nmt
1.0.0
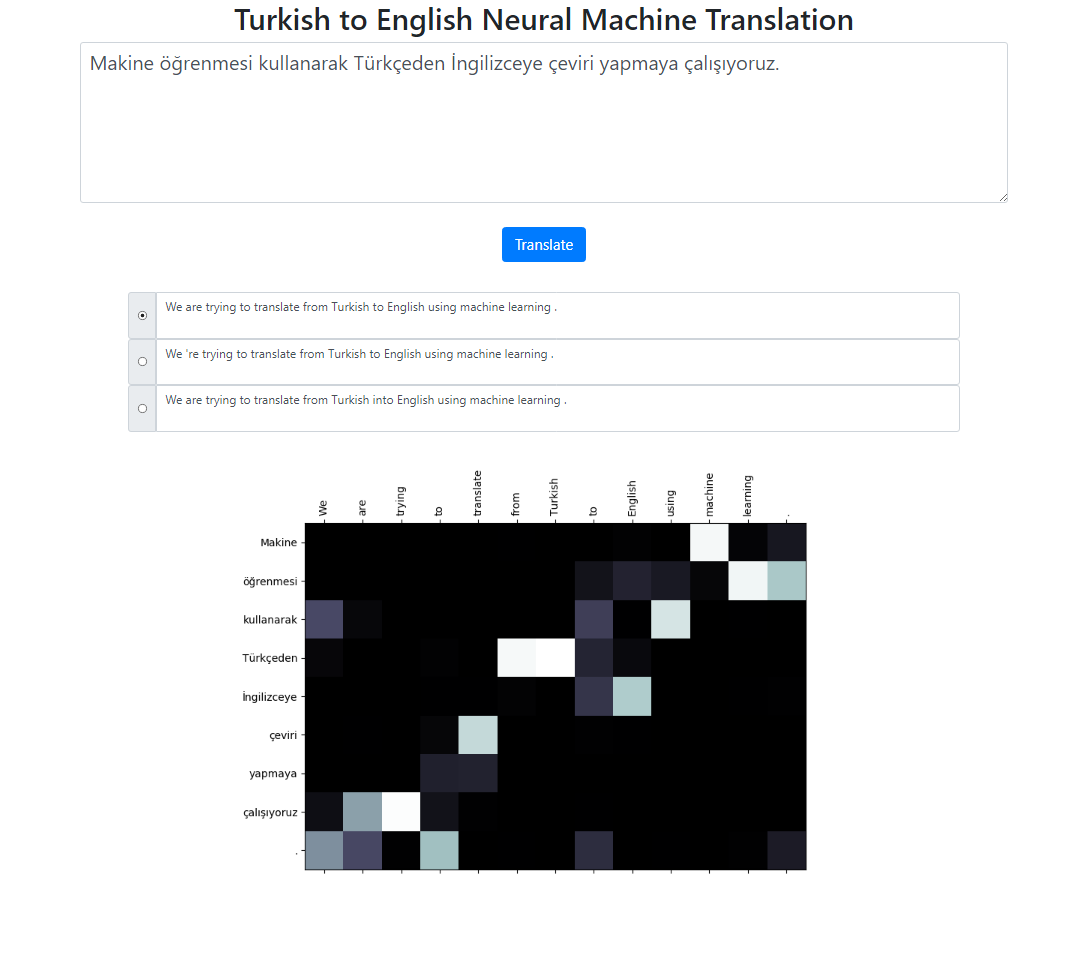
Dieses Repository implementiert ein neuronales maschinelles Übersetzungssystem vom Türkischen ins Englische unter Verwendung des Seq2Seq + Global Attention-Modells. Es gibt auch eine Flask-Anwendung, die Sie lokal ausführen können. Sie können den Text eingeben, übersetzen und die Ergebnisse sowie die Aufmerksamkeitsvisualisierung überprüfen. Wir führen im Hintergrund eine Strahlsuche mit Strahlgröße 3 durch und geben die wahrscheinlichsten Sequenzen sortiert nach ihrer relativen Punktzahl zurück.
Der Datensatz für dieses Projekt stammt von hier. Ich habe das Tatoeba-Korpus verwendet. Ich habe einige der in den Daten gefundenen Duplikate gelöscht. Ich habe den Datensatz auch vorab tokenisiert. Die endgültige Version finden Sie im Datenordner.
Zum Tokenisieren der türkischen Sätze habe ich den RegexpTokenizer des nltk verwendet.
puncts_exclus_apostrophe = '!"#$%&()*+,-./:;<=>?@[]^_`{|}~'TOKENIZE_PATTERN = fr"[{puncts_exclus_apostrophe}]|w+|['w ]+"regex_tokenizer = RegexpTokenizer(pattern=TOKENIZE_PATTERN)text = "Titanic 15. September 2019 02:20'de Battı. "tokenized_text = regex_tokenizer.tokenize(text)print(" ".join(tokenized_text))# Output: Titanic 15. September um 02:20 Uhr .# This splitting property on "02: 20 " unterscheidet sich vom englischen Tokenizer.# Wir könnten mit solchen Situationen umgehen. Aber ich wollte es einfach halten und sehen, ob # Die Aufmerksamkeitsverteilung auf diese Wörter stimmt mit den englischen Tokens überein.# Es gibt ähnliche Fälle, meist auch an Datumsangaben, wie in diesem Beispiel: 09.02.2019Für die Tokenisierung der englischen Sätze habe ich das englische Modell von spacy verwendet.
en_nlp = spacy.load('en_core_web_sm')text = "Die Titanic sank am Montag, dem 15. April, um 02:20 Uhr."tokenized_text = en_nlp.tokenizer(text)print(" ".join([tok.text für tok in tokenized_text ]))# Ausgabe: Die Titanic sank am Montag, dem 15. April, um 02:20 Uhr.Es wird erwartet, dass türkische und englische Sätze in zwei verschiedenen Dateien vorliegen.
file: train.tr tr_sent_1 tr_sent_2 tr_sent_3 ... file: train.en en_sent_1 en_sent_2 en_sent_3 ...
Bitte führen Sie python train.py -h aus, um die vollständige Liste der Argumente zu erhalten.
Sample usage: python train.py --train_data train.tr train.en --valid_data valid.tr valid.en --n_epochs 30 --batch_size 32 --embedding_dim 256 --hidden_size 256 --num_layers 2 --bidirectional --dropout_p 0.3 --device cuda
Zur Berechnung des Blue-Scores auf Korpusebene.
usage: test.py [-h] --model_file MODEL_FILE --valid_data VALID_DATA [VALID_DATA ...] Neural Machine Translation Testing optional arguments: -h, --help show this help message and exit --model_file MODEL_FILE Model File --valid_data VALID_DATA [VALID_DATA ...] Validation_data Sample Usage: python test.py --model_file model.bin --validation_data valid.tr valid.en
Um die Anwendung lokal auszuführen, führen Sie Folgendes aus:
python app.py
Stellen Sie sicher, dass Ihre Modellpfade in der Datei config.py ordnungsgemäß definiert sind.
Modelldatei
Vokabeldatei
Verwendung von Unterworteinheiten (sowohl für Türkisch als auch für Englisch)
Verschiedene Aufmerksamkeitsmechanismen (Lernen unterschiedlicher Parameter für die Aufmerksamkeit)
Der Grundcode für dieses Projekt stammt aus dem NLP-Kurs der Stanford University: CS224n


