synthetic data generator
0.2.3
Sprache wechseln: 简体中文 | Neueste API-Dokumente | Roadmap | Treten Sie der Wechat-Gruppe bei
Colab-Beispiele: LLM: Datensynthese | LLM: Off-Table-Inferenz | CTGAN unterstützt Daten auf Milliardenebene
Der Synthetic Data Generator (SDG) ist ein spezielles Framework zur Generierung hochwertiger strukturierter Tabellendaten.
Synthetische Daten enthalten keine sensiblen Informationen, behalten jedoch die wesentlichen Merkmale der Originaldaten bei und sind daher von Datenschutzbestimmungen wie DSGVO und ADPPA ausgenommen.
Hochwertige synthetische Daten können sicher in verschiedenen Bereichen genutzt werden, einschließlich Datenaustausch, Modelltraining und Debugging, Systementwicklung und -tests usw.
Wir freuen uns, Sie hier zu haben und freuen uns auf Ihre Beiträge. Beginnen Sie mit dem Projekt mit diesem Beitragsübersichtsleitfaden!
Unsere aktuellen wichtigsten Erfolge und Zeitpläne sind wie folgt:
21. November 2024: 1) Modellintegration – Wir haben das GaussianCopula Modell in unser Datenprozessorsystem integriert. Schauen Sie sich das Codebeispiel in dieser PR an. 2) Synthetische Qualität – Wir haben die automatische Erkennung von Datenspaltenbeziehungen implementiert und eine Beziehungsspezifikation ermöglicht, wodurch die Qualität synthetischer Daten verbessert wurde (Codebeispiel); 3) Leistungsverbesserung – Wir haben die Speichernutzung von GaussianCopula bei der Verarbeitung diskreter Daten erheblich reduziert und ermöglichen so das Training auf Tausenden von kategorialen Dateneinträgen mit einem 2C4G -Setup!
30. Mai 2024: Das Datenprozessormodul wurde offiziell zusammengeführt. Dieses Modul wird: 1) SDG dabei helfen, das Format einiger Datenspalten (z. B. Datetime-Spalten) zu konvertieren, bevor es in das Modell eingespeist wird (um zu vermeiden, dass es als diskrete Typen behandelt wird), und die vom Modell generierten Daten umgekehrt in das Originalformat umzuwandeln ; 2) eine individuellere Vor- und Nachbearbeitung verschiedener Datentypen durchführen; 3) problemlos mit Problemen wie Nullwerten in den Originaldaten umgehen; 4) Unterstützung des Plug-in-Systems.
20. Februar 2024: Ein auf LLM basierendes Einzeltabellen-Datensynthesemodell ist enthalten, siehe Colab-Beispiel: LLM: Datensynthese und LLM: Off-Table Feature Inference.
7. Februar 2024: Wir haben sdgx.data_models.metadata verbessert, um Metadateninformationen zu unterstützen, die einzelne Tabellen und mehrere Tabellen beschreiben, mehrere Datentypen unterstützen und die automatische Datentypinferenz unterstützen. Colab-Beispiel anzeigen: SDG Single-Table Metadata。
20. Dezember 2023: v0.1.0 veröffentlicht, ein CTGAN-Modell, das Milliarden von Datenverarbeitungsfunktionen unterstützt, ist enthalten. Sehen Sie sich unseren Benchmark mit SDV an, bei dem SDG einen geringeren Speicherverbrauch erzielte und Abstürze während des Trainings vermieden wurden. Für eine spezifische Verwendung sehen Sie sich das Colab-Beispiel an: Billion-Level-Data unterstütztes CTGAN.
10. August 2023: Erste Zeile des SDG-Codes festgeschrieben.
LLM wird seit langem dazu verwendet, verschiedene Arten von Daten zu verstehen und zu generieren. Tatsächlich verfügt LLM auch über bestimmte Fähigkeiten bei der tabellarischen Datengenerierung. Außerdem verfügt es über einige Fähigkeiten, die mit herkömmlichen Methoden (basierend auf GAN-Methoden oder statistischen Methoden) nicht erreicht werden können.
Unser sdgx.models.LLM.single_table.gpt.SingleTableGPTModel implementiert zwei neue Funktionen:
Es sind keine Trainingsdaten erforderlich, synthetische Daten können auf Basis von Metadatendaten generiert werden, siehe unser Colab-Beispiel.
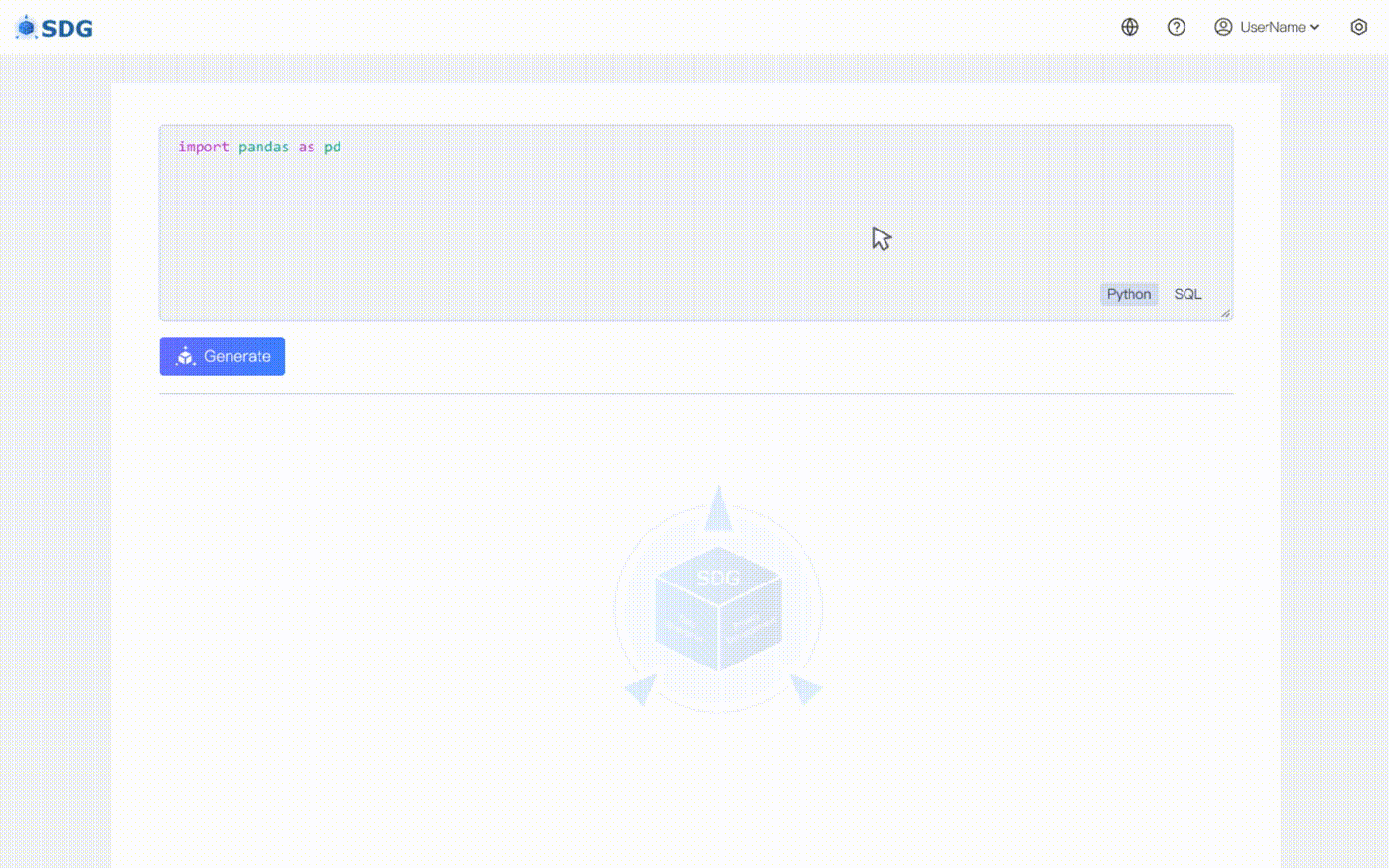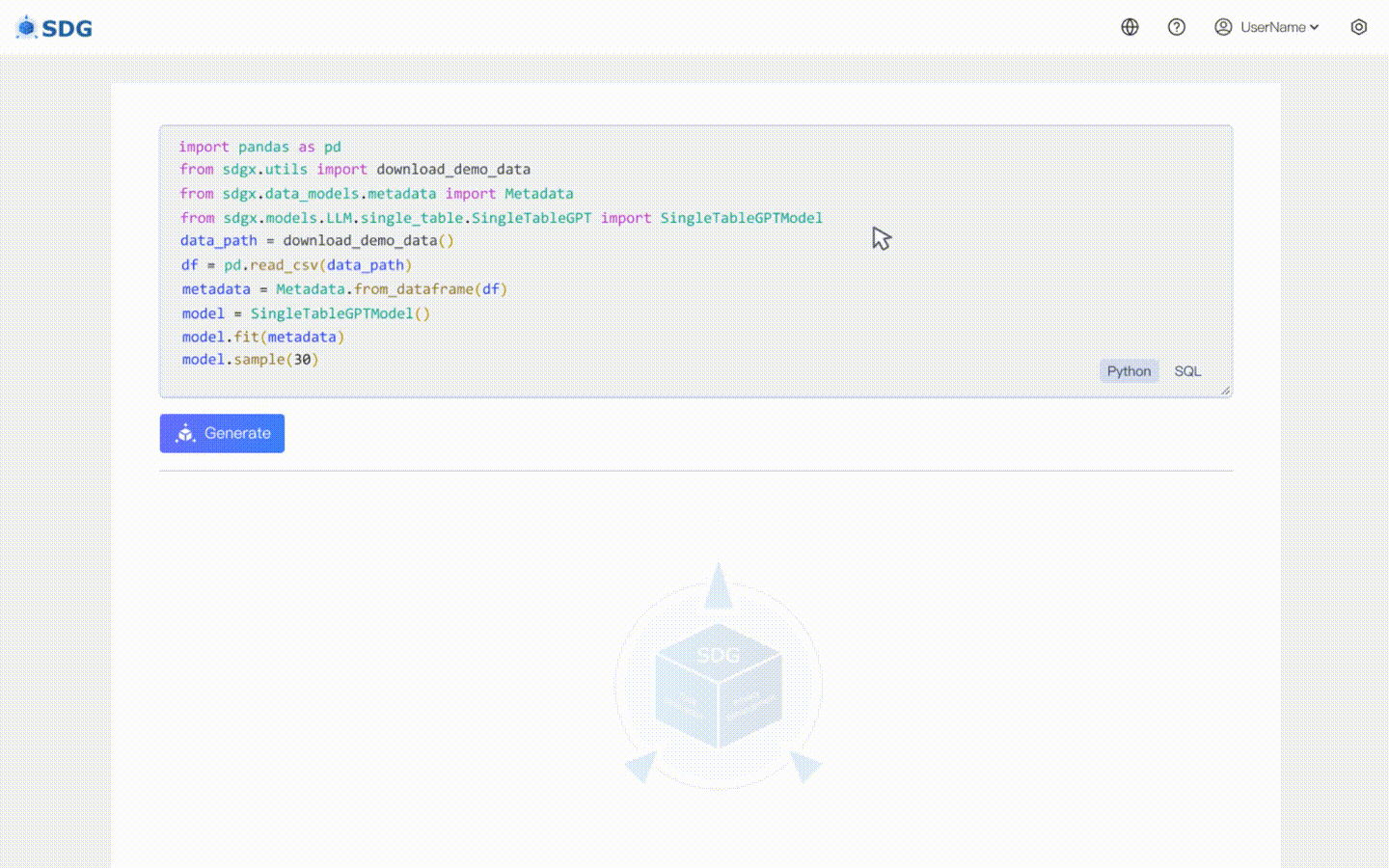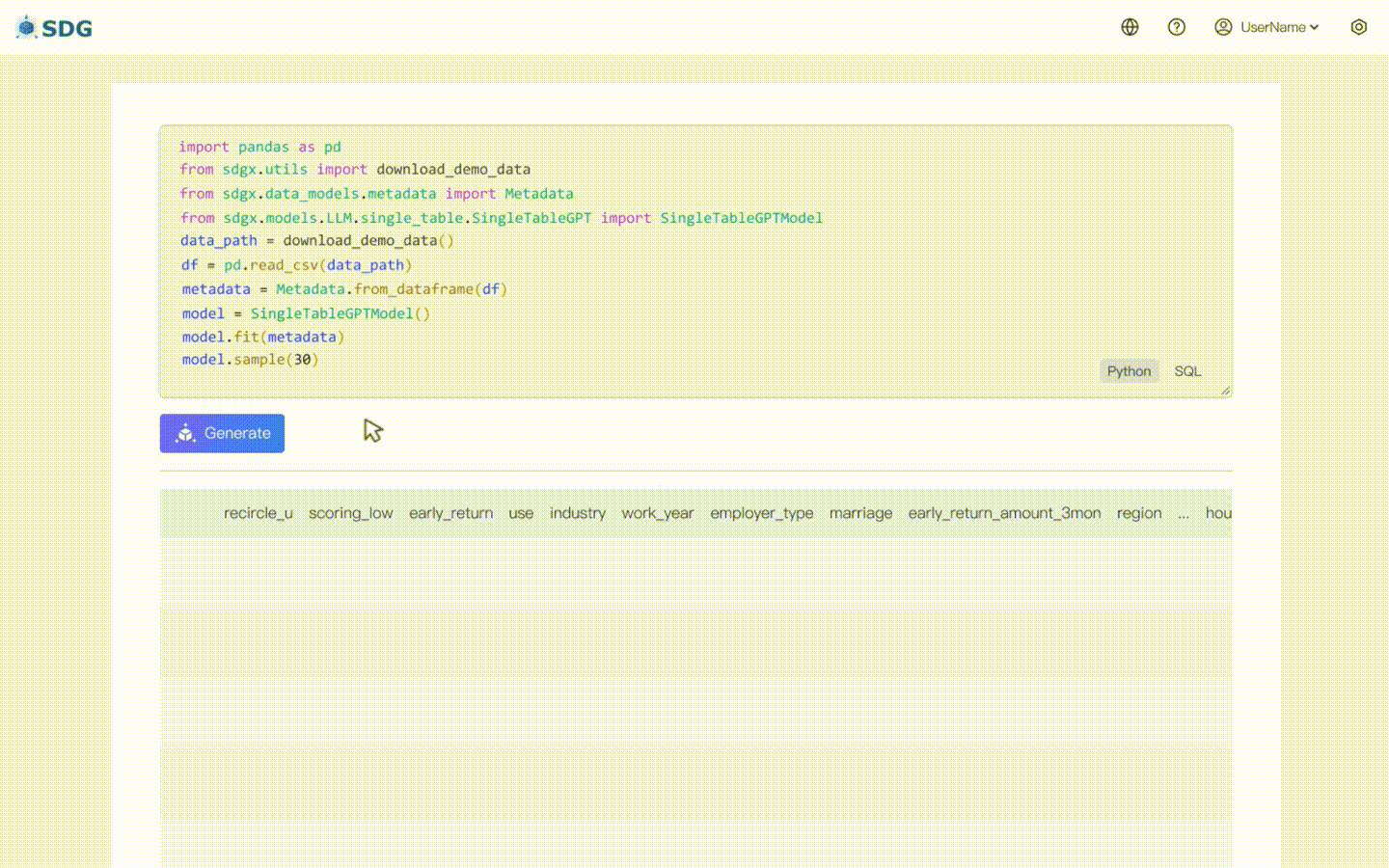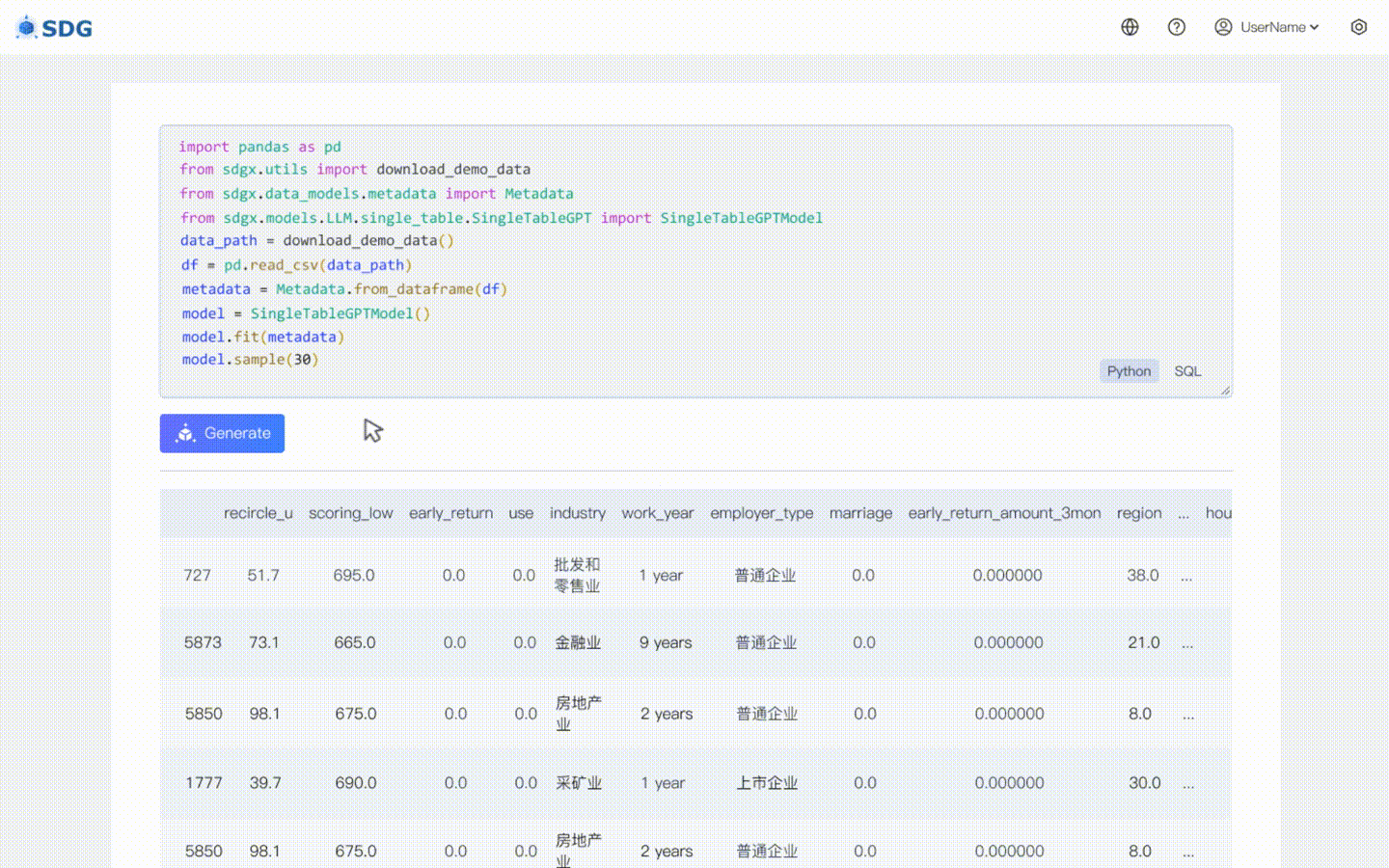
Leiten Sie neue Spaltendaten basierend auf den vorhandenen Daten in der Tabelle und dem von LLM beherrschten Wissen ab, siehe unser Colab-Beispiel.
Technologische Fortschritte:
Unterstützt eine breite Palette statistischer Datensynthesealgorithmen. Ein LLM-basiertes Modell zur Generierung synthetischer Daten ist ebenfalls integriert.
Optimiert für Big Data, wodurch der Speicherverbrauch effektiv reduziert wird;
Kontinuierliche Verfolgung der neuesten Fortschritte in Wissenschaft und Industrie und zeitnahe Einführung der Unterstützung für hervorragende Algorithmen und Modelle.
Datenschutzverbesserungen:
SDG unterstützt differenziellen Datenschutz, Anonymisierung und andere Methoden, um die Sicherheit synthetischer Daten zu erhöhen.
Einfach zu erweitern:
Unterstützt die Erweiterung von Modellen, Datenverarbeitung, Datenkonnektoren usw. in Form von Plug-in-Paketen.
Sie können vorgefertigte Bilder verwenden, um schnell die neuesten Funktionen kennenzulernen.
Docker Pull idsteam/sdgx:latest
pip install sdgx
Verwenden Sie SDG, indem Sie es über den Quellcode installieren.
Git-Klon [email protected]:hitsz-ids/synthetic-data-generator.git pip install .# Oder von gitpip install git+https://github.com/hitsz-ids/synthetic-data-generator.git installieren
from sdgx.data_connectors.csv_connector import CsvConnectorfrom sdgx.models.ml.single_table.ctgan import CTGANSynthesizerModelfrom sdgx.synthesizer import Synthesizerfrom sdgx.utils import download_demo_data# Dadurch werden Demodaten nach ./datasetdataset_csv = download_demo_data()# heruntergeladen. Datenkonnektor für CSV erstellen filedata_connector = CsvConnector(path=dataset_csv)# Synthesizer initialisieren, CTGAN-Modell verwendensynthesizer = Synthesizer(model=CTGANSynthesizerModel(epochs=1), # Für eine schnelle Demodata_connector=data_connector, )# Passen Sie das Modell ansynthesizer.fit()# Samplesampled_data = synthesizer.sample(1000)print(sampled_data)
Die tatsächlichen Daten lauten wie folgt:
>>> data_connector.read() Alter Arbeitsklasse fnlwgt Bildung ... Kapitalverlust Stunden pro Woche Heimatland Klasse0 2 Bundesstaat-Regierung 77516 Junggesellen ... 0 2 Vereinigte Staaten <=50K1 3 Selbständigerwerb-nicht-inc 83311 Junggesellen .. . 0 0 Vereinigte Staaten <=50K2 2 Privat 215646 HS-grad ... 0 2 Vereinigte Staaten <=50K3 3 Privat 234721 11. ... 0 2 Vereinigte Staaten <=50K4 1 Privat 338409 Junggesellen ... 0 2 Kuba <=50K... ... ... ... ... ... . .. ... ... ...48837 2 Privat 215419 Bachelors ... 0 2 Vereinigte Staaten <=50K48838 4 NaN 321403 HS-grad ... 0 2 USA <=50K48839 2 Privat 374983 Junggesellen ... 0 3 USA <=50K48840 2 Privat 83891 Junggesellen ... 0 2 USA <=50K48841 1 Selbstständig 182148 Junggesellen . .. 0 3 Vereinigte Staaten >50.000[48842 Zeilen x 15 Spalten]
Synthetische Daten lauten wie folgt:
>>> sampled_data Alter Arbeitsklasse fnlwgt Bildung ... Kapitalverlust Stunden pro Woche Heimatland Klasse0 1 NaN 28219 Irgendein College ... 0 2 Puerto-Rico <=50K1 2 Privat 250166 HS-Absolvent ... 0 2 Vereinigte Staaten >50K2 2 Privat 50304 HS-grad ... 0 2 Vereinigte Staaten <=50K3 4 Privat 89318 Junggesellen ... 0 2 Puerto-Rico >50K4 1 Privat 172149 Junggesellen ... 0 3 Vereinigte Staaten <=50K.. ... ... ... ... ... ... ... ... ...995 2 NaN 208938 Junggesellen ... 0 1 Vereinigte Staaten <=50K996 2 Privat 166416 Junggesellen ... 2 2 Vereinigte Staaten <=50K997 2 NaN 336022 HS-Abschluss ... 0 1 Vereinigte Staaten <=50K998 3 Privat 198051 Masters ... 0 2 Vereinigte Staaten >50K999 1 NaN 41973 HS-Abschluss ... 0 2 Vereinigte Staaten <= 50.000 [1000 Zeilen x 15 Spalten]
CTGAN: Modellierung tabellarischer Daten mithilfe von bedingtem GAN
C3-TGAN: C3-TGAN – steuerbare tabellarische Datensynthese mit expliziten Korrelationen und Eigenschaftsbeschränkungen
TVAE: Modellierung tabellarischer Daten mithilfe von bedingtem GAN
table-GAN: Datensynthese basierend auf generativen gegnerischen Netzwerken
CTAB-GAN:CTAB-GAN: Effektive Tabellendatensynthese
OCT-GAN: OCT-GAN: Neuronale ODE-basierte bedingte tabellarische GANs
Das SDG-Projekt wurde vom Institute of Data Security des Harbin Institute of Technology initiiert. Wenn Sie an unserem Projekt interessiert sind, sind Sie herzlich willkommen, unserer Community beizutreten. Wir begrüßen Organisationen, Teams und Einzelpersonen, die unser Engagement für Datenschutz und Sicherheit durch Open Source teilen:
Lesen Sie „Beitrag leisten“, bevor Sie eine Pull-Anfrage entwerfen.
Reichen Sie ein Problem ein, indem Sie „Gutes erstes Problem anzeigen“ anzeigen oder eine Pull-Anfrage senden.
Treten Sie unserer Wechat-Gruppe über den QR-Code bei.


