QuillGPT
1.0.0

QuillGPT ist eine Implementierung des GPT-Decoderblocks, die auf der Architektur aus dem Artikel „Attention is All You Need“ von Vaswani et al. basiert. al. implementiert in PyTorch. Darüber hinaus enthält dieses Repository zwei vorab trainierte Modelle – Shakespeare-GPT und Harpoon-GPT – zusammen mit ihren trainierten Gewichten. Um das Experimentieren und Bereitstellen zu erleichtern, wird ein Streamlit Playground zur interaktiven Erkundung dieser Modelle und ein FastAPI-Mikroservice bereitgestellt, der mit Docker-Containerisierung für eine skalierbare Bereitstellung implementiert wird. Sie finden auch Python-Skripte zum Trainieren neuer GPT-Modelle und zum Durchführen von Rückschlüssen auf diese sowie Notebooks, in denen trainierte Modelle vorgestellt werden. Um die Kodierung und Dekodierung von Text zu erleichtern, ist ein einfacher Tokenizer implementiert. Entdecken Sie QuillGPT, um diese Tools zu nutzen und Ihre Projekte zur Verarbeitung natürlicher Sprache zu verbessern!
In diesem Repository sind zwei vorab trainierte Modelle und Gewichte enthalten.
| Besonderheit | Shakespeare-GPT | Harpune GPT |
|---|---|---|
| Parameter | 10,7 Mio | 226 Mio |
| Gewichte | Gewichte | Gewichte |
| Modellkonfiguration | Konfig | Konfig |
| Trainingsdaten | Text aus Shakespeare-Stücken (input.txt) | Zufälliger Text aus Büchern (corpus.txt) |
| Einbettungstyp | Charaktereinbettungen | Charaktereinbettungen |
| Trainingsnotizbuch | Notizbuch | Notizbuch |
| Hardware | NVIDIA T4 | NVIDIA A100 |
| Schulungs- und Validierungsverlust | 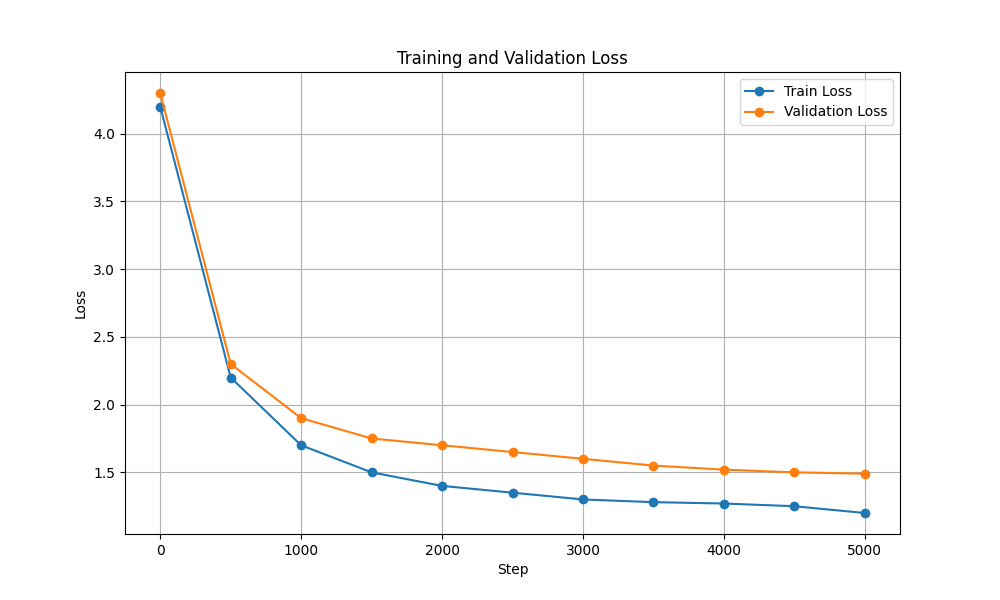 | 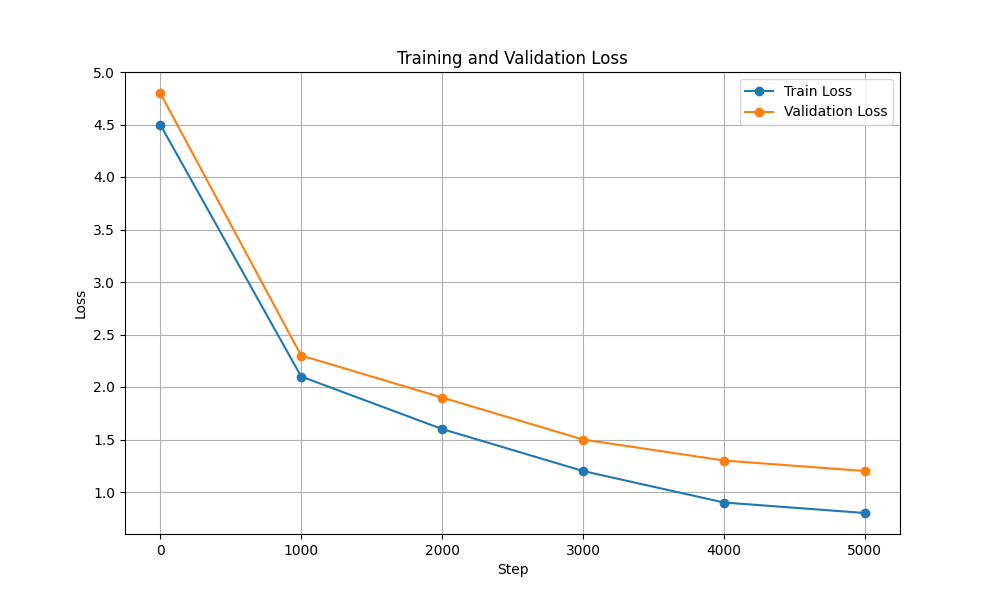 |
Führen Sie die folgenden Schritte aus, um die Trainings- und Inferenzskripte auszuführen:
git clone https://github.com/NotShrirang/GPT-From-Scratch.git
cd GPT-From-Scratchpip install -r requirements.txtStellen Sie sicher, dass Sie die Gewichte für Harpoon GPT hier herunterladen, bevor Sie fortfahren!
Es wird auf dem Streamlit Cloud Service gehostet. Sie können es über den Link hier besuchen.
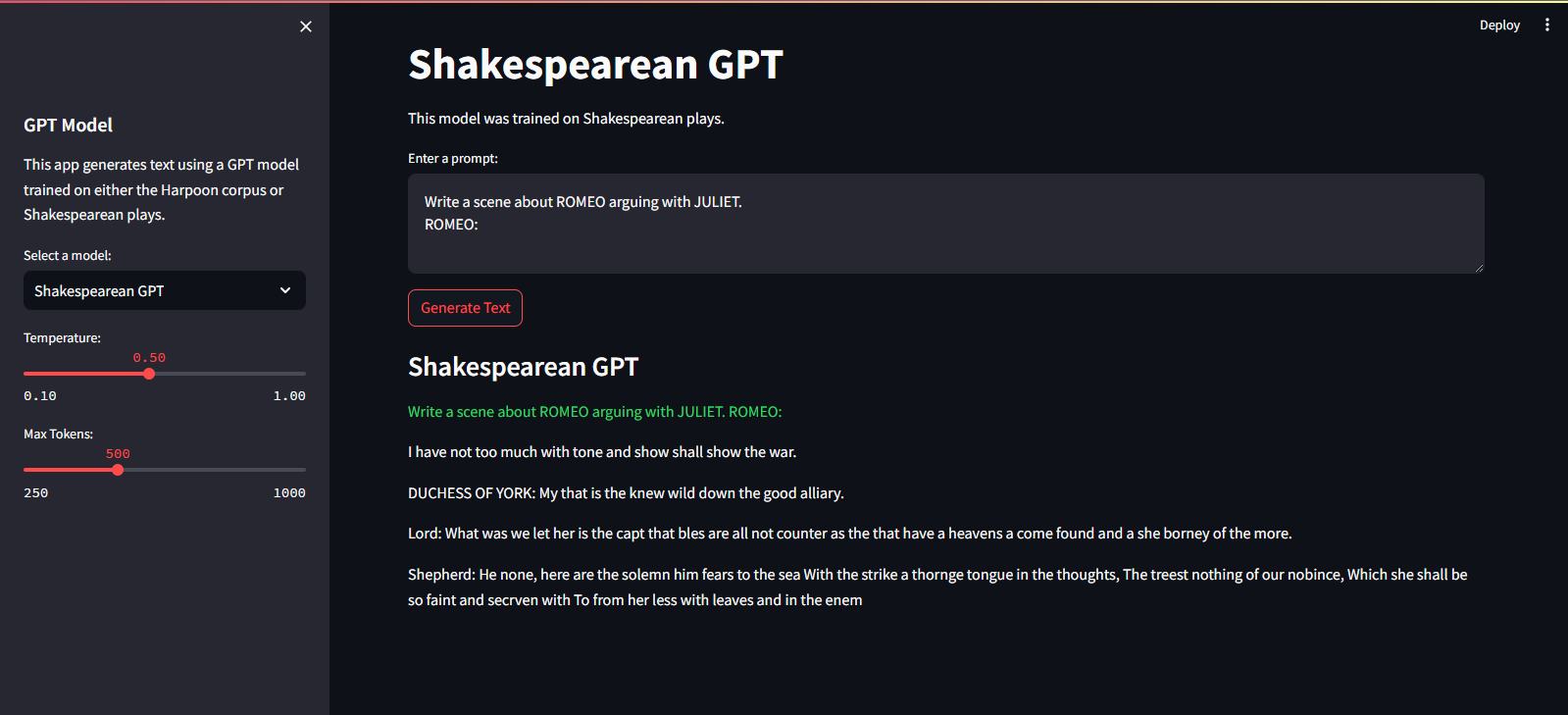
streamlit run app.pypython main.py./run.sh start-dev./run.sh stop-devGehen Sie folgendermaßen vor, um das GPT-Modell zu trainieren:
Daten vorbereiten. Fügen Sie die gesamten Textdaten in eine einzelne TXT-Datei ein und speichern Sie sie.
Schreiben Sie die Konfigurationen für den Transformer und speichern Sie die Datei.
Zum Beispiel: json { "data_path": "data/corpus.txt", "vocab_size": 135, "batch_size": 32, "block_size": 256, "max_iters": 3000, "eval_interval": 300, "learning_rate": 3e-5, "eval_iters": 50, "n_embd": 1024, "n_head": 12, "n_layer": 18, "dropout": 0.3, }
Trainieren Sie das Modell mit dem Skript scripts/train_gpt.py
python scripts/train_gpt.py
--config_path config/config.json
--data_path data/corpus.txt
--output_dir trained_models (Sie können den config_path , data_path und output_dir entsprechend Ihren Anforderungen ändern.)
output_dir gespeichert.Nach dem Training können Sie das trainierte GPT-Modell zur Textgenerierung verwenden. Hier ist ein Beispiel für die Verwendung des trainierten Modells zur Inferenz:
python scripts/inference_gpt.py
--config_path config/shakespearean_config.json
--weights_path weights/GPT_model_char.pt
--max_length 500
--prompt " Once upon a time " 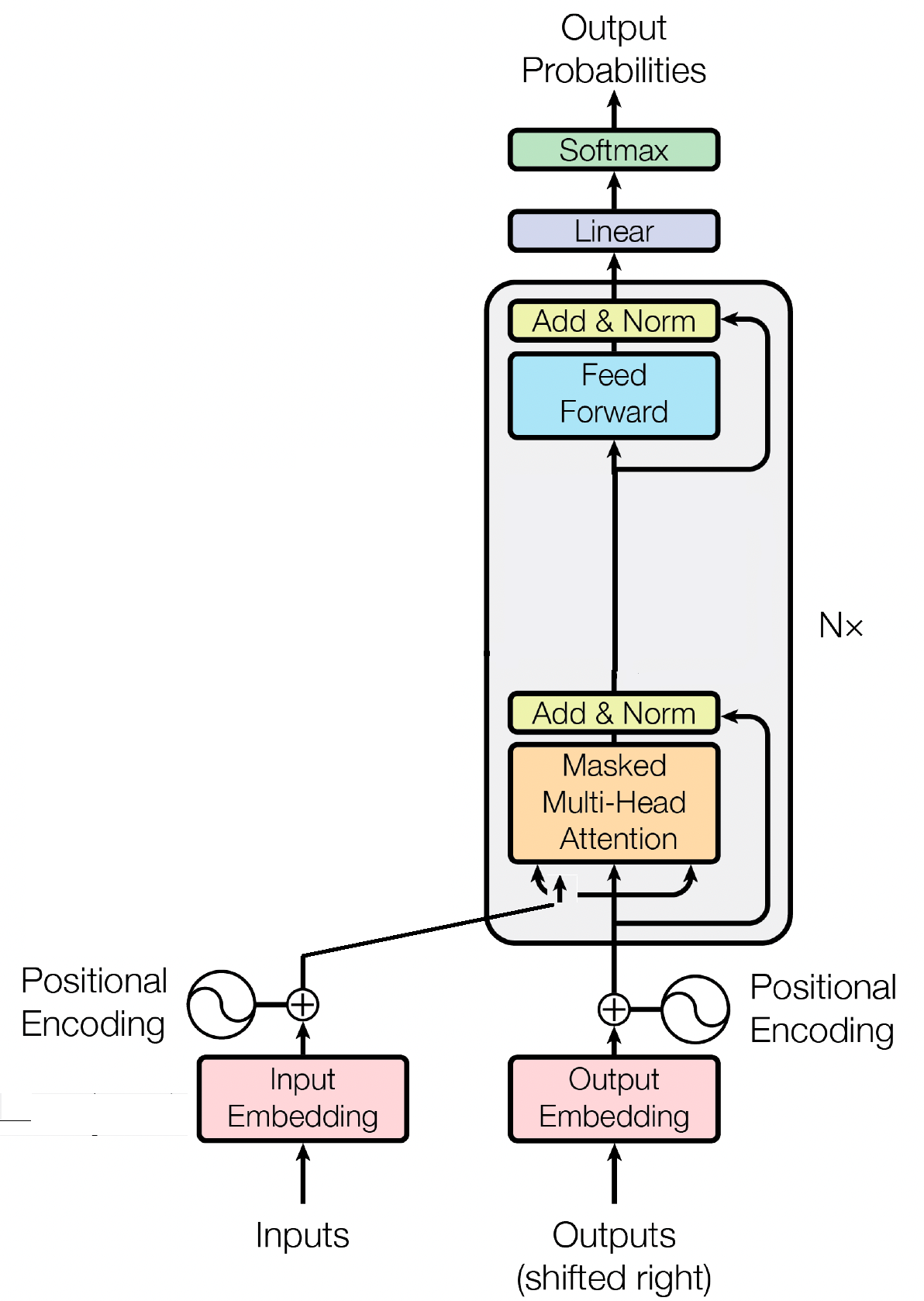
Der Decoderblock ist eine entscheidende Komponente des GPT-Modells (Generative Pre-trained Transformer). Hier generiert GPT tatsächlich den Text. Es nutzt den Selbstaufmerksamkeitsmechanismus, um Eingabesequenzen zu verarbeiten und kohärente Ausgaben zu generieren. Jeder Decoderblock besteht aus mehreren Schichten, einschließlich Selbstaufmerksamkeitsschichten, Feed-Forward-Neuronalen Netzen und Schichtnormalisierung. Die Selbstaufmerksamkeitsebenen ermöglichen es dem Modell, die Bedeutung verschiedener Wörter in einer Sequenz abzuwägen und Kontext und Abhängigkeiten unabhängig von ihrer Position zu erfassen. Dadurch kann das GPT-Modell kontextrelevanten Text generieren.
Eingabeeinbettungen spielen in transformatorbasierten Modellen wie GPT eine entscheidende Rolle, indem sie Eingabetokens in aussagekräftige numerische Darstellungen umwandeln. Diese Einbettungen dienen als erste Eingabe für das Modell und erfassen semantische Informationen über die Wörter in der Sequenz. Der Prozess umfasst die Abbildung jedes Tokens in der Eingabesequenz auf einen hochdimensionalen Vektorraum, in dem ähnliche Token näher beieinander positioniert sind. Dadurch kann das Modell die Beziehungen zwischen verschiedenen Wörtern verstehen und effektiv aus den Eingabedaten lernen. Die Eingabeeinbettungen werden dann zur weiteren Verarbeitung in die nachfolgenden Schichten des Modells eingespeist.
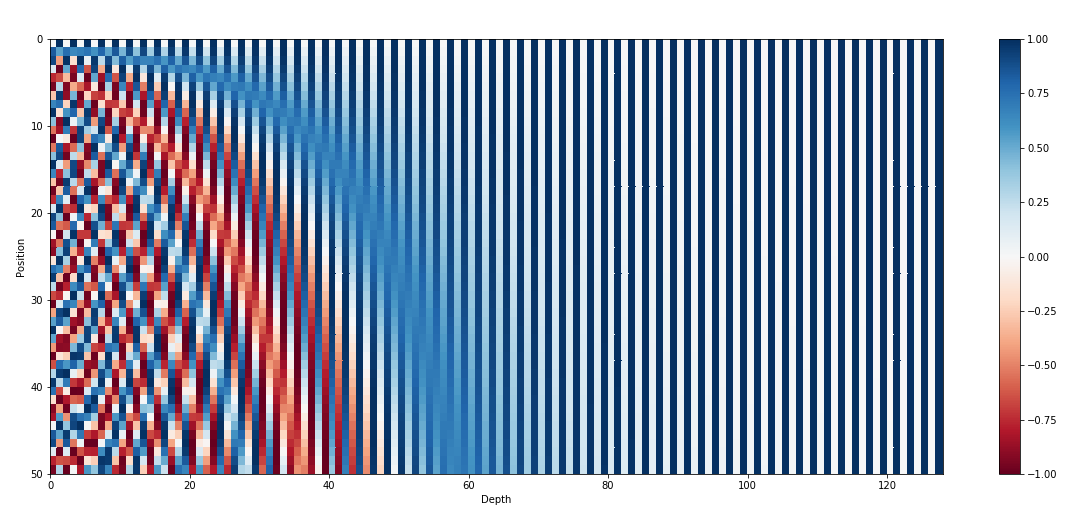
Neben Eingabeeinbettungen sind Positionseinbettungen eine weitere wichtige Komponente von Transformatorarchitekturen wie GPT. Da es Transformatoren an inhärenten Informationen über die Reihenfolge der Token in einer Sequenz mangelt, werden Positionseinbettungen eingeführt, um das Modell mit Positionsinformationen zu versorgen. Diese Einbettungen kodieren die Position jedes Tokens innerhalb der Sequenz, sodass das Modell Token anhand ihrer Positionen unterscheiden kann. Durch die Integration von Positionseinbettungen können Transformatoren wie GPT die sequentielle Natur von Daten effektiv erfassen und kohärente Ausgaben generieren, die die korrekte Reihenfolge der Wörter im generierten Text beibehalten.

Selbstaufmerksamkeit, ein grundlegender Mechanismus in transformatorbasierten Modellen wie GPT, funktioniert durch die Zuweisung von Wichtigkeitswerten zu verschiedenen Wörtern in einer Sequenz. Dieser Prozess umfasst drei Schlüsselschritte: Berechnen von Aufmerksamkeitswerten, Anwenden von Softmax zum Erhalten von Aufmerksamkeitsgewichten und schließlich Kombinieren dieser Gewichte mit den Eingabeeinbettungen, um kontextbezogene Darstellungen zu generieren. Im Kern ermöglicht die Selbstaufmerksamkeit dem Modell, sich mehr auf relevante Wörter zu konzentrieren und weniger wichtige Wörter weniger hervorzuheben, was ein effektives Lernen kontextueller Abhängigkeiten innerhalb der Eingabedaten erleichtert. Dieser Mechanismus ist von entscheidender Bedeutung für die Erfassung weitreichender Abhängigkeiten und kontextueller Nuancen und ermöglicht es Transformatormodellen, lange Textsequenzen zu generieren.
MIT © Shrirang Mahajan
Fühlen Sie sich frei, Pull-Anfragen einzureichen, Probleme zu erstellen oder die Nachricht zu verbreiten!
Unterstützen Sie mich, indem Sie einfach dieses Repository markieren!


