distrifuser
v0.0.1beta0
[29. Juli 2024] DistriFusion wird in ColossalAI unterstützt!
[4. April 2024] DistriFusion wird als Highlight -Poster im CVPR 2024 ausgewählt!
[29. Februar 2024] DistriFusion wird von CVPR 2024 akzeptiert! Unser Code ist öffentlich verfügbar!
 Wir stellen DistriFusion vor, einen trainingsfreien Algorithmus zur Nutzung mehrerer GPUs, um die Inferenz von Diffusionsmodellen zu beschleunigen, ohne die Bildqualität zu beeinträchtigen. Naive Patch (Übersicht (b)) leidet unter dem Fragmentierungsproblem aufgrund der fehlenden Patch-Interaktion. Die vorgestellten Beispiele werden mit SDXL unter Verwendung eines 50-stufigen Euler-Samplers bei einer Auflösung von 1280 x 1920 generiert und die Latenz wird auf A100-GPUs gemessen.
Wir stellen DistriFusion vor, einen trainingsfreien Algorithmus zur Nutzung mehrerer GPUs, um die Inferenz von Diffusionsmodellen zu beschleunigen, ohne die Bildqualität zu beeinträchtigen. Naive Patch (Übersicht (b)) leidet unter dem Fragmentierungsproblem aufgrund der fehlenden Patch-Interaktion. Die vorgestellten Beispiele werden mit SDXL unter Verwendung eines 50-stufigen Euler-Samplers bei einer Auflösung von 1280 x 1920 generiert und die Latenz wird auf A100-GPUs gemessen.
DistriFusion: Verteilte parallele Inferenz für hochauflösende Diffusionsmodelle
Muyang Li*, Tianle Cai*, Jiaxin Cao, Qinsheng Zhang, Han Cai, Junjie Bai, Yangqing Jia, Ming-Yu Liu, Kai Li und Song Han
MIT, Princeton, Lepton AI und NVIDIA
Im CVPR 2024.
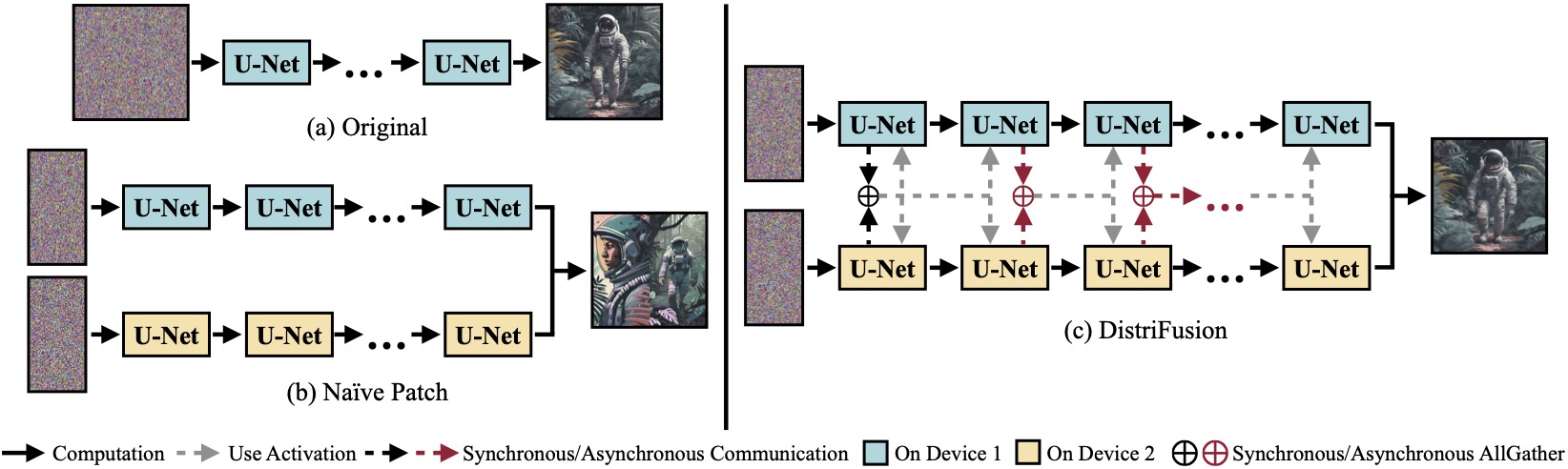 (a) Ursprüngliches Diffusionsmodell, das auf einem einzelnen Gerät ausgeführt wird. (b) Die naive Aufteilung des Bildes in zwei Patches auf zwei GPUs führt zu einer offensichtlichen Naht an der Grenze, da keine Interaktion zwischen den Patches stattfindet. (c) Unsere DistriFusion nutzt im ersten Schritt synchrone Kommunikation für die Patch-Interaktion. Danach verwenden wir die Aktivierungen aus dem vorherigen Schritt über asynchrone Kommunikation wieder. Auf diese Weise kann der Kommunikationsaufwand in der Berechnungspipeline ausgeblendet werden.
(a) Ursprüngliches Diffusionsmodell, das auf einem einzelnen Gerät ausgeführt wird. (b) Die naive Aufteilung des Bildes in zwei Patches auf zwei GPUs führt zu einer offensichtlichen Naht an der Grenze, da keine Interaktion zwischen den Patches stattfindet. (c) Unsere DistriFusion nutzt im ersten Schritt synchrone Kommunikation für die Patch-Interaktion. Danach verwenden wir die Aktivierungen aus dem vorherigen Schritt über asynchrone Kommunikation wieder. Auf diese Weise kann der Kommunikationsaufwand in der Berechnungspipeline ausgeblendet werden.
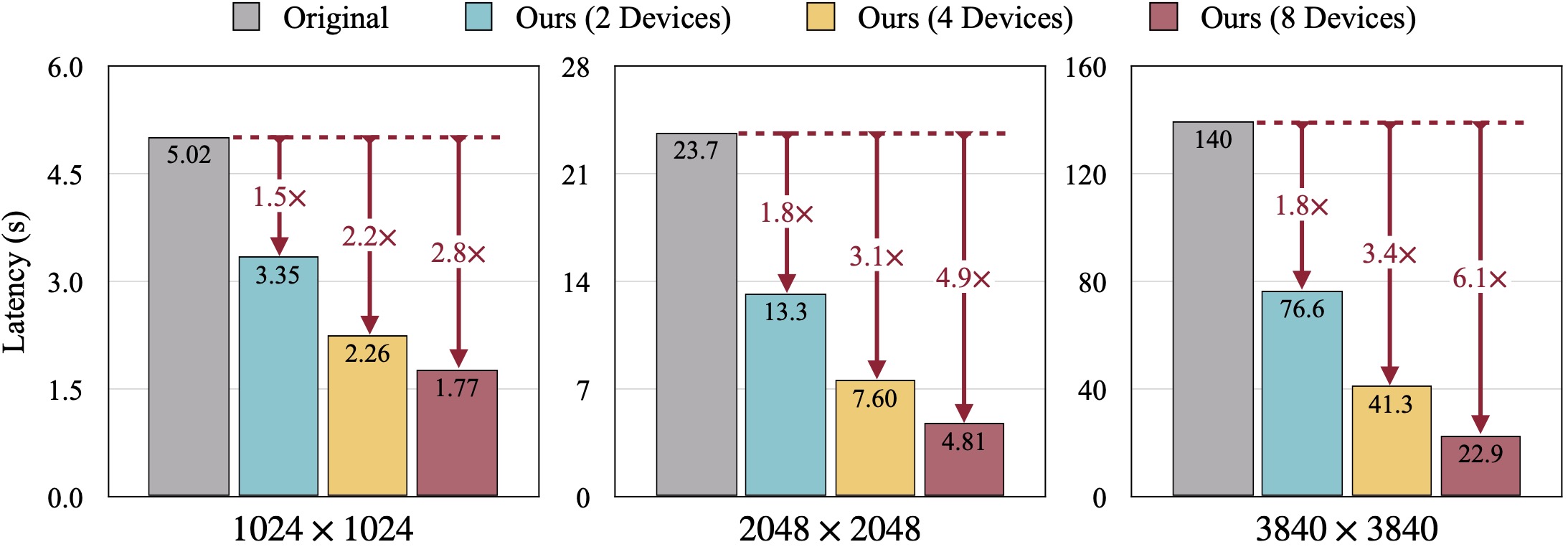
 Qualitative Ergebnisse von SDXL. Der FID wird anhand der Ground-Truth-Bilder berechnet. Unsere DistriFusion kann die Latenz entsprechend der Anzahl der verwendeten Geräte reduzieren und gleichzeitig die visuelle Wiedergabetreue bewahren.
Qualitative Ergebnisse von SDXL. Der FID wird anhand der Ground-Truth-Bilder berechnet. Unsere DistriFusion kann die Latenz entsprechend der Anzahl der verwendeten Geräte reduzieren und gleichzeitig die visuelle Wiedergabetreue bewahren.
Referenzen:
Nach der Installation von PyTorch sollten Sie in der Lage sein, distrifuser mit PyPI zu installieren
pip install distrifuseroder über GitHub:
pip install git+https://github.com/mit-han-lab/distrifuser.gitoder lokal für die Entwicklung
git clone [email protected]:mit-han-lab/distrifuser.git
cd distrifuser
pip install -e . In scripts/sdxl_example.py stellen wir ein minimales Skript zum Ausführen von SDXL mit DistriFusion bereit.
import torch
from distrifuser . pipelines import DistriSDXLPipeline
from distrifuser . utils import DistriConfig
distri_config = DistriConfig ( height = 1024 , width = 1024 , warmup_steps = 4 )
pipeline = DistriSDXLPipeline . from_pretrained (
distri_config = distri_config ,
pretrained_model_name_or_path = "stabilityai/stable-diffusion-xl-base-1.0" ,
variant = "fp16" ,
use_safetensors = True ,
)
pipeline . set_progress_bar_config ( disable = distri_config . rank != 0 )
image = pipeline (
prompt = "Astronaut in a jungle, cold color palette, muted colors, detailed, 8k" ,
generator = torch . Generator ( device = "cuda" ). manual_seed ( 233 ),
). images [ 0 ]
if distri_config . rank == 0 :
image . save ( "astronaut.png" ) Insbesondere verfügt unser distrifuser über dieselben APIs wie Diffusoren und kann auf ähnliche Weise verwendet werden. Sie müssen lediglich eine DistriConfig definieren und unsere umschlossene DistriSDXLPipeline verwenden, um das vorab trainierte SDXL-Modell zu laden. Dann können wir das Bild wie die StableDiffusionXLPipeline in Diffusoren erzeugen. Der laufende Befehl lautet
torchrun --nproc_per_node= $N_GPUS scripts/sdxl_example.py Dabei ist $N_GPUS die Anzahl der GPUs, die Sie verwenden möchten.
Wir stellen auch ein minimales Skript zum Ausführen von SD1.4/2 mit DistriFusion in scripts/sd_example.py bereit. Die Verwendung ist die gleiche.
Unsere Benchmark-Ergebnisse verwenden PyTorch 2.2 und Diffuser 0.24.0. Zunächst müssen Sie möglicherweise einige zusätzliche Abhängigkeiten installieren:
pip install git+https://github.com/zhijian-liu/torchprofile datasets torchmetrics dominate clean-fid Sie können scripts/generate_coco.py verwenden, um Bilder mit COCO-Beschriftungen zu generieren. Der Befehl lautet
torchrun --nproc_per_node=$N_GPUS scripts/generate_coco.py --no_split_batch
Dabei ist $N_GPUS die Anzahl der GPUs, die Sie verwenden möchten. Standardmäßig werden die generierten Ergebnisse in results/coco gespeichert. Sie können es auch mit --output_root anpassen. Einige zusätzliche Argumente, die Sie möglicherweise optimieren möchten:
--num_inference_steps : Die Anzahl der Inferenzschritte. Wir verwenden standardmäßig 50.--guidance_scale : Die klassifikatorfreie Orientierungsskala. Wir verwenden standardmäßig 5.--scheduler : Der Diffusionssammler. Wir verwenden standardmäßig den DDIM-Sampler. Sie können auch euler für den Euler-Sampler und dpm-solver für den DPM-Solver verwenden.--warmup_steps : Die Anzahl zusätzlicher Aufwärmschritte (standardmäßig 4).--sync_mode : Verschiedene GroupNorm-Synchronisierungsmodi. Standardmäßig wird unsere korrigierte asynchrone GroupNorm verwendet.--parallelism : Das von Ihnen verwendete Parallelitätsparadigma. Standardmäßig handelt es sich um Patch-Parallelität. Sie können tensor für Tensorparallelität und naive_patch für naiven Patch verwenden. Nachdem Sie alle Bilder generiert haben, können Sie unser Skript scripts/compute_metrics.py verwenden, um PSNR, LPIPS und FID zu berechnen. Die Verwendung ist
python scripts/compute_metrics.py --input_root0 $IMAGE_ROOT0 --input_root1 $IMAGE_ROOT1 Dabei sind $IMAGE_ROOT0 und $IMAGE_ROOT1 Pfade zu den Bildordnern, die Sie vergleichen möchten. Wenn IMAGE_ROOT0 der Ground-Truth-Ordner ist, fügen Sie bitte ein Flag --is_gt zur Größenänderung hinzu. Wir stellen auch ein Skript scripts/dump_coco.py zur Verfügung, um die Ground-Truth-Bilder zu sichern.
Sie können scripts/run_sdxl.py verwenden, um die Latenz unserer verschiedenen Methoden zu vergleichen. Der Befehl lautet
torchrun --nproc_per_node= $N_GPUS scripts/run_sdxl.py --mode benchmark --output_type latent Dabei ist $N_GPUS die Anzahl der GPUs, die Sie verwenden möchten. Ähnlich wie bei scripts/generate_coco.py können Sie auch einige Argumente ändern:
--num_inference_steps : Die Anzahl der Inferenzschritte. Wir verwenden standardmäßig 50.--image_size : Die generierte Bildgröße. Standardmäßig ist es 1024×1024.--no_split_batch : Deaktivieren Sie die Stapelaufteilung für eine klassifikatorfreie Führung.--warmup_steps : Die Anzahl zusätzlicher Aufwärmschritte (standardmäßig 4).--sync_mode : Verschiedene GroupNorm-Synchronisierungsmodi. Standardmäßig wird unsere korrigierte asynchrone GroupNorm verwendet.--parallelism : Das von Ihnen verwendete Parallelitätsparadigma. Standardmäßig handelt es sich um Patch-Parallelität. Sie können tensor für Tensorparallelität und naive_patch für naiven Patch verwenden.--warmup_times / --test_times : Die Anzahl der Aufwärm-/Testläufe. Standardmäßig sind es 5 bzw. 20. Wenn Sie diesen Code für Ihre Recherche verwenden, zitieren Sie bitte unseren Artikel.
@inproceedings { li2023distrifusion ,
title = { DistriFusion: Distributed Parallel Inference for High-Resolution Diffusion Models } ,
author = { Li, Muyang and Cai, Tianle and Cao, Jiaxin and Zhang, Qinsheng and Cai, Han and Bai, Junjie and Jia, Yangqing and Liu, Ming-Yu and Li, Kai and Han, Song } ,
booktitle = { Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) } ,
year = { 2024 }
}Unser Code basiert auf Huggingface/Diffusers und lmxyy/sige. Wir danken Torchprofile für die MACs-Messung, Clean-Fid für die FID-Berechnung und Lightning-AI/Torchmetrics für PSNR und LPIPS.
Wir danken Jun-Yan Zhu und Ligeng Zhu für ihre hilfreiche Diskussion und ihr wertvolles Feedback. Das Projekt wird vom MIT-IBM Watson AI Lab, Amazon, MIT Science Hub und der National Science Foundation unterstützt.


