DeveloperGPT
v0.7.5
DeveloperGPT ist ein LLM-basiertes Befehlszeilentool, das natürliche Sprache für Terminalbefehle und In-Terminal-Chat ermöglicht. DeveloperGPT basiert standardmäßig auf Google Gemini 1.5 Flash, unterstützt aber auch Google Gemini 1.0 Pro, OpenAI GPT-3.5 und GPT-4, Anthropic Claude 3 Haiku und Sonnet sowie offene LLMs (Zephyr, Gemma, Mistral), die auf Hugging Face gehostet und quantisiert werden Mistral-7B-Instruct läuft offline auf dem Gerät.
Ab Juni 2024 ist die Nutzung von DeveloperGPT völlig kostenlos, wenn Google Gemini 1.5 Pro (standardmäßig verwendet) oder Google Gemini 1.0 Pro mit bis zu 15 Anfragen pro Minute verwendet wird.
Wechseln Sie zwischen verschiedenen LLMs mit dem Flag --model : developergpt --model [llm_name] [cmd, chat]
| Modell(e) | Quelle | Einzelheiten |
|---|---|---|
| Gemini Pro , Gemini Flash (Standard) | Google Gemini 1.0 Pro, Gemini 1.5 Flash | Kostenlos (bis zu 15 Anfragen/Min.), Google AI API-Schlüssel erforderlich |
| GPT35, GPT4 | OpenAI | Bezahlung pro Nutzung, OpenAI-API-Schlüssel erforderlich |
| Haiku, Sonett | Anthropisch (Claude 3) | Pay-per-Usage, Anthropic-API-Schlüssel erforderlich |
| Zephyr | Zephyr7B-Beta | Kostenloses, offenes LLM, Hugging Face Inference API |
| Gemma, Gemma-Basis | Gemma-1.1-7B-Instruct, Gemma-Base | Kostenloses, offenes LLM, Hugging Face Inference API |
| Mistral-Q6, Mistral-Q4 | Quantisiertes GGUF Mistral-7B-Instruct | Kostenloses, offenes LLM, OFFLINE, ON-DEVICE |
| Mistral | Mistral-7B-Instruct | Kostenloses, offenes LLM, Hugging Face Inference API |
mistral-q6 und mistral-q4 sind quantisierte GGUF-Mistral-7B-Instruct-LLMs, die lokal auf dem Gerät unter Verwendung von llama.cpp ausgeführt werden (Q6_K-quantisierte bzw. Q4_K-quantisierte Modelle). Diese LLMs können auf Maschinen ohne dedizierte GPU ausgeführt werden – weitere Details finden Sie in llama.cpp.DeveloperGPT verfügt über zwei Hauptfunktionen.
Verwendung: developergpt cmd [your natural language command request]
# Example
$ developergpt cmd list all git commits that contain the word llm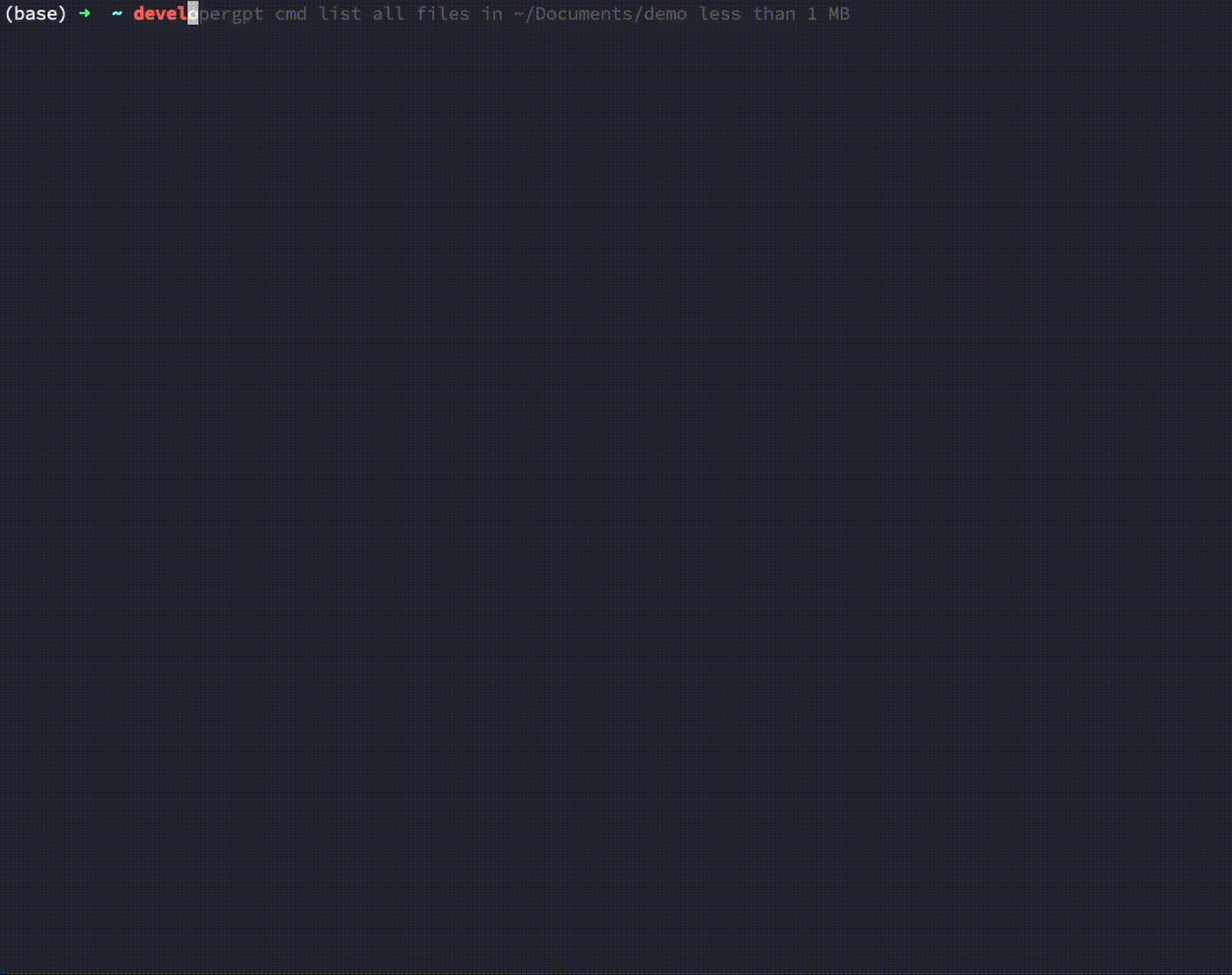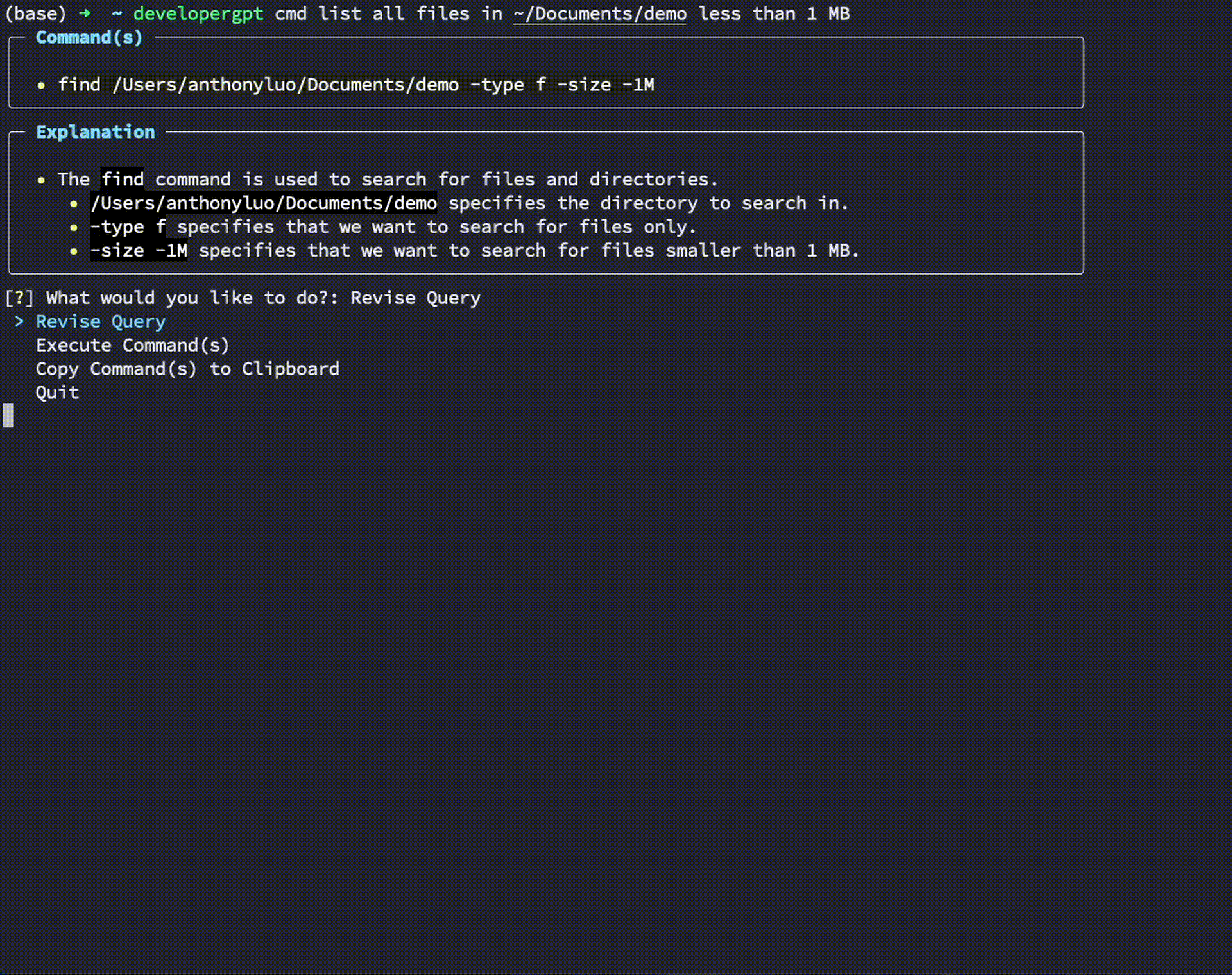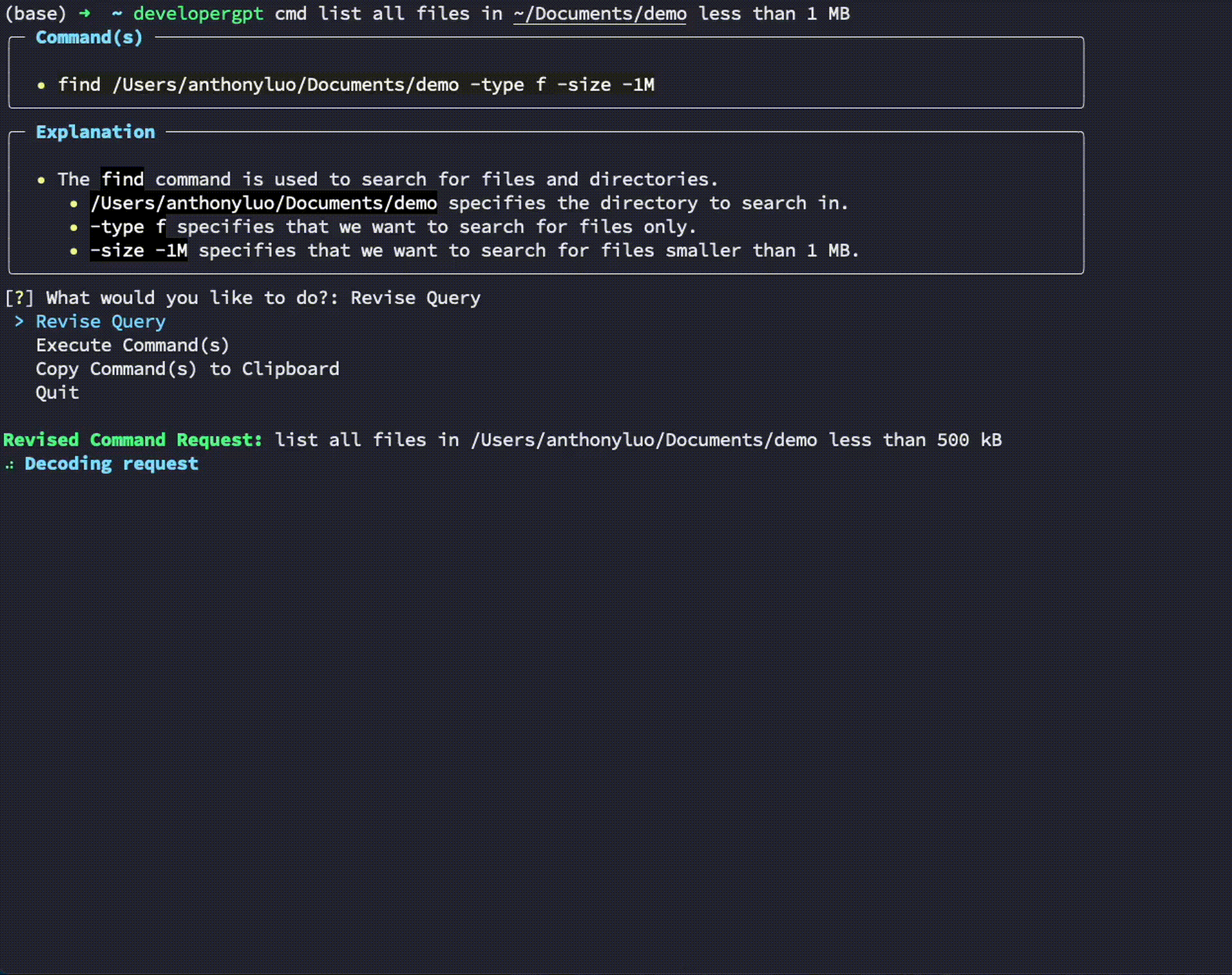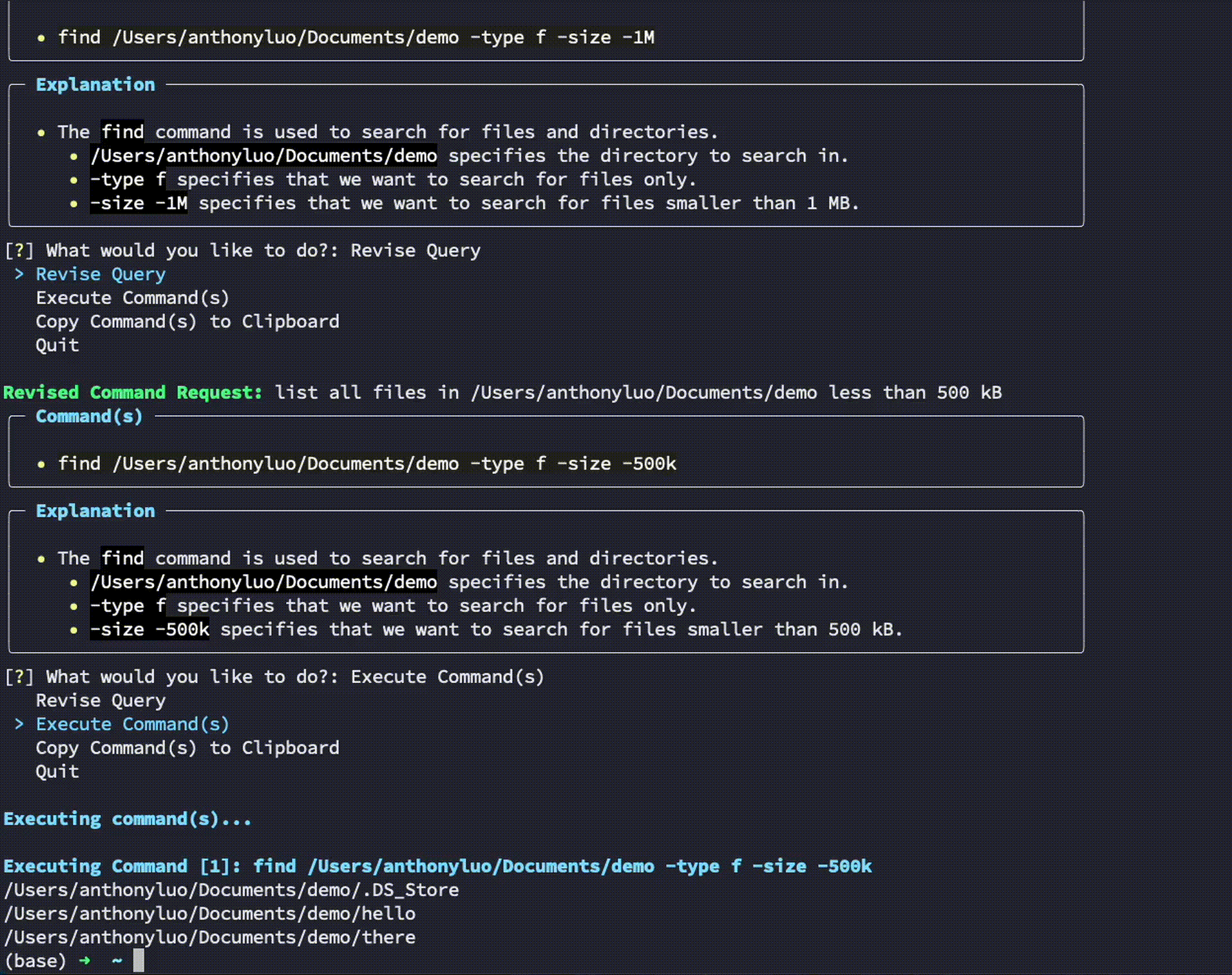
Verwenden Sie developergpt cmd --fast um Befehle ohne Erklärungen schneller abzurufen (ca. 1,6 Sekunden mit --fast vs. ca. 3,2 Sekunden mit „normal“ im Durchschnitt). Befehle, die von DeveloperGPT im Modus --fast bereitgestellt werden, sind möglicherweise weniger genau. Weitere Informationen finden Sie unter Genauigkeit von DeveloperGPT-Natürlichkeits- und Terminalbefehlen.
# Fast Mode: Commands are given without explanation for faster response
$ developergpt cmd --fast [your natural language command request] Verwenden Sie developergpt --model [model_name] cmd um ein anderes LLM anstelle von Gemini Flash (standardmäßig verwendet) zu verwenden.
# Example: Natural Language to Terminal Commands using the GPT-3.5 instead of Gemini Flash
$ developergpt --model gpt35 cmd [your natural language command request] Verwendung: developergpt chat
# Chat with DeveloperGPT using Gemini 1.5 Flash (default)
$ developergpt chat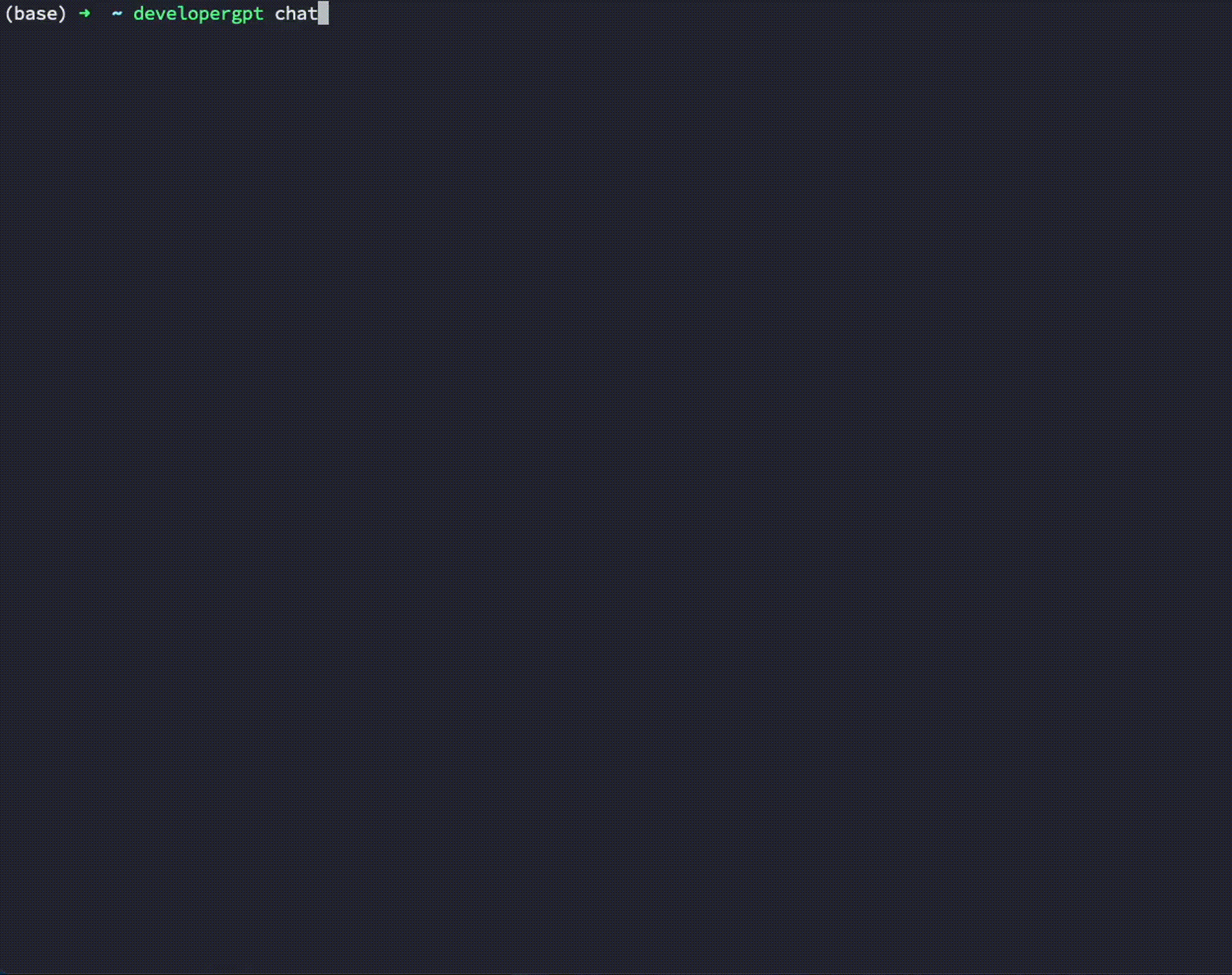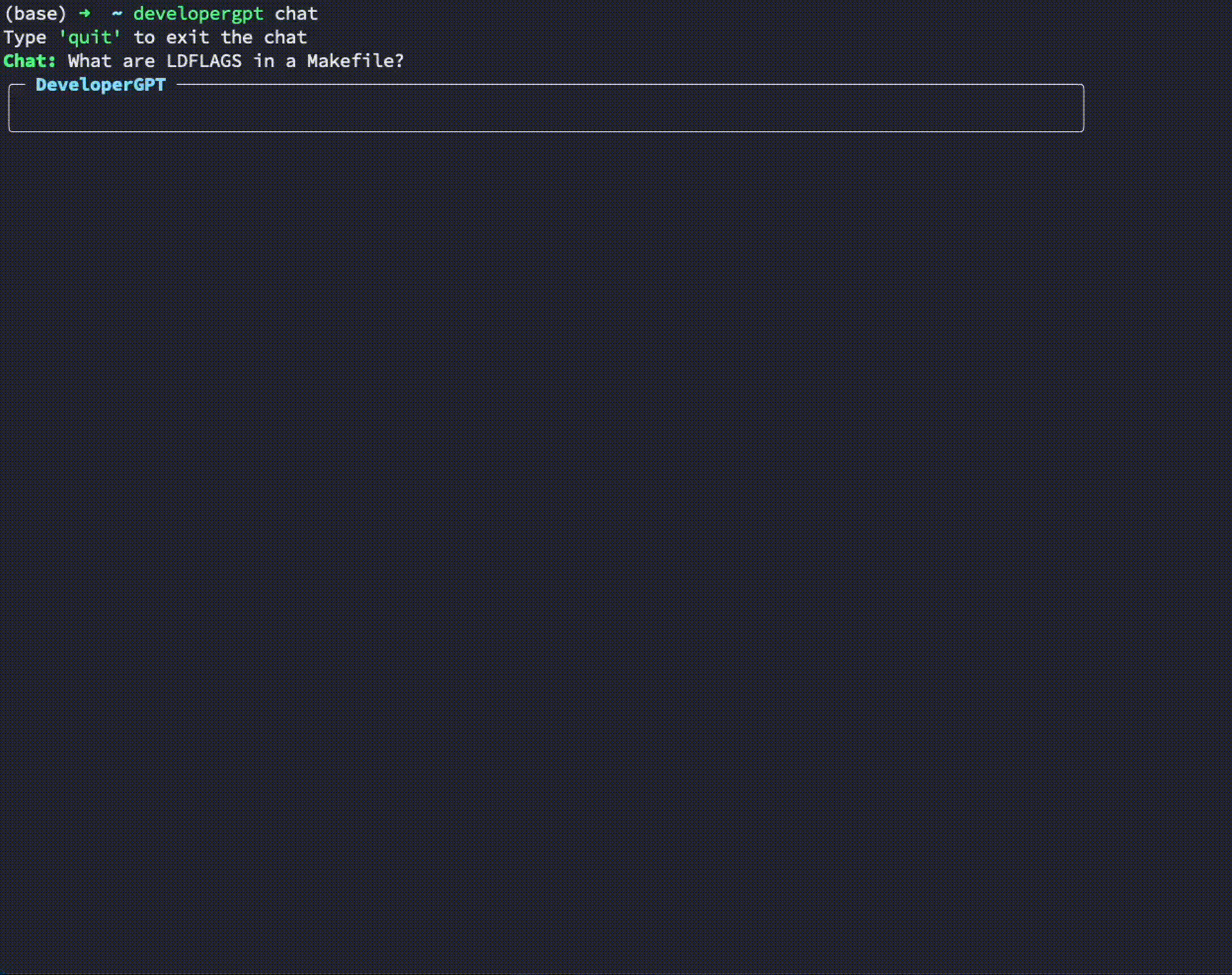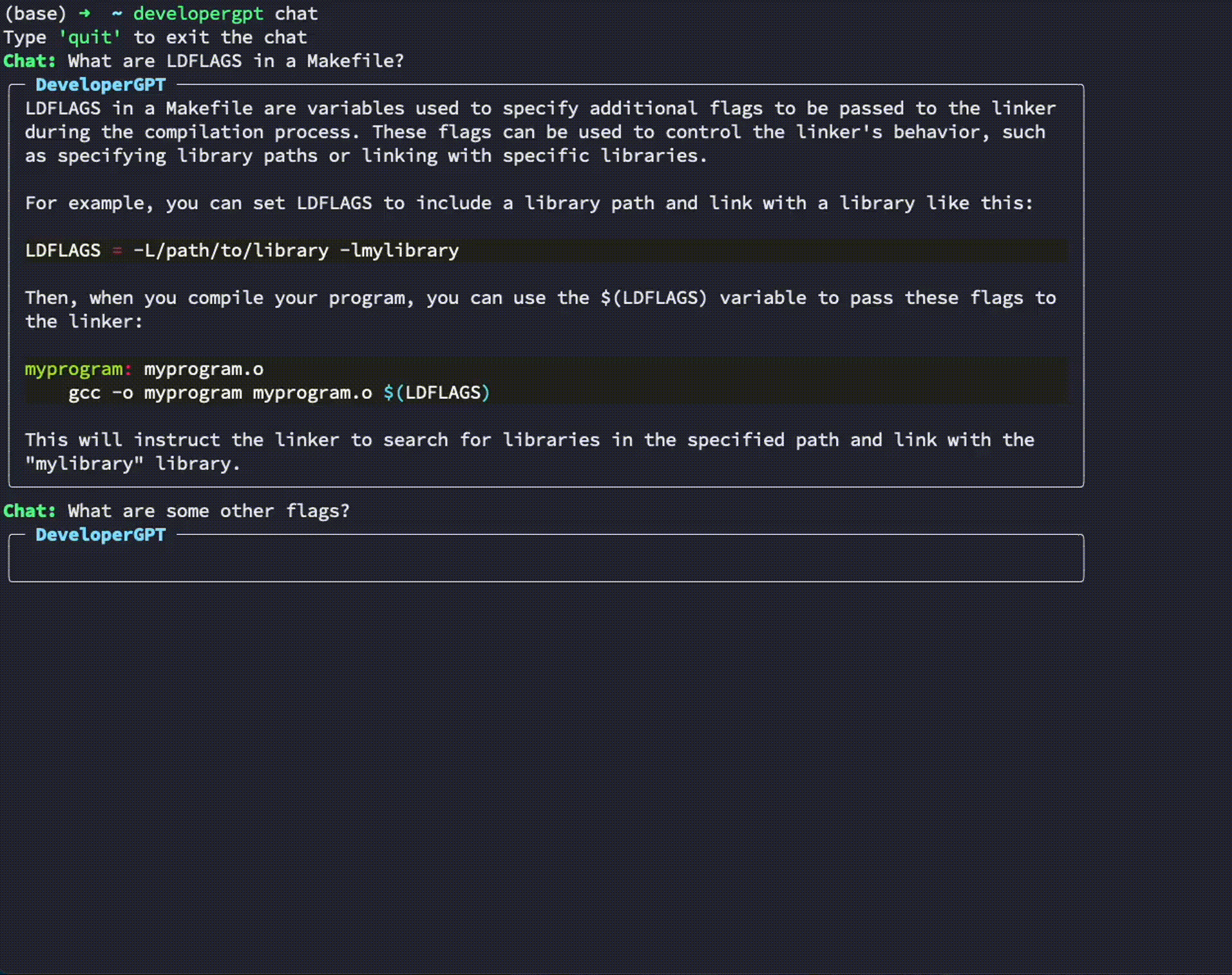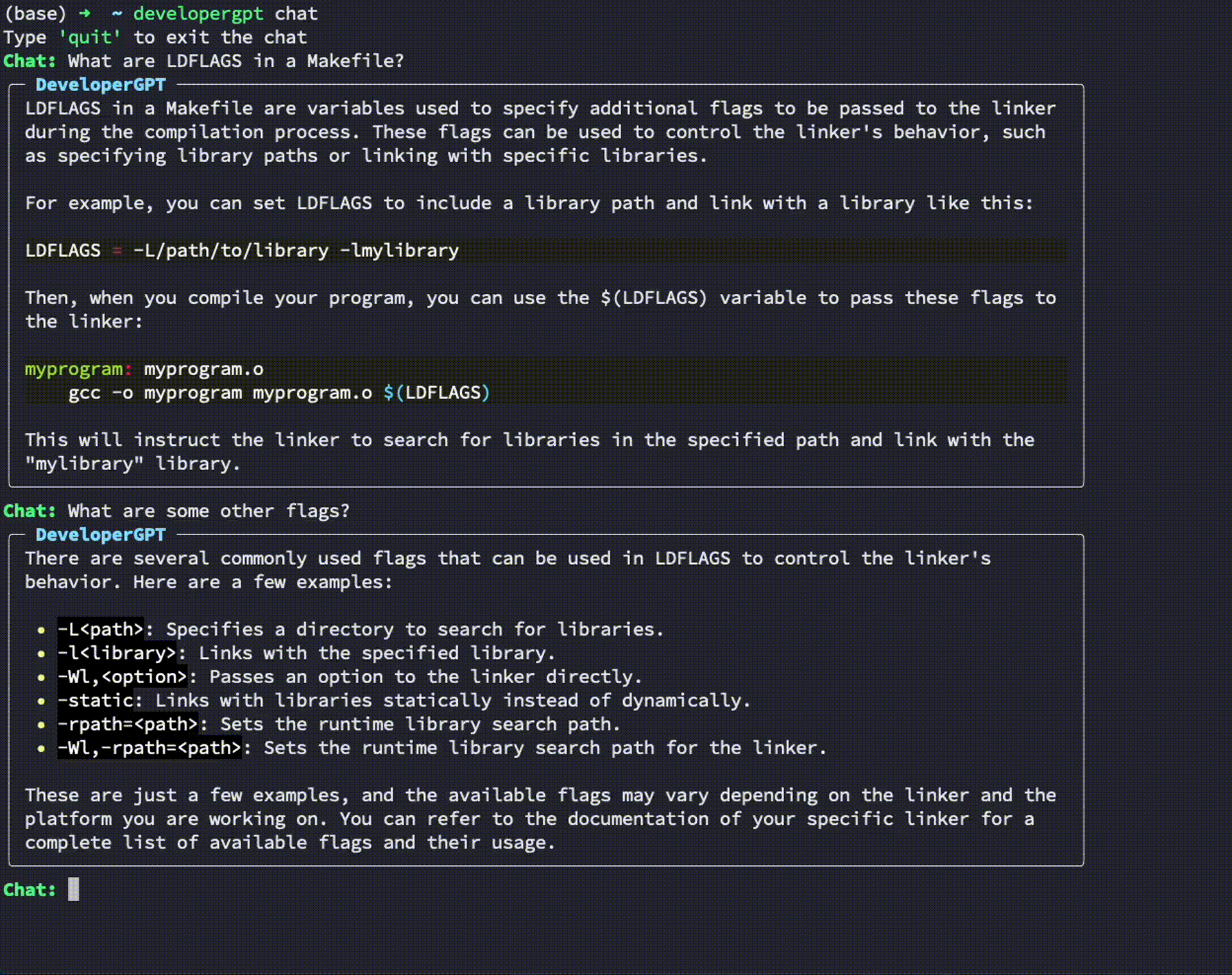
Verwenden Sie developergpt --model [model_name] chat , um ein anderes LLM zu verwenden.
# Example
$ developergpt --model mistral chatChat-Moderation ist NICHT implementiert – alle Ihre Chat-Nachrichten sollten den Nutzungsbedingungen des verwendeten LLM folgen.
DeveloperGPT darf NICHT für Zwecke verwendet werden, die durch die Nutzungsbedingungen der verwendeten LLMs verboten sind. Darüber hinaus ist DeveloperGPT selbst (abgesehen von den LLMs) ein Proof-of-Concept-Tool und nicht für ernsthafte oder kommerzielle Zwecke gedacht.
pip install -U developergpt # see available commands
$ developergpt Die Genauigkeit von DeveloperGPT variiert je nach verwendetem LLM und Modus ( --fast vs. Regular). Unten sehen Sie die Top@1-Genauigkeit verschiedener LLMs für einen Satz von 85 Befehlsanfragen in natürlicher Sprache (dies ist keine strenge Bewertung, vermittelt aber einen groben Eindruck von der Genauigkeit). Zum Vergleich ist auch Github CoPilot in der CLI v1.0.1 enthalten.
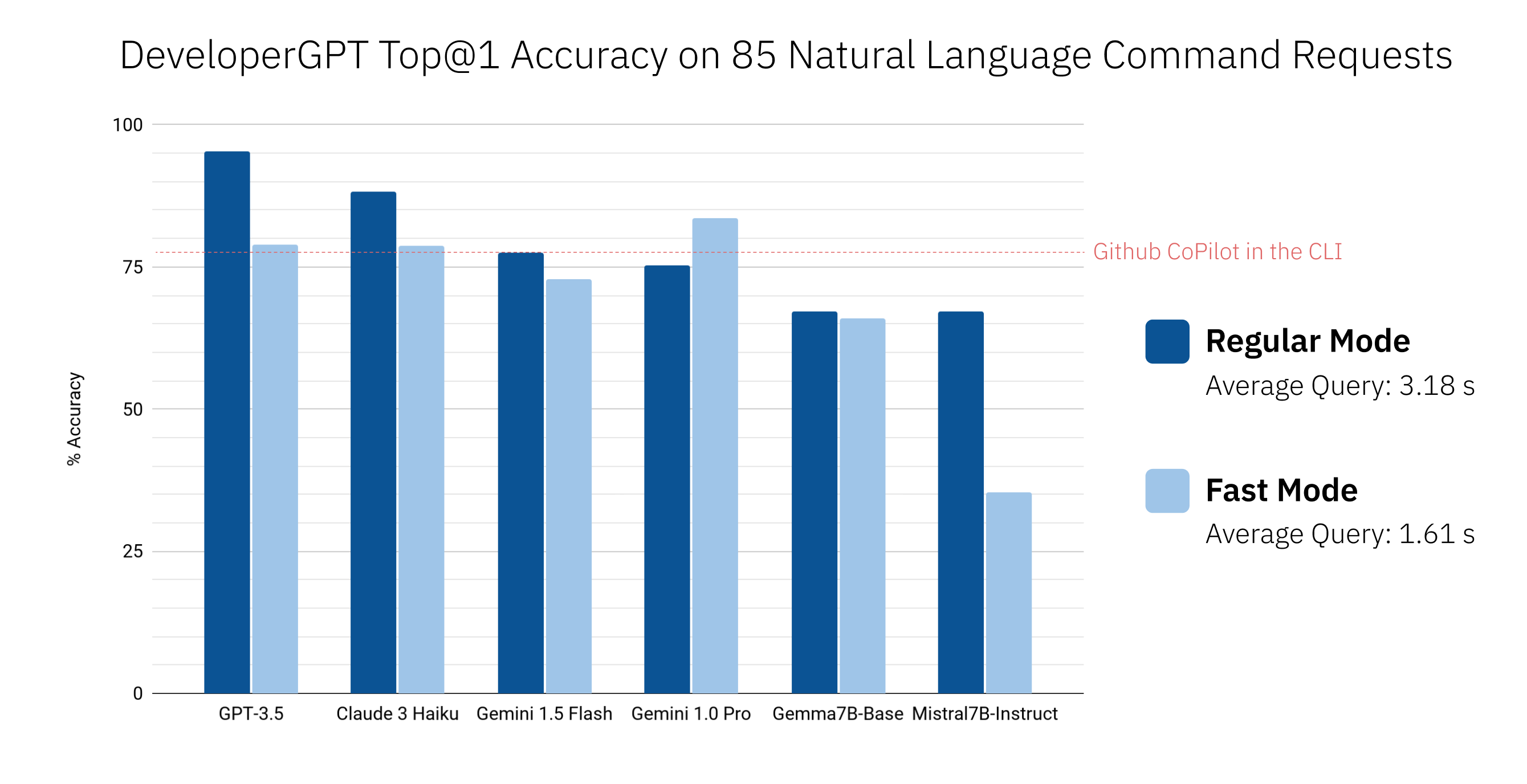
Standardmäßig verwendet DeveloperGPT Google Gemini 1.5 Flash. Um Gemini 1.0 Pro oder Gemini 1.5 Flash verwenden zu können, benötigen Sie einen API-Schlüssel (kostenlos für bis zu 15 Abfragen pro Minute).
GOOGLE_API_KEY fest. Sie müssen dies nur einmal tun. # set Google API Key (using zsh for example)
$ echo ' export GOOGLE_API_KEY=[your_key_here] ' >> ~ /.zshenv
# reload the environment (or just quit and open a new terminal)
$ source ~ /.zshenv Um offene LLMs wie Gemma oder Mistral zu verwenden, die auf Hugging Face gehostet werden, können Sie optional ein Hugging Face-Inferenz-API-Token als Umgebungsvariable HUGGING_FACE_API_KEY einrichten. Weitere Details finden Sie unter https://huggingface.co/docs/api-inference/index.
Um quantisiertes Mistral-7B-Instruct zu verwenden, führen Sie einfach DeveloperGPT mit dem Flag --offline aus. Dadurch wird das Modell beim ersten Durchlauf heruntergeladen und bei künftigen Durchläufen lokal verwendet (nach der ersten Verwendung ist keine Internetverbindung erforderlich). Es ist keine spezielle Einrichtung erforderlich.
developergpt --offline chatUm GPT-3.5 oder GPT-4 verwenden zu können, benötigen Sie einen OpenAI-API-Schlüssel.
OPENAI_API_KEY fest. Sie müssen dies nur einmal tun. Um Anthropic Claude 3 Sonnet oder Haiku nutzen zu können, benötigen Sie einen Anthropic API-Schlüssel.
ANTHROPIC_API_KEY fest. Sie müssen dies nur einmal tun.Ab Juni 2024 können Google Gemini 1.0 Pro und Gemini 1.5 Flash bis zu 15 Abfragen pro Minute kostenlos nutzen. Weitere Informationen finden Sie unter: https://ai.google.dev/pricing
Ab Juni 2024 ist die Nutzung der von der Hugging Face Inference API gehosteten LLMs kostenlos, aber preislich begrenzt. Weitere Details finden Sie unter https://huggingface.co/docs/api-inference/index.
Die Nutzung von Mistral-7B-Instruct ist kostenlos und läuft lokal auf dem Gerät.
Sie können Ihre OpenAI-API-Nutzung hier überwachen: https://platform.openai.com/account/usage. Die durchschnittlichen Kosten pro Abfrage mit GPT-3.5 betragen < 0,1 Cent. Die Verwendung von GPT-4 wird nicht empfohlen, da GPT-3.5 wesentlich kostengünstiger ist und bei den meisten Befehlen eine sehr hohe Genauigkeit erreicht.
Sie können Ihre Anthropic-API-Nutzung hier überwachen: https://console.anthropic.com/settings/plans. Die durchschnittlichen Kosten pro Anfrage mit Claude 3 Haiku betragen < 0,1 Cent. Preisdetails finden Sie unter https://www.anthropic.com/api.
Lesen Sie die Datei CONTRIBUTING.md.


