thumb
1.0.0
Eine einfache Prompt-Testbibliothek für LLMs.
pip install thumb
import os
import thumb
# Set your API key: https://platform.openai.com/account/api-keys
os . environ [ "OPENAI_API_KEY" ] = "YOUR_API_KEY_HERE"
# set up a prompt templates for the a/b test
prompt_a = "tell me a joke"
prompt_b = "tell me a family friendly joke"
# generate the responses
test = thumb . test ([ prompt_a , prompt_b ])Jede Eingabeaufforderung wird standardmäßig zehnmal asynchron ausgeführt, was etwa neunmal schneller ist als die sequentielle Ausführung. In Jupyter Notebooks wird eine einfache Benutzeroberfläche für Blindbewertungsantworten angezeigt (Sie sehen nicht, welche Eingabeaufforderung die Antwort generiert hat).
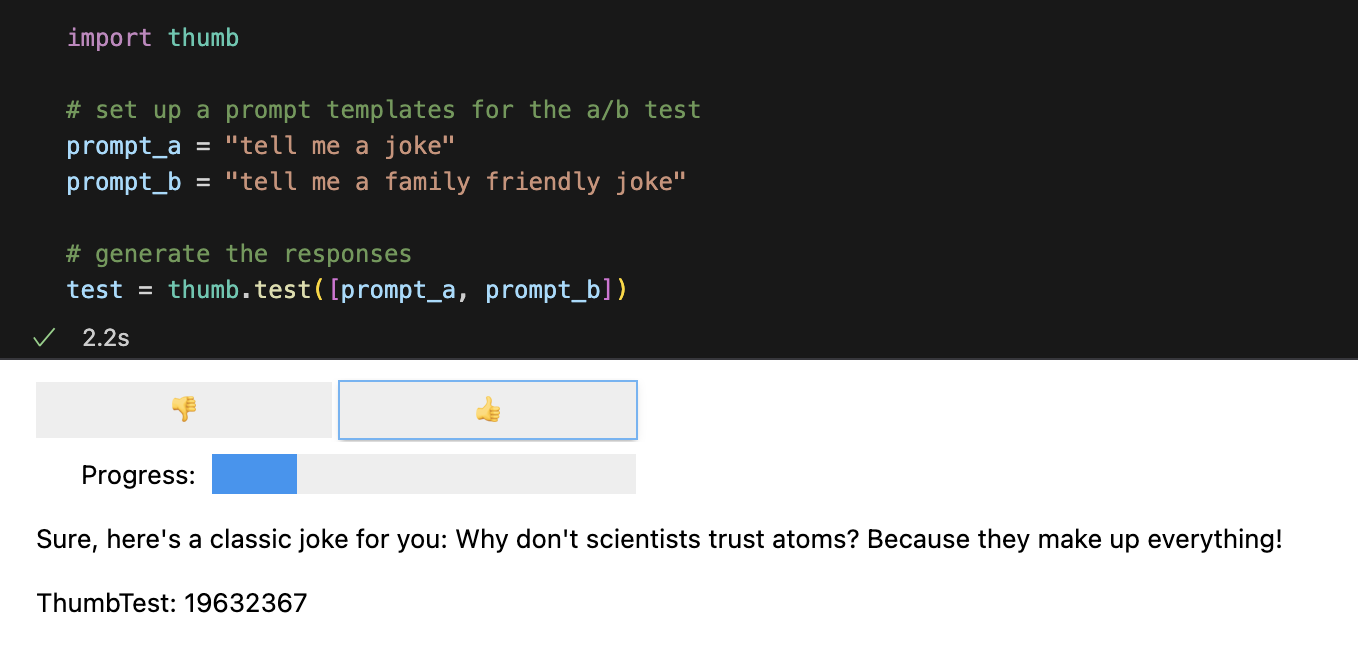
Sobald alle Antworten bewertet wurden, werden die folgenden Leistungsstatistiken berechnet, aufgeschlüsselt nach Eingabeaufforderungsvorlage:
avg_score Menge an positivem Feedback als Prozentsatz aller Läufeavg_tokens : Wie viele Token wurden in der Eingabeaufforderung und Antwort verwendet?avg_cost : eine Schätzung der durchschnittlichen Kosten für die Ausführung der Eingabeaufforderung Im Notizbuch wird ein einfacher Bericht angezeigt und die vollständigen Daten werden in der CSV-Datei thumb/ThumbTest-{TestID}.csv gespeichert.

Testfälle liegen vor, wenn Sie eine Eingabeaufforderungsvorlage mit verschiedenen Eingabevariablen testen möchten. Wenn Sie beispielsweise eine Eingabeaufforderungsvorlage testen möchten, die eine Variable für den Namen eines Komikers enthält, können Sie Testfälle für verschiedene Komiker einrichten.
# set up a prompt templates for the a/b test
prompt_a = "tell me a joke in the style of {comedian}"
prompt_b = "tell me a family friendly joke in the style of {comedian}"
# set test cases with different input variables
cases = [
{ "comedian" : "chris rock" },
{ "comedian" : "ricky gervais" },
{ "comedian" : "robin williams" }
]
# generate the responses
test = thumb . test ([ prompt_a , prompt_b ], cases )Jeder Testfall wird für jede Eingabeaufforderungsvorlage ausgeführt. In diesem Beispiel erhalten Sie also 6 Kombinationen (3 Testfälle x 2 Eingabeaufforderungsvorlagen), die jeweils 10 Mal ausgeführt werden (insgesamt 60 Aufrufe an OpenAI). Jeder Testfall muss einen Wert für jede Variable in der Eingabeaufforderungsvorlage enthalten.
Eingabeaufforderungen können in jedem Testfall mehrere Variablen haben. Wenn Sie beispielsweise eine Eingabeaufforderungsvorlage testen möchten, die eine Variable für den Namen eines Komikers und ein Witzthema enthält, können Sie Testfälle für verschiedene Komiker und Themen einrichten.
# set up a prompt templates for the a/b test
prompt_a = "tell me a joke about {subject} in the style of {comedian}"
prompt_b = "tell me a family friendly joke about {subject} in the style of {comedian}"
# set test cases with different input variables
cases = [
{ "subject" : "joe biden" , "comedian" : "chris rock" },
{ "subject" : "joe biden" , "comedian" : "ricky gervais" },
{ "subject" : "donald trump" , "comedian" : "chris rock" },
{ "subject" : "donald trump" , "comedian" : "ricky gervais" },
]
# generate the responses
test = thumb . test ([ prompt_a , prompt_b ], cases )Jeder Fall wird anhand jeder Eingabeaufforderung getestet, um einen fairen Vergleich der Leistung jeder Eingabeaufforderung bei gleichen Eingabedaten zu erhalten. Mit 4 Testfällen und 2 Eingabeaufforderungen erhalten Sie 8 Kombinationen (4 Testfälle x 2 Eingabeaufforderungsvorlagen), die jeweils 10 Mal ausgeführt werden (insgesamt 80 Aufrufe an OpenAI).
# set up a prompt templates for the a/b test
prompt_a = "tell me a joke"
prompt_b = "tell me a family friendly joke"
# generate the responses
test = thumb . test ([ prompt_a , prompt_b ], models = [ "gpt-4" , "gpt-3.5-turbo" ])Dadurch wird jede Eingabeaufforderung mit jedem Modell verglichen, um einen fairen Vergleich der Leistung jeder Eingabeaufforderung bei gleichen Eingabedaten zu erhalten. Mit 2 Eingabeaufforderungen und 2 Modellen erhalten Sie 4 Kombinationen (2 Eingabeaufforderungen x 2 Modelle), die jeweils 10 Mal ausgeführt werden (insgesamt 40 Aufrufe an OpenAI).
# set up a prompt templates for the a/b test
system_message = "You are the comedian {comedian}"
prompt_a = [ system_message , "tell me a funny joke about {subject}" ]
prompt_b = [ system_message , "tell me a hillarious joke {subject}" ]
cases = [{ "subject" : "joe biden" , "comedian" : "chris rock" },
{ "subject" : "donald trump" , "comedian" : "chris rock" }]
# generate the responses
test = thumb . test ([ prompt_a , prompt_b ], cases ) Eingabeaufforderungen können eine Zeichenfolge oder ein Array von Zeichenfolgen sein. Wenn es sich bei der Eingabeaufforderung um ein Array handelt, wird die erste Zeichenfolge als Systemnachricht verwendet, und die restlichen Eingabeaufforderungen wechseln zwischen menschlichen und Assistentennachrichten ( [system, human, ai, human, ai, ...] ). Dies ist nützlich zum Testen von Eingabeaufforderungen, die eine Systemnachricht enthalten oder die Vorwärmung verwenden (das Einfügen vorheriger Nachrichten in den Chat, um die KI zum gewünschten Verhalten zu führen).
# set up a prompt templates for the a/b test
system_message = "You are the comedian {comedian}"
prompt_a = [ system_message , # system
"tell me a funny joke about {subject}" , # human
"Sorry, as an AI language model, I am not capable of humor" , # assistant
"That's fine just try your best" ] # human
prompt_b = [ system_message , # system
"tell me a hillarious joke about {subject}" , # human
"Sorry, as an AI language model, I am not capable of humor" , # assistant
"That's fine just try your best" ] # human
cases = [{ "subject" : "joe biden" , "comedian" : "chris rock" },
{ "subject" : "donald trump" , "comedian" : "chris rock" }]
# generate the responses
test = thumb . test ([ prompt_a , prompt_b ], cases )Wenn der Test abgeschlossen ist, erhalten Sie einen vollständigen Bewertungsbericht, aufgeschlüsselt nach PID, CID und Modell, sowie einen Gesamtbericht, aufgeschlüsselt nach allen Kombinationen. Wenn Sie nur ein Modell oder ein Gehäuse testen, entfallen diese Aufschlüsselungen. Der Bericht zeigt unten einen Schlüssel an, um zu sehen, welche ID welcher Eingabeaufforderung oder welchem Fall entspricht.
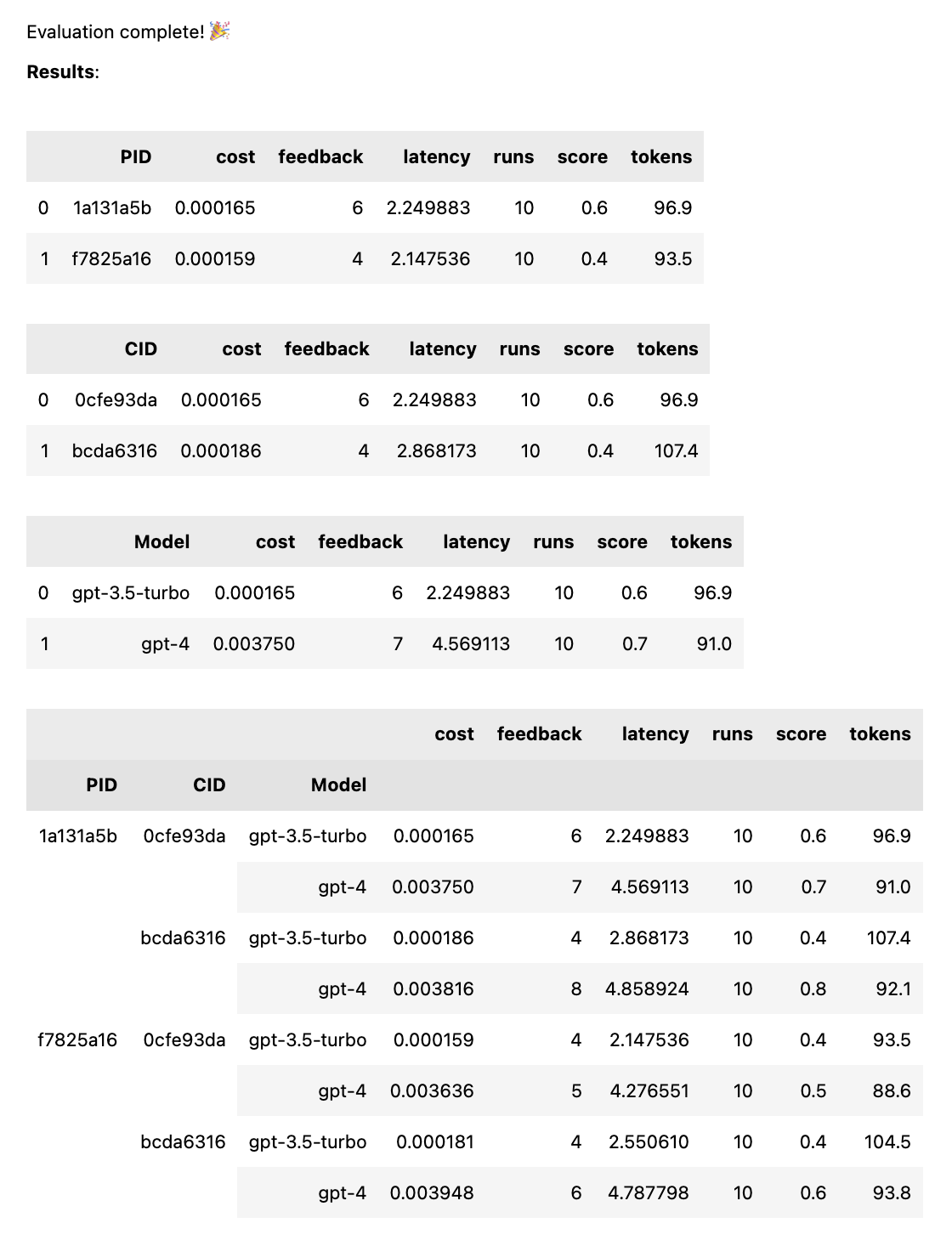
Die Funktion thumb.test übernimmt die folgenden Parameter:
None )10 )gpt-3.5-turbo ])True ) Wenn Sie 10 Testläufe mit 2 Eingabeaufforderungsvorlagen und 3 Testfällen haben, sind das 10 x 2 x 3 = 60 Aufrufe an OpenAI. Achtung: Gerade bei GPT-4 können sich die Kosten schnell summieren!
Die Langchain-Ablaufverfolgung zu LangSmith wird automatisch aktiviert, wenn LANGCHAIN_API_KEY als Umgebungsvariable festgelegt ist (optional).
Die Funktion .test() gibt ein ThumbTest Objekt zurück. Sie können dem Test weitere Eingabeaufforderungen oder Fälle hinzufügen oder ihn mehrmals ausführen. Sie können die Testdaten auch jederzeit generieren, auswerten und exportieren.
# set up a prompt templates for the a/b test
prompt_a = "tell me a joke"
prompt_b = "tell me a family friendly joke"
# generate the responses
test = thumb . test ([ prompt_a , prompt_b ])
# add more prompts
test . add_prompts ([ "tell me a knock knock joke" , "tell me a knock knock joke about {subject}" ])
# add more cases
test . add_cases ([{ "subject" : "joe biden" }, { "subject" : "donald trump" }])
# run each prompt and case 5 more times
test . add_runs ( 5 )
# generate the responses
test . generate ()
# rate the responses
test . evaluate ()
# export the test data for analysis
test . export_to_csv () Jede Eingabeaufforderungsvorlage erhält von jedem Testfall die gleichen Eingabedaten, die Eingabeaufforderung muss jedoch nicht alle Variablen im Testfall verwenden. Wie im obigen Beispiel verwendet die Eingabeaufforderung tell me a knock knock joke nicht die subject , sie wird jedoch für jeden Testfall einmal (ohne Variablen) generiert.
Testdaten werden in einer lokalen JSON-Datei „ thumb/.cache/{TestID}.json zwischengespeichert, nachdem jeder Satz von Ausführungen für eine Eingabeaufforderungs- und Fallkombination generiert wurde. Wenn Ihr Test unterbrochen wird oder Sie etwas hinzufügen möchten, können Sie die Funktion thumb.load verwenden, um die Testdaten aus dem Cache zu laden.
# load a previous test
test_id = "abcd1234" # replace with your test id
test = thumb . load ( f"thumb/.cache/ { test_id } .json" )
# run each prompt and case 2 more times
test . add_runs ( 2 )
# generate the responses
test . generate ()
# rate the responses
test . evaluate ()
# export the test data for analysis
test . export_to_csv () Jede Ausführung für jede Kombination aus Eingabeaufforderung und Fall wird im Objekt (und im Cache) gespeichert. Daher werden durch den erneuten Aufruf von test.generate() keine neuen Antworten generiert, wenn keine weiteren Eingabeaufforderungen, Fälle oder Ausführungen hinzugefügt werden. Ebenso führt ein erneuter Aufruf von test.evaluate() nicht zu einer erneuten Bewertung der Antworten, die Sie bereits bewertet haben, sondern zeigt lediglich die Ergebnisse erneut an, wenn der Test beendet ist.
Der Unterschied zwischen Leuten, die nur mit ChatGPT herumspielen, und denen, die KI in der Produktion verwenden, ist die Bewertung. LLMs reagieren nicht deterministisch, daher ist es wichtig zu testen, wie Ergebnisse aussehen, wenn sie auf eine Vielzahl von Szenarien übertragen werden. Ohne einen Bewertungsrahmen müssen Sie blind raten, was in Ihren Eingabeaufforderungen funktioniert (oder nicht).
Seriöse Prompt-Ingenieure testen und lernen, welche Eingaben zuverlässig und im großen Maßstab zu nützlichen oder gewünschten Ergebnissen führen. Dieser Vorgang wird als prompte Optimierung bezeichnet und sieht folgendermaßen aus:
Daumentests schließen die Lücke zwischen groß angelegten professionellen Bewertungsmechanismen und der blinden Eingabe durch Versuch und Irrtum. Wenn Sie eine Eingabeaufforderung in eine Produktionsumgebung überführen, kann die Verwendung thumb zum Testen Ihrer Eingabeaufforderung dabei helfen, Grenzfälle zu erkennen und frühzeitiges Benutzer- oder Team-Feedback zu den Ergebnissen zu erhalten.
Diese Leute bauen in ihrer Freizeit zum Spaß thumb . ?
hammer-mt |


