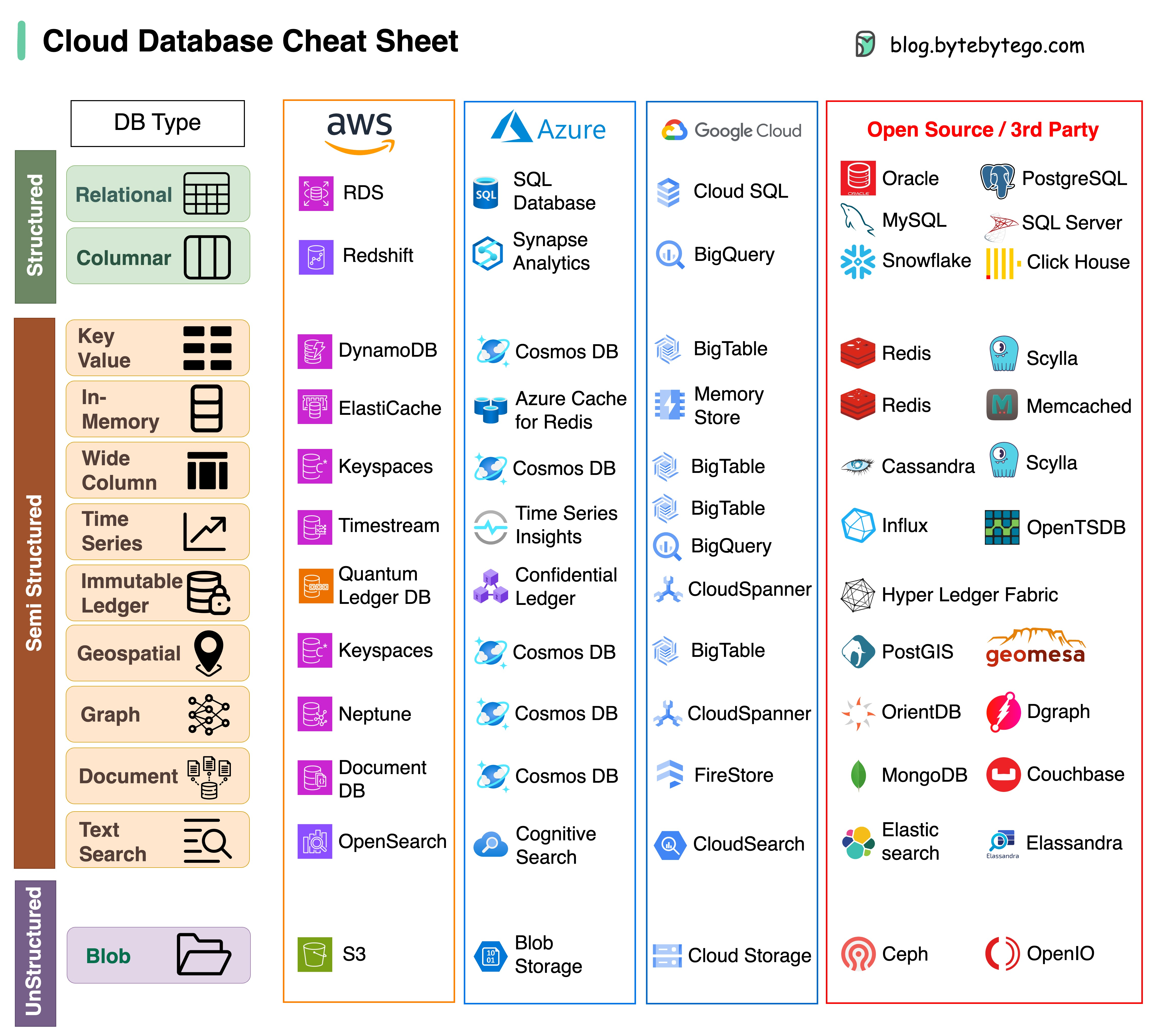
Die Auswahl der richtigen Datenbank für Ihr Projekt ist eine komplexe Aufgabe. Viele Datenbankoptionen, die jeweils für unterschiedliche Anwendungsfälle geeignet sind, können schnell zu Entscheidungsmüdigkeit führen.
Wir hoffen, dass dieser Spickzettel eine allgemeine Orientierung bietet, um den richtigen Service zu finden, der zu den Anforderungen Ihres Projekts passt, und mögliche Fallstricke zu vermeiden.
Hinweis: Google verfügt nur über begrenzte Dokumentation für seine Datenbank-Anwendungsfälle. Obwohl wir unser Bestes getan haben, um zu prüfen, was verfügbar ist, und die beste Option gefunden haben, müssen einige Einträge möglicherweise genauer sein.
Die Antwort variiert je nach Anwendungsfall. Daten können im Speicher oder auf der Festplatte indiziert werden. Ebenso variieren die Datenformate, z. B. Zahlen, Zeichenfolgen, geografische Koordinaten usw. Das System kann schreiblastig oder leselastig sein. Alle diese Faktoren wirken sich auf die Wahl des Datenbankindexformats aus.
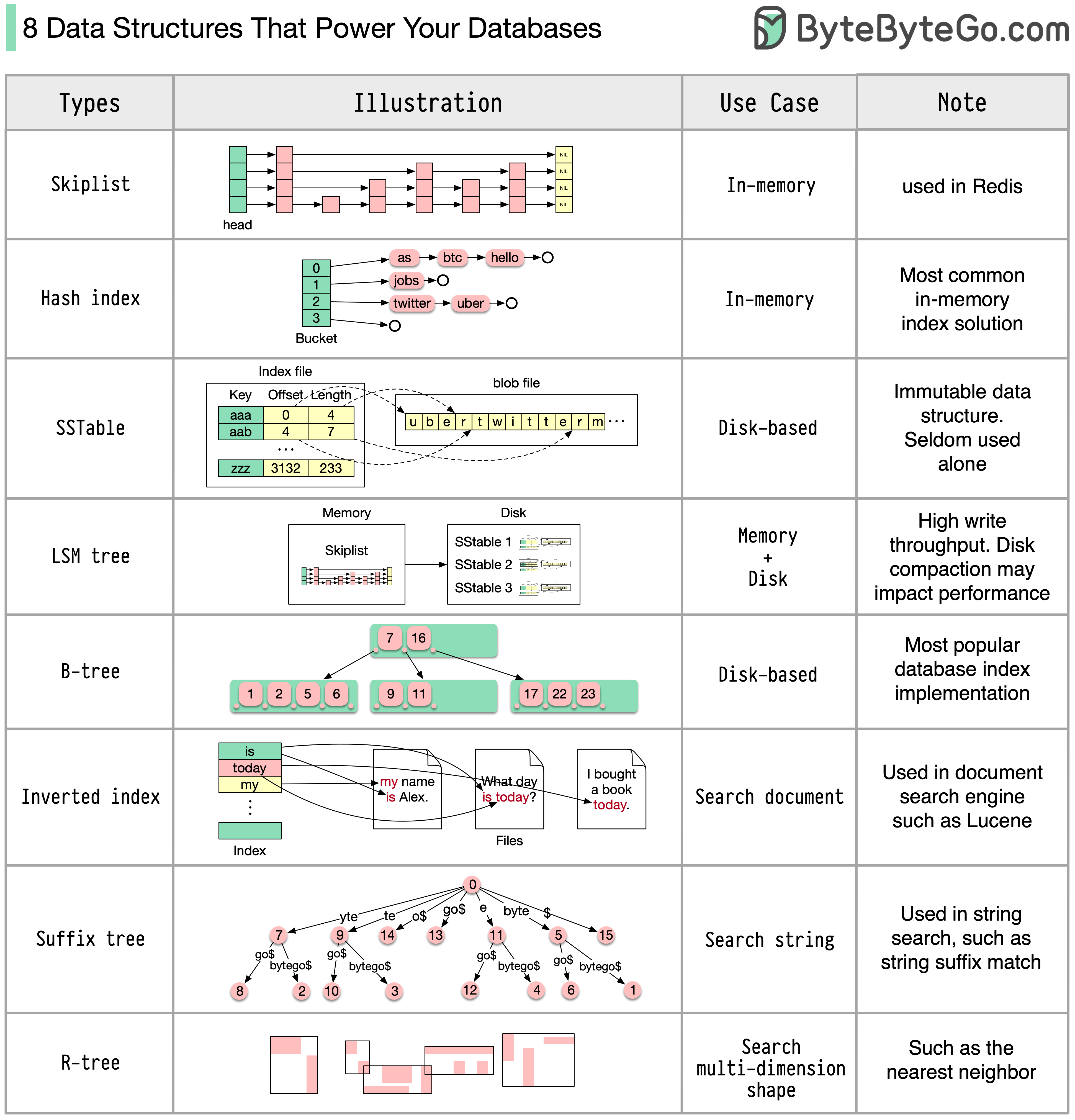
Im Folgenden sind einige der gängigsten Datenstrukturen aufgeführt, die zur Indizierung von Daten verwendet werden:
Das folgende Diagramm zeigt den Prozess. Beachten Sie, dass die Architekturen für verschiedene Datenbanken unterschiedlich sind. Das Diagramm zeigt einige gängige Designs.
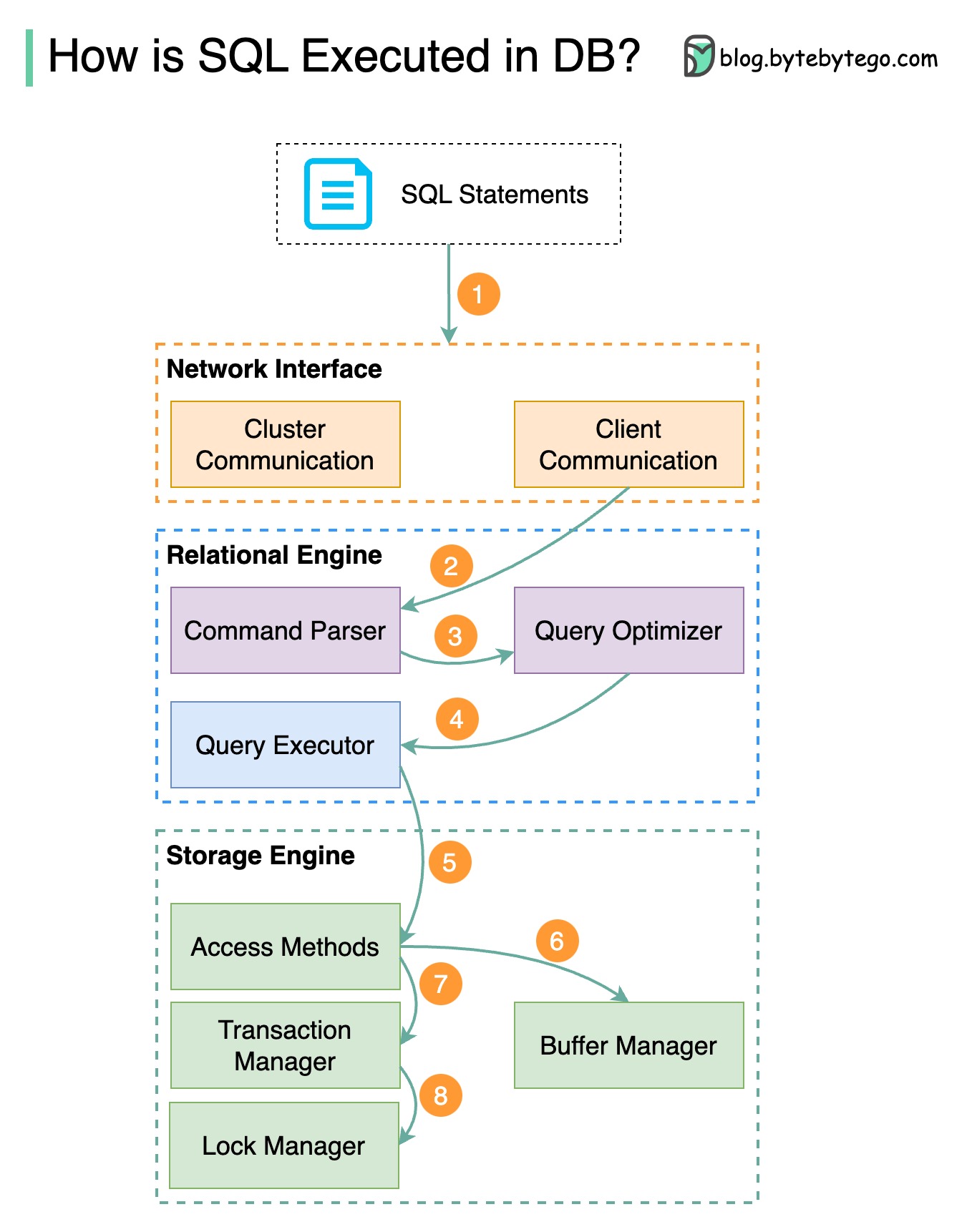
Schritt 1 – Eine SQL-Anweisung wird über ein Transportschichtprotokoll (z. B. TCP) an die Datenbank gesendet.
Schritt 2 – Die SQL-Anweisung wird an den Befehlsparser gesendet, wo sie eine syntaktische und semantische Analyse durchläuft und anschließend ein Abfragebaum generiert wird.
Schritt 3 – Der Abfragebaum wird an den Optimierer gesendet. Der Optimierer erstellt einen Ausführungsplan.
Schritt 4 – Der Ausführungsplan wird an den Testamentsvollstrecker gesendet. Der Ausführende ruft Daten aus der Ausführung ab.
Schritt 5 – Zugriffsmethoden stellen die für die Ausführung erforderliche Datenabruflogik bereit und rufen Daten aus der Speicher-Engine ab.
Schritt 6 – Zugriffsmethoden entscheiden, ob die SQL-Anweisung schreibgeschützt ist. Wenn die Abfrage schreibgeschützt ist (SELECT-Anweisung), wird sie zur weiteren Verarbeitung an den Puffermanager übergeben. Der Puffermanager sucht nach den Daten im Cache oder in den Datendateien.
Schritt 7 – Wenn es sich bei der Anweisung um ein UPDATE oder INSERT handelt, wird sie zur weiteren Verarbeitung an den Transaktionsmanager übergeben.
Schritt 8 – Während einer Transaktion befinden sich die Daten im Sperrmodus. Dies wird durch den Lockmanager gewährleistet. Es stellt außerdem die ACID-Eigenschaften der Transaktion sicher.
Das CAP-Theorem ist einer der bekanntesten Begriffe in der Informatik, aber ich wette, dass verschiedene Entwickler unterschiedliche Verständnisse haben. Sehen wir uns an, was es ist und warum es verwirrend sein kann.
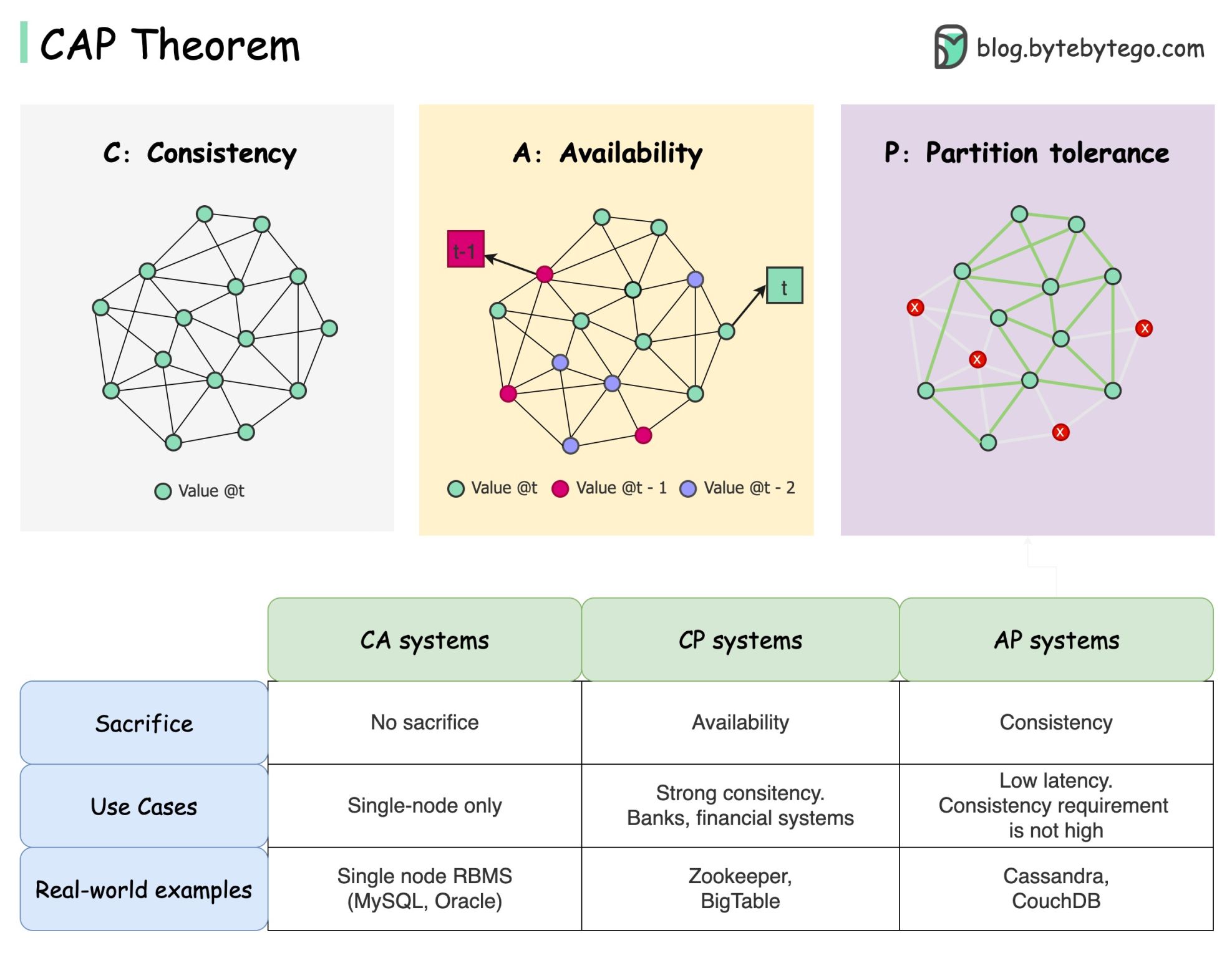
Das CAP-Theorem besagt, dass ein verteiltes System nicht mehr als zwei dieser drei Garantien gleichzeitig bieten kann.
Konsistenz : Konsistenz bedeutet, dass alle Clients zur gleichen Zeit dieselben Daten sehen, unabhängig davon, mit welchem Knoten sie sich verbinden.
Verfügbarkeit : Verfügbarkeit bedeutet, dass jeder Client, der Daten anfordert, eine Antwort erhält, auch wenn einige der Knoten ausgefallen sind.
Partitionstoleranz : Eine Partition weist auf eine Kommunikationsunterbrechung zwischen zwei Knoten hin. Partitionstoleranz bedeutet, dass das System trotz Netzwerkpartitionen weiterarbeitet.
Die „2 von 3“-Formulierung kann nützlich sein, diese Vereinfachung könnte jedoch irreführend sein .
Die Auswahl einer Datenbank ist nicht einfach. Es reicht nicht aus, unsere Wahl allein auf der Grundlage des CAP-Theorems zu rechtfertigen. Beispielsweise entscheiden sich Unternehmen nicht nur deshalb für Cassandra für Chat-Anwendungen, weil es sich um ein AP-System handelt. Es gibt eine Liste guter Eigenschaften, die Cassandra zu einer wünschenswerten Option zum Speichern von Chat-Nachrichten machen. Wir müssen tiefer graben.
„CAP verbietet nur einen winzigen Teil des Designraums: perfekte Verfügbarkeit und Konsistenz bei Vorhandensein von Partitionen, die selten sind.“ Zitiert aus dem Artikel: CAP Twelve Years Later: How the „Rules“ Have Changed.
Das Theorem besagt etwa 100 % Verfügbarkeit und Konsistenz. Eine realistischere Diskussion wäre der Kompromiss zwischen Latenz und Konsistenz, wenn keine Netzwerkpartition vorhanden ist. Weitere Einzelheiten finden Sie im PACELC-Theorem.
Ist das CAP-Theorem tatsächlich nützlich?
Ich denke, es ist immer noch nützlich, da es uns für eine Reihe von Kompromissdiskussionen öffnet, aber es ist nur ein Teil der Geschichte. Bei der Auswahl der richtigen Datenbank müssen wir tiefer graben.
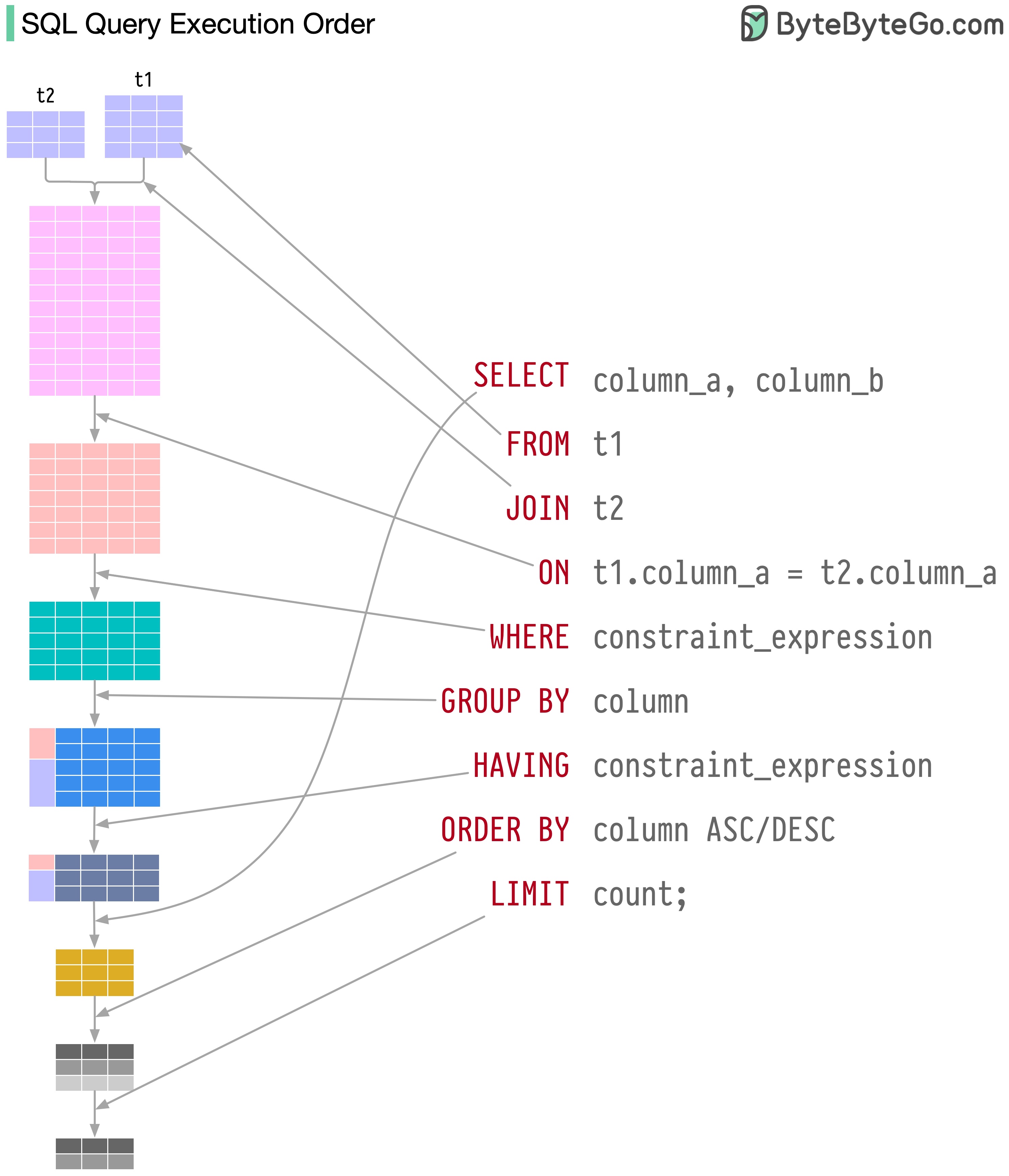
SQL-Anweisungen werden vom Datenbanksystem in mehreren Schritten ausgeführt, darunter:
Die Ausführung von SQL ist sehr komplex und erfordert viele Überlegungen, wie zum Beispiel:
Im Jahr 1986 wurde SQL (Structured Query Language) zum Standard. In den nächsten 40 Jahren entwickelte es sich zur dominierenden Sprache für relationale Datenbankverwaltungssysteme. Das Lesen des neuesten Standards (ANSI SQL 2016) kann zeitaufwändig sein. Wie kann ich es lernen?
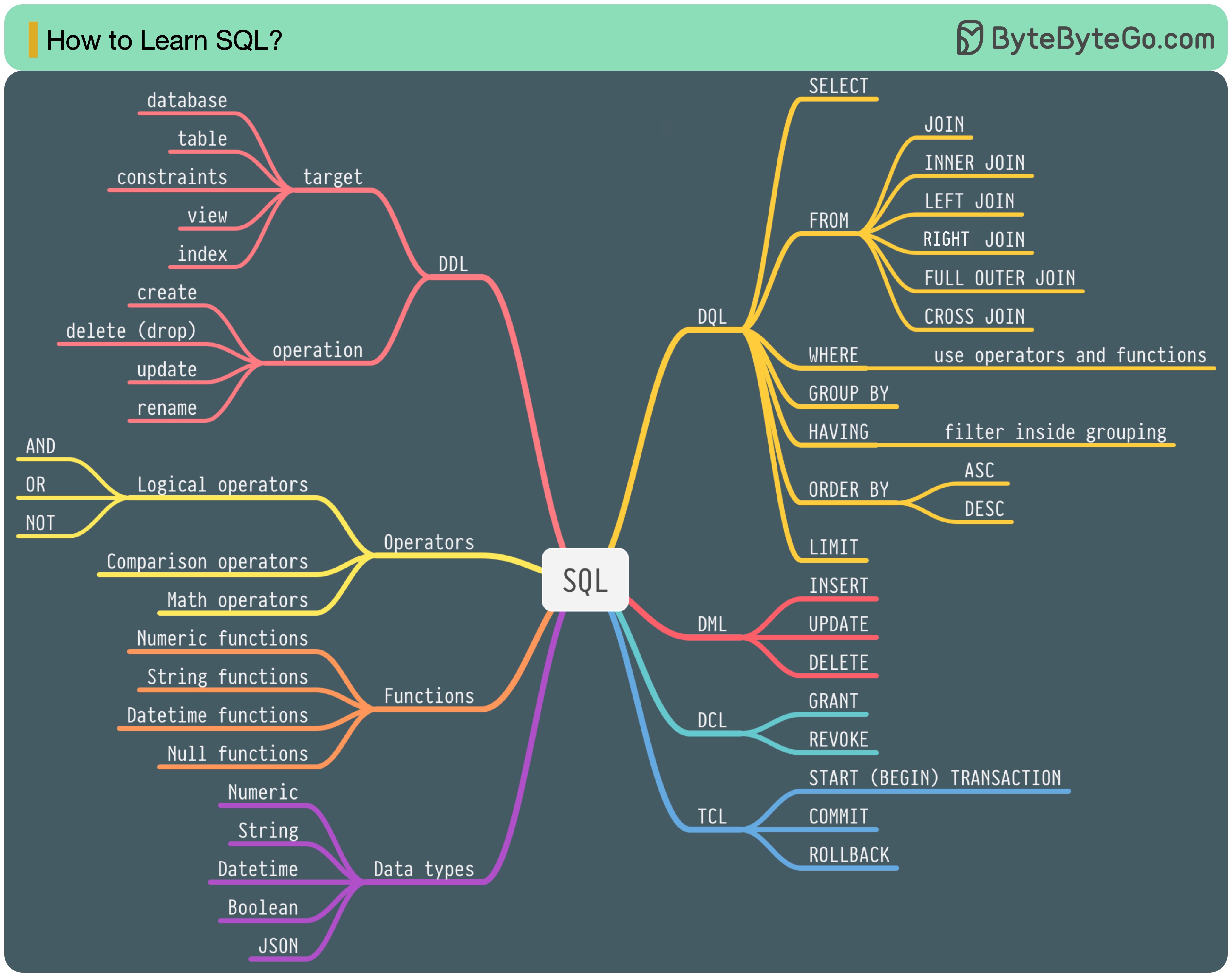
Es gibt 5 Komponenten der SQL-Sprache:
Als Backend-Ingenieur müssen Sie möglicherweise das meiste davon wissen. Als Datenanalyst müssen Sie möglicherweise über gute Kenntnisse von DQL verfügen. Wählen Sie die Themen aus, die für Sie am relevantesten sind.
Dieses Diagramm veranschaulicht, wo wir Daten in einer typischen Architektur zwischenspeichern.
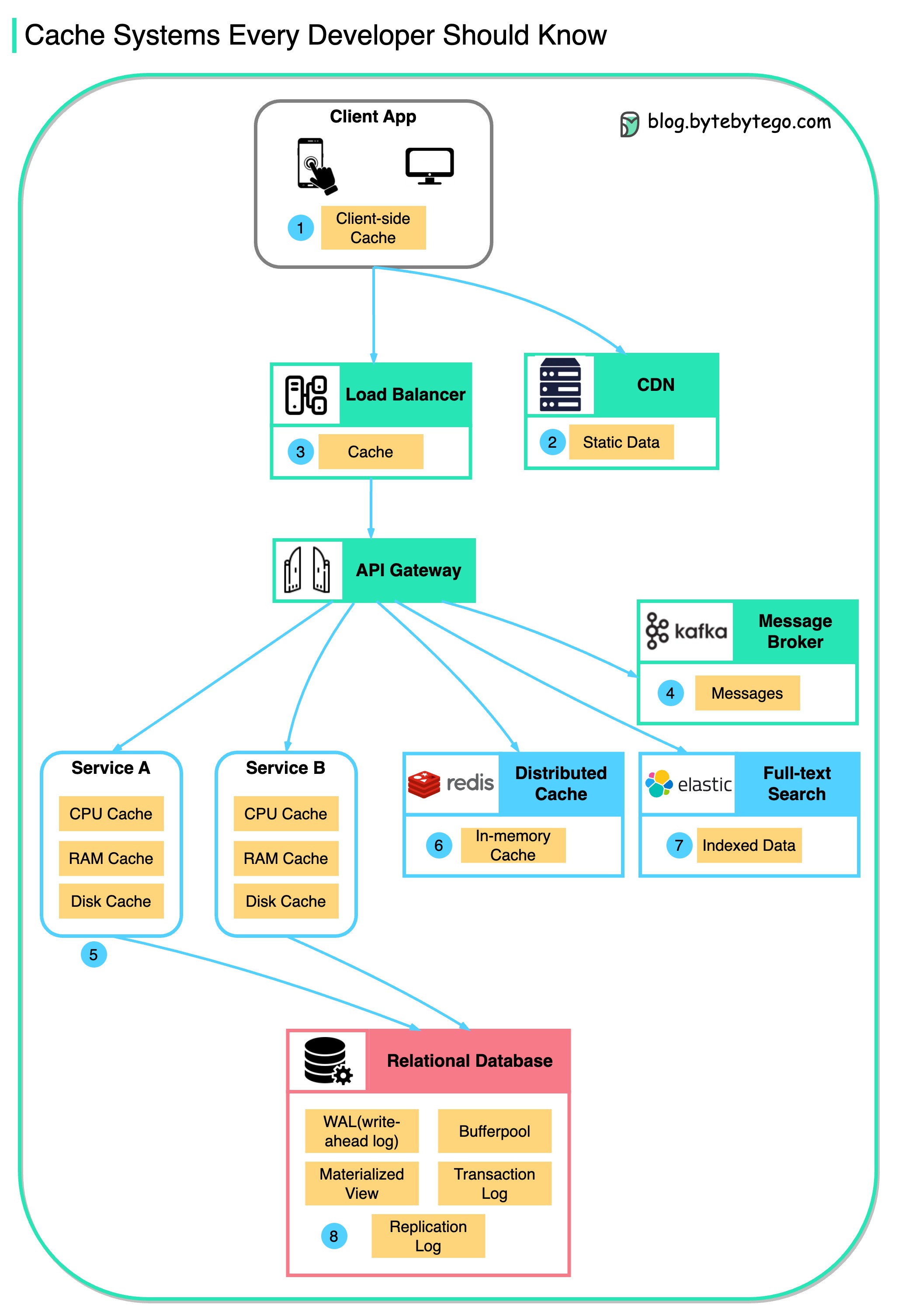
Entlang der Strömung gibt es mehrere Schichten .
Es gibt drei Hauptgründe, wie im Diagramm unten dargestellt.
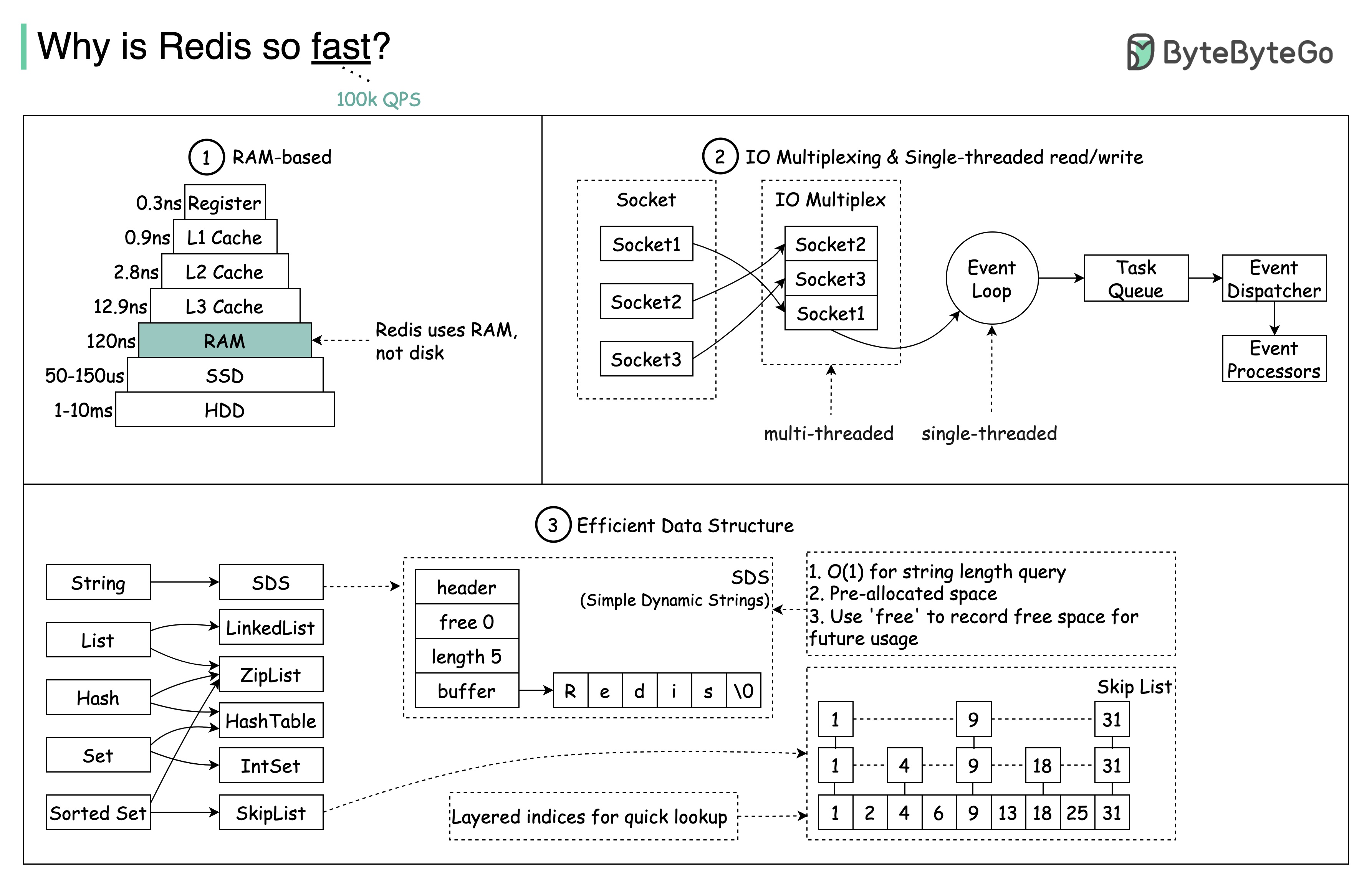
Frage: Ein weiterer beliebter In-Memory-Speicher ist Memcached. Kennen Sie die Unterschiede zwischen Redis und Memcached?
Vielleicht haben Sie bemerkt, dass sich der Stil dieses Diagramms von meinen vorherigen Beiträgen unterscheidet. Bitte lassen Sie mich wissen, welches Sie bevorzugen.
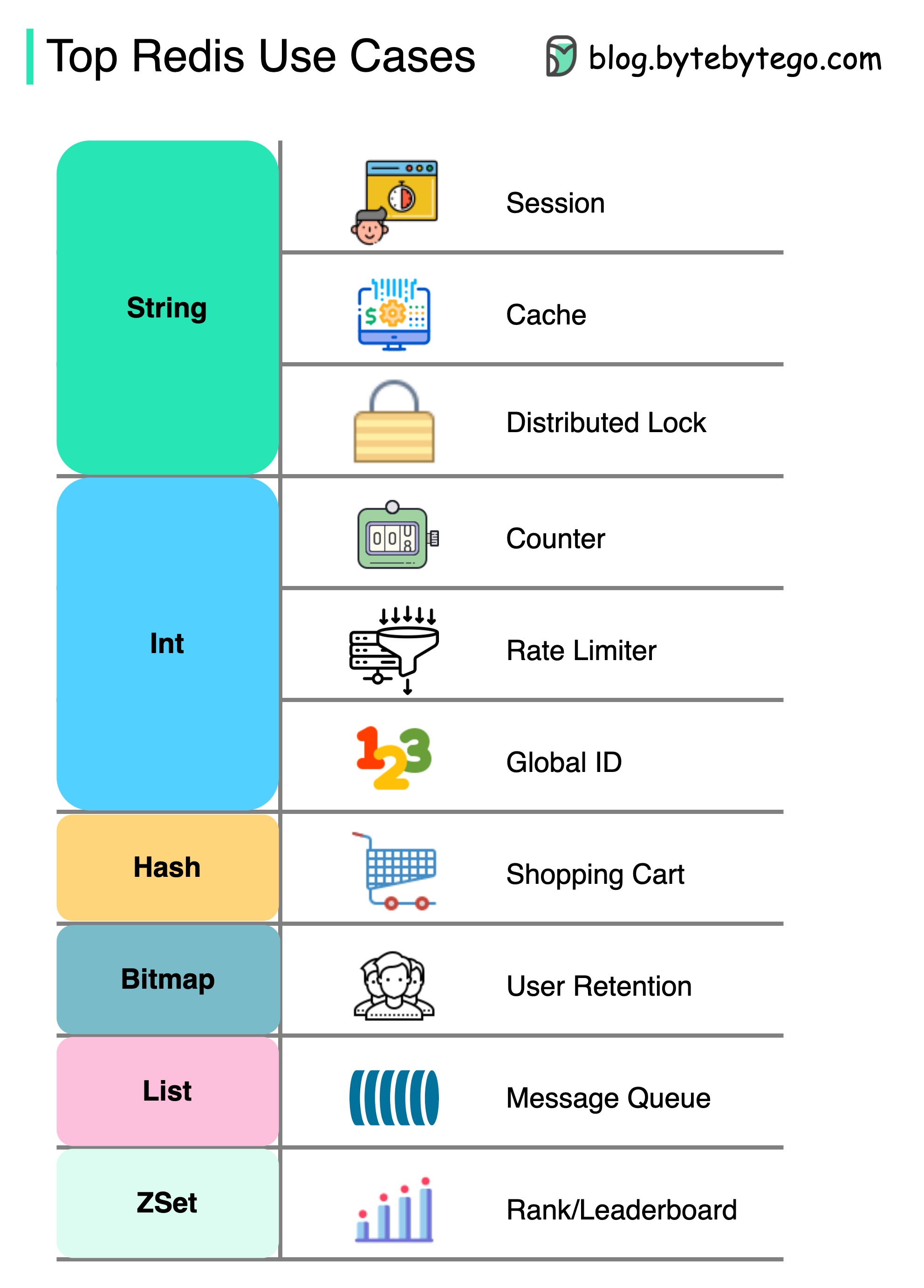
Redis gibt mehr als nur das Zwischenspeichern.
Redis kann in einer Vielzahl von Szenarien verwendet werden, wie im Diagramm gezeigt.
Sitzung
Wir können Redis verwenden, um Benutzersitzungsdaten in verschiedenen Diensten zu teilen.
Cache
Wir können Redis verwenden, um Objekte oder Seiten, insbesondere für Hotspot -Daten, zu zwischenstrahlen.
Verteilte Sperre
Wir können eine Redis -Zeichenfolge verwenden, um Schlösser zwischen verteilten Diensten zu erwerben.
Schalter
Wir können zählen, wie viele Likes oder wie viele Lesevorgänge für Artikel.
Ratenbegrenzer
Wir können einen Ratenbegrenzer für bestimmte Benutzer -IPs anwenden.
Globaler ID -Generator
Wir können Redis int für globale ID verwenden.
Warenkorb
Wir können Redis Hash verwenden, um Schlüsselwertpaare in einem Einkaufswagen darzustellen.
Berechnen Sie die Benutzerbindung
Wir können Bitmap verwenden, um die Benutzeranmeldung täglich darzustellen und die Benutzerbindung zu berechnen.
Meldungswarteschlange
Wir können die Liste für eine Nachrichtenwarteschlange verwenden.
Rang
Wir können Zset verwenden, um die Artikel zu sortieren.
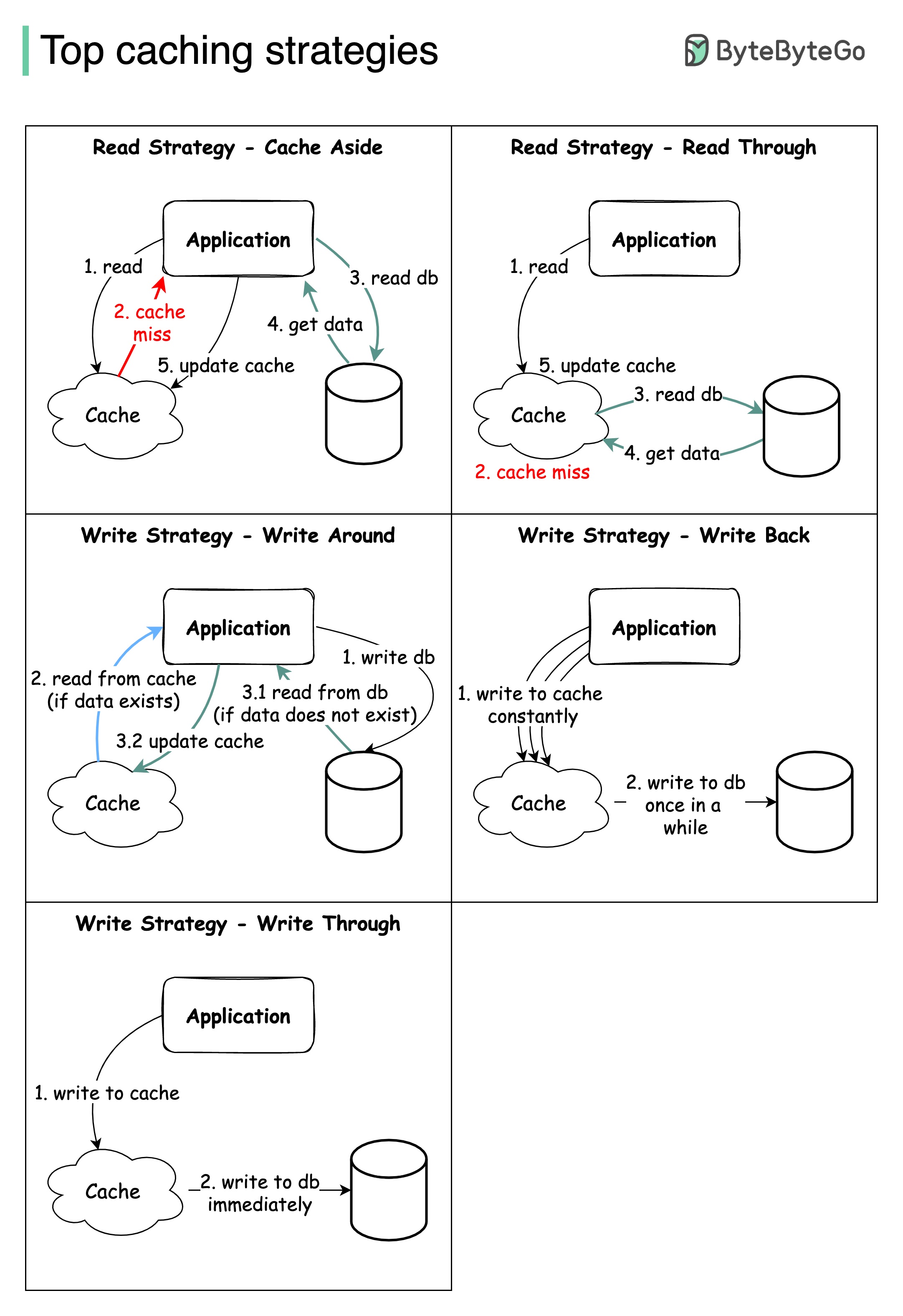
Das Entwerfen großer Systeme erfordert normalerweise eine sorgfältige Berücksichtigung des Zwischenspeichers. Im Folgenden finden Sie fünf Caching -Strategien, die häufig verwendet werden.
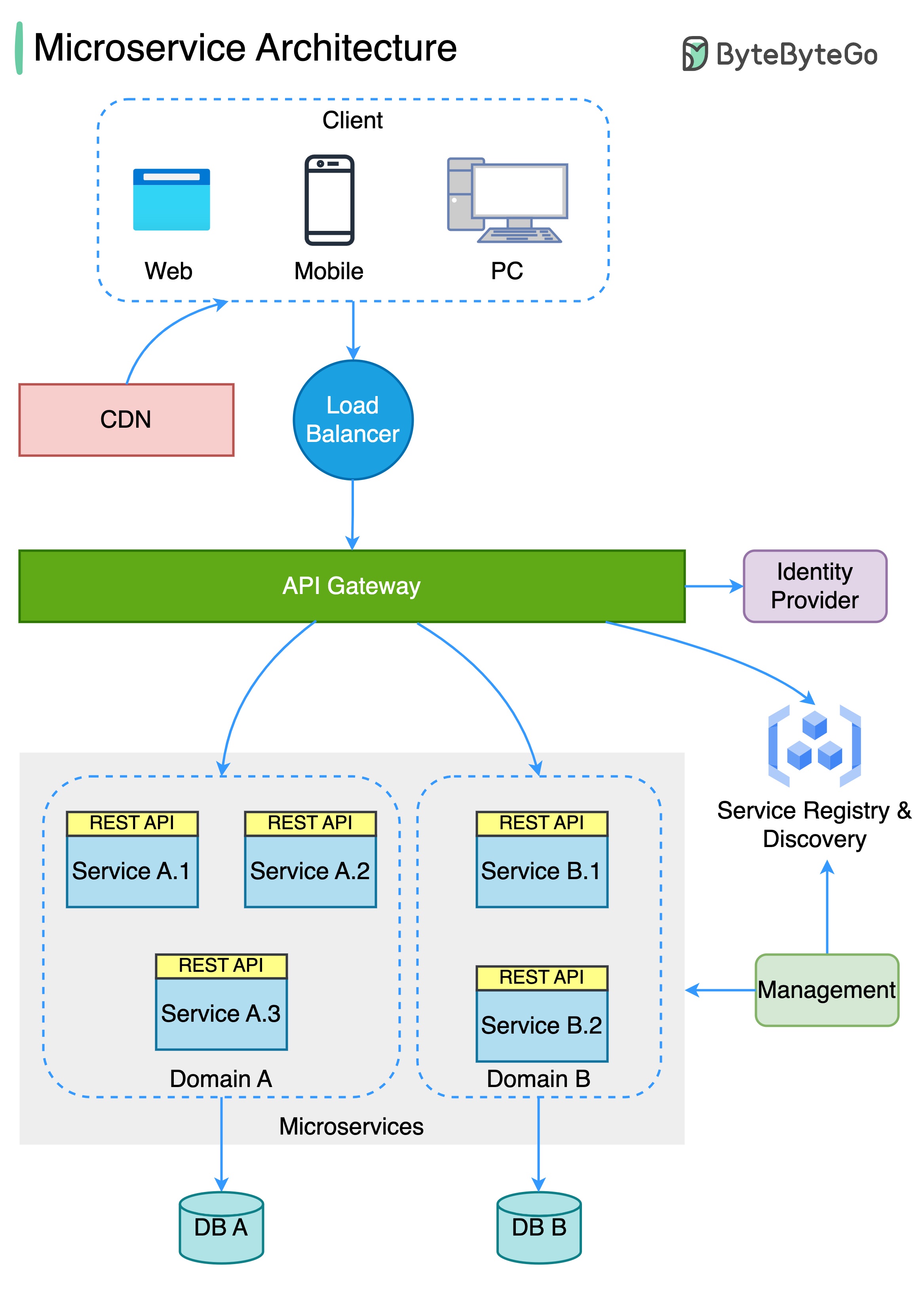
Das folgende Diagramm zeigt eine typische Microservice -Architektur.
Vorteile von Microservices:
Ein Bild ist mehr als tausend Worte: 9 Best Practices für die Entwicklung von Mikrodiensten.
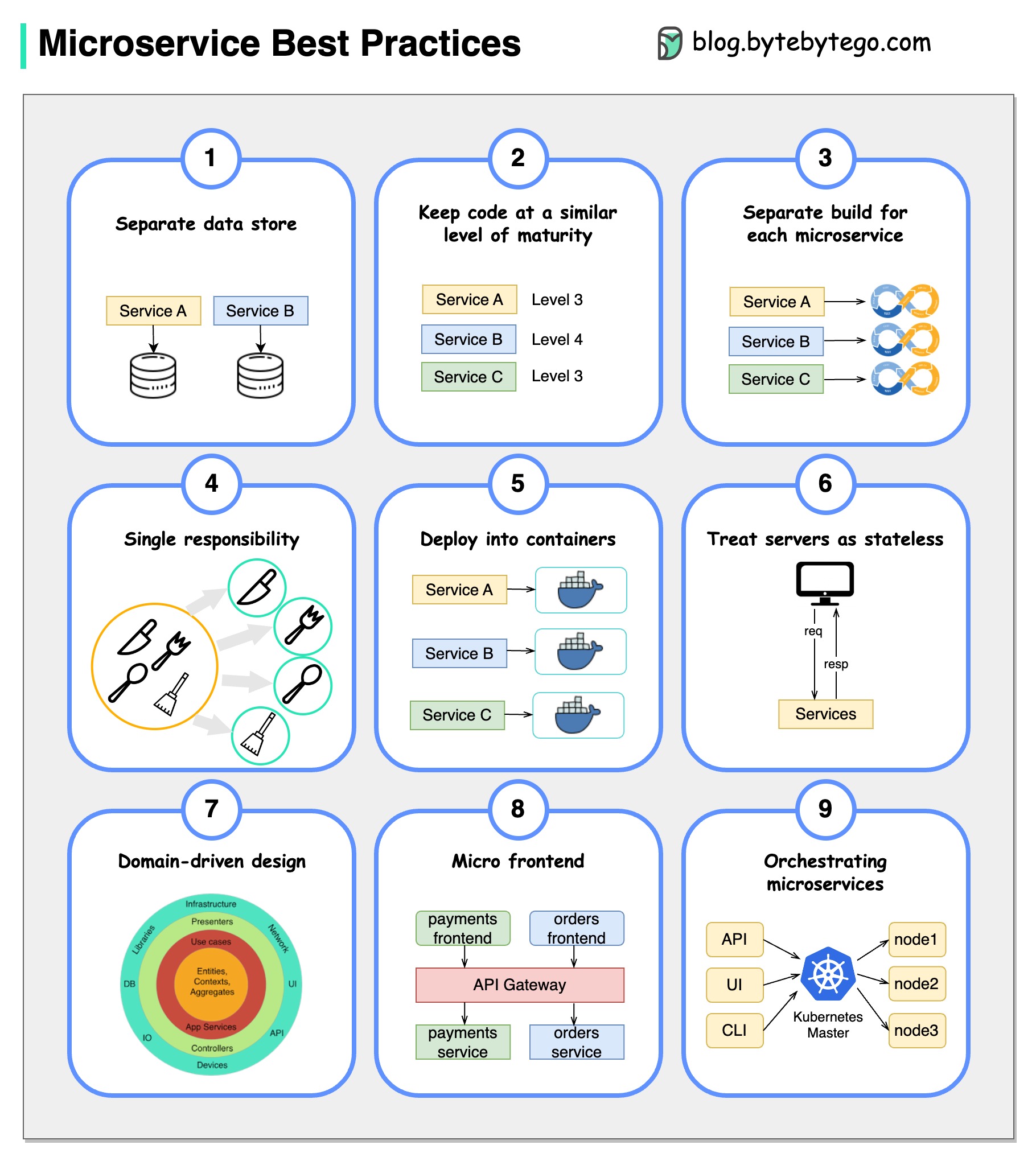
Wenn wir Microservices entwickeln, müssen wir den folgenden Best Practices folgen:
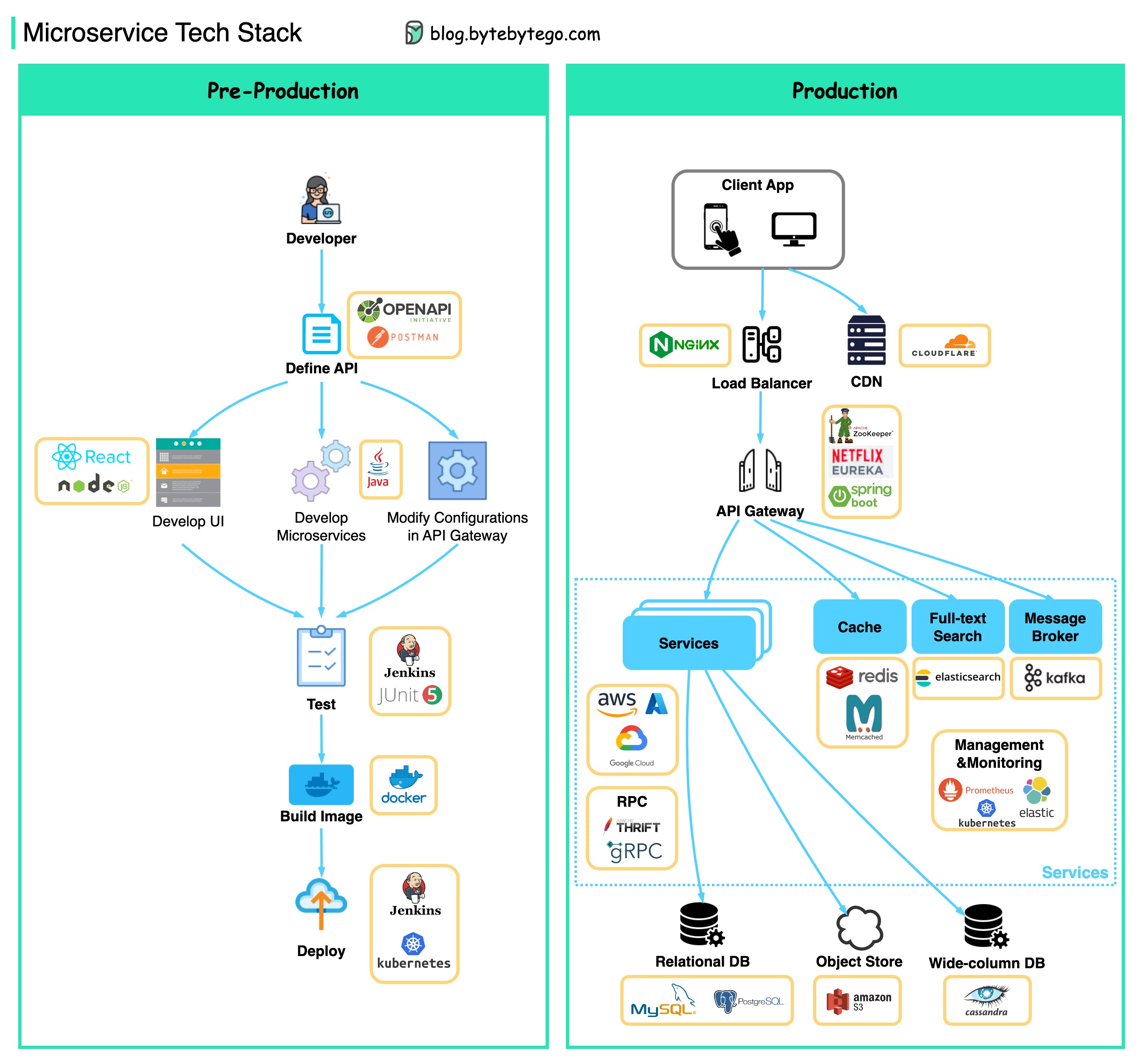
Im Folgenden finden Sie ein Diagramm, das den Microservice Tech -Stack sowohl für die Entwicklungsphase als auch für die Produktion zeigt.
Es gibt viele Designentscheidungen, die zur Leistung von Kafka beigetragen haben. In diesem Beitrag werden wir uns auf zwei konzentrieren. Wir glauben, dass diese beiden das meiste Gewicht trugen.
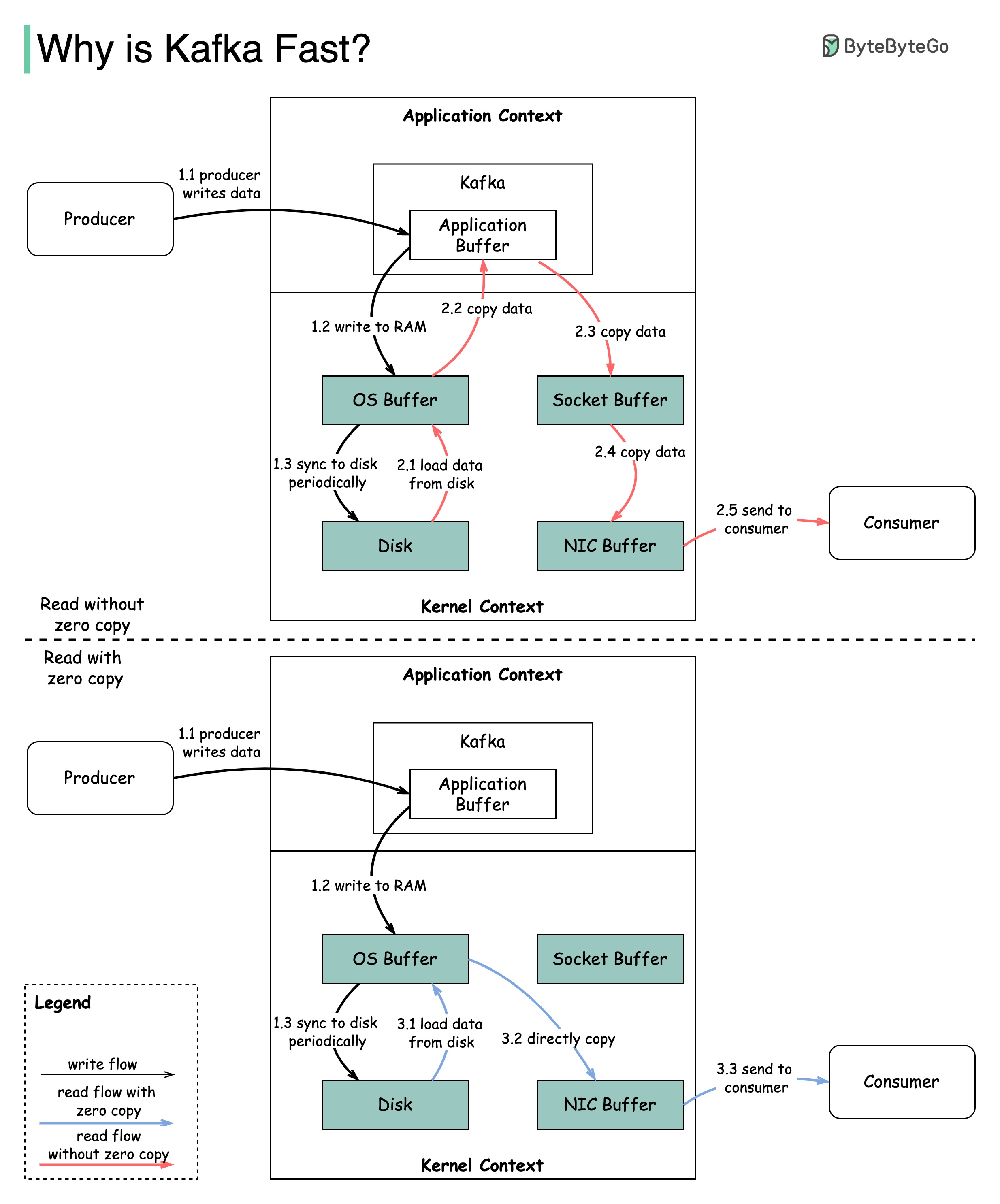
Das Diagramm zeigt, wie die Daten zwischen Produzent und Verbraucher übertragen werden und was keine Kopie bedeutet.
2.1 Die Daten werden von der Festplatte zu OS -Cache geladen
2.2 Die Daten werden vom Betriebssystem -Cache zur Kafka -Anwendung kopiert
2.3 Kafka -Anwendung kopiert die Daten in den Socket -Puffer
2.4 Die Daten werden vom Socket -Puffer zu Netzwerkkarte kopiert
2.5 Die Netzwerkkarte sendet Daten an den Verbraucher
3.1: Die Daten werden von der Festplatte zu Betriebssystem -Cache 3.2 OS -Cache geladen, die die Daten direkt über SendFile () Befehl 3.3 Die Netzwerkkarte sendet Daten an den Verbraucher aus
Zero Copy ist eine Verknüpfung, um die mehreren Datenkopien zwischen Anwendungskontext und Kernelkontext zu speichern.
Das folgende Diagramm zeigt die Ökonomie des Kreditkartenzahlungsflusss.
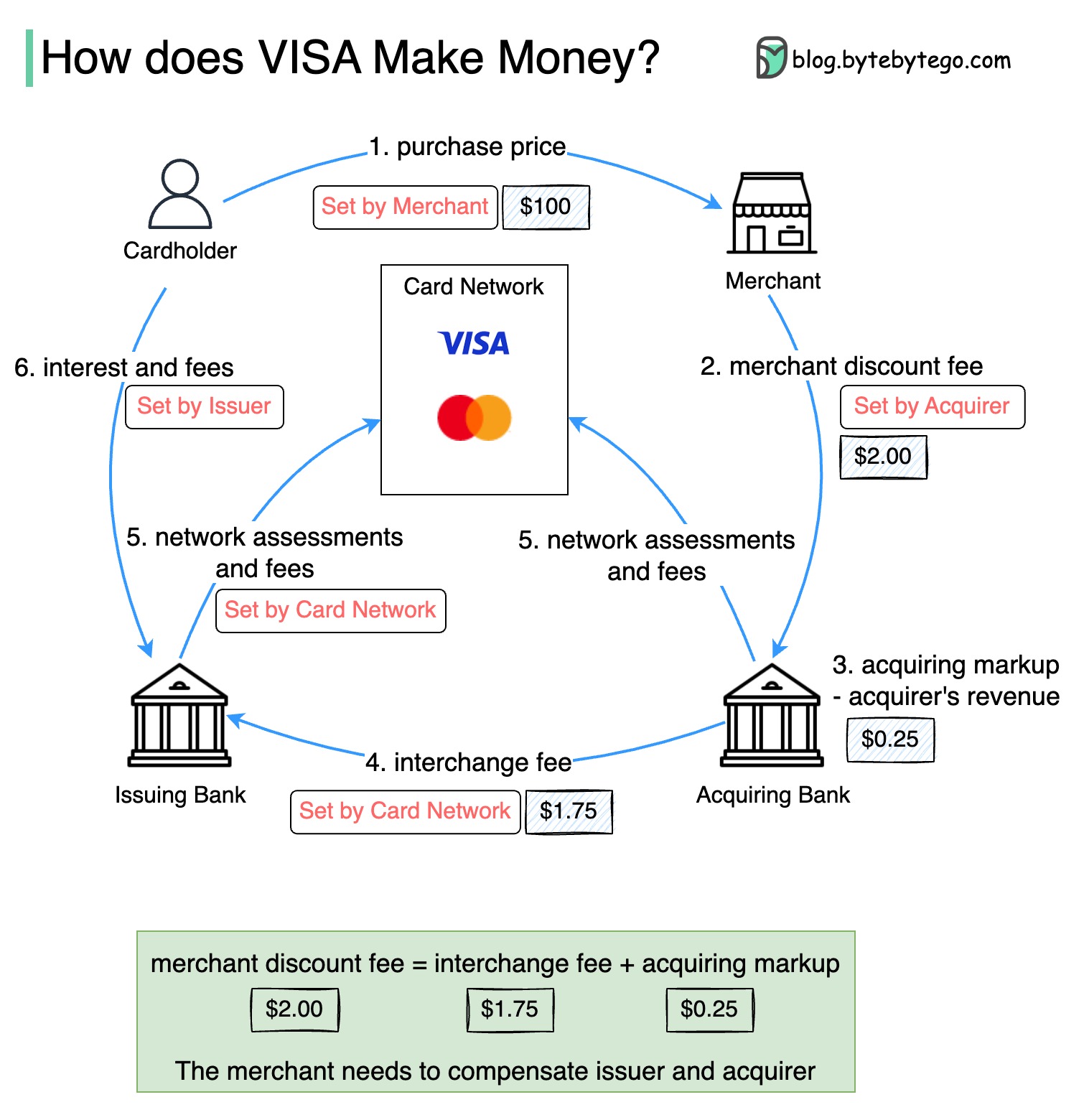
1. Der Karteninhaber zahlt einem Händler $ 100, um ein Produkt zu kaufen.
2. Der Händler profitiert von der Verwendung der Kreditkarte mit höherem Verkaufsvolumen und muss den Emittenten und das Kartennetz für die Bereitstellung des Zahlungsdienstes kompensieren. Die erwerbende Bank legt eine Gebühr für den Händler fest, die als "Händler -Rabattgebühr" bezeichnet wird.
3 - 4. Die Akzeptanz der Akzeptanz hält 0,25 USD als Erwerbsmarkup, und 1,75 USD werden an die ausstellende Bank als Austauschgebühr gezahlt. Die Händler -Rabattgebühr sollte die Austauschgebühr abdecken.
Die Austauschgebühr wird vom Kartennetz festgelegt, da es für jede ausstellende Bank weniger effizient ist, mit jedem Händler Gebühren auszuhandeln.
5. Das Kartennetz legt die Netzwerkbewertungen und -gebühren mit jeder Bank ein, die das Kartennetz für seine Dienste jeden Monat bezahlt. Zum Beispiel berechnet Visa eine Bewertung von 0,11% zuzüglich einer Nutzungsgebühr von 0,0195 USD für jeden Schlag.
6. Der Karteninhaber bezahlt die ausstellende Bank für ihre Dienstleistungen.
Warum sollte die ausstellende Bank entschädigt werden?
Visa, MasterCard und American Express dienen als Kartennetzwerke für das Löschen und Absetzen von Geldern. Die Kartenerwerbbank und die Karte zur Kartenausstellung können und sind oft anders. Wenn Banken Transaktionen einzeln ohne einen Vermittler regeln würden, müsste jede Bank die Transaktionen mit allen anderen Banken regeln. Das ist ziemlich ineffizient.
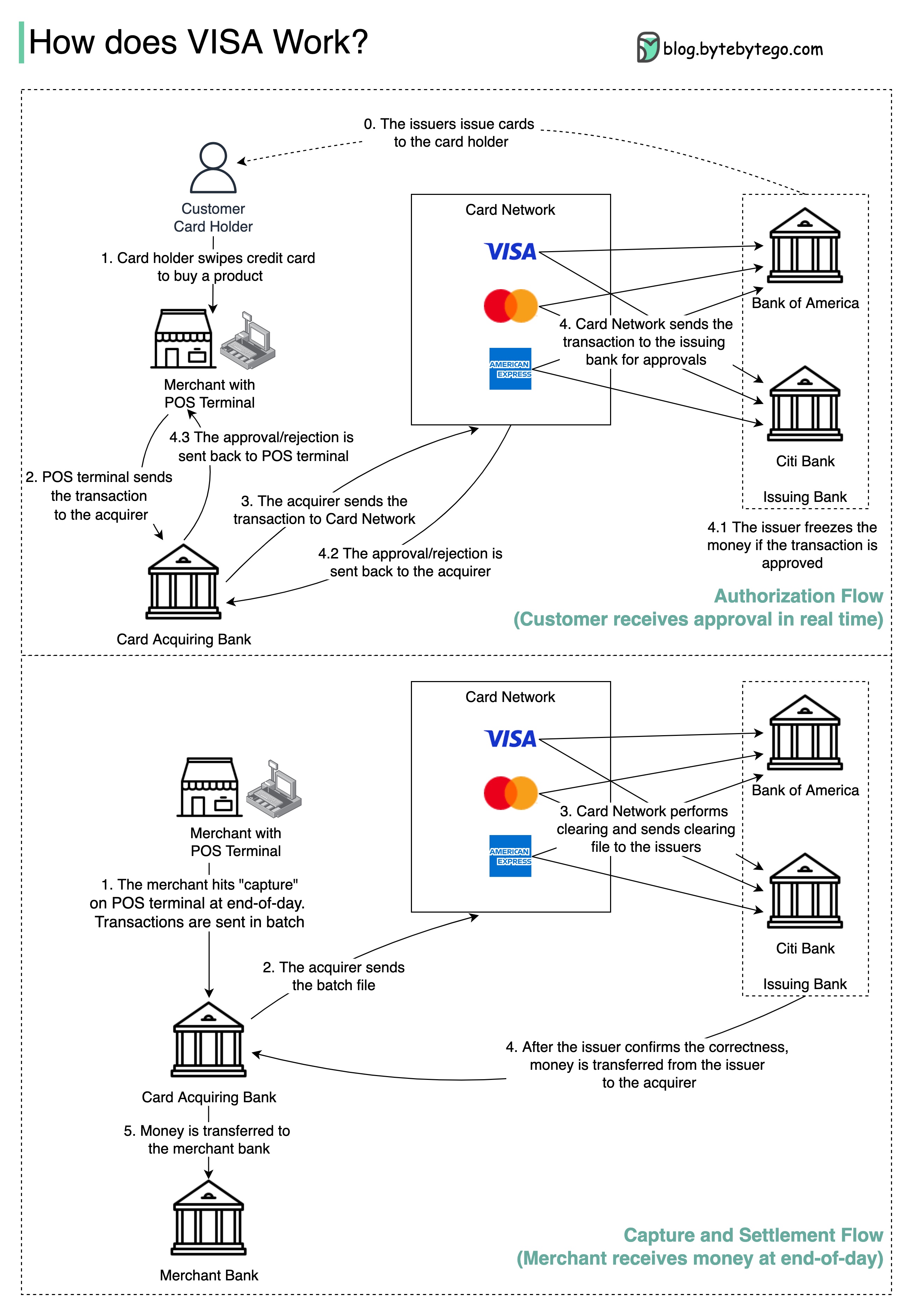
Das folgende Diagramm zeigt die Rolle von Visa im Kreditkartenzahlungsprozess. Es sind zwei Ströme beteiligt. Der Autorisierungsfluss erfolgt, wenn der Kunde die Kreditkarte wischt. Capture und Siedlungsfluss geschieht, wenn der Händler am Ende des Tages das Geld bekommen will.
Schritt 0: Die Kartenausstellung von Bankguthaben geben ihren Kunden Kreditkarten aus.
Schritt 1: Der Karteninhaber möchte ein Produkt kaufen und die Kreditkarte am POS -Terminal (POS) im Handel des Händlers wischen.
Schritt 2: Das POS -Terminal sendet die Transaktion an die Erwerbsbank, die das POS -Terminal bereitgestellt hat.
Schritte 3 und 4: Die erwerbende Bank sendet die Transaktion an das Kartennetz, das auch als Kartenschema bezeichnet wird. Das Kartennetz sendet die Transaktion zur Genehmigung an die ausstellende Bank.
Schritte 4.1, 4.2 und 4.3: Die ausstellende Bank friert das Geld ein, wenn die Transaktion genehmigt wird. Die Genehmigung oder Ablehnung wird sowohl an den Erwerber als auch an das POS -Terminal zurückgeschickt.
Schritte 1 und 2: Der Händler möchte am Ende des Tages das Geld sammeln, damit er auf dem POS -Terminal "Capture" getroffen hat. Die Transaktionen werden in Batch an den Erwerber gesendet. Der Erwerber sendet die Stapeldatei mit Transaktionen an das Kartennetz.
Schritt 3: Das Kartennetz führt Löschen für die von verschiedenen Erwerber gesammelten Transaktionen durch und sendet die Lösungsdateien an verschiedene ausstellende Banken.
Schritt 4: Die ausstellenden Banken bestätigen die Richtigkeit der Clearing -Dateien und übertragen Geld an die zuständigen Erwerbsbanken.
Schritt 5: Die Akku -Bank überträgt dann Geld an die Bank des Händlers.
Schritt 4: Das Kartennetz wird die Transaktionen aus verschiedenen Erwerbsbanken freigegeben. Clearing ist ein Prozess, bei dem gegenseitige Offset -Transaktionen einnettiert werden, sodass die Anzahl der Gesamttransaktionen verringert wird.
Dabei übernimmt das Kartennetz die Belastung, mit jeder Bank zu sprechen, und erhält als Gegenleistung Servicegebühren.
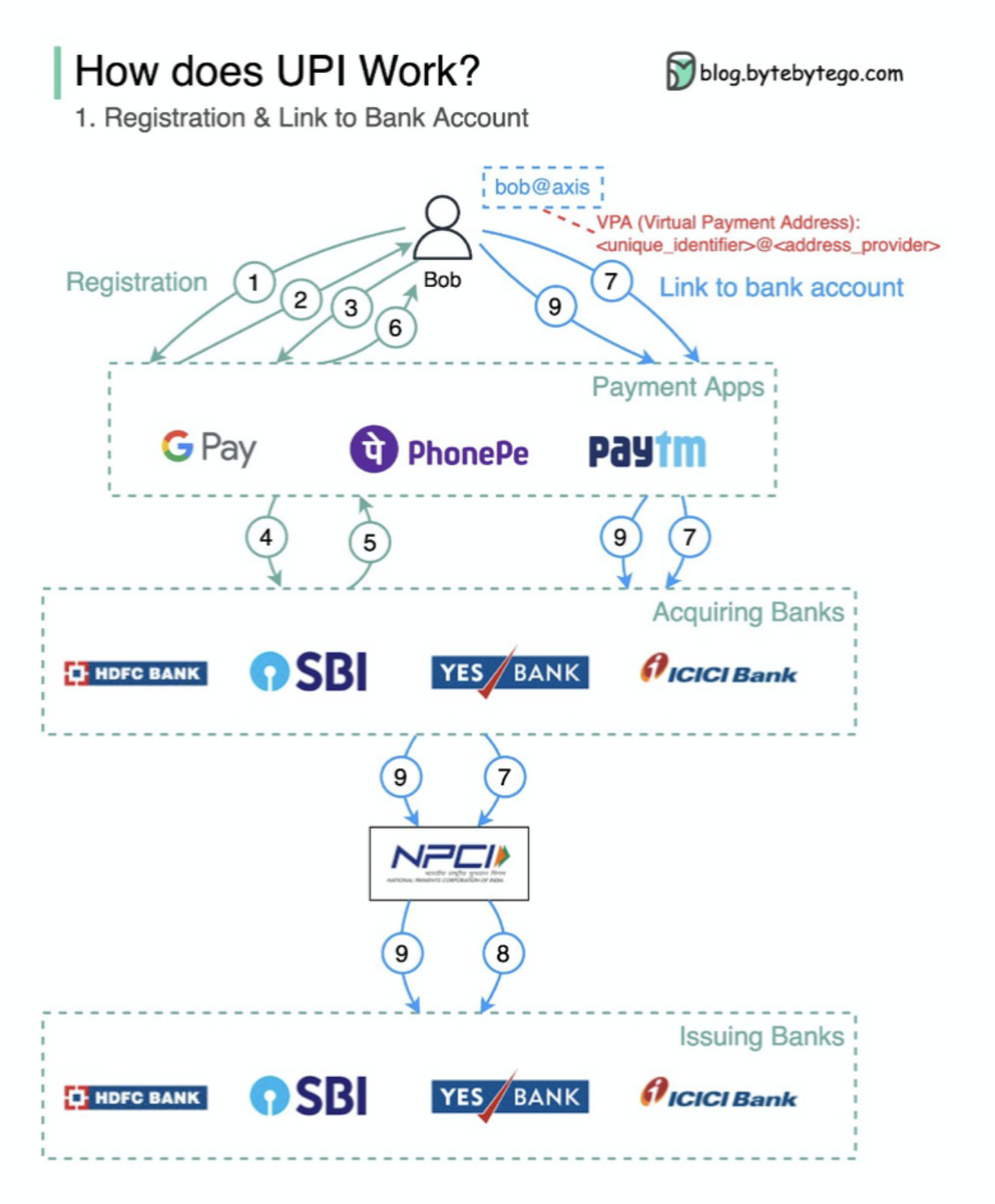
Was ist UPI? UPI ist ein sofortiges Echtzeit-Zahlungssystem, das von der National Payments Corporation of India entwickelt wurde.
Es macht heute 60% der digitalen Einzelhandelstransaktionen in Indien aus.
UPI = Zahlungsmarkup -Sprache + Standard für interoperable Zahlungen
Die Konzepte von DevOps, SRE und Plattform Engineering sind zu unterschiedlichen Zeiten entstanden und wurden von verschiedenen Personen und Organisationen entwickelt.
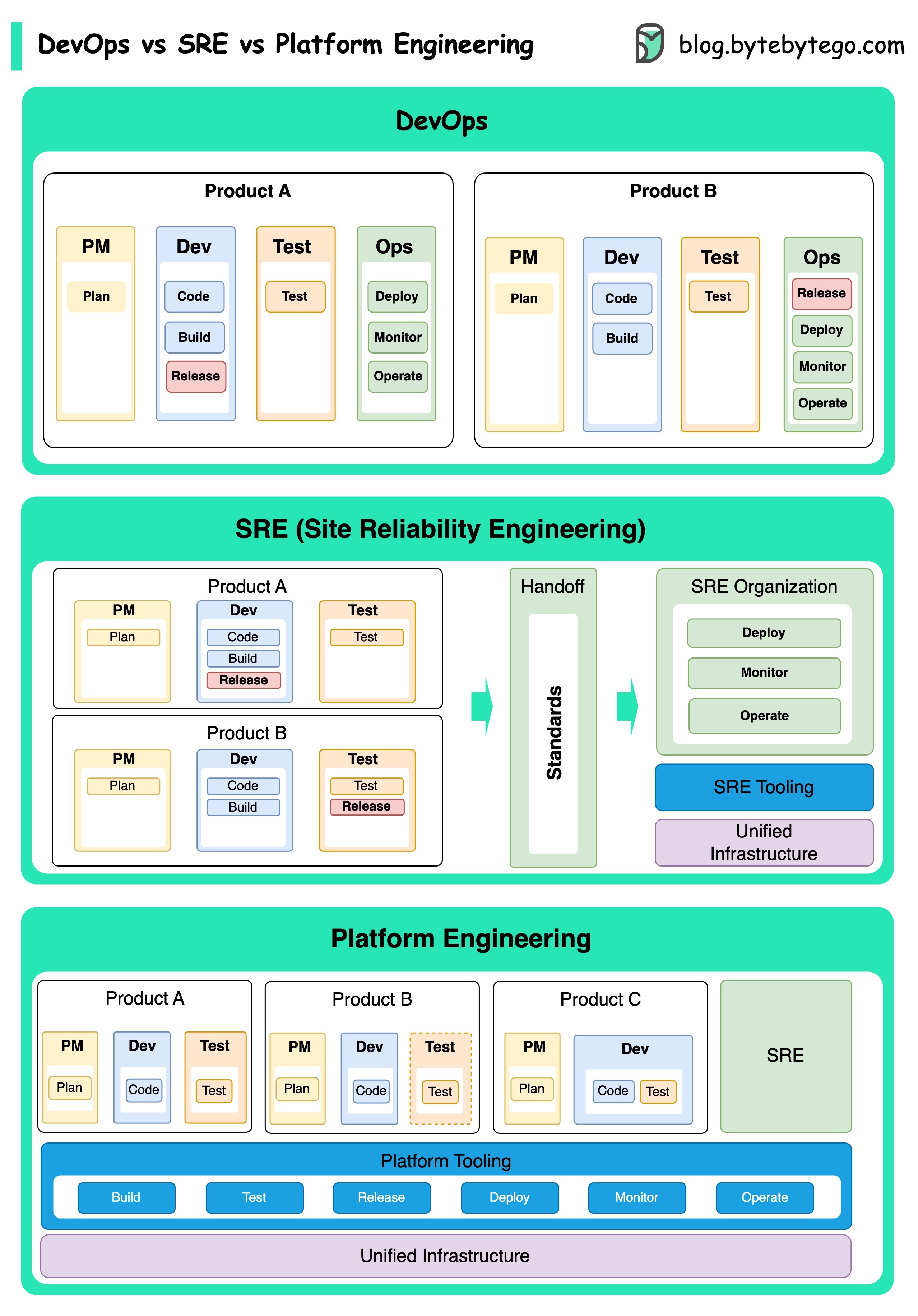
DevOps als Konzept wurde 2009 von Patrick Debois und Andrew Shafer auf der Agile Conference eingeführt. Sie versuchten, die Lücke zwischen Softwareentwicklung und Operationen zu überbrücken, indem sie eine kollaborative Kultur und gemeinsame Verantwortung für den gesamten Lebenszyklus der Softwareentwicklung fördern.
SRE oder Site Zuverlässigkeitstechnik wurde Anfang der 2000er Jahre von Google Pionierarbeit, um die betrieblichen Herausforderungen bei der Verwaltung großer, komplexer Systeme zu bewältigen. Google entwickelte SRE -Praktiken und Tools wie das Borg -Cluster -Managementsystem und das Monarch -Überwachungssystem, um die Zuverlässigkeit und Effizienz ihrer Dienste zu verbessern.
Platform Engineering ist ein neueres Konzept, das auf der Grundlage von SRE Engineering aufbaut. Die genauen Ursprünge von Plattform Engineering sind weniger klar, es wird jedoch allgemein als Erweiterung der DevOps und SRE -Praktiken angesehen, wobei der Schwerpunkt auf einer umfassenden Plattform für die Produktentwicklung liegt, die die gesamte Geschäftsperspektive unterstützt.
Es ist erwähnenswert, dass diese Konzepte zwar zu unterschiedlichen Zeiten entstanden sind. Sie alle beziehen sich auf den breiteren Trend zur Verbesserung der Zusammenarbeit, Automatisierung und Effizienz in der Softwareentwicklung und -betrieb.
K8S ist ein Container -Orchestrierungssystem. Es wird für die Bereitstellung und Verwaltung von Containern verwendet. Das Design ist stark von Googles internem System Borg beeinflusst.
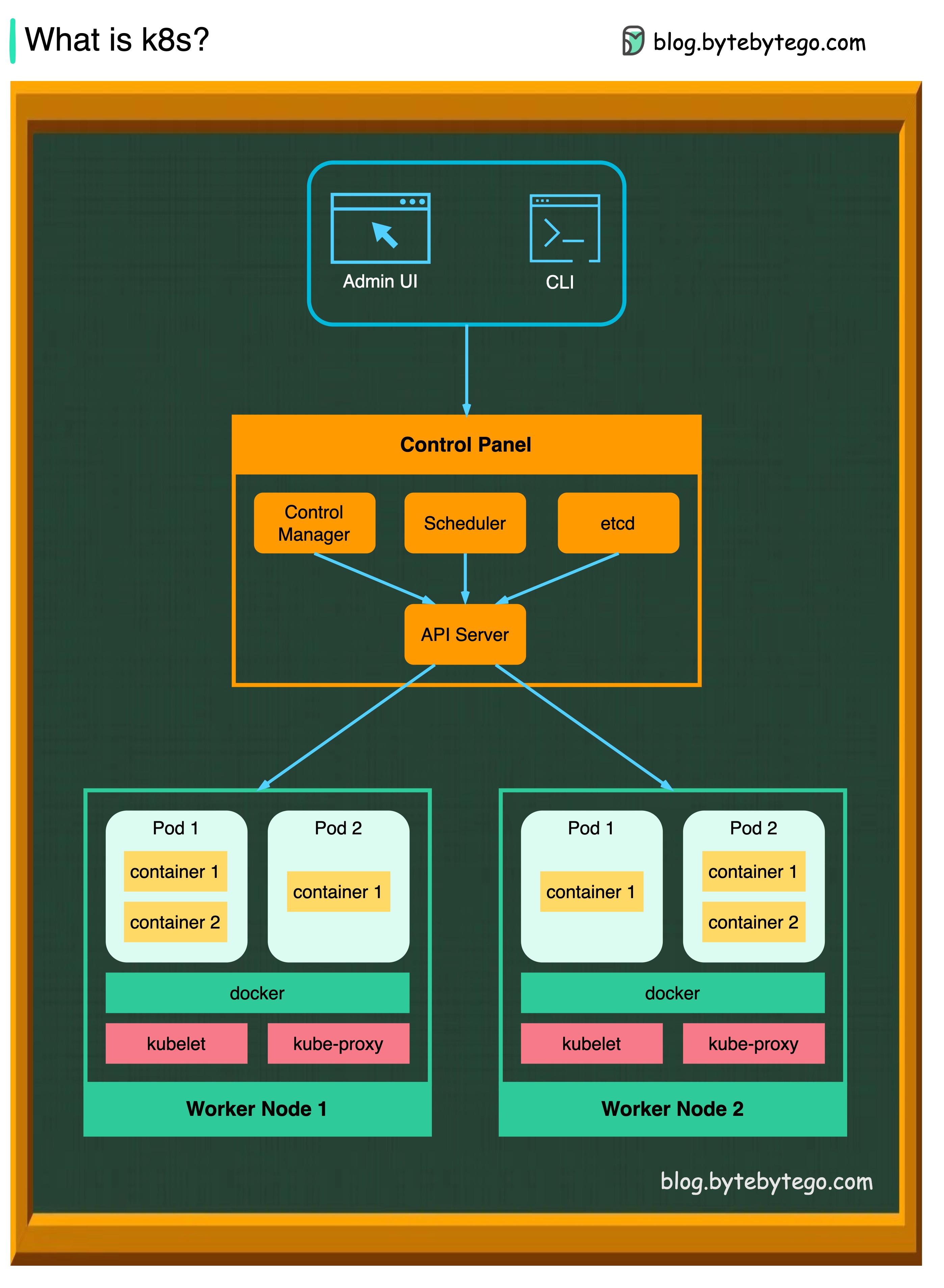
Ein K8S -Cluster besteht aus einer Reihe von Arbeitermaschinen, die als Knoten bezeichnet werden und die Containeranwendungen ausführen. Jeder Cluster hat mindestens einen Arbeiterknoten.
Die Arbeiterknoten halten die Pods, die die Komponenten der Anwendungs -Workload sind. Die Kontrollebene verwaltet die Arbeiterknoten und die Schoten im Cluster. In Produktionsumgebungen läuft die Steuerebene normalerweise über mehrere Computer, und ein Cluster führt normalerweise mehrere Knoten aus, wodurch Fehlertoleranz und hohe Verfügbarkeit bereitgestellt werden.
API-Server
Der API -Server spricht mit allen Komponenten im K8S -Cluster. Alle Vorgänge auf Pods werden durch Gespräch mit dem API -Server ausgeführt.
Planer
Die Scheduler beobachten Pod Workloads und weist Ladungen für neu erstellte Pods zu.
Controller-Manager
Der Controller -Manager führt die Controller aus, einschließlich Knotencontroller, Jobcontroller, Endpointslice Controller und ServiceAccount Controller.
Usw
ETCD ist ein Schlüsselwertspeicher, der als Kubernetes-Backing-Store für alle Clusterdaten verwendet wird.
Schoten
Eine Pod ist eine Gruppe von Behältern und die kleinste Einheit, die K8s verwaltet. Pods haben eine einzelne IP -Adresse, die auf jeden Container innerhalb der Pod angewendet wird.
Kuberett
Ein Agent, der auf jedem Knoten im Cluster ausgeführt wird. Es sorgt dafür, dass Behälter in einem Pod laufen.
Kube Proxy
Kube-Proxy ist ein Netzwerkproxy, der auf jedem Knoten in Ihrem Cluster ausgeführt wird. Es leitet den Verkehr aus dem Dienst in einen Knoten. Es leitet die Arbeitsanfragen an die richtigen Container weiter.

Was ist Docker?
Docker ist eine Open-Source-Plattform, mit der Sie Anwendungen in isolierten Containern verpacken, vertreiben und ausführen können. Es konzentriert sich auf Containerisierung und bietet leichte Umgebungen, die Anwendungen und deren Abhängigkeiten zusammenfassen.
Was ist Kubernetes?
Kubernetes, oft als K8S bezeichnet, ist eine Open-Source-Container-Orchestrierungsplattform. Es bietet einen Framework zur Automatisierung der Bereitstellung, Skalierung und Verwaltung von Containeranwendungen über eine Gruppe von Knoten.
Wie unterscheiden sich beide voneinander?
Docker: Docker arbeitet auf einer einzelnen Containerebene auf einem einzelnen Betriebssystem -Host.
Sie müssen jeden Host manuell verwalten und Netzwerke, Sicherheitsrichtlinien und Speicher für mehrere verwandte Container einrichten, kann komplex sein.
Kubernetes: Kubernetes arbeitet auf Clusterebene. Es verwaltet mehrere Containeranwendungen über mehrere Hosts hinweg und bietet Automatisierung für Aufgaben wie Lastausgleich, Skalierung und Gewährleistung des gewünschten Anwendungszustands.
Kurz gesagt, Docker konzentriert sich auf Containerisierung und laufende Container auf einzelnen Hosts, während Kubernetes auf eine Gruppe von Hosts auf die Verwaltung und Orchestrierung von Containern auf dem Maßstab spezialisiert ist.
Das folgende Diagramm zeigt die Architektur von Docker und wie es funktioniert, wenn wir "Docker Build", "Docker Pull" und "Docker Run" ausführen.
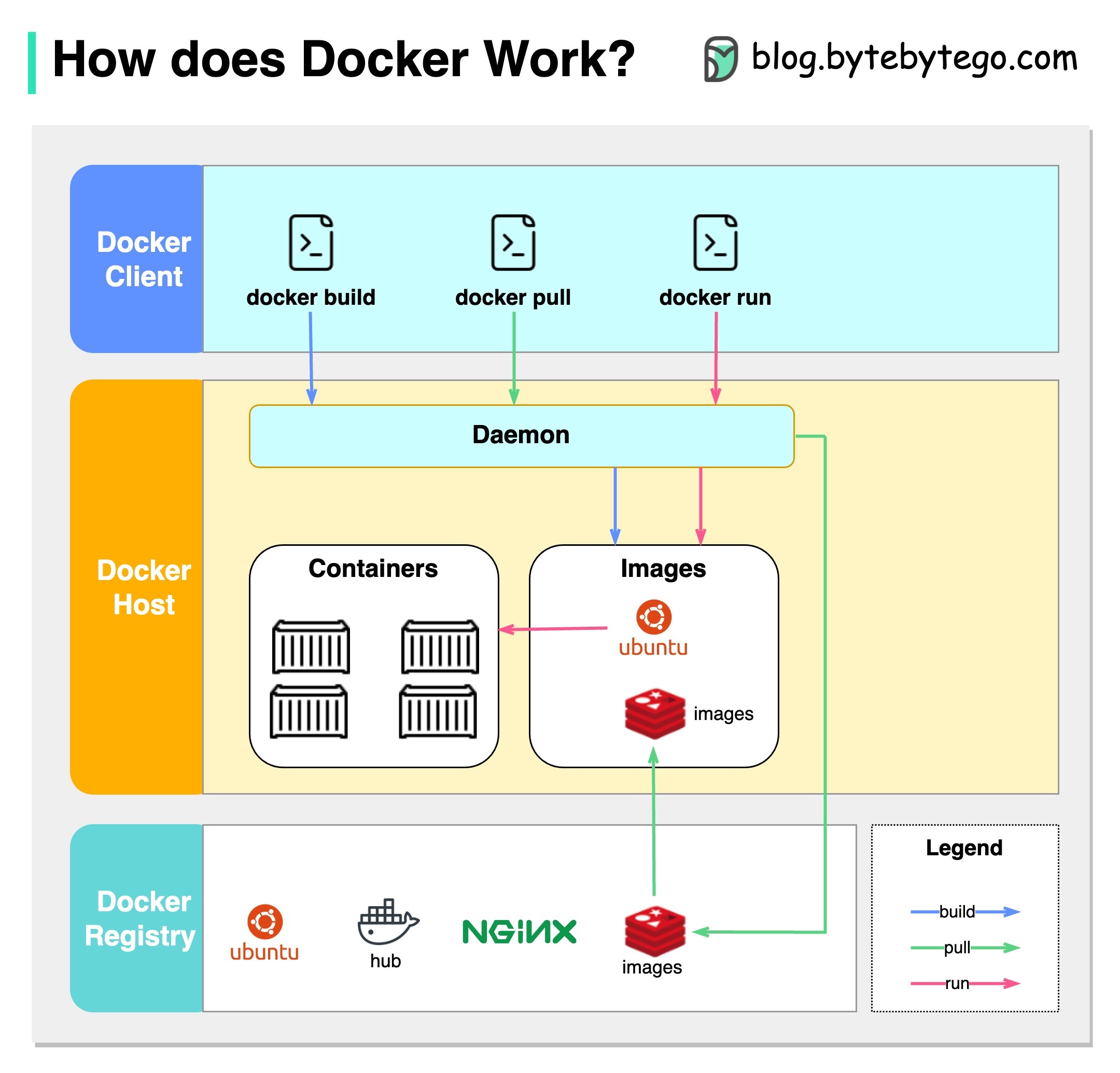
Es gibt 3 Komponenten in der Docker -Architektur:
Docker -Kunde
Der Docker -Kunde spricht mit dem Docker -Daemon.
Docker -Host
Der Docker -Daemon hört auf Docker -API -Anfragen und verwaltet Docker -Objekte wie Bilder, Container, Netzwerke und Volumina.
Docker -Registrierung
Ein Docker Registry Stores Docker Images. Docker Hub ist ein öffentliches Register, das jeder verwenden kann.
Nehmen wir den Befehl "Docker Run" als Beispiel.
Zunächst ist es wichtig zu ermitteln, wo unser Code gespeichert ist. Die übliche Annahme ist, dass es nur zwei Standorte gibt - einen auf einem Remote -Server wie GitHub und den anderen auf unserer lokalen Maschine. Dies ist jedoch nicht ganz genau. Git unterhält drei lokale Speicher auf unserer Maschine, was bedeutet, dass unser Code an vier Stellen gefunden werden kann:
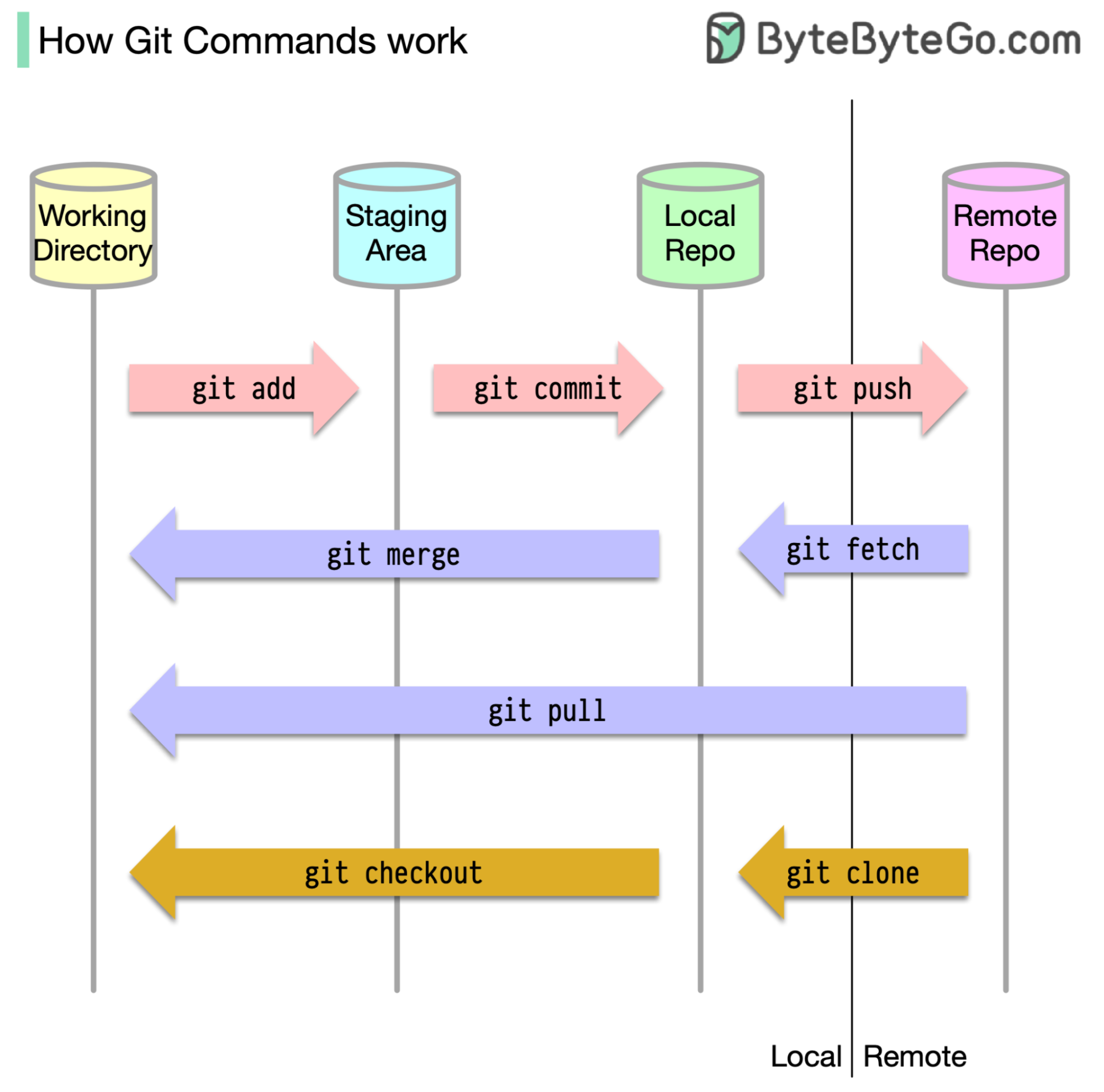
Die meisten GIT -Befehle verschieben Dateien in erster Linie zwischen diesen vier Standorten.
Das folgende Diagramm zeigt den Git -Workflow.
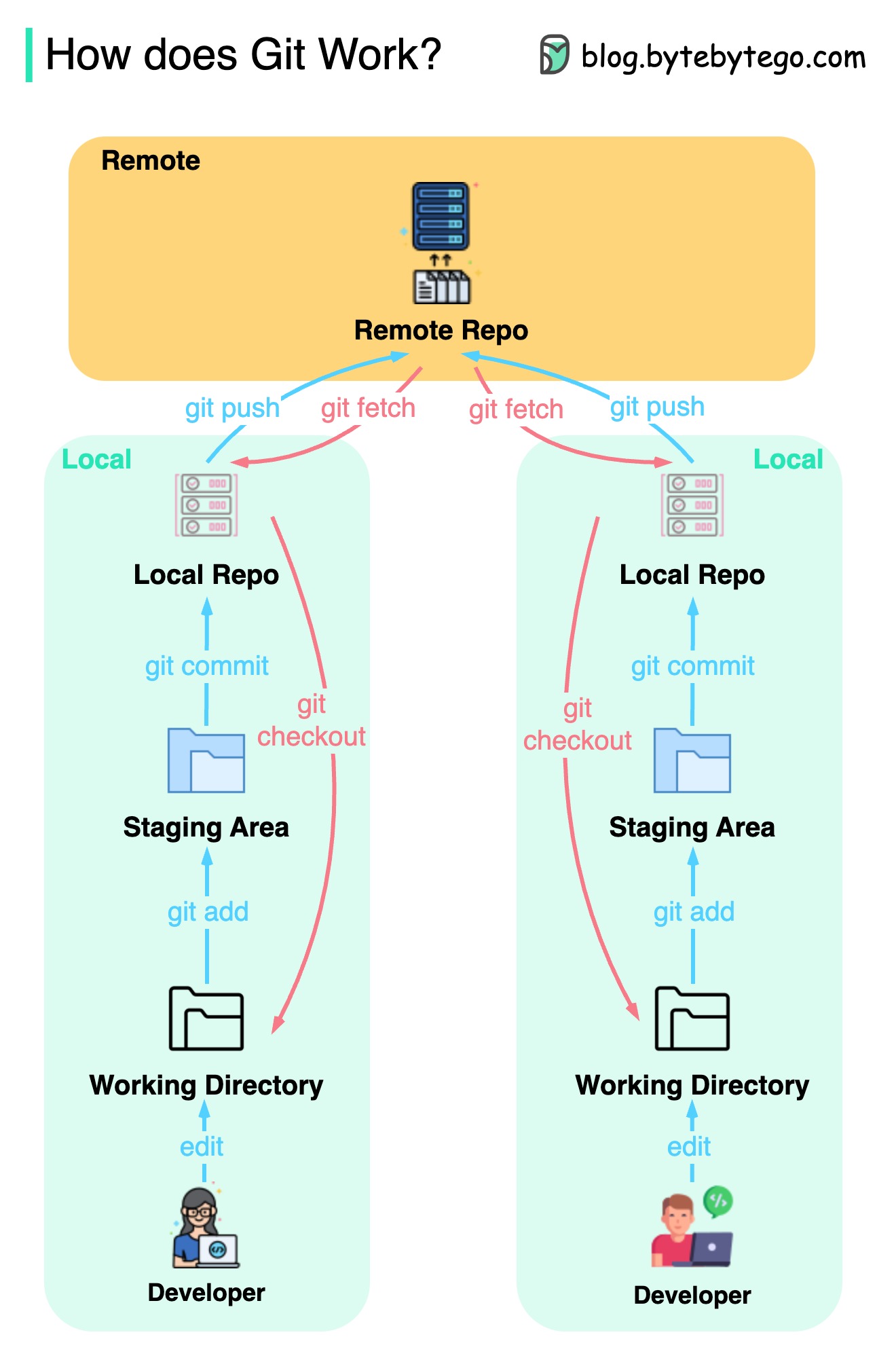
Git ist ein verteiltes Versionskontrollsystem.
Jeder Entwickler unterhält eine lokale Kopie des Haupt -Repositorys und bearbeitet und verpflichtet sich an die lokale Kopie.
Das Commit ist sehr schnell, da die Operation nicht mit dem Remote -Repository interagiert.
Wenn das Remote -Repository abstürzt, können die Dateien aus den lokalen Repositorys wiederhergestellt werden.
Was sind die Unterschiede?


