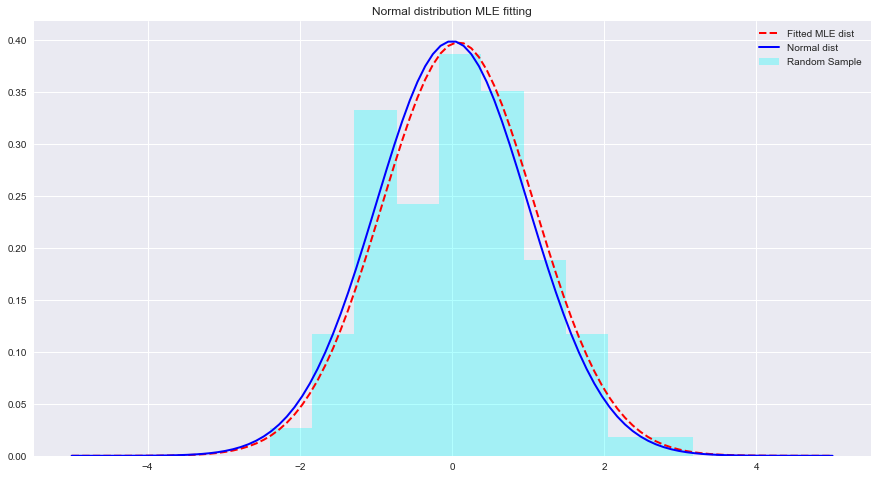
In diesem Labor werden wir die mathematischen Formeln, die wir in der vorherigen Lektion gesehen haben, in die Praxis umsetzen, um zu sehen, wie MLE mit Normalverteilungen funktioniert.
Sie können:
Hinweis: *Eine detaillierte Ableitung aller MLE-Gleichungen mit Beweisen finden Sie auf dieser Website. *
Sehen wir uns unten ein Beispiel für MLE und Verteilungsanpassungen mit Python an. Hier berechnet scipy.stats.norm.fit die Verteilungsparameter mithilfe der Maximum-Likelihood-Schätzung.
from scipy . stats import norm # for generating sample data and fitting distributions
import matplotlib . pyplot as plt
plt . style . use ( 'seaborn' )
import numpy as np sample = Nonestats.norm.fit(data) um eine Verteilung an die oben genannten Daten anzupassen. param = None
#param[0], param[1]
# (0.08241224761452863, 1.002987490235812)x = np.linspace(-5,5,100) x = np . linspace ( - 5 , 5 , 100 )
# Generate the pdf from fitted parameters (fitted distribution)
fitted_pdf = None
# Generate the pdf without fitting (normal distribution non fitted)
normal_pdf = None # Your code here 
# Your comments/observations In dieser kurzen Übung haben wir die Bayes'sche Einstellung in einem Gauß'schen Kontext betrachtet, dh wenn die zugrunde liegenden Zufallsvariablen normalverteilt sind. Wir haben gelernt, dass MLE die unbekannten Parameter einer Normalverteilung schätzen kann, indem es die Wahrscheinlichkeit des erwarteten Mittelwerts maximiert. Der erwartete Mittelwert kommt dem Mittelwert einer nicht angepassten Normalverteilung innerhalb dieses Parameterraums sehr nahe. Wir werden dieses Verständnis weiterentwickeln und lernen, wie solche Schätzungen durchgeführt werden, um Mittelwerte für eine Reihe von in der Datenverteilung vorhandenen Klassen mithilfe des Naive-Bayes-Klassifikators zu schätzen.