ai toolkit
1.0.0
Dies ist mein Forschungsrepo. Ich mache viele Experimente damit und es ist möglich, dass ich Dinge kaputt mache. Wenn etwas kaputt geht, überprüfen Sie einen früheren Commit. Mit diesem Repo können viele Dinge trainiert werden, und es ist schwierig, mit allen Schritt zu halten.
Meine Arbeit an diesem Projekt wäre ohne die großartige Unterstützung von Glif und allen im Team nicht möglich. Wenn Sie mich unterstützen möchten, unterstützen Sie Glif. Treten Sie der Website bei, treten Sie uns auf Discord bei, folgen Sie uns auf Twitter und machen Sie mit uns ein paar coole Sachen
Anforderungen:
Linux:
git clone https://github.com/ostris/ai-toolkit.git
cd ai-toolkit
git submodule update --init --recursive
python3 -m venv venv
source venv/bin/activate
# .venvScriptsactivate on windows
# install torch first
pip3 install torch
pip3 install -r requirements.txtWindows:
git clone https://github.com/ostris/ai-toolkit.git
cd ai-toolkit
git submodule update --init --recursive
python -m venv venv
. v env S cripts a ctivate
pip install torch torchvision --index-url https://download.pytorch.org/whl/cu121
pip install -r requirements.txtUm schnell loszulegen, schauen Sie sich das @araminta_k-Tutorial zur Feinabstimmung von Flux Dev auf einem 3090 mit 24 GB VRAM an.
Sie benötigen derzeit eine GPU mit mindestens 24 GB VRAM, um FLUX.1 zu trainieren. Wenn Sie es als GPU zur Steuerung Ihrer Monitore verwenden, müssen Sie wahrscheinlich das Flag low_vram: true in der Konfigurationsdatei unter model: setzen. Dadurch wird das Modell auf der CPU quantisiert und sollte es ermöglichen, mit angeschlossenen Monitoren zu trainieren. Benutzer haben es unter Windows mit WSL zum Laufen gebracht, es gibt jedoch einige Berichte über einen Fehler bei der nativen Ausführung unter Windows. Ich habe es vorerst nur unter Linux getestet. Dies ist noch äußerst experimentell und es mussten viele Quantisierungen und Tricks durchgeführt werden, damit es überhaupt auf 24 GB passt.
FLUX.1-dev verfügt über eine nichtkommerzielle Lizenz. Das bedeutet, dass alles, was Sie trainieren, die nichtkommerzielle Lizenz erbt. Da es sich ebenfalls um ein geschlossenes Modell handelt, müssen Sie die Lizenz auf HF akzeptieren, bevor Sie es verwenden können. Andernfalls schlägt dies fehl. Hier sind die erforderlichen Schritte zum Einrichten einer Lizenz.
.env.env Datei hinzu, etwa so: HF_TOKEN=your_key_hereFLUX.1-schnell ist Apache 2.0. Alles, was darauf trainiert wird, kann nach Belieben lizenziert werden und es ist kein HF_TOKEN zum Trainieren erforderlich. Allerdings ist für das Training ein spezieller Adapter erforderlich, der ostris/FLUX.1-schnell-training-adapter. Es ist auch sehr experimentell. Für eine optimale Gesamtqualität wird eine Schulung zu FLUX.1-dev empfohlen.
Um es zu verwenden, müssen Sie den Assistenten nur wie folgt zum model Ihrer Konfigurationsdatei hinzufügen:
model :
name_or_path : " black-forest-labs/FLUX.1-schnell "
assistant_lora_path : " ostris/FLUX.1-schnell-training-adapter "
is_flux : true
quantize : trueSie müssen auch Ihre Beispielschritte anpassen, da für schnell nicht so viele erforderlich sind
sample :
guidance_scale : 1 # schnell does not do guidance
sample_steps : 4 # 1 - 4 works wellconfig/examples/train_lora_flux_24gb.yaml ( config/examples/train_lora_flux_schnell_24gb.yaml für schnell) in den config und benennen Sie sie in whatever_you_want.yml umpython run.py config/whatever_you_want.ymlBeim Start wird ein Ordner mit dem Namen und dem Trainingsordner aus der Konfigurationsdatei erstellt. Es enthält alle Kontrollpunkte und Bilder. Sie können das Training jederzeit mit Strg+C stoppen. Wenn Sie es fortsetzen, wird es wieder am letzten Kontrollpunkt fortgesetzt.
WICHTIG. Wenn Sie während des Speicherns Strg+C drücken, wird dieser Prüfpunkt wahrscheinlich beschädigt. Warten Sie also, bis das Speichern abgeschlossen ist
Bitte öffnen Sie keinen Fehlerbericht, es sei denn, es handelt sich um einen Fehler im Code. Du kannst gerne meinem Discord beitreten und dort um Hilfe bitten. Bitte sehen Sie jedoch davon ab, mir direkt eine allgemeine Frage oder Unterstützung per PN zu senden. Fragen Sie im Discord und ich werde antworten, sobald ich kann.
Um mit dem lokalen Training mit einer benutzerdefinierten Benutzeroberfläche zu beginnen, nachdem Sie die oben genannten Schritte ausgeführt und ai-toolkit installiert haben:
cd ai-toolkit # in case you are not yet in the ai-toolkit folder
huggingface-cli login # provide a `write` token to publish your LoRA at the end
python flux_train_ui.py Sie instanziieren eine Benutzeroberfläche, mit der Sie Ihre Bilder hochladen, beschriften, Ihre LoRA trainieren und veröffentlichen können 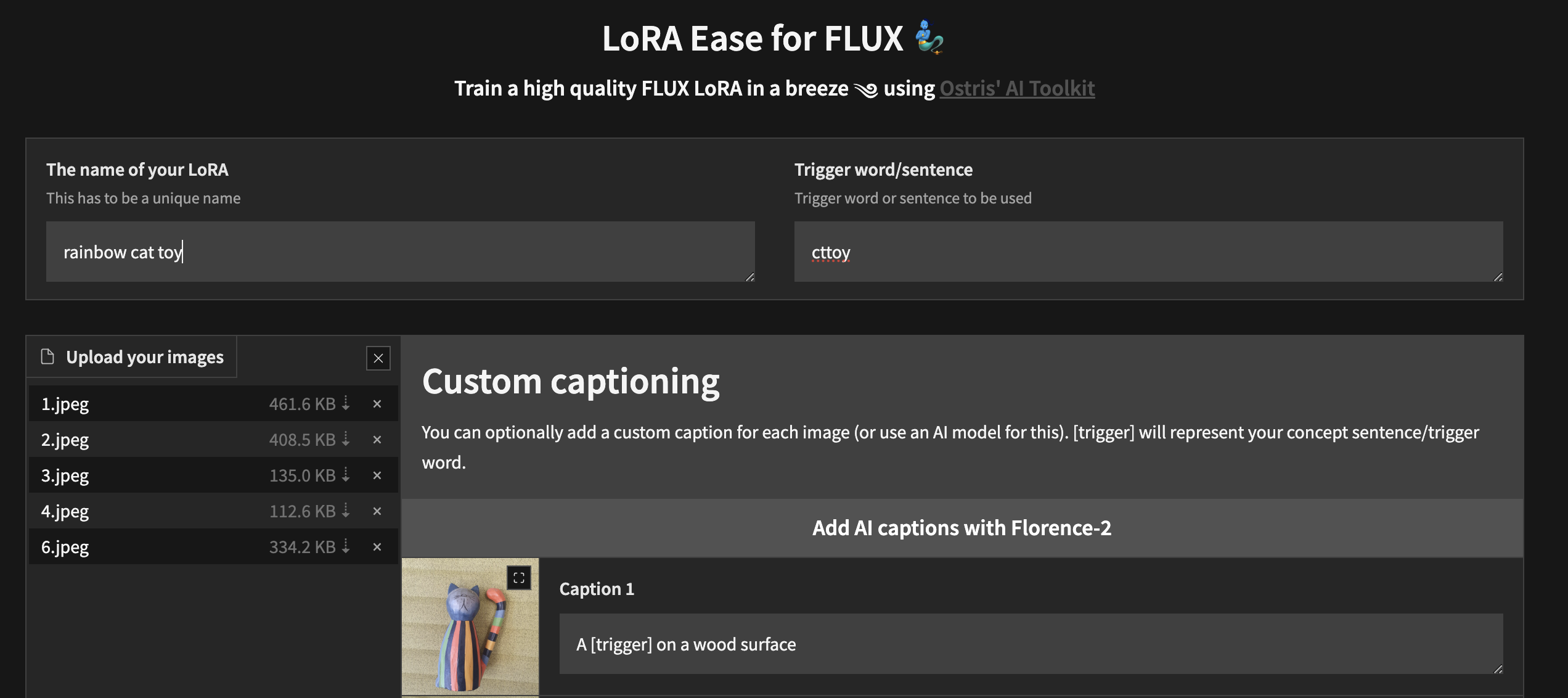
Beispiel einer RunPod-Vorlage: runpod/pytorch:2.2.0-py3.10-cuda12.1.1-devel-ubuntu22.04
Sie benötigen mindestens 24 GB VRAM. Wählen Sie eine GPU nach Ihren Wünschen.
git clone https://github.com/ostris/ai-toolkit.git
cd ai-toolkit
git submodule update --init --recursive
python -m venv venv
source venv/bin/activate
pip install torch
pip install -r requirements.txt
pip install --upgrade accelerate transformers diffusers huggingface_hub #Optional, run it if you run into issues
dataset oder wie auch immer Sie möchten.huggingface-cli login aus und fügen Sie Ihr Token ein.config/examples befindet, in den Konfigurationsordner und benennen Sie sie in whatever_you_want.yml um.folder_path: "/path/to/images/folder" in Ihren Datensatzpfad, z. B. folder_path: "/workspace/ai-toolkit/your-dataset" .python run.py config/whatever_you_want.yml .
git clone https://github.com/ostris/ai-toolkit.git
cd ai-toolkit
git submodule update --init --recursive
python -m venv venv
source venv/bin/activate
pip install torch
pip install -r requirements.txt
pip install --upgrade accelerate transformers diffusers huggingface_hub #Optional, run it if you run into issues
pip install modal aus, um das modale Python-Paket zu installieren.modal setup aus (wenn dies nicht funktioniert, versuchen Sie es mit python -m modal setup ). huggingface-cli login aus und fügen Sie Ihr Token ein.ai-toolkit .config/examples/modal befindet, in den config und benennen Sie sie in whatever_you_want.yml um./root/ai-toolkit . Legen Sie Ihren gesamten lokalen ai-toolkit Pfad unter code_mount = modal.Mount.from_local_dir fest, etwa so:
code_mount = modal.Mount.from_local_dir("/Users/username/ai-toolkit", remote_path="/root/ai-toolkit")
Wählen Sie in @app.function eine GPU und Timeout aus (Standard ist A100 40 GB und 2 Stunden Timeout) .
modal run run_modal.py --config-file-list-str=/root/ai-toolkit/config/whatever_you_want.yml .Storage > flux-lora-models gespeichert.modal volume ls flux-lora-models ausführen.modal volume get flux-lora-models your-model-name ausführen.modal volume get flux-lora-models my_first_flux_lora_v1 .
Datensätze müssen im Allgemeinen ein Ordner sein, der Bilder und zugehörige Textdateien enthält. Derzeit werden nur die Formate JPG, JPEG und PNG unterstützt. Webp hat derzeit Probleme. Die Textdateien sollten denselben Namen wie die Bilder haben, jedoch mit der Erweiterung .txt . Zum Beispiel image2.jpg und image2.txt . Die Textdatei sollte nur die Beschriftung enthalten. Sie können das Wort [trigger] in der Untertiteldatei hinzufügen und wenn Sie trigger_word in Ihrer Konfiguration haben, wird es automatisch ersetzt.
Bilder werden nie hochskaliert, sondern verkleinert und zur Stapelverarbeitung in Buckets abgelegt. Sie müssen Ihre Bilder nicht zuschneiden/in der Größe ändern . Der Loader passt die Größe automatisch an und kann mit unterschiedlichen Seitenverhältnissen umgehen.
Um bestimmte Ebenen mit LoRA zu trainieren, können Sie die Netzwerk-Kwargs only_if_contains verwenden. Wenn Sie beispielsweise nur die beiden in diesem Beitrag erwähnten Ebenen von The Last Ben trainieren möchten, können Sie Ihre Netzwerk-Kwargs wie folgt anpassen:
network :
type : " lora "
linear : 128
linear_alpha : 128
network_kwargs :
only_if_contains :
- " transformer.single_transformer_blocks.7.proj_out "
- " transformer.single_transformer_blocks.20.proj_out " Die Benennungskonventionen der Ebenen entsprechen dem Diffusorformat. Wenn Sie also das Statusdiktat eines Modells überprüfen, wird das Suffix des Namens der Ebenen angezeigt, die Sie trainieren möchten. Sie können diese Methode auch verwenden, um nur bestimmte Gewichtsgruppen zu trainieren. Um beispielsweise nur den single_transformer für FLUX.1 zu trainieren, können Sie Folgendes verwenden:
network :
type : " lora "
linear : 128
linear_alpha : 128
network_kwargs :
only_if_contains :
- " transformer.single_transformer_blocks. " Sie können Layer auch anhand ihres Namens ausschließen, indem Sie ignore_if_contains network kwarg“ verwenden. Um also alle einzelnen Transformatorblöcke auszuschließen,
network :
type : " lora "
linear : 128
linear_alpha : 128
network_kwargs :
ignore_if_contains :
- " transformer.single_transformer_blocks. " ignore_if_contains hat Vorrang vor only_if_contains . Wenn also ein Gewicht von beiden abgedeckt wird, wird es ignoriert.
Es funktioniert vielleicht immer noch so, aber ich habe es eine Weile nicht getestet.
Ein Bildgenerator, der aus einer Konfigurationsdatei stammen oder eine TXT-Datei erstellen und diese in einem Ordner generieren kann. Ich brauchte dies hauptsächlich für einen SDXL-Test, den ich gerade durchführe, habe aber etwas Feinschliff hinzugefügt, damit es für die Generierung von Batch-Bildern verwendet werden kann. Alles läuft über eine Konfigurationsdatei, für die Sie ein Beispiel unter config/examples/generate.example.yaml finden. Weitere Informationen finden Sie in den Kommentaren im Beispiel
Es basiert auf dem Extraktor im LyCORIS-Tool, bietet jedoch einige QOL-Funktionen und LoRA-Unterstützung (Lierla). Es können mehrere Arten von Extraktionen in einem Durchlauf durchgeführt werden. Alles läuft über eine Konfigurationsdatei, für die Sie ein Beispiel in config/examples/extract.example.yml finden. Kopieren Sie einfach diese Datei in den config und benennen Sie sie in whatever_you_want.yml um. Anschließend können Sie die Datei nach Ihren Wünschen bearbeiten. und nenne es so:
python3 run.py config/whatever_you_want.ymlSie können auch einen vollständigen Pfad zu einer Konfigurationsdatei angeben, wenn Sie diese an einem anderen Ort aufbewahren möchten.
python3 run.py " /home/user/whatever_you_want.yml "Weitere Hinweise zur Funktionsweise finden Sie in der Beispielkonfigurationsdatei selbst. LoRA und LoCON unterstützen beide Extraktionen von „fest“, „Schwelle“, „Verhältnis“ und „Quantil“. Ich werde später aktualisieren, was diese bewirken und bedeuten. Die meisten Leute verwendeten „Fixed“, also die traditionelle Extraktion fester Dimensionen.
process ist eine Reihe verschiedener auszuführender Prozesse. Sie können ein paar hinzufügen und kombinieren. Ein LoRA, ein LyCON usw.
Ändern Sie <lora:my_lora:4.6> in <lora:my_lora:1.0> oder was auch immer Sie möchten, mit dem gleichen Effekt. Ein Tool zum Neuskalieren der Gewichte einer LoRA. Sollte auch mit LoCON funktionieren, habe ich aber nicht getestet. Alles läuft über eine Konfigurationsdatei, für die Sie ein Beispiel in config/examples/mod_lora_scale.yml finden. Kopieren Sie einfach diese Datei in den config und benennen Sie sie in whatever_you_want.yml um. Anschließend können Sie die Datei nach Ihren Wünschen bearbeiten. und nenne es so:
python3 run.py config/whatever_you_want.ymlSie können auch einen vollständigen Pfad zu einer Konfigurationsdatei angeben, wenn Sie diese an einem anderen Ort aufbewahren möchten.
python3 run.py " /home/user/whatever_you_want.yml "Weitere Hinweise zur Funktionsweise finden Sie in der Beispielkonfigurationsdatei selbst. Dies ist bei der Erstellung aller LoRAs nützlich, da das ideale Gewicht selten 1,0 beträgt, aber jetzt können Sie das beheben. Schieberegler können seltsame Skalen von -2 bis 2 oder sogar -15 bis 15 haben. Auf diese Weise können Sie sie so anpassen, dass sie alle die gewünschte Skala haben
Auf diese Weise trainiere ich die meisten meiner aktuellen Slider auf Civitai. Sie können sie in meinem Civitai-Profil nachlesen. Es basiert auf der Arbeit von p1atdev/LECO und rohitgandikota/erasing, wurde jedoch stark modifiziert, um Schieberegler statt Löschkonzepte zu erstellen. Ich habe noch viel mehr vor, aber es ist so wie es ist sehr funktional. Es ist auch sehr einfach zu bedienen. Kopieren Sie einfach die Beispielkonfigurationsdatei in config/examples/train_slider.example.yml in den config und benennen Sie sie in whatever_you_want.yml um. Anschließend können Sie die Datei nach Ihren Wünschen bearbeiten. und nenne es so:
python3 run.py config/whatever_you_want.ymlDiese Beispieldatei enthält noch viele weitere Informationen. Sie können das Beispiel sogar ohne Änderungen ausführen, um zu sehen, wie es funktioniert. Es wird ein Schieberegler erstellt, der alle Tiere in Hunde (neg) oder Katzen (pos) verwandelt. Führen Sie es einfach so aus:
python3 run.py config/examples/train_slider.example.ymlUnd Sie können sehen, wie es funktioniert, ohne etwas konfigurieren zu müssen. Für diese Methode sind keine Datensätze erforderlich. Ich werde bald ein besseres Tutorial veröffentlichen.
Sie können jetzt benutzerdefinierte Erweiterungen erstellen und teilen. Diese laufen innerhalb dieses Frameworks und verfügen über alle integrierten Tools. Ich werde dies wahrscheinlich in Zukunft als primäre Entwicklungsmethode verwenden, damit ich diesem Basis-Repo nicht ständig weitere Funktionen hinzufüge. Ich werde wahrscheinlich auch viele der vorhandenen Funktionen migrieren, um alles modular zu gestalten. Im extensions befindet sich eine Beispielerweiterung, die zeigt, wie eine Model Merger-Erweiterung erstellt wird. Der gesamte Code ist ausführlich dokumentiert, was hoffentlich ausreicht, um Ihnen den Einstieg zu erleichtern. Um eine Erweiterung vorzunehmen, kopieren Sie einfach dieses Beispiel und ersetzen Sie alle erforderlichen Elemente.
Es befindet sich im extensions . Es handelt sich um eine voll funktionale Modellfusion, bei der beliebig viele Modelle zusammengeführt werden können. Es ist ein gutes Beispiel dafür, wie man eine Erweiterung erstellt, ist aber auch eine ziemlich nützliche Funktion, da die meisten Fusionen jeweils nur ein Modell erstellen können und dieses so viele benötigt, wie Sie möchten. Darin befindet sich eine Beispielkonfigurationsdatei. Kopieren Sie diese einfach in Ihren config und benennen Sie sie in whatever_you_want.yml um. und verwenden Sie es wie jede andere Konfigurationsdatei.
Dies funktioniert, ist aber noch nicht für die Verwendung durch andere bereit und verfügt daher nicht über eine Beispielkonfiguration. Ich arbeite immer noch daran. Ich werde dies aktualisieren, sobald es fertig ist. Ich füge viele Funktionen für Kriterien hinzu, die ich in meiner Bildvergrößerungsarbeit verwendet habe. Ein Kritiker (Diskriminator), Inhaltsverlust, Stilverlust und einige mehr. Falls Sie es nicht wissen: Die VAE für stabile Diffusion (ja, sogar die MSE-Version und SDXL) sind bei kleineren Gesichtern schrecklich und halten SD zurück. Ich werde das beheben. Ich werde später mehr dazu mit besseren Beispielen posten, aber hier ist ein kurzer Test eines Durchlaufs mit verschiedenen VAEs. Bin einfach rein und raus gegangen. Bei kleineren Gesichtern ist es viel schlimmer als hier gezeigt.
extensions an. Lesen Sie oben mehr darüber.Ein weiterer großer Refaktor, um SD modularer zu machen.
Skript zur Batch-Bildgenerierung erstellt
Wichtige Änderungen und Aktualisierungen. Neues LoRA-Reskalierungstool, Details finden Sie oben. Bessere Metadaten hinzugefügt, damit Automatic1111 weiß, um welches Basismodell es sich handelt. Einige Experimente und eine Menge Updates hinzugefügt. Dieses Ding ist im Moment noch instabil, daher gibt es hoffentlich keine Breaking Changes.
Leider bin ich zu faul, ein richtiges Changelog mit allen Änderungen zu schreiben.
Ich habe den Schiebereglern SDXL-Training hinzugefügt ... aber ... es funktioniert nicht richtig. Das Slider-Training basiert auf der Fähigkeit eines Modells zu verstehen, dass eine unbedingte (negative Eingabeaufforderung) bedeutet, dass Sie dieses Konzept nicht in der Ausgabe haben möchten. SDXL versteht dies aus irgendeinem Grund nicht, was die Trennung von Konzepten innerhalb des Modells schwierig macht. Ich bin mir sicher, dass die Community im Laufe der Zeit einen Weg finden wird, das Problem zu beheben, aber im Moment wird es nicht richtig funktionieren. Und wenn einer von Ihnen denkt: „Könnten wir das vielleicht beheben, indem wir dem Modell ein oder zwei weitere Text-Encoder sowie ein paar weitere völlig separate Diffusionsnetzwerke hinzufügen?“ Nein. Gott nein. Es braucht nur ein wenig Training, ohne dass jede experimentelle neue Arbeit hinzugefügt wird. Der KISS-Direktor.
Dem Slider-Trainer wurden „Anker“ hinzugefügt. Auf diese Weise können Sie eine Eingabeaufforderung festlegen, die als Regularisierer verwendet wird. Sie können den Netzwerkmultiplikator so einstellen, dass bei hohen Gewichtungen eine gleichmäßige Verteilung erzwungen wird


