Open-Source-KI-Copilot für den mühelosen Aufbau von Datenpipelines
Hauptmerkmale
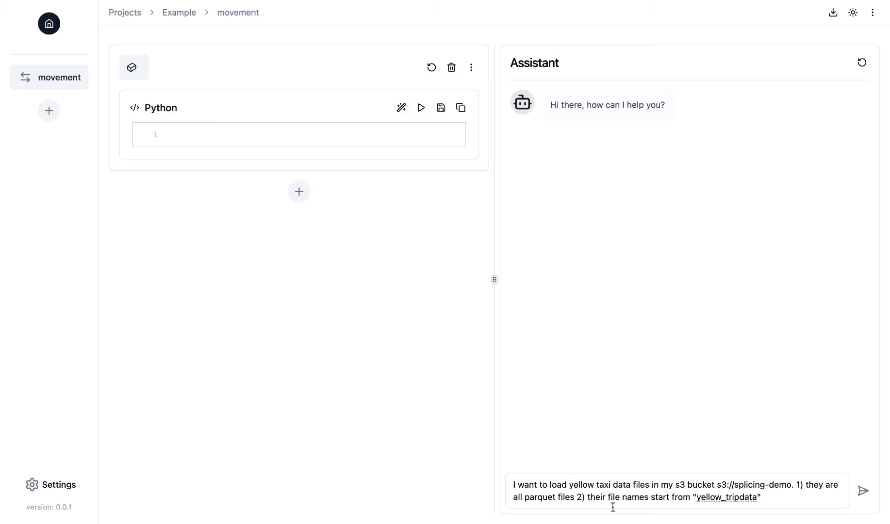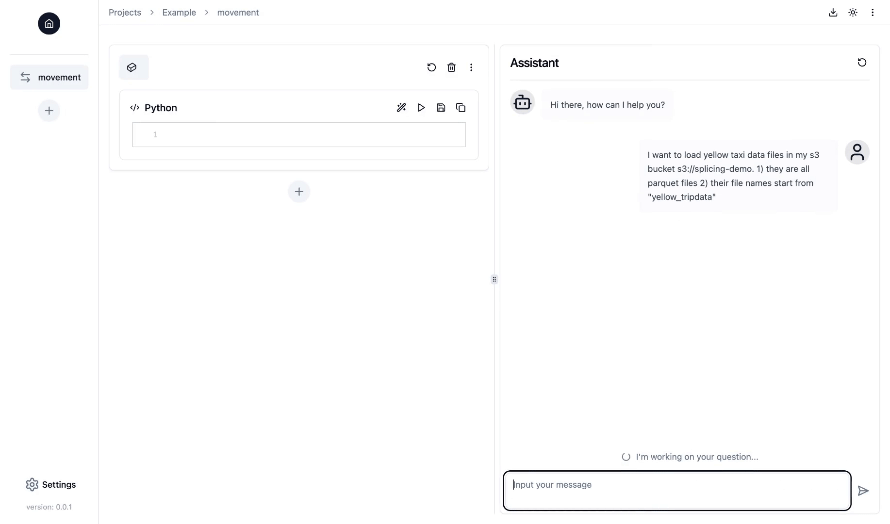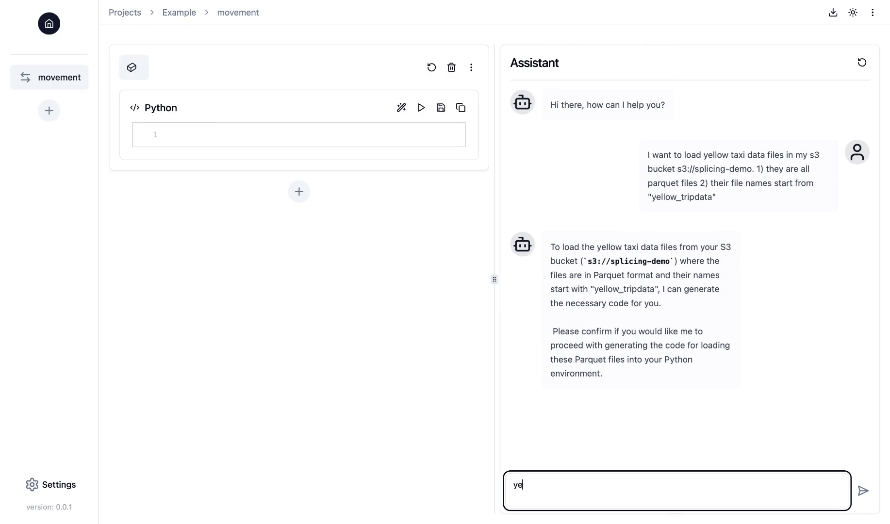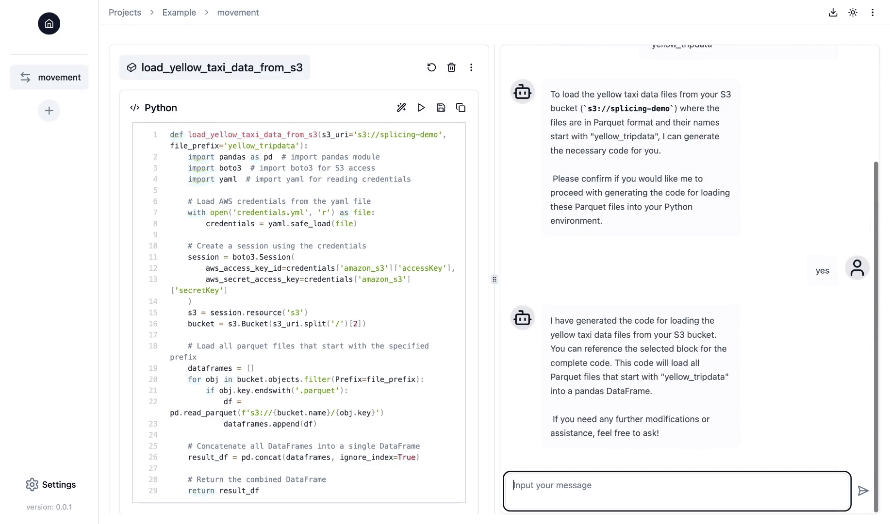
- Schnittstelle im Notebook-Stil mit Chat-Funktionen in einer Web-Benutzeroberfläche : Arbeiten Sie an Ihren Datenpipelines in einer vertrauten Jupyter-Notebook-Oberfläche, während der KI-Copilot Sie durch die Generierung, Ausführung und Fehlerbehebung von Data-Engineering-Code während des gesamten Prozesses unterstützt und anleitet.
- Keine Anbieterbindung : Erstellen Sie Ihre Datenpipelines mit einem beliebigen Datenstapel Ihrer Wahl und wählen Sie das LLM aus, das Sie für Ihren Copiloten bevorzugen, und das bei voller Flexibilität.
- Vollständig anpassbar : Teilen Sie Ihre Pipeline in mehrere Komponenten auf – z. B. Datenverschiebung, Transformation und mehr – und passen Sie jede Komponente an Ihre spezifischen Anforderungen an. Durch das Spleißen werden diese Komponenten dann nahtlos zu einer vollständigen, funktionsfähigen Datenpipeline zusammengefügt.
- Sicher und verwaltbar : Host-Splicing auf Ihrer eigenen Infrastruktur mit vollständiger Kontrolle über Ihre Daten und LLMs. Ihre Daten und geheimen Schlüssel werden zu keinem Zeitpunkt an LLM-Anbieter weitergegeben.
Schnellstart
Der einfachste Weg, Splicing auszuführen, ist in Docker:
Installieren Sie Docker.
Führen Sie den folgenden Befehl aus, um Splicing auszuführen:
docker run -v $( pwd ) /.splicing:/app/.splicing
-p 3000:3000
-p 8000:8000
-it --rm splicingai/splicing:latest
Standardmäßig werden alle Anwendungsdaten im Ordner ./.splicing im aktuellen Verzeichnis gespeichert, in dem Sie den obigen Befehl ausführen. Wenn Sie die Daten beibehalten möchten, stellen Sie sicher, dass Sie diesen Ordner sichern.
- Navigieren Sie zu http://localhost:3000/, um auf die Web-Benutzeroberfläche zuzugreifen.
Sie können Splicing auch ohne Docker für die Entwicklung installieren, indem Sie den Anweisungen im CONTRIBUTING-Leitfaden folgen.
Roadmap
- Bereitstellung von Datenpipelines : Unterstützen Sie die Bereitstellung von Datenpipelines in Ihren Produktionsumgebungen mit einem Push-to-Deploy-Erlebnis.
- Weitere Datenpipeline-Komponenten : Unterstützung für wichtigere Komponenten in Datenpipelines, wie z. B. Datenqualitätsprüfungen und Datenherkunft.
- Weitere Integrationen :
- Unterstützung für eine Vielzahl von Datenintegrationen in Datenpipelines (z. B. verschiedene Datenquellen und Warehouses).
- Unterstützen Sie mehr LLMs als Copiloten (z. B. Claude und lokale Modelle).
- Optimieren Sie die Quellcodestruktur und erleichtern Sie der Community das Hinzufügen von Integrationen.
- Intelligenterer Copilot : Erweitern Sie den Copiloten mit mehr Funktionen, z. B. der automatischen Generierung semantischer Modelle und ER-Diagramme für Daten in Lagern, wodurch der Aufbau von Datenpipelines einfacher wird.
Ressourcen
- Dokumentation
- Demo
- Gemeinschaft
Tech-Stacks
- Frontend: Next.js, Tailwind CSS und Shadcn
- Backend: FastAPI und Redis
- Agentisches Framework: LangGraph
Mitwirken
Weitere Informationen finden Sie unter CONTRIBUTING.md.
FAQs
Was sind die Hauptanwendungsfälle für Spleißen?
Splicing hilft beim Aufbau von Datenpipelines, einschließlich Aufgaben wie Datenaufnahme, -transformation und -orchestrierung, um Ihre Daten für nachgelagerte Prozesse wie Datenanalyse und maschinelles Lernen vorzubereiten.
Für wen ist Splicing geeignet?
Splicing richtet sich an Dateningenieure, Datenwissenschaftler und alle, die Datenpipelines aufbauen müssen. Selbst wenn Sie nur über begrenzte Erfahrung im Bereich Data Engineering verfügen, führt Sie der KI-Copilot von Splicing Schritt für Schritt und Sie können jederzeit in natürlicher Sprache um Hilfe bitten.
Wie unterscheidet sich Splicing von anderen Codegenerierungstools und KI-Copiloten?
Splicing ist speziell für die Datentechnik konzipiert, ein Bereich mit vielen komplexen Entscheidungen, der generative KI für die Produktivität noch nicht vollständig übernommen hat. Im Gegensatz zu generischen Tools konzentriert sich Splicing auf die Optimierung von Sprachmodellen für die in Datenpipelines üblichen festen Schritte. Es ist außerdem tief in Datenquellen und Tools integriert, sodass der Copilot den Kontext Ihres Projekts – Ihre Konfigurationen, Daten usw. – verstehen kann, was zu einer genaueren und nützlicheren Codegenerierung im Vergleich zu Allzweck-Copiloten führt.
Wie sicher ist Spleißen? Werden meine Daten weitergegeben?
Splicing ist Open Source und kann auf Ihrer eigenen Infrastruktur gehostet werden. Ihre Daten und geheimen Schlüssel werden niemals an uns oder einen LLM-Anbieter weitergegeben. Darüber hinaus führt der Splicing Copilot generierten Code nicht automatisch aus – Sie steuern, wann und wie er ausgeführt wird.
Kann ich mit Splicing erstellte Datenpipelines an anderer Stelle ausführen?
Ja! Splicing generiert Code mithilfe Ihrer bevorzugten Datenintegrationen und Tools. Sie können den Code mit einem einzigen Klick exportieren und ihn an einem beliebigen Ort ausführen oder bereitstellen. Es gibt keine Anbieterbindung.



