mage ai
0.9.75
Verleihen Sie Ihrem Datenteam magische Kräfte.
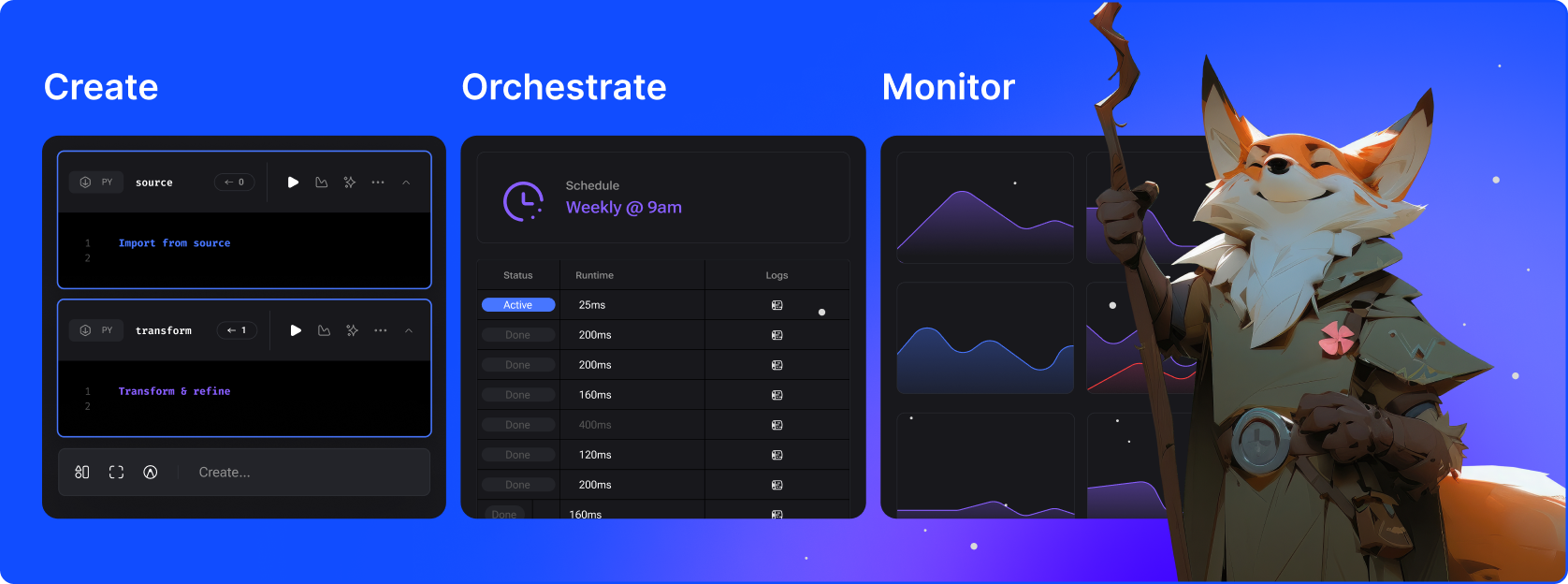
Mage ist ein hybrides Framework zur Transformation und Integration von Daten. Es vereint das Beste aus beiden Welten: die Flexibilität von Notebooks mit der Genauigkeit modularen Codes.
Extrahieren und synchronisieren Sie Daten aus Drittanbieterquellen.
Transformieren Sie Daten mit Echtzeit- und Batch-Pipelines mit Python, SQL und R.
Laden Sie Daten mithilfe unserer vorgefertigten Konnektoren in Ihr Data Warehouse oder Ihren Data Lake.
Führen, überwachen und orchestrieren Sie Tausende von Pipelines, ohne den Schlaf zu verlieren.
Plus Hunderte von Funktionen der Enterprise-Klasse, Infrastrukturinnovationen und magische Überraschungen.
 Für Teams. Vollständig verwaltete Plattform zur Integration und Transformation von Daten. Für Teams. Vollständig verwaltete Plattform zur Integration und Transformation von Daten. |  Selbst gehostet. System zum Erstellen, Ausführen und Verwalten von Datenpipelines. Selbst gehostet. System zum Erstellen, Ausführen und Verwalten von Datenpipelines. |
Eine Dokumentation zu den ersten Schritten, der Entwicklung und der Bereitstellung in der Produktion finden Sie im Live-Stream
Entwicklerdokumentationsportal .
Der empfohlene Weg, die neueste Version von Mage zu installieren, ist über Docker mit dem folgenden Befehl:
Docker Pull mageai/mageai:latest
Sie können Mage auch mit pip oder conda installieren, allerdings kann dies ohne die richtige Umgebung zu Abhängigkeitsproblemen führen.
pip install mage-ai
conda install -c conda-forge mage-ai
Suchen Sie Hilfe? Der schnellste Weg zum Einstieg besteht darin, sich hier unsere Dokumentation anzusehen.
Suchen Sie nach schnellen Beispielen? Öffnen Sie ein Demoprojekt direkt in Ihrem Browser oder schauen Sie sich unsere Anleitungen an.
Erstellen und betreiben Sie eine Datenpipeline mit unserer Demo-App .
WARNUNG
Die Live-Demo ist für jedermann öffentlich, bitte speichern Sie keine sensiblen Daten (z. B. Passwörter, Geheimnisse usw.).

Klicken Sie auf das Bild, um das Video abzuspielen
| Orchestrierung | Planen und verwalten Sie Datenpipelines mit Observability. | |
| Notizbuch | Interaktiver Python-, SQL- und R-Editor zum Codieren von Datenpipelines. | |
| Datenintegrationen | Synchronisieren Sie Daten von Drittanbieterquellen mit Ihren internen Zielen. | |
| Streaming-Pipelines | Erfassen und transformieren Sie Echtzeitdaten. | |
| dbt | Erstellen, führen und verwalten Sie Ihre DBT-Modelle mit Mage. |
Eine Beispieldatenpipeline, die über 3 Dateien hinweg definiert ist ➝
Daten laden ➝
@data_loaderdef load_csv_from_file() -> pl.DataFrame:return pl.read_csv('default_repo/titanic.csv')Daten transformieren ➝
@transformerdef select_columns_from_df(df: pl.DataFrame, *args) -> pl.DataFrame:return df[['Age', 'Fare', 'Survived']]
Daten exportieren ➝
@data_exporterdef export_titanic_data_to_disk(df: pl.DataFrame) -> None:df.to_csv('default_repo/titanic_transformed.csv')

