Aufdecken versteckter Zusammenhänge in unstrukturierten Finanzdaten mithilfe von Amazon Bedrock und Amazon Neptune
Dieses Repository enthält Code zur Bereitstellung einer Prototyplösung, die zeigt, wie generative KI und Wissensgraphen kombiniert werden können, um ein skalierbares, ereignisgesteuertes, serverloses System zur Verarbeitung unstrukturierter Daten für Finanzdienstleistungen zu erstellen. Diese Lösung kann Vermögensverwaltern in Ihrem Unternehmen dabei helfen, versteckte Zusammenhänge in ihren Anlageportfolios aufzudecken und bietet eine beispielhafte, benutzerfreundliche Benutzeroberfläche, um Finanznachrichten zu lesen und deren Zusammenhänge mit ihren Anlageportfolios zu verstehen.
Geschäftsanwendungsfall
Vermögensverwalter investieren im Allgemeinen in eine große Anzahl von Unternehmen in ihren Portfolios und müssen in der Lage sein, alle Nachrichten zu diesen Unternehmen im Auge zu behalten, da diese Nachrichten ihnen helfen würden, den Marktbewegungen einen Schritt voraus zu sein, Investitionsmöglichkeiten zu erkennen und ihre Investitionen besser zu verwalten Portfolio.
Im Allgemeinen lässt sich die Nachverfolgung von Nachrichten problemlos durch die Einrichtung einer einfachen, auf Schlüsselwörtern basierenden Nachrichtenbenachrichtigung unter Verwendung des Namens des Beteiligungsunternehmens durchführen. Dies wird jedoch immer schwieriger, wenn das Nachrichtenereignis keine direkten Auswirkungen auf das Beteiligungsunternehmen hat. Die Auswirkungen könnten sich beispielsweise auf einen Lieferanten eines Beteiligungsunternehmens auswirken und möglicherweise die Lieferkette des Unternehmens stören. Oder die Auswirkungen könnten sich auf einen Kunden eines Kunden Ihres Beteiligungsunternehmens auswirken. Wenn diese Unternehmen ihre Umsätze auf einige wenige Schlüsselkunden konzentrieren, hätte dies möglicherweise negative finanzielle Auswirkungen auf Ihre Investition.
Solche Auswirkungen zweiter oder dritter Ordnung sind schwer zu identifizieren und noch schwieriger zu verfolgen. Mit dieser automatisierten Lösung können Vermögensverwalter einen Wissensgraphen über die Beziehungen rund um ihr Anlageportfolio erstellen und dieses Wissen dann nutzen, um Korrelationen und Erkenntnisse aus den neuesten Nachrichten zu ziehen.
Architektur
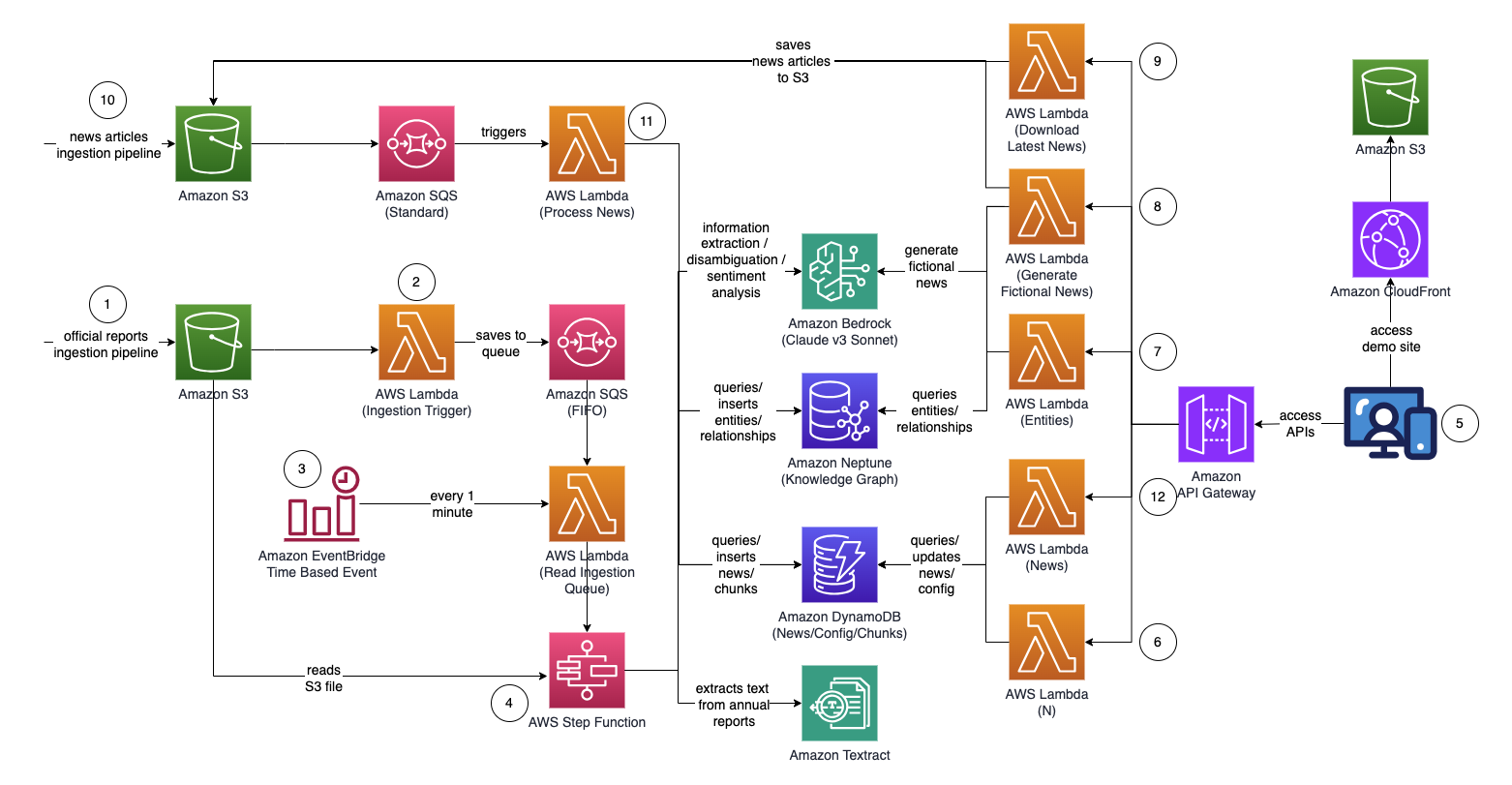
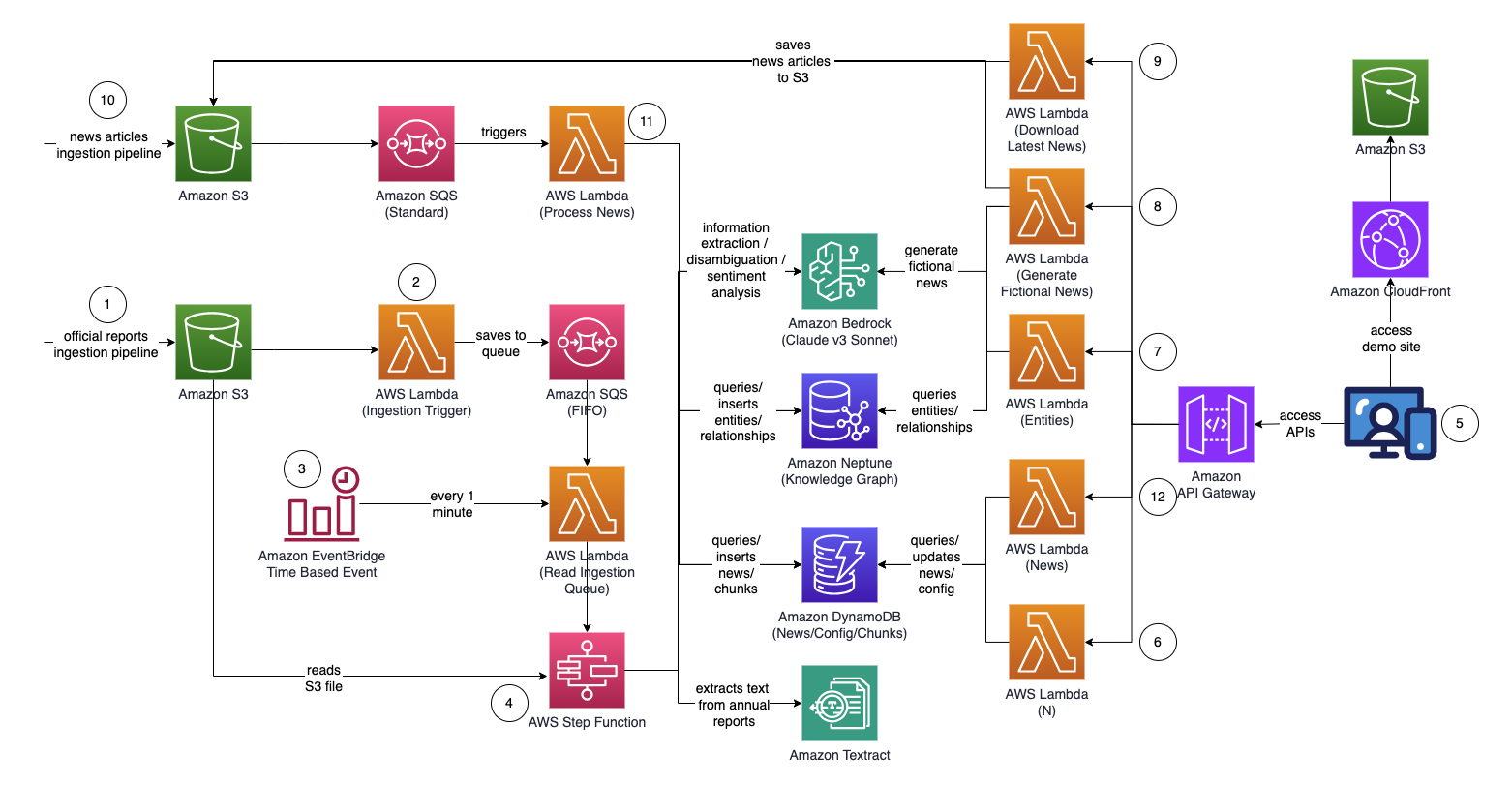
Schrittfunktionsdiagramm (ab Punkt 4)
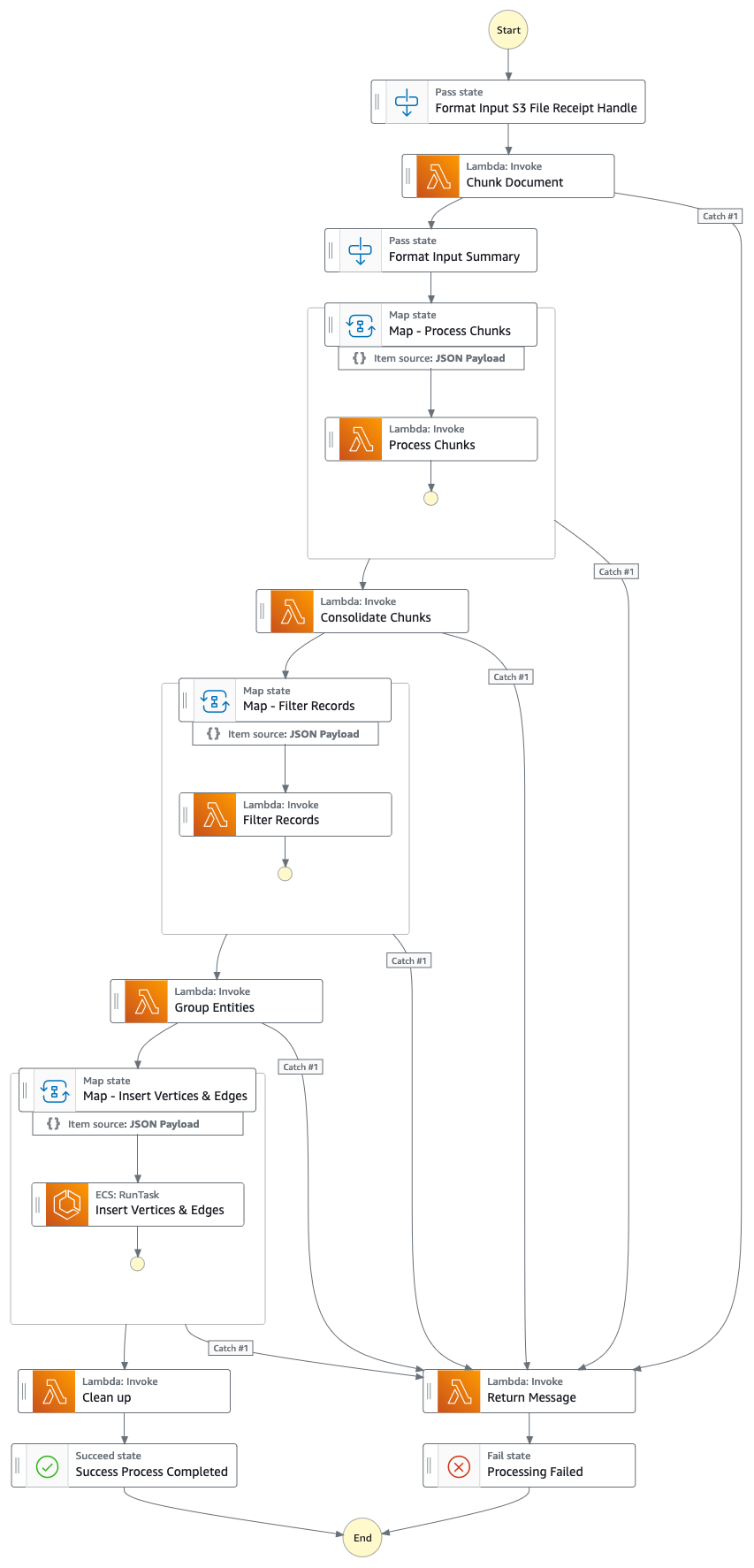
Lösungsfluss (Schritt für Schritt)
- Laden Sie offizielle Proxy-/Jahresberichte/10.000-Berichte (.PDF) in den Amazon S3-Bucket hoch.
- Der Name des S3-Buckets, in den hochgeladen werden soll, kann von der CloudFormation-Konsole abgerufen werden – Haupt-Stack-Ausgabe – „IngestionBucket“
- Beachten Sie, dass es sich bei den verwendeten Berichten um offiziell veröffentlichte Berichte handeln sollte, um die Aufnahme ungenauer Daten in Ihren Wissensgraphen zu minimieren (im Gegensatz zu Nachrichten/Boulevardzeitungen).
- Die S3-Ereignisbenachrichtigung löst eine AWS Lambda-Funktion aus, die den S3-Bucket-/Dateinamen an eine Amazon Simple Queue Service Queue (FIFO) sendet.
- Durch die Verwendung der FIFO-Warteschlange soll sichergestellt werden, dass der Berichtsaufnahmeprozess sequenziell durchgeführt wird, um die Wahrscheinlichkeit zu verringern, dass doppelte Daten in Ihren Wissensgraphen eingefügt werden.
- Ein zeitbasiertes Ereignis von Amazon EventBridge wird jede Minute ausgeführt, um eine AWS Lambda-Funktion aufzurufen. Die Funktion ruft die nächste verfügbare Warteschlangennachricht von SQS ab und startet asynchron die Ausführung einer AWS Step Function.
- Eine Schrittfunktions-Zustandsmaschine führt eine Reihe von Aufgaben aus, um das hochgeladene Dokument zu verarbeiten, indem sie wichtige Informationen extrahiert und in Ihren Wissensgraphen einfügt.
- Aufgaben
- Extrahieren Sie mit Amazon Textract Textinhalte aus der Proxy-/Jahresberichtsdatei (PDF) in Amazon S3 und teilen Sie sie zur Verarbeitung in mehrere kleinere Textblöcke auf. Speichern Sie die Textblöcke in Amazon DynamoDB.
- Verarbeiten Sie mit Anthropics Claude v3 Sonnet auf Amazon Bedrock die ersten paar Textabschnitte, um die Hauptentität zu bestimmen, auf die sich der Bericht bezieht, zusammen mit relevanten Attributen (z. B. Branche).
- Ruft die Textblöcke aus DynamoDB ab und ruft für jeden Textblock eine Lambda-Funktion auf, um mithilfe von Amazon Bedrock Entitäten (Firma/Person) und deren Beziehung (Kunde/Lieferant/Partner/Konkurrent/Direktor) zur Hauptentität zu extrahieren.
- Konsolidieren Sie alle extrahierten Informationen
- Filtert Rauschen/irrelevante Entitäten (z. B. allgemeine Begriffe wie „Verbraucher“) mithilfe von Amazon Bedrock heraus.
- Verwenden Sie Amazon Bedrock, um eine Begriffsklärung durchzuführen, indem Sie die extrahierten Informationen mit der Liste ähnlicher Entitäten aus dem Wissensgraphen vergleichen. Wenn die Entität nicht existiert, fügen Sie sie ein. Andernfalls verwenden Sie die Entität, die bereits im Wissensgraphen vorhanden ist. Fügt alle extrahierten Beziehungen ein.
- Führen Sie eine Bereinigung durch, indem Sie die SQS-Warteschlangennachricht und die S3-Datei löschen.
- Sobald dieser Schritt abgeschlossen ist, ist Ihr Wissensgraph aktualisiert und einsatzbereit.
- Ein Benutzer greift auf eine React-basierte Webanwendung zu, um die Nachrichtenartikel anzuzeigen, die mit Entitäts-/Stimmungs-/Verbindungspfadinformationen angereichert sind.
- Die URL für die Webanwendung kann von der CloudFormation-Konsole kopiert werden – Webapp-Stack-Ausgabe – „WebApplicationURL“
- Da es sich um eine Beispiellösung für Demozwecke handelt, gibt der Benutzer den API-Endpunkt, den API-Schlüssel und den News-API-Schlüssel in der Webanwendung an, indem er auf das Zahnradsymbol in der oberen rechten Ecke klickt.
- Der API-Endpunkt kann von der CloudFormation-Konsole kopiert werden – Haupt-Stack-Ausgabe – „APIEndpoint“.
- Der API-Schlüssel kann von der API Gateway-API-Schlüsselkonsole – Hauptstapel – kopiert werden.
- Der News-API-Schlüssel kann von NewsAPI.org bezogen werden, nachdem Sie kostenlos ein Konto erstellt haben.
- Klicken Sie nach dem Ausfüllen der Werte auf die Schaltfläche „Einstellungen aktualisieren“.
- Mithilfe der Webanwendung gibt ein Benutzer die Anzahl der Hops (Standard: N=2) auf dem zu überwachenden Verbindungspfad an.
- Klicken Sie dazu auf das Zahnradsymbol oben rechts und geben Sie dann den Wert von N ein.
- Mithilfe der Webanwendung gibt ein Benutzer die Liste der zu verfolgenden Entitäten an.
- Klicken Sie dazu auf das Zahnradsymbol in der oberen rechten Ecke und schalten Sie dann den Schalter „Interessiert“ um, der die entsprechende Entität als INTERESSIERT=JA/NEIN markiert.
- Dies ist ein wichtiger Schritt und muss durchgeführt werden, bevor Nachrichtenartikel verarbeitet werden.
- Um fiktive Nachrichten zu generieren, klickt ein Benutzer auf die Schaltfläche „Beispielnachrichten generieren“, um 10 Beispielfinanznachrichten mit zufälligem Inhalt zu generieren, die in den Nachrichtenaufnahmeprozess eingespeist werden.
- Die Inhalte werden mit Amazon Bedrock generiert und sind rein fiktiv.
- Um aktuelle Nachrichten herunterzuladen, klickt ein Benutzer auf die Schaltfläche „Neueste Nachrichten herunterladen“, um die wichtigsten aktuellen Nachrichten herunterzuladen (unterstützt von NewsAPI.org).
- Laden Sie Nachrichten (.TXT) in den S3-Bucket hoch.
- Der Name des S3-Buckets, in den hochgeladen werden soll, kann von der CloudFormation-Konsole abgerufen werden – Haupt-Stack-Ausgabe – „NewsBucket“
- Mit den Schritten Nr. 8 oder Nr. 9 wurden Nachrichten automatisch in den S3-Bucket hochgeladen. Sie können jedoch auch Integrationen zu Ihrem bevorzugten Nachrichtenanbieter wie AWS Data Exchange oder einem anderen Nachrichtenanbieter von Drittanbietern erstellen, um Nachrichtenartikel als Dateien im S3-Bucket abzulegen.
- Der Inhalt der Nachrichtendatendatei sollte wie folgt formatiert sein: {TT MMM JJJJ{Titel}{Nachrichteninhalt
- Die S3-Ereignisbenachrichtigung sendet den S3-Bucket-/Dateinamen an SQS (Standard), was mehrere Lambda-Funktionen auslöst, um die Nachrichtendaten parallel zu verarbeiten.
- Mithilfe von Amazon Bedrock extrahiert die Lambda-Funktion in den Nachrichten erwähnte Entitäten zusammen mit allen zugehörigen Informationen, Beziehungen und Stimmungen der erwähnten Entität.
- Anschließend prüft es den Wissensgraphen und verwendet Amazon Bedrock, um eine Begriffsklärung durchzuführen, indem es die verfügbaren Informationen aus den Nachrichten und aus dem Wissensgraphen nutzt, um die entsprechende Entität zu identifizieren.
- Sobald die Entität gefunden wurde, sucht sie nach allen Verbindungspfaden, die mit Entitäten verbunden sind, die im Wissensgraphen mit INTERESTED=YES markiert sind und sich innerhalb von N=2 Hops befinden, und gibt diese zurück.
- Die Webanwendung wird alle 1 Sekunde automatisch aktualisiert, um die neuesten verarbeiteten Nachrichten abzurufen und in der Webanwendung anzuzeigen.
Webanwendung reagieren – Einstellungen
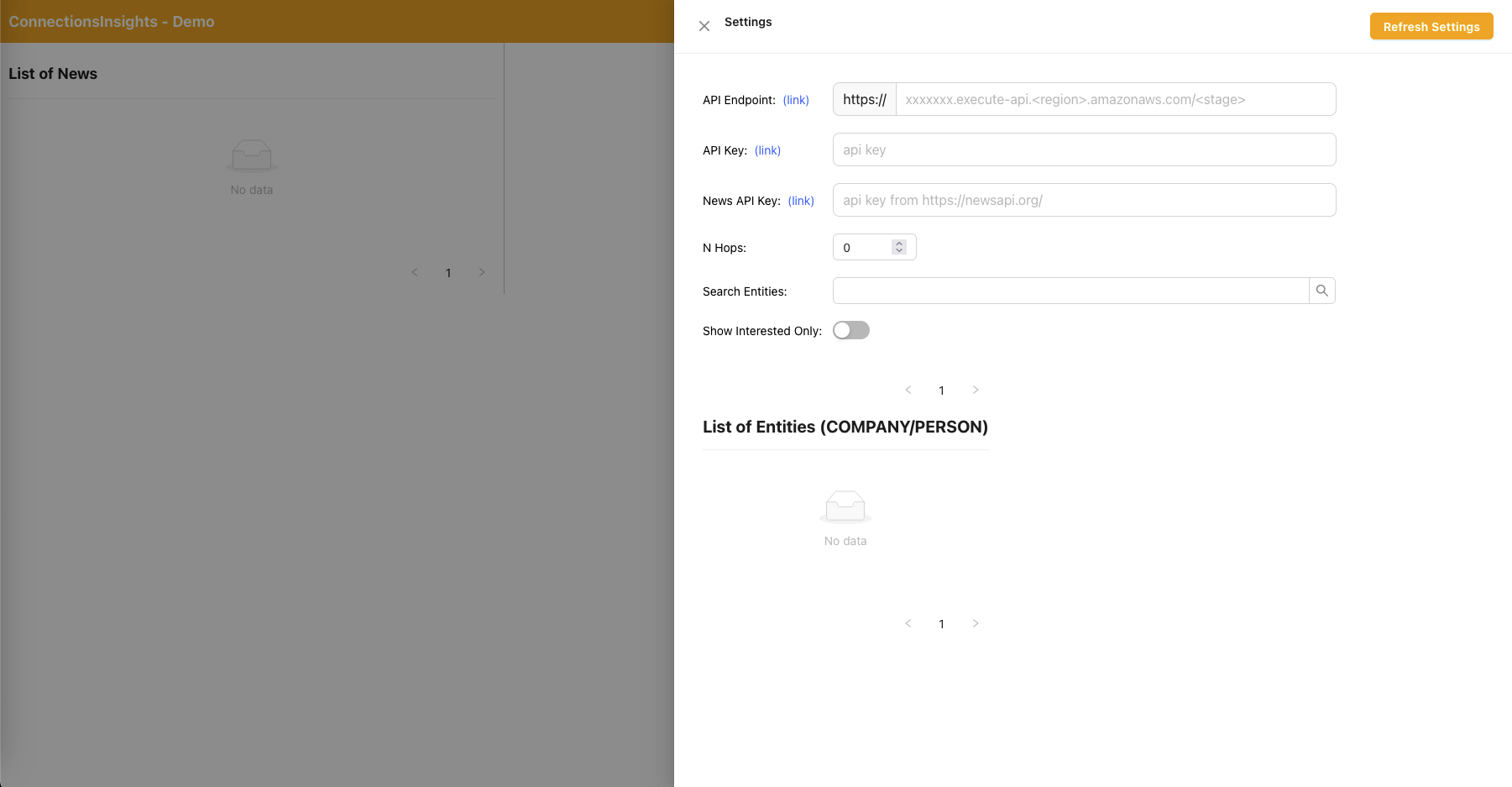
Diagramm-Explorer
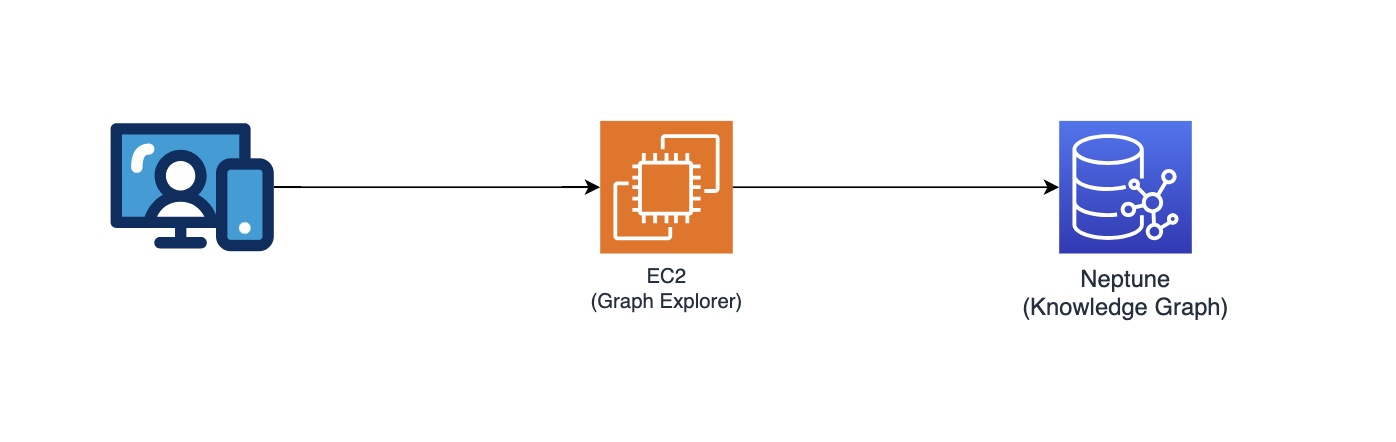
Dieses Repository stellt auch Graph Explorer (github/aws/graphexplorer) bereit, eine React-basierte Webanwendung, die es Benutzern ermöglicht, die extrahierten Entitäten und Beziehungen zu visualisieren.
- Um auf den Graph Explorer zuzugreifen, rufen Sie die URL von der CloudFormation-Konsole ab – Haupt-Stack-Ausgabe – „GraphExplorer“
- Wenn Sie auf die Webanwendung zugreifen, erhalten Sie in Ihrem Browser eine Warnung vor einem möglichen Sicherheitsrisiko, da das für die Website verwendete Zertifikat selbstsigniert ist. Sie können fortfahren. Um die Warnung loszuwerden, lesen Sie dies.
- Nach dem Start stellt die Anwendung automatisch eine Verbindung zur AWS Neptune-Datenbank her und synchronisiert ihre Daten. Sie können jederzeit auf das Aktualisierungssymbol klicken, um die Daten erneut zu synchronisieren.
- Klicken Sie oben rechts auf „Graph-Explorer öffnen“, um mit der Visualisierung des Wissensgraphen zu beginnen.
- Weitere Informationen zum Graph Explorer finden Sie unter github/aws/graphexplorer.
- Beachten Sie, dass der Graph Explorer nicht als Teil der Lösung erforderlich ist, Ihnen aber die Erkundung der extrahierten Beziehungen erleichtert.
Demo – Erste Schritte mit Graph Explorer
Erste Schritte mit dem Graph-Explorer.mp4
Hier ist eine weitere Videodemo zu den Funktionen von Graph Explorer: Link zur Videodemo
Graph Explorer – Wissensgraph
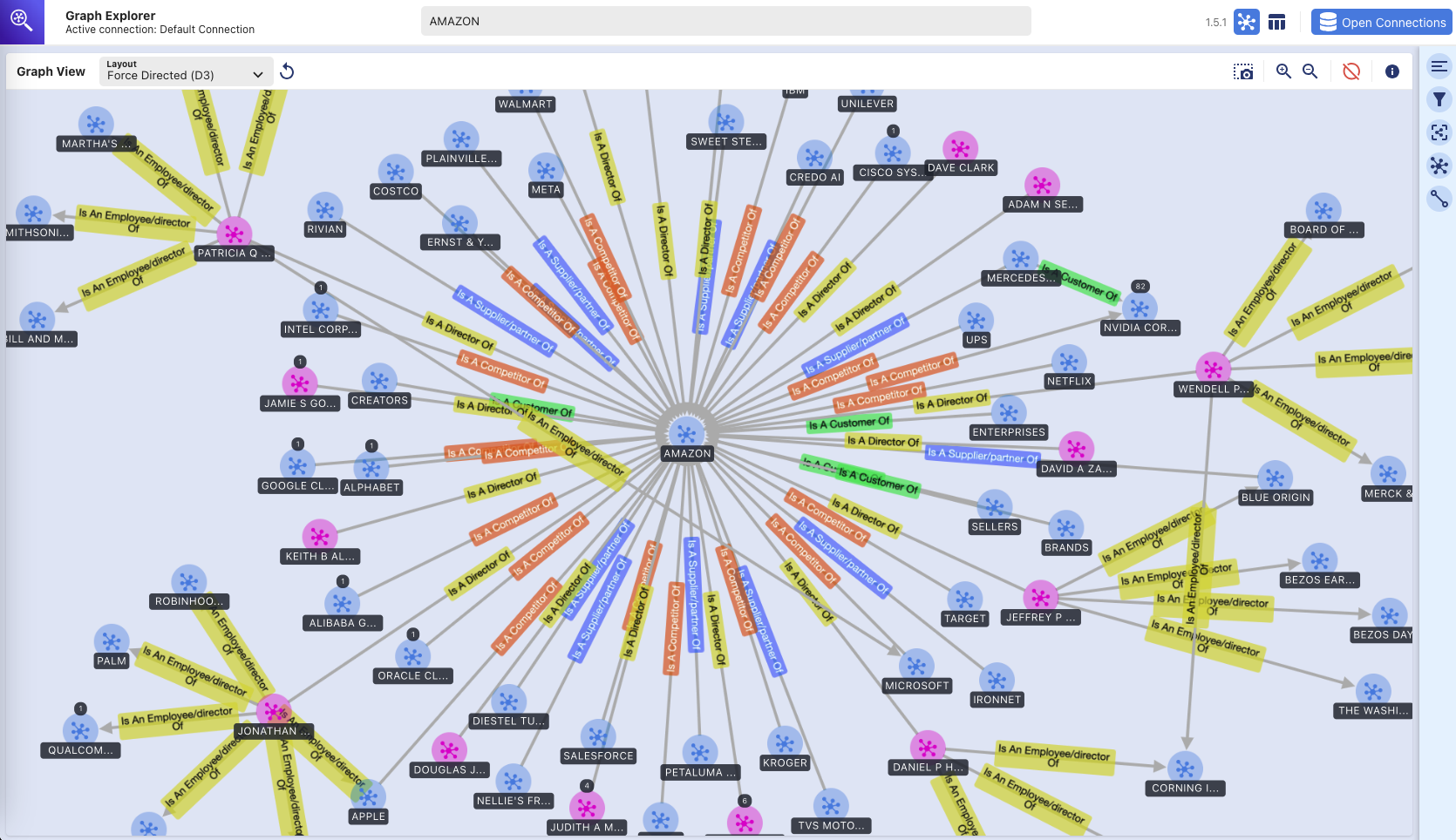
(visuelle Erkundung der Amazon Neptune-Diagrammdatenbank mit dem Graph Explorer-Tool)
Bereitstellungsanweisungen
Dieses Repository stellt eine CDK-Anwendung bereit, die die gesamte Prototyplösung über zwei CDK-Stacks bereitstellt:
- Hauptanwendungsstapel („Hauptstapel“), der in jeder Region (z. B. us-east-1, us-west-2) bereitgestellt werden kann, die über die erforderlichen Dienste und Amazon Bedrock-Modelle verfügt.
- Webanwendungsstapel („Webapp-Stack“), der nur auf us-east-1 bereitgestellt werden kann, da er AWS WAF erfordert.
Sie können die beiden Stacks in verschiedenen Regionen oder in derselben Region (z. B. us-east-1) bereitstellen.
Verwendete AWS-Dienste
- Amazonas-Grundgestein
- Amazon Neptun
- Amazon Textract
- Amazon DynamoDB
- AWS-Schrittfunktion
- AWS Lambda
- Amazon Simple Queue Service (SQS)
- Amazon EventBridge
- Amazon Simple Storage Service (S3)
- Amazon CloudFront
- AWS WAF
- Amazon Elastic Compute Cloud (EC2)
- Amazon VPC
- Amazon API Gateway
- AWS Identitäts- und Zugriffsverwaltung
Voraussetzungen
- Amazon Bedrock – Sie benötigen Zugriff auf Anthropic Claude v3 Sonnet. Lesen Sie dies, um den Modellzugriff in Amazon Bedrock einzurichten.
- Python – Sie benötigen Python 3 und höher.
- Knoten – Sie benötigen Version 18.0.0 und höher.
- Docker – Sie benötigen Version 24.0.0 und höher mit Docker Buildx und müssen den Docker-Daemon ausführen.
Virtualenv einrichten
So erstellen Sie manuell eine virtuelle Umgebung unter MacOS und Linux:
Nachdem der Init-Prozess abgeschlossen und die virtuelle Umgebung erstellt wurde, können Sie mit dem folgenden Schritt Ihre virtuelle Umgebung aktivieren.
$ source .venv/bin/activate
Wenn Sie eine Windows-Plattform verwenden, würden Sie die virtuelle Umgebung wie folgt aktivieren:
% .venvScriptsactivate.bat
Sobald die virtuelle Umgebung aktiviert ist, können Sie die erforderlichen Abhängigkeiten installieren.
$ pip install -r requirements.txt
Vor der Bereitstellung
Wenn Sie Ihren Code zum ersten Mal über CDK in Ihrem AWS-Konto bereitstellen, müssen Sie zunächst Ihr AWS-Konto sowohl in us-east-1 als auch in der Region, in der Sie die Bereitstellung durchführen, booten. Andernfalls können Sie diesen Schritt überspringen.
$ cdk bootstrap aws:///us-east-1 aws:///
Führen Sie dann den folgenden Befehl aus, um:
- Erstellen Sie die React-basierte Webanwendung
- Laden Sie die Python-Abhängigkeiten herunter, die für die Erstellung des AWS Lambda Layer erforderlich sind
- Benutzerdefinierte Bibliothek kopieren (connectionsinsights)
Einsetzen
So stellen Sie die Lösung bereit (dauert etwa 30 Minuten):
Aufräumen
Um die Lösung zu zerstören:
Wenn ein Löschfehler auftritt, weil die S3-Buckets nicht leer sind, kann dies an Zugriffsprotokolldateien liegen, die in die S3-Buckets geschrieben wurden, nachdem diese im Rahmen des CDK-Zerstörungsprozesses geleert wurden. Wenn dies passiert, leeren Sie einfach die Buckets und führen Sie den Bereinigungsbefehl erneut aus.