REaLTabFormer
v0.2.1
Der REaLTabFormer (Realistic Relational and Tabular Data using Transformers) bietet ein einheitliches Framework für die Synthese tabellarischer Daten verschiedener Typen. Zur Generierung synthetischer relationaler Datensätze wird ein Sequenz-zu-Sequenz-Modell (Seq2Seq) verwendet. Das REaLTabFormer-Modell für nicht relationale Tabellendaten verwendet GPT-2 und kann sofort zum Modellieren beliebiger Tabellendaten mit unabhängigen Beobachtungen verwendet werden.
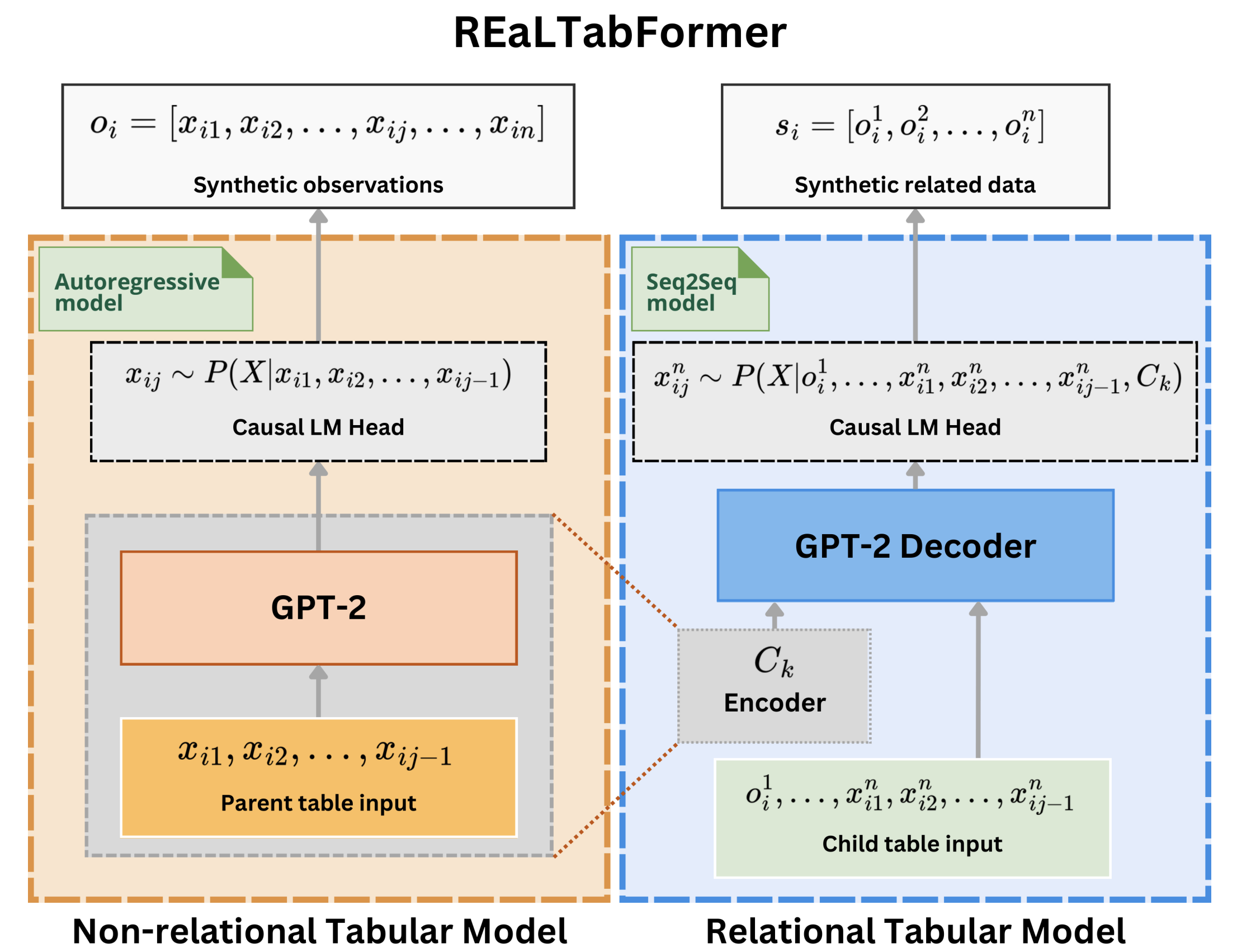
REaLTabFormer: Generieren realistischer relationaler und tabellarischer Daten mithilfe von Transformern
Artikel über ArXiv
REaLTabFormer ist auf PyPi verfügbar und kann einfach mit pip (Python-Version >= 3.7) installiert werden:
pip install realtabformer
Wir zeigen Beispiele für die Verwendung des REaLTabFormer zur Modellierung und Generierung synthetischer Daten aus einem trainierten Modell.
Notiz
Das Modell implementiert beim Training eines nicht relationalen Tabellenmodells ein optimales Stoppkriterium basierend auf der synthetischen Datenverteilung. Das Modell stoppt das Training, wenn die synthetische Datenverteilung nahe an der realen Datenverteilung liegt.
Stellen Sie sicher, dass Sie den Parameter epochs auf eine große Zahl festlegen, damit das Modell besser an die Daten angepasst werden kann. Das Modell beendet das Training, wenn das optimale Stoppkriterium erfüllt ist.
# pip install realtabformerimport pandas as pdfrom realtabformer import REaLTabFormerdf = pd.read_csv("foo.csv")# HINWEIS: Entfernen Sie alle eindeutigen Bezeichner in den # Daten, die nicht modelliert werden sollen.# Nicht relationale oder übergeordnete Tabelle. rtf_model = REaLTabFormer(model_type="tabular",gradient_accumulation_steps=4,logging_steps=100)# Passen Sie das Modell an den Datensatz an.# Zusätzliche Parameter können an die Methode „.fit“ übergeben werden.rtf_model.fit(df)# Speichern Sie das Modell unter das aktuelle Verzeichnis.# Ein neues Verzeichnis „rtf_model/“ wird erstellt.# Darin wird ein Verzeichnis mit der # Experiment-ID des Modells „idXXXX“ erstellt Außerdem werden # dort erstellt, wo die Artefakte des Modells gespeichert werden.rtf_model.save("rtf_model/")# Synthetische Daten mit der gleichen # Anzahl von Beobachtungen wie der reale Datensatz generieren.samples = rtf_model.sample(n_samples=len(df ))# Laden Sie das gespeicherte Modell. Das Verzeichnis zum # Experiment muss angegeben werden.rtf_model2 = REaLTabFormer.load_from_dir(path="rtf_model/idXXXX") # pip install realtabformerimport osimport pandas as pdfrom pathlib import Pathfrom realtabformer import REaLTabFormerparent_df = pd.read_csv("foo.csv")child_df = pd.read_csv("bar.csv")join_on = "unique_id"# Stellen Sie sicher, dass die Schlüsselspalten in Sowohl die übergeordnete als auch die untergeordnete Tabelle haben denselben Namen.assert ((join_on in parent_df.columns) and(join_on in child_df.columns))# Nicht relationale oder übergeordnete Tabelle. # unique_id field.parent_model = REaLTabFormer(model_type="tabular")parent_model.fit(parent_df.drop(join_on, axis=1))pdir = Path("rtf_parent/")parent_model.save(pdir)# nicht einschließen # Rufen Sie das zuletzt gespeicherte übergeordnete Modell ab,# # oder geben Sie ein anderes gespeichertes Modell an.# parent_model_path = pdir / "idXXX"parent_model_path = sorted([p for p in pdir.glob("id*") if p.is_dir()],key=os.path.getmtime)[-1]child_model = REaLTabFormer(model_type="relational",parent_realtabformer_path=parent_model_path,output_max_length=None,train_size=0.8)child_model.fit(df=child_df,in_df=parent_df,join_on=join_on)# Eltern-Samples generieren.parent_samples = parent_model.sample(len(parend_df ))# Erstellen Sie die eindeutigen IDs basierend auf index.parent_samples.index.name = join_onparent_samples = parent_samples.reset_index()# Erzeugen Sie die relationalen Beobachtungen.child_samples = child_model.sample(input_unique_ids=parent_samples[join_on],input_df=parent_samples.drop(join_on, axis=1), gen_batch=64) Das REaLTabFormer-Framework bietet eine Schnittstelle zum einfachen Erstellen von Beobachtungsvalidatoren zum Filtern ungültiger synthetischer Proben. Nachfolgend zeigen wir ein Beispiel für die Verwendung des GeoValidator . Das Diagramm links zeigt die Verteilung der generierten Breiten- und Längengrade ohne Validierung. Das Diagramm rechts zeigt die synthetischen Proben mit Beobachtungen, die mithilfe des GeoValidator mit der kalifornischen Grenze validiert wurden. Selbst wenn wir das Modell nicht optimal für die Generierung trainiert haben, sind die ungültigen Stichproben (die außerhalb der Grenze liegen) in den generierten Daten ohne Validator selten.
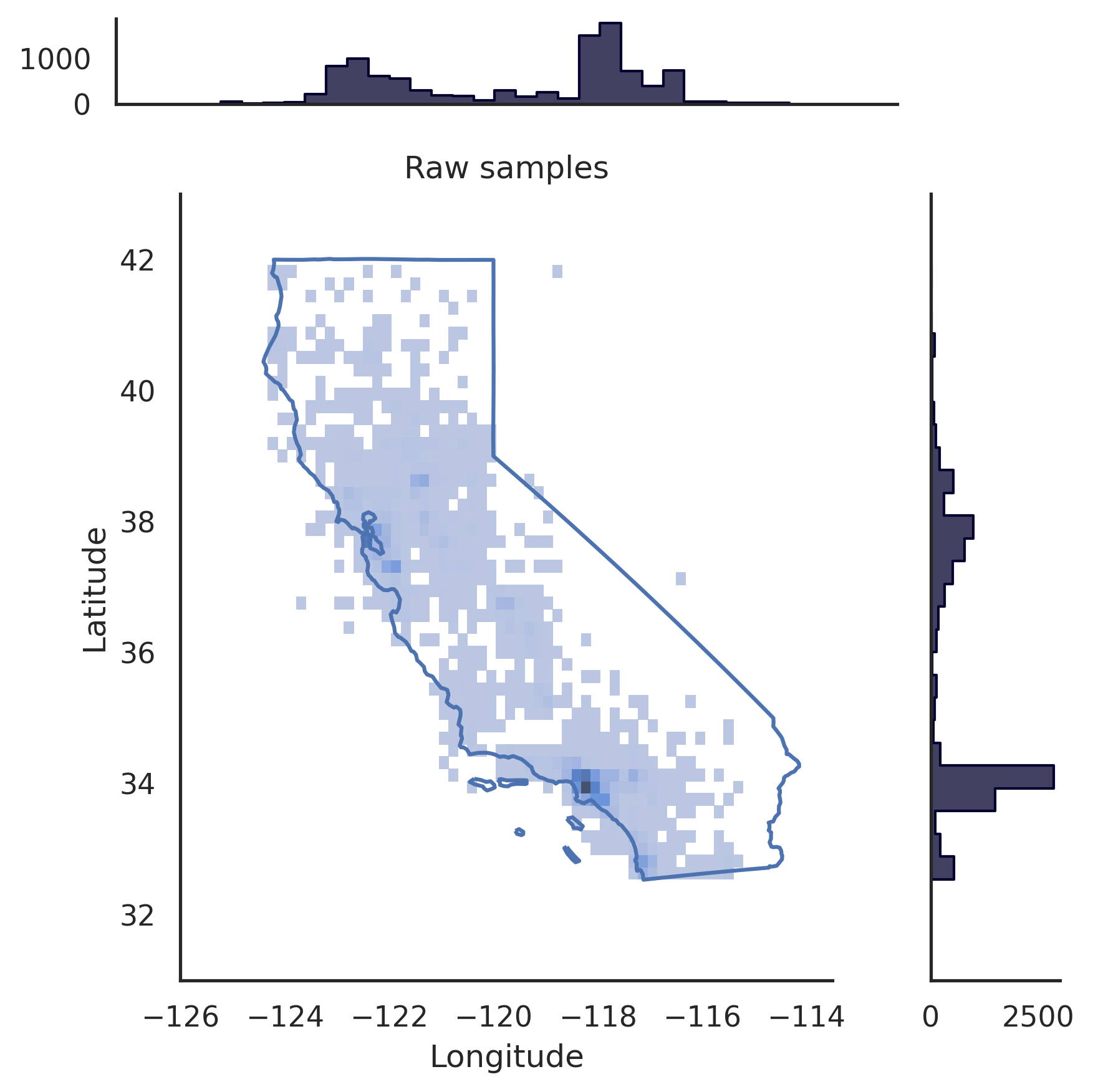
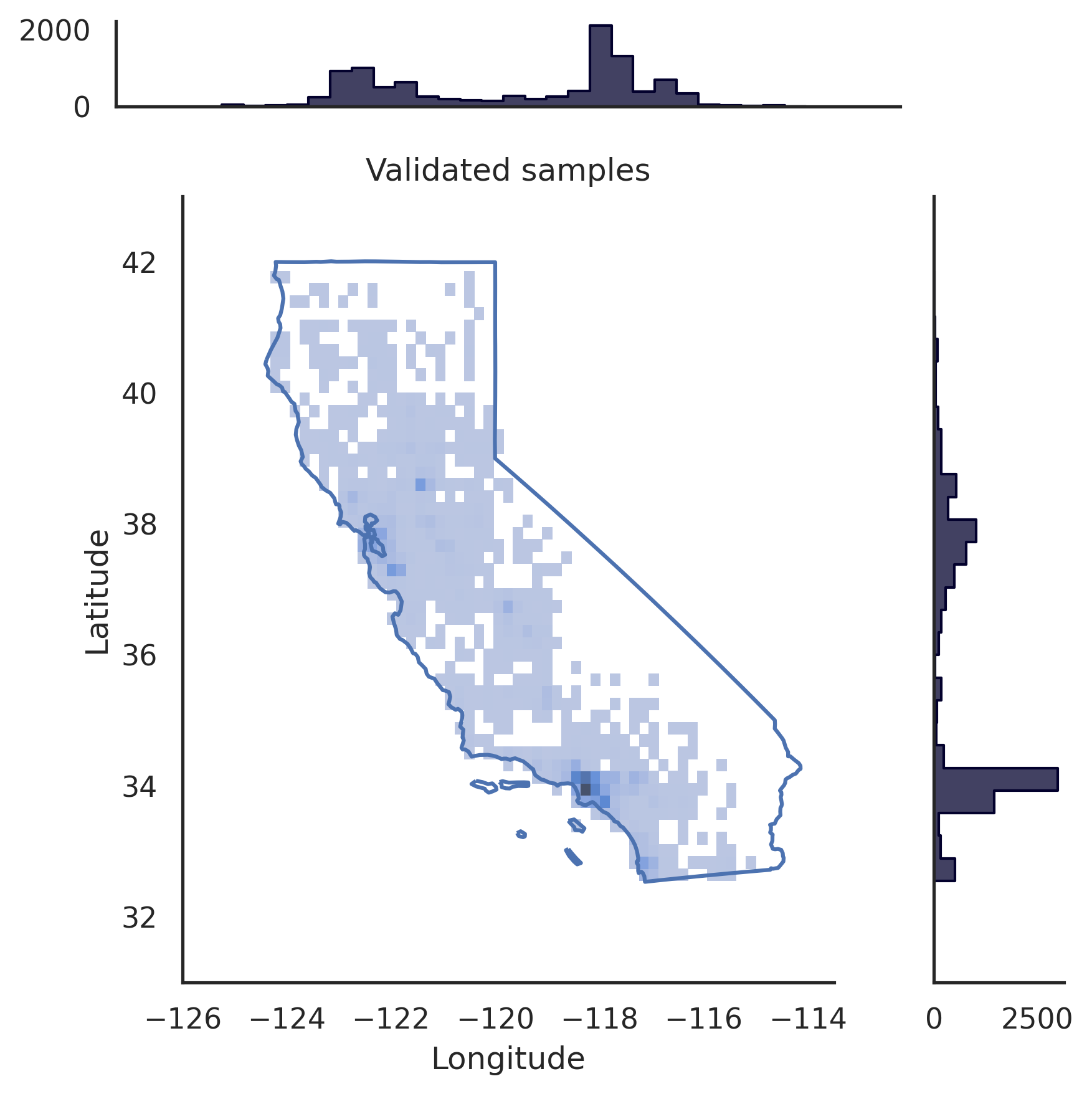
# !pip install geopandas &> /dev/null# !pip install realtabformer &> /dev/null# !git clone https://github.com/joncutrer/geopandas-tutorial.git &> /dev/nullimport geopandasimport seaborn as snsimport matplotlib.pyplot als pltfrom realtabformer import REaLTabFormerfrom realtabformer import rtf_validators as rtf_valfrom shapely.geometry import Polygon, LineString, Point, MultiPolygonfrom sklearn.datasets import fetch_california_housingdef plot_sf(data, examples, title=None):xlims = (-126, -113.5)ylims = (31, 43)bins = (50 , 50)dd = Samples.copy()pp = dd.loc[dd["Longitude"].between(data["Longitude"].min(), data["Longitude"].max()) &dd["Latitude"].between(data["Latitude" ].min(), data["Latitude"].max())
]g = sns.JointGrid(data=pp, x="Longitude", y="Latitude", marginal_ticks=True)g.plot_joint(sns.histplot,bins=bins,
)states[states['NAME'] == 'California'].boundary.plot(ax=g.ax_joint)g.ax_joint.set_xlim(*xlims)g.ax_joint.set_ylim(*ylims)g.plot_marginals(sns. histplot, element="step", color="#03012d")if title:g.ax_joint.set_title(title)plt.tight_layout()# Geografische Dateien abrufenstates = geopandas.read_file('geopandas-tutorial/data/usa-states-census-2014.shp')states = states.to_crs("EPSG :4326") # GPS-Projektion# Holen Sie sich den Wohnungsdatensatz für Kaliforniendata = fetch_california_housing(as_frame=True).frame# Wir erstellen ein Modell mit kleinen Epochen für die Demo, Standard ist 200.rtf_model = REaLTabFormer(model_type="tabular",batch_size=64,epochs=10,gradient_accumulation_steps=4,logging_steps=100) # Passen Sie das angegebene Modell an. Wir reduzieren auch num_bootstrap, der Standardwert ist 500.rtf_model.fit(data, num_bootstrap=10)# Speichern Sie das trainierte Modellrtf_model.save("rtf_model/")# Beispiel-Rohdaten ohne Validatorenamples_raw = rtf_model.sample(n_samples=10240, gen_batch= 512)# Beispieldaten mit dem geografischen Validatorobs_validator = rtf_val.ObservationValidator()obs_validator.add_validator("geo_validator",rtf_val.GeoValidator(MultiPolygon(states[states['NAME'] == 'California'].geometry[0])),
(„Längengrad“, „Breitengrad“)
)samples_validated = rtf_model.sample(n_samples=10240, gen_batch=512,validator=obs_validator,
)# Visualisieren Sie die Probenplot_sf(data, Samples_raw, title="Rohproben")plot_sf(data, Samples_validated, Title="Validierte Proben")Bitte zitieren Sie unsere Arbeit, wenn Sie den REaLTabFormer in Ihren Projekten oder Forschungsarbeiten verwenden.
@article{solatorio2023realtabformer, title={REaLTabFormer: Generating Realistic Relational and Tabular Data using Transformers}, Autor={Solatorio, Aivin V. und Dupriez, Olivier}, Journal={arXiv preprint arXiv:2302.02041}, Jahr={2023}}Wir danken dem Joint Data Center on Forced Displacement (JDC) der Weltbank und des UNHCR für die Finanzierung des Projekts „Enhancing Responsible Microdata Access to Improve Policy and Response in Forced Displacement Situations“ (KP-P174174-GINP-TF0B5124). Ein Teil des Fonds floss in die Unterstützung der Entwicklung des REaLTabFormer-Frameworks, das zur Generierung der synthetischen Population für die Erforschung des Offenlegungsrisikos und des Mosaikeffekts verwendet wurde.
Wir versenden auch ? zum HuggingFace ? für die gesamte Open-Source-Software, die sie veröffentlichen. Und an alle Open-Source-Projekte: Vielen Dank!


