ShapeGPT
1.0.0

Projektseite • Arxiv-Papier • Demo • FAQ • Zitat
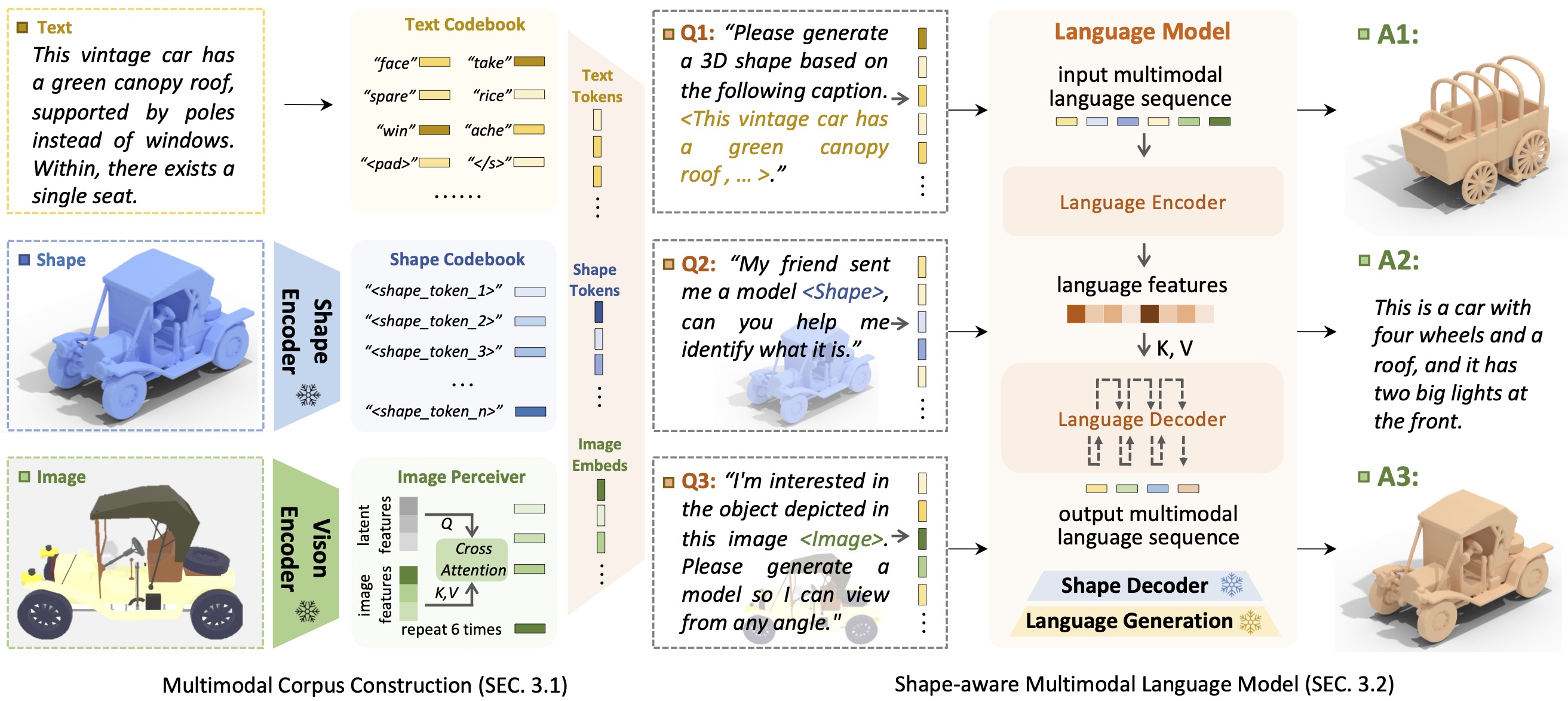
Einführung in ShapeGPTShapeGPT ist ein einheitliches und benutzerfreundliches formzentriertes multimodales Sprachmodell zum Aufbau eines multimodalen Korpus und zur Entwicklung formbewusster Sprachmodelle für mehrere Formaufgaben .
Das Aufkommen großer Sprachmodelle, die Flexibilität durch anweisungsgesteuerte Ansätze ermöglichen, hat viele traditionelle generative Aufgaben revolutioniert, aber große Modelle für 3D-Daten, insbesondere für die umfassende Handhabung von 3D-Formen mit anderen Modalitäten, sind noch immer unzureichend erforscht. Durch die Erzielung anweisungsbasierter Formgenerierungen können vielseitige multimodale generative Formmodelle verschiedenen Bereichen wie der virtuellen 3D-Konstruktion und dem netzwerkgestützten Design erhebliche Vorteile bringen. In dieser Arbeit stellen wir ShapeGPT vor, ein formintegriertes multimodales Framework zur Nutzung starker vorab trainierter Sprachmodelle zur Bewältigung mehrerer formrelevanter Aufgaben. Insbesondere verwendet ShapeGPT ein Wort-Satz-Absatz-Framework, um kontinuierliche Formen in Formwörter zu diskretisieren, diese Wörter weiter für Formsätze zusammenzusetzen und Formen mit Anleitungstext für multimodale Absätze zu integrieren. Um dieses Formsprachenmodell zu erlernen, verwenden wir ein dreistufiges Trainingsschema, das Formdarstellung, multimodale Ausrichtung und anweisungsbasierte Generierung umfasst, um Formsprache-Codebücher auszurichten und die komplizierten Korrelationen zwischen diesen Modalitäten zu lernen. Umfangreiche Experimente zeigen, dass ShapeGPT bei formrelevanten Aufgaben, einschließlich Text-zu-Form, Form-zu-Text, Formvervollständigung und Formbearbeitung, eine vergleichbare Leistung erzielt.
Wenn Ihnen unser Code oder unser Papier weiterhilft, denken Sie bitte darüber nach, Folgendes zu zitieren:
@misc { yin2023shapegpt ,
title = { ShapeGPT: 3D Shape Generation with A Unified Multi-modal Language Model } ,
author = { Fukun Yin and Xin Chen and Chi Zhang and Biao Jiang and Zibo Zhao and Jiayuan Fan and Gang Yu and Taihao Li and Tao Chen } ,
year = { 2023 } ,
eprint = { 2311.17618 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
}
Dank des T5-Modells, Motion-GPT, Perceiver-IO und SDFusion orientiert sich unser Code teilweise an ihnen. Unser Ansatz ist inspiriert von Unified-IO, Michelangelo, ShapeCrafter, Pix2Vox und 3DShape2VecSet.
Dieser Code wird unter einer MIT-LIZENZ vertrieben.
Beachten Sie, dass unser Code von anderen Bibliotheken abhängt, einschließlich PyTorch3D und PyTorch Lightning, und Datensätze verwendet, für die jeweils eigene Lizenzen gelten, die ebenfalls befolgt werden müssen.


