mae
1.0.0
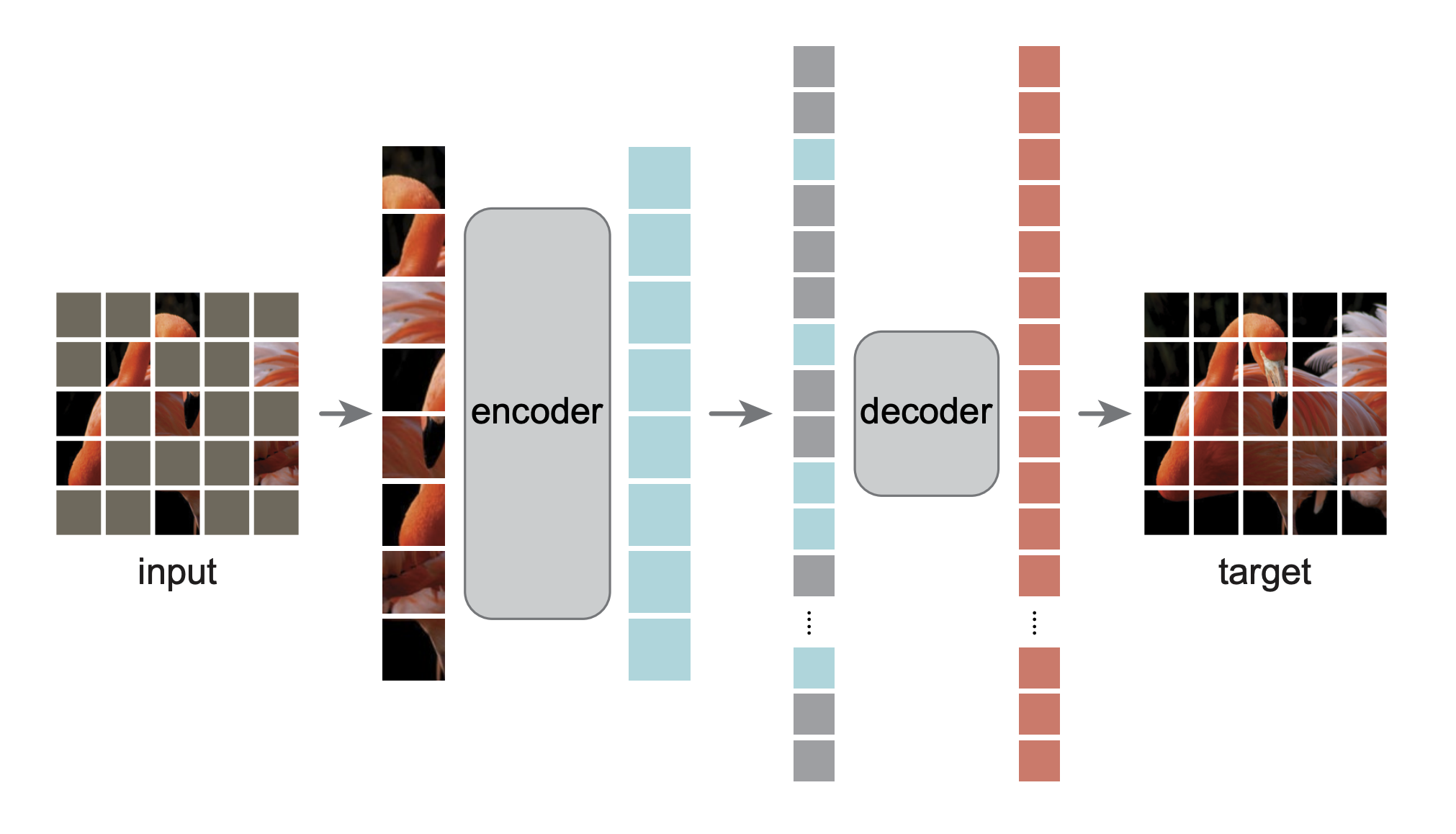
Dies ist eine PyTorch/GPU-Neuimplementierung des Artikels Masked Autoencoders Are Scalable Vision Learners:
@Article{MaskedAutoencoders2021,
author = {Kaiming He and Xinlei Chen and Saining Xie and Yanghao Li and Piotr Doll{'a}r and Ross Girshick},
journal = {arXiv:2111.06377},
title = {Masked Autoencoders Are Scalable Vision Learners},
year = {2021},
}
Die ursprüngliche Implementierung erfolgte in TensorFlow+TPU. Diese Neuimplementierung erfolgt in PyTorch+GPU.
Dieses Repo ist eine Modifikation des DeiT-Repos. Installation und Vorbereitung folgen diesem Repo.
Dieses Repo basiert auf timm==0.3.2 , für das ein Fix erforderlich ist, um mit PyTorch 1.8.1+ zu funktionieren.
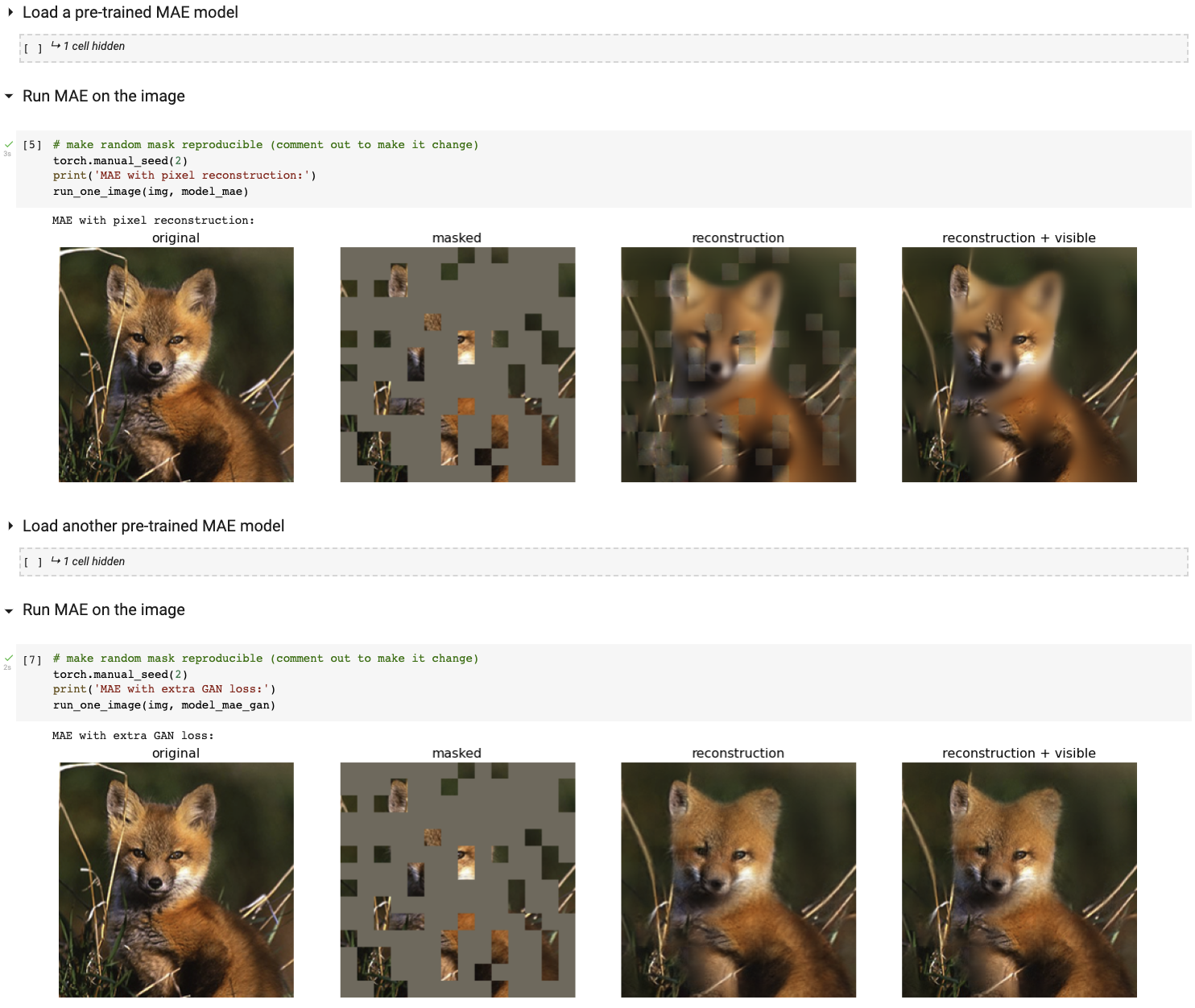
Führen Sie unsere interaktive Visualisierungsdemo mit Colab Notebook aus (keine GPU erforderlich):
Die folgende Tabelle enthält die im Dokument verwendeten vorab trainierten Prüfpunkte, konvertiert von TF/TPU in PT/GPU:
| ViT-Basis | ViT-Groß | ViT-Riesig | |
|---|---|---|---|
| vorab trainierter Kontrollpunkt | herunterladen | herunterladen | herunterladen |
| md5 | 8cad7c | b8b06e | 9bdbb0 |
Die Anleitung zur Feinabstimmung finden Sie in FINETUNE.md.
Durch die Feinabstimmung dieser vorab trainierten Modelle erreichen wir den ersten Platz bei diesen Klassifizierungsaufgaben (im Detail im Artikel beschrieben):
| ViT-B | ViT-L | ViT-H | ViT-H 448 | prev am besten | |
|---|---|---|---|---|---|
| ImageNet-1K (keine externen Daten) | 83,6 | 85,9 | 86,9 | 87,8 | 87.1 |
| Im Folgenden finden Sie eine Bewertung derselben Modellgewichte (feinabgestimmt im ursprünglichen ImageNet-1K): | |||||
| ImageNet-Korruption (Fehlerrate) | 51.7 | 41.8 | 33.8 | 36.8 | 42,5 |
| ImageNet-Adversarial | 35.9 | 57.1 | 68.2 | 76,7 | 35.8 |
| ImageNet-Wiedergabe | 48.3 | 59.9 | 64,4 | 66,5 | 48,7 |
| ImageNet-Skizze | 34.5 | 45.3 | 49,6 | 50.9 | 36,0 |
| Im Folgenden finden Sie Transferlernen durch Feinabstimmung des vorab trainierten MAE auf den Zieldatensatz: | |||||
| iNaturalists 2017 | 70,5 | 75,7 | 79,3 | 83,4 | 75,4 |
| iNaturalists 2018 | 75,4 | 80.1 | 83,0 | 86,8 | 81.2 |
| iNaturalists 2019 | 80,5 | 83,4 | 85,7 | 88,3 | 84.1 |
| Orte205 | 63,9 | 65,8 | 65,9 | 66,8 | 66,0 |
| Orte365 | 57.9 | 59.4 | 59,8 | 60.3 | 58,0 |
Die Anleitung vor dem Training finden Sie in PRETRAIN.md.
Dieses Projekt steht unter der CC-BY-NC 4.0-Lizenz. Weitere Informationen finden Sie unter LIZENZ.


