llm data annotation
1.0.0
Dieses Framework kombiniert menschliches Fachwissen mit der Effizienz von Large Language Models (LLMs) wie GPT-3.5 von OpenAI, um die Annotation von Datensätzen und die Modellverbesserung zu vereinfachen. Der iterative Ansatz gewährleistet die kontinuierliche Verbesserung der Datenqualität und damit der Leistung der anhand dieser Daten optimierten Modelle. Dies spart nicht nur Zeit, sondern ermöglicht auch die Erstellung maßgeschneiderter LLMs, die sowohl menschliche Annotatoren als auch LLM-basierte Präzision nutzen.
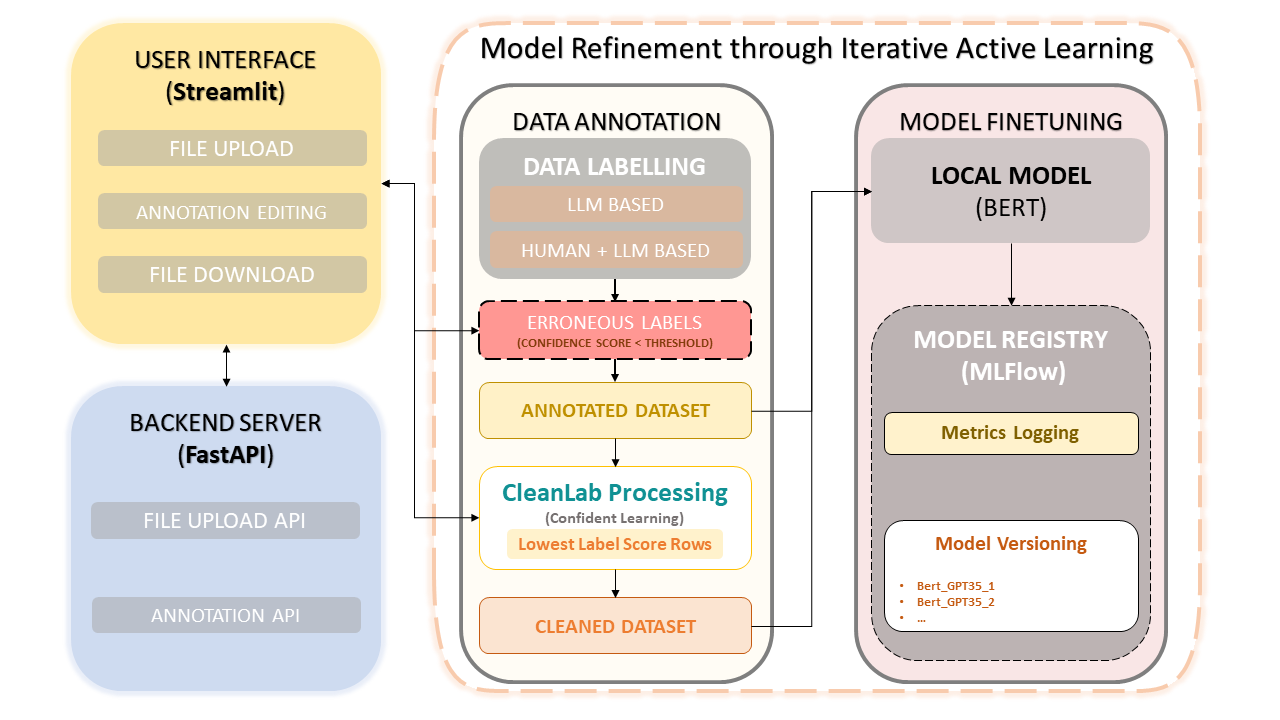
Hochladen und Kommentieren von Datensätzen
Manuelle Anmerkungskorrekturen
CleanLab: Souveräner Lernansatz
Datenversionierung und -speicherung
Modelltraining
pip install -r requirements.txtStarten Sie das FastAPI-Backend :
uvicorn app:app --reloadFühren Sie die Streamlit-App aus :
streamlit run frontend.pyStarten Sie die MLflow-Benutzeroberfläche : Um Modelle, Metriken und registrierte Modelle anzuzeigen, können Sie mit dem folgenden Befehl auf die MLflow-Benutzeroberfläche zugreifen:
mlflow uiGreifen Sie in Ihrem Webbrowser auf die bereitgestellten Links zu :
http://127.0.0.1:5000 navigieren.Befolgen Sie die Anweisungen auf dem Bildschirm, um Ihren Datensatz hochzuladen, zu kommentieren, zu korrigieren und zu trainieren.
Selbstbewusstes Lernen hat sich als bahnbrechende Technik beim überwachten Lernen und bei schwacher Aufsicht herausgestellt. Ziel ist es, Etikettenrauschen zu charakterisieren, Etikettenfehler zu finden und effizient mit verrauschten Etiketten zu lernen. Durch die Bereinigung verrauschter Daten und die Einstufung von Beispielen für ein sicheres Training gewährleistet diese Methode einen sauberen und zuverlässigen Datensatz und verbessert die Gesamtleistung des Modells.
Dieses Projekt ist Open-Source unter der MIT-Lizenz.


