guidance for natural language queries of relational databases on aws
1.0.0
Diese AWS-Lösung enthält eine Demonstration generativer KI, insbesondere die Verwendung von Natural Language Query (NLQ), um Fragen an eine Amazon RDS für PostgreSQL-Datenbank zu stellen. Diese Lösung bietet drei Architekturoptionen für Foundation-Modelle: 1. Amazon SageMaker JumpStart, 2. Amazon Bedrock und 3. OpenAI API. Die webbasierte Anwendung der Demonstration, die auf Amazon ECS auf AWS Fargate läuft, verwendet eine Kombination aus LangChain, Streamlit, Chroma und HuggingFace SentenceTransformers. Die Anwendung akzeptiert Fragen in natürlicher Sprache von Endbenutzern und gibt Antworten in natürlicher Sprache zusammen mit der zugehörigen SQL-Abfrage und dem mit Pandas DataFrame kompatiblen Ergebnissatz zurück.
Die Auswahl des Foundation Model (FM) für Natural Language Query (NLQ) spielt eine entscheidende Rolle für die Fähigkeit der Anwendung, Fragen in natürlicher Sprache genau in Antworten in natürlicher Sprache zu übersetzen. Nicht alle FMs sind in der Lage, NLQ durchzuführen. Neben der Modellauswahl hängt die NLQ-Genauigkeit auch stark von Faktoren wie der Qualität der Eingabeaufforderung, der Eingabeaufforderungsvorlage, gekennzeichneten Beispielabfragen für kontextbezogenes Lernen ( auch Few-Shot-Eingabeaufforderung genannt ) und den für das Datenbankschema verwendeten Namenskonventionen ab , sowohl Tabellen als auch Spalten.
Die NLQ-Anwendung wurde auf verschiedenen Open-Source- und kommerziellen FMs getestet. Als Basis dienen OpenAIs Generative Pre-Trained Transformer-Modelle der GPT-3- und GPT-4-Serie, einschließlich gpt-3.5-turbo und gpt-4 , anhand eines Durchschnitts präzise Antworten auf eine Vielzahl einfacher bis komplexer natürlichsprachlicher Abfragen Umfang des kontextbezogenen Lernens und minimales Prompt-Engineering.
Auch Amazon Titan Text G1 – Express, amazon.titan-text-express-v1 , erhältlich über Amazon Bedrock, wurde getestet. Dieses Modell lieferte mithilfe einiger modellspezifischer Eingabeaufforderungsoptimierung genaue Antworten auf grundlegende Abfragen in natürlicher Sprache. Allerdings war dieses Modell nicht in der Lage, auf komplexere Anfragen zu reagieren. Eine weitere zeitnahe Optimierung könnte die Modellgenauigkeit verbessern.
Open-Source-Modelle wie google/flan-t5-xxl und google/flan-t5-xxl-fp16 (Halbpräzisions-Gleitkommaformat-Version (FP16) des vollständigen Modells) sind über Amazon SageMaker JumpStart verfügbar. Während die Modellreihe google/flan-t5 eine beliebte Wahl für die Entwicklung generativer KI-Anwendungen ist, sind ihre Fähigkeiten für NLQ im Vergleich zu neueren Open-Source- und kommerziellen Modellen begrenzt. Die Demonstration google/flan-t5-xxl-fp16 ist in der Lage, grundlegende Abfragen in natürlicher Sprache mit ausreichend kontextbezogenem Lernen zu beantworten. Beim Testen gelang es jedoch häufig nicht, eine Antwort zurückzugeben oder korrekte Antworten bereitzustellen, und es kam häufig zu Zeitüberschreitungen am Endpunkt des SageMaker-Modells aufgrund von Ressourcenerschöpfung bei mittelschweren bis komplexen Abfragen.
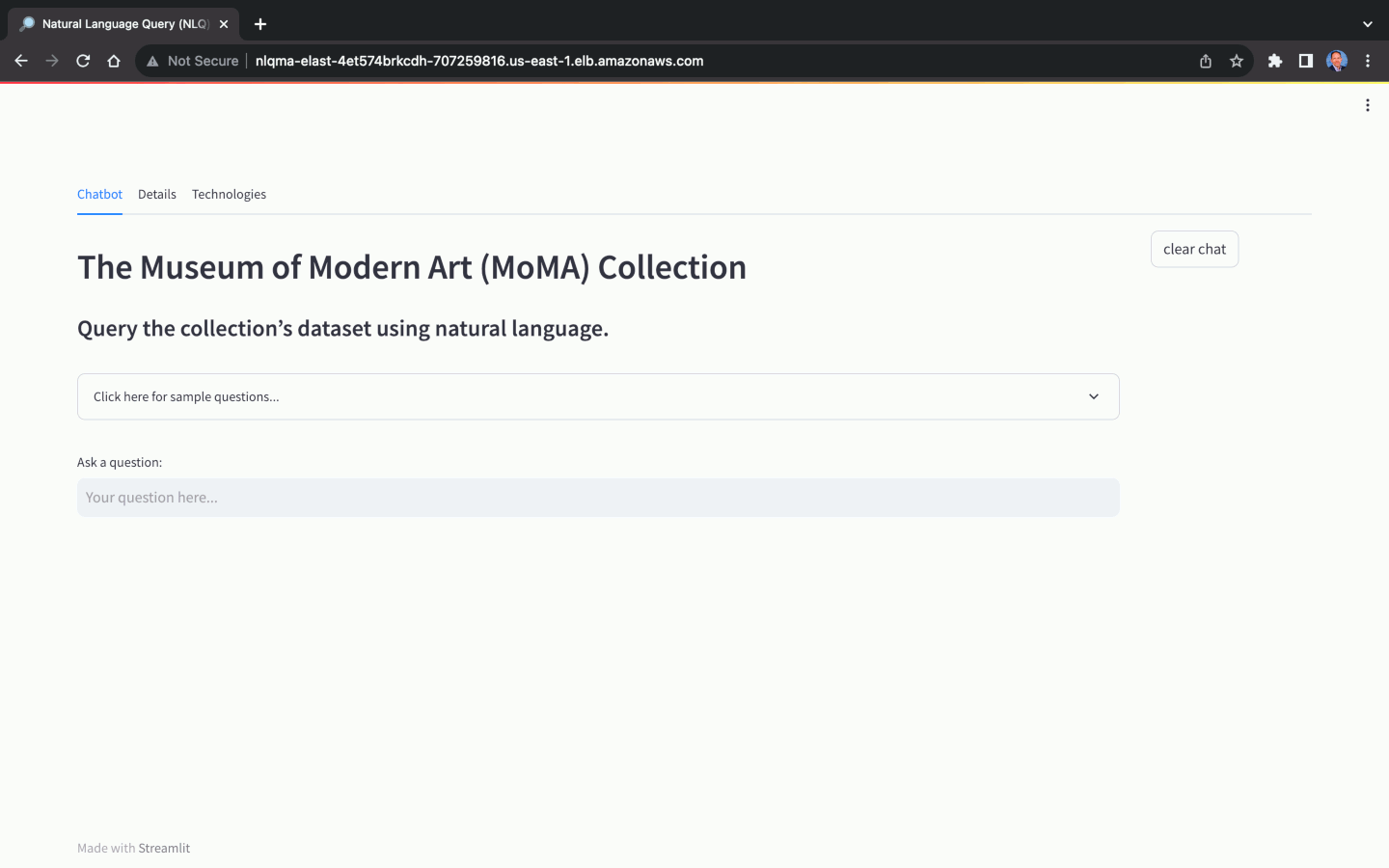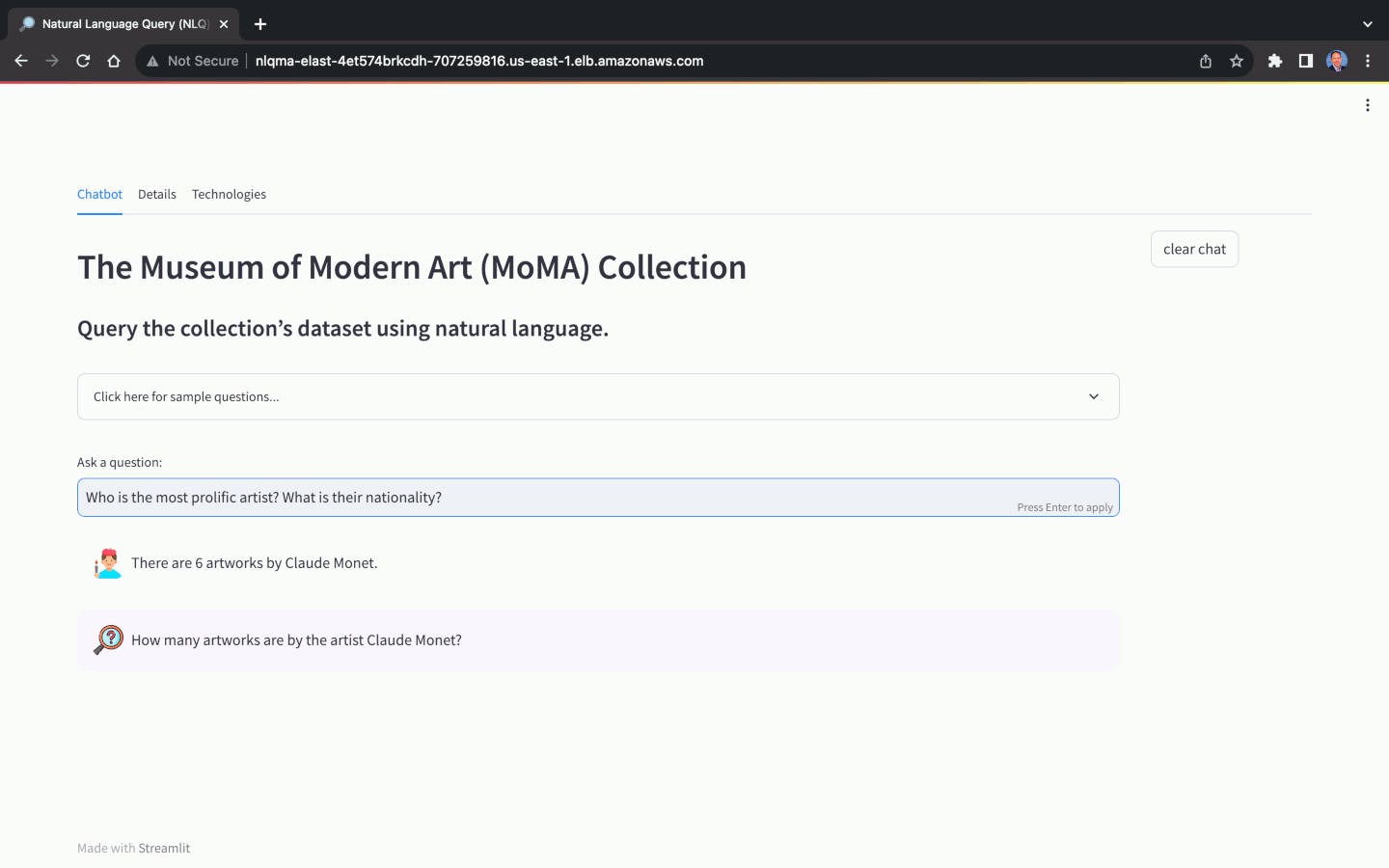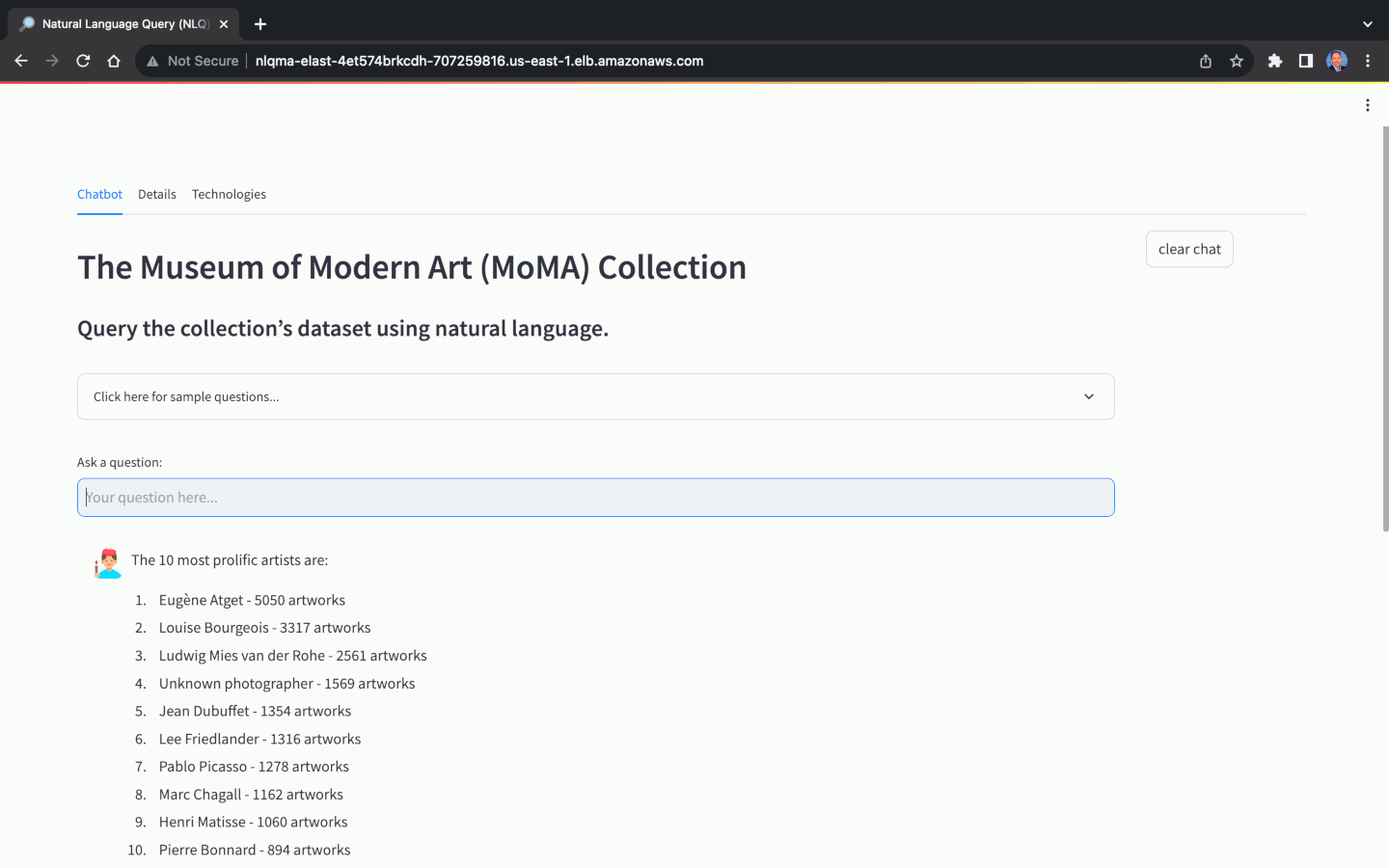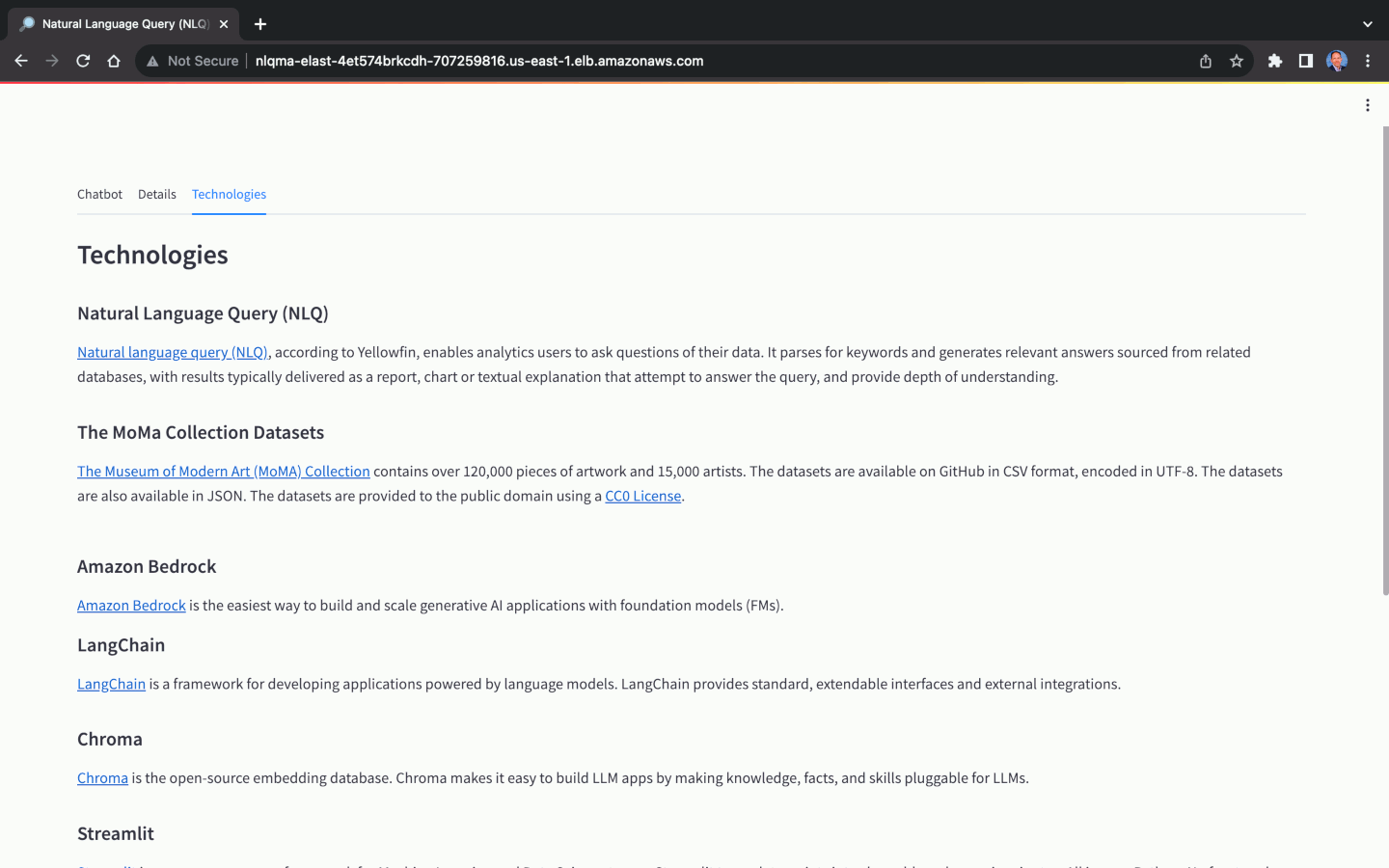
Diese Lösung verwendet eine NLQ-optimierte Kopie der Open-Source-Datenbank The Museum of Modern Art (MoMA) Collection, die auf GitHub verfügbar ist. Die MoMA-Datenbank enthält über 121.000 Kunstwerke und 15.000 Künstler. Dieses Projekt-Repository enthält durch Pipes getrennte Textdateien, die einfach in die Amazon RDS for PostgreSQL-Datenbankinstanz importiert werden können.
Mithilfe des MoMA-Datensatzes können wir Fragen in natürlicher Sprache mit unterschiedlichem Komplexitätsgrad stellen:
Auch hier hängt die Fähigkeit der NLQ-Anwendung, eine Antwort zurückzugeben und eine genaue Antwort zurückzugeben, in erster Linie von der Wahl des Modells ab. Nicht alle Modelle sind NLQ-fähig, während andere keine genauen Antworten liefern. Die Optimierung der oben genannten Eingabeaufforderungen für bestimmte Modelle kann zur Verbesserung der Genauigkeit beitragen.
ml.g5.24xlarge für google/flan-t5-xxl-fp16 -Modell). Informationen zur Auswahl der Instanztypen finden Sie in der Dokumentation des Modells.NlqMainStack CloudFormation-Vorlage bereit. Bitte beachten Sie, dass Sie Amazon ECS mindestens einmal in Ihrem Konto verwendet haben müssen, andernfalls ist die serviceverknüpfte Rolle AWSServiceRoleForECS noch nicht vorhanden und der Stack schlägt fehl. Überprüfen Sie die serviceverknüpfte Rolle AWSServiceRoleForECS , bevor Sie den NlqMainStack -Stack bereitstellen. Diese Rolle wird automatisch erstellt, wenn Sie zum ersten Mal einen ECS-Cluster in Ihrem Konto erstellen.nlq-genai:2.0.0-sm und übertragen Sie es in das neue Amazon ECR-Repository. Alternativ können Sie das Docker-Image nlq-genai:2.0.0-bedrock oder nlq-genai:2.0.0-oai für die Verwendung mit Option 2: Amazon Bedrock oder Option 3: OpenAI API erstellen und übertragen.nlqapp Benutzer zur MoMA-Datenbank hinzu.NlqSageMakerEndpointStack CloudFormation-Vorlage bereit.NlqEcsSageMakerStack CloudFormation-Vorlage bereit. Alternativ können Sie die NlqEcsBedrockStack CloudFormation-Vorlage zur Verwendung mit Option 2: Amazon Bedrock oder die NlqEcsOpenAIStack -Vorlage zur Verwendung mit Option 3: OpenAI API bereitstellen. Stellen Sie für Option 1: Amazon SageMaker JumpStart sicher, dass Sie über die erforderliche EC2-Instanz für die Amazon SageMaker JumpStart-Endpunktinferenz verfügen, oder fordern Sie sie mithilfe von Servicekontingenten in der AWS-Managementkonsole an (z. B. ml.g5.24xlarge für google/flan-t5-xxl-fp16 -Modell). Informationen zur Auswahl der Instanztypen finden Sie in der Dokumentation des Modells.
Stellen Sie sicher, dass Sie die folgenden Geheimwerte aktualisieren, bevor Sie fortfahren. In diesem Schritt werden Geheimnisse für die Anmeldeinformationen für die NLQ-Anwendung erstellt. Der Zugriff der NLQ-Anwendung auf die Datenbank ist auf Lesezugriff beschränkt. Für Option 3: OpenAI-API erstellt dieser Schritt ein Geheimnis zum Speichern Ihres OpenAI-API-Schlüssels. Master-Benutzeranmeldeinformationen für die Amazon RDS-Instanz werden automatisch festgelegt und im Rahmen der NlqMainStack CloudFormation-Vorlagenbereitstellung im AWS Secret Manager gespeichert. Diese Werte finden Sie im AWS Secret Manager.
aws secretsmanager create-secret
--name /nlq/NLQAppUsername
--description " NLQ Application username for MoMA database. "
--secret-string " <your_nlqapp_username> "
aws secretsmanager create-secret
--name /nlq/NLQAppUserPassword
--description " NLQ Application password for MoMA database. "
--secret-string " <your_nlqapp_password> "
# Only for Option 2: OpenAI API/model
aws secretsmanager create-secret
--name /nlq/OpenAIAPIKey
--description " OpenAI API key. "
--secret-string " <your_openai_api_key "Der Zugriff auf ALB und RDS wird extern auf Ihre aktuelle IP-Adresse beschränkt. Sie müssen ein Update durchführen, wenn sich Ihre IP-Adresse nach der Bereitstellung ändert.
cd cloudformation/
aws cloudformation create-stack
--stack-name NlqMainStack
--template-body file://NlqMainStack.yaml
--capabilities CAPABILITY_NAMED_IAM
--parameters ParameterKey= " MyIpAddress " ,ParameterValue= $( curl -s http://checkip.amazonaws.com/ ) /32Erstellen Sie das/die Docker-Image(s) für die NLQ-Anwendung basierend auf den von Ihnen gewählten Modelloptionen. Sie können die Docker-Image(s) lokal, in einer CI/CD-Pipeline, mithilfe der SageMaker Notebook-Umgebung oder AWS Cloud9 erstellen. Ich bevorzuge AWS Cloud9 zum Entwickeln und Testen der Anwendung und zum Erstellen der Docker-Images.
cd docker/
# Located in the output from the NlqMlStack CloudFormation template
# e.g. 111222333444.dkr.ecr.us-east-1.amazonaws.com/nlq-genai
ECS_REPOSITORY= " <you_ecr_repository> "
aws ecr get-login-password --region us-east-1 |
docker login --username AWS --password-stdin $ECS_REPOSITORYOption 1: Amazon SageMaker JumpStart
TAG= " 2.0.0-sm "
docker build -f Dockerfile_SageMaker -t $ECS_REPOSITORY : $TAG .
docker push $ECS_REPOSITORY : $TAGOption 2: Amazonas-Grundgestein
TAG= " 2.0.0-bedrock "
docker build -f Dockerfile_Bedrock -t $ECS_REPOSITORY : $TAG .
docker push $ECS_REPOSITORY : $TAGOption 3: OpenAI-API
TAG= " 2.0.0-oai "
docker build -f Dockerfile_OpenAI -t $ECS_REPOSITORY : $TAG .
docker push $ECS_REPOSITORY : $TAG 5a. Stellen Sie mit Ihrem bevorzugten PostgreSQL-Tool eine Verbindung zur moma -Datenbank her. Abhängig davon, wie Sie eine Verbindung zur Datenbank herstellen, müssen Sie vorübergehend Public access für die RDS-Instanz aktivieren.
5b. Erstellen Sie die beiden MoMA-Sammlungstabellen in der moma Datenbank.
CREATE TABLE public .artists
(
artist_id integer NOT NULL ,
full_name character varying ( 200 ),
nationality character varying ( 50 ),
gender character varying ( 25 ),
birth_year integer ,
death_year integer ,
CONSTRAINT artists_pk PRIMARY KEY (artist_id)
)
CREATE TABLE public .artworks
(
artwork_id integer NOT NULL ,
title character varying ( 500 ),
artist_id integer NOT NULL ,
date integer ,
medium character varying ( 250 ),
dimensions text ,
acquisition_date text ,
credit text ,
catalogue character varying ( 250 ),
department character varying ( 250 ),
classification character varying ( 250 ),
object_number text ,
diameter_cm text ,
circumference_cm text ,
height_cm text ,
length_cm text ,
width_cm text ,
depth_cm text ,
weight_kg text ,
durations integer ,
CONSTRAINT artworks_pk PRIMARY KEY (artwork_id)
) 5c. Entpacken Sie die beiden Datendateien und importieren Sie sie mithilfe der Textdateien im Unterverzeichnis /data in die moma -Datenbank. Beide Dateien enthalten eine Kopfzeile und sind durch Pipes getrennt ('|').
# examples commands from pgAdmin4
--command " "\copy public.artists (artist_id, full_name, nationality, gender, birth_year, death_year) FROM 'moma_public_artists.txt' DELIMITER '|' CSV HEADER QUOTE '"' ESCAPE '''';""
--command " "\copy public.artworks (artwork_id, title, artist_id, date, medium, dimensions, acquisition_date, credit, catalogue, department, classification, object_number, diameter_cm, circumference_cm, height_cm, length_cm, width_cm, depth_cm, weight_kg, durations) FROM 'moma_public_artworks.txt' DELIMITER '|' CSV HEADER QUOTE '"' ESCAPE '''';""Erstellen Sie das schreibgeschützte Benutzerkonto für die NLQ-Anwendungsdatenbank. Aktualisieren Sie die Benutzernamen- und Kennwortwerte im SQL-Skript an drei Stellen mit den Geheimnissen, die Sie in Schritt 2 oben konfiguriert haben.
CREATE ROLE < your_nlqapp_username > WITH
LOGIN
NOSUPERUSER
NOCREATEDB
NOCREATEROLE
INHERIT
NOREPLICATION
CONNECTION LIMIT - 1
PASSWORD ' <your_nlqapp_password> ' ;
GRANT
pg_read_all_data
TO
< your_nlqapp_username > ;Option 1: Amazon SageMaker JumpStart
cd cloudformation/
aws cloudformation create-stack
--stack-name NlqSageMakerEndpointStack
--template-body file://NlqSageMakerEndpointStack.yaml
--capabilities CAPABILITY_NAMED_IAMOption 1: Amazon SageMaker JumpStart
aws cloudformation create-stack
--stack-name NlqEcsSageMakerStack
--template-body file://NlqEcsSageMakerStack.yaml
--capabilities CAPABILITY_NAMED_IAMOption 2: Amazonas-Grundgestein
aws cloudformation create-stack
--stack-name NlqEcsBedrockStack
--template-body file://NlqEcsBedrockStack.yaml
--capabilities CAPABILITY_NAMED_IAMOption 3: OpenAI-API
aws cloudformation create-stack
--stack-name NlqEcsOpenAIStack
--template-body file://NlqEcsOpenAIStack.yaml
--capabilities CAPABILITY_NAMED_IAM Sie können das standardmäßige JumpStart Foundation-Modell google/flan-t5-xxl-fp16 ersetzen, das mithilfe der CloudFormation-Vorlagendatei NlqSageMakerEndpointStack.yaml bereitgestellt wird. Sie müssen zunächst die Modellparameter in der Datei NlqSageMakerEndpointStack.yaml ändern und den bereitgestellten CloudFormation-Stack NlqSageMakerEndpointStack aktualisieren. Darüber hinaus müssen Sie Anpassungen an der NLQ-Anwendung app_sagemaker.py vornehmen und die ContentHandler -Klasse so ändern, dass sie der Antwortnutzlast des ausgewählten Modells entspricht. Erstellen Sie dann das Amazon ECR-Docker-Image neu, erhöhen Sie die Version, z. B. nlq-genai-2.0.1-sm , mithilfe der Dockerfile_SageMaker Dockerdatei und übertragen Sie es in das Amazon ECR-Repository. Zuletzt müssen Sie die bereitgestellte ECS-Aufgabe und den bereitgestellten ECS-Dienst aktualisieren, die Teil des NlqEcsSageMakerStack CloudFormation-Stacks sind.
Um vom standardmäßigen Amazon Titan Text G1 - Express ( amazon.titan-text-express-v1 ) Foundation Model der Lösung zu wechseln, müssen Sie die CloudFormation-Vorlagendatei NlqEcsBedrockStack.yaml ändern und erneut bereitstellen. Darüber hinaus müssen Sie die NLQ-Anwendung app_bedrock.py ändern. Anschließend das Amazon ECR-Docker-Image mit der Dockerfile_Bedrock Dockerdatei neu erstellen und das resultierende Image, z. B. nlq-genai-2.0.1-bedrock , in das Amazon ECR-Repository übertragen . Zuletzt müssen Sie die bereitgestellte ECS-Aufgabe und den bereitgestellten ECS-Dienst aktualisieren, die Teil des NlqEcsBedrockStack CloudFormation-Stacks sind.
Der Wechsel von der standardmäßigen OpenAI-API der Lösung zur API eines anderen Drittanbieter-Modellanbieters wie Cohere oder Anthropic ist ähnlich einfach. Um die Modelle von OpenAI nutzen zu können, müssen Sie zunächst ein OpenAI-Konto erstellen und Ihren persönlichen API-Schlüssel erhalten. Als Nächstes ändern und erstellen Sie das Amazon ECR-Docker-Image mithilfe der Dockerfile_OpenAI Dockerdatei neu und übertragen das resultierende Image, z. B. nlq-genai-2.0.1-oai , in das Amazon ECR-Repository. Abschließend ändern Sie die CloudFormation-Vorlagendatei NlqEcsOpenAIStack.yaml und stellen sie erneut bereit.
Weitere Informationen finden Sie unter BEITRAGEN.
Diese Bibliothek ist unter der MIT-0-Lizenz lizenziert. Siehe die LICENSE-Datei.


