Transformer Chatbot mit TensorFlow 2
Erstellen Sie einen End-to-End-Chatbot mit Transformer in TensorFlow 2. Sehen Sie sich mein Tutorial auf blog.tensorflow.org an.
Aktualisierungen
- 16. Juni 2022:
- Aktualisieren Sie das Skript
setup.sh um die Apple Silicon-Version von TensorFlow 2.9 zu installieren (verwenden Sie dies nur, wenn Sie abenteuerlustig sind). - Die beiden benutzerdefinierten Ebenen
PositionalEncoding und MultiHeadAttentionLayer wurden aktualisiert, um das Speichern von Modellen über model.save() oder tf.keras.models.save_model() zu ermöglichen. -
train.py zeigt, wie man model.save() und tf.keras.models.load_model() aufruft.
- 8. Dezember 2020: Aktualisierte Unterstützung für TensorFlow 2.3.1 und TensorFlow Datasets 4.1.0
- 18. Januar 2020: Notebook mit Google Colab TPU-Unterstützung in TensorFlow 2.1 hinzugefügt.
Pakete
- TensorFlow 2.9.1
- TensorFlow-Datensätze
Aufstellen
- Erstellen Sie eine neue Anaconda-Umgebung und initialisieren Sie den Umgebungs
chatbot conda create -n chatbot python=3.8
conda activate chatbot
- Führen Sie das Installationsskript aus
- Hinweis: Das Skript installiert CUDA und cuDNN über Conda, wenn es auf einem Linux-System installiert wird, oder
tensorflow-metal für Geräte mit Apple Silicon (Beachten Sie, dass es bei TensorFlow auf der Apple Silicon GPU jede Menge Fehler gibt, z. B. funktioniert der Adam-Optimierer nicht).
Datensatz
- Wir werden die Konversationen in Filmen und Fernsehsendungen, die von Cornell Movie-Dialogs Corpus bereitgestellt werden und mehr als 220.000 Konversationsaustausche zwischen mehr als 10.000 Paaren von Filmcharakteren enthalten, als unseren Datensatz verwenden.
- Wir verarbeiten unseren Datensatz in der folgenden Reihenfolge vor:
- Extrahieren Sie
max_samples Konversationspaare in eine Liste mit questions und answers . - Verarbeiten Sie jeden Satz vor, indem Sie Sonderzeichen in jedem Satz entfernen.
- Erstellen Sie einen Tokenizer (ordnen Sie Text der ID und die ID dem Text zu) mit TensorFlow Datasets SubwordTextEncoder.
- Markieren Sie jeden Satz mit einem Token und fügen Sie
start_token und end_token hinzu, um den Anfang und das Ende jedes Satzes anzugeben. - Filtern Sie Sätze heraus, die mehr als
max_length -Tokens enthalten. - Füllen Sie tokenisierte Sätze auf
max_length auf
- Überprüfen Sie die Implementierung von dataset.py.
Modell
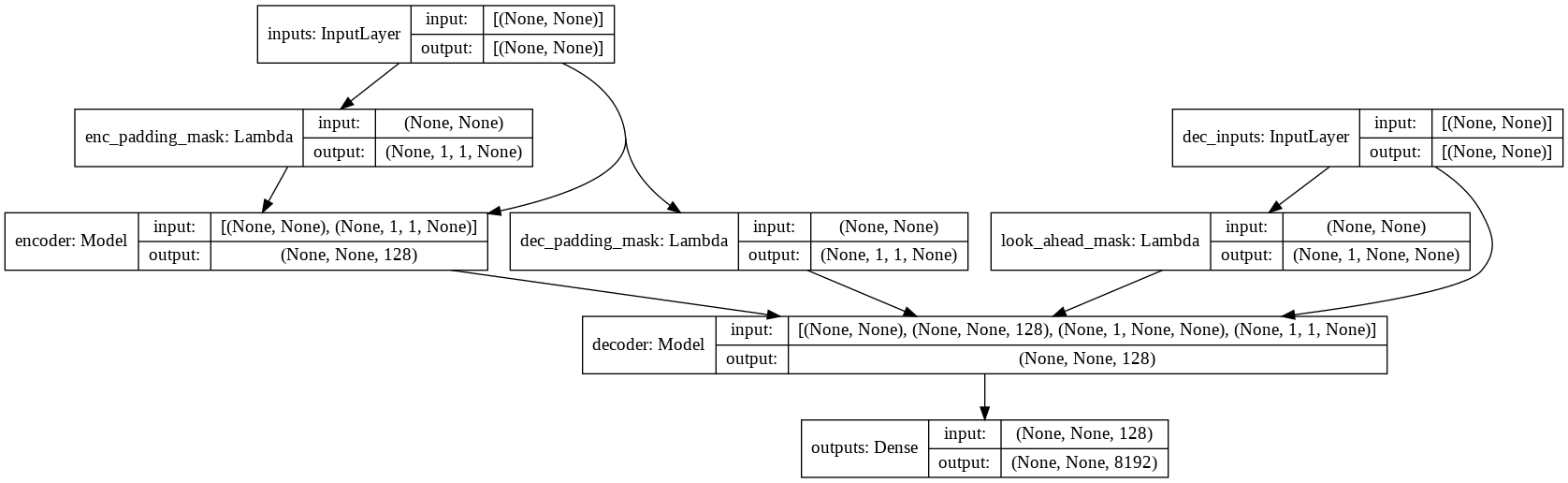
- Überprüfen Sie model.py auf die Implementierung von Multi-Headed Attention, Positional Encoding und Transformer.
Laufen
- Überprüfen Sie alle verfügbaren Flags und Hyperparameter
python main.py --help
python train.py --output_dir runs/save_model --batch_size 256 --epochs 50 --max_samples 50000
- Das endgültig trainierte Modell wird unter
runs/save_model gespeichert.
Proben
input: where have you been?
output: i m not talking about that .
input: it's a trap!
output: no , it s not .


