LLaMA_MPS
1.0.0
Führen Sie die LLaMA- (und Stanford-Alpaca-)Inferenz auf Apple Silicon-GPUs aus.
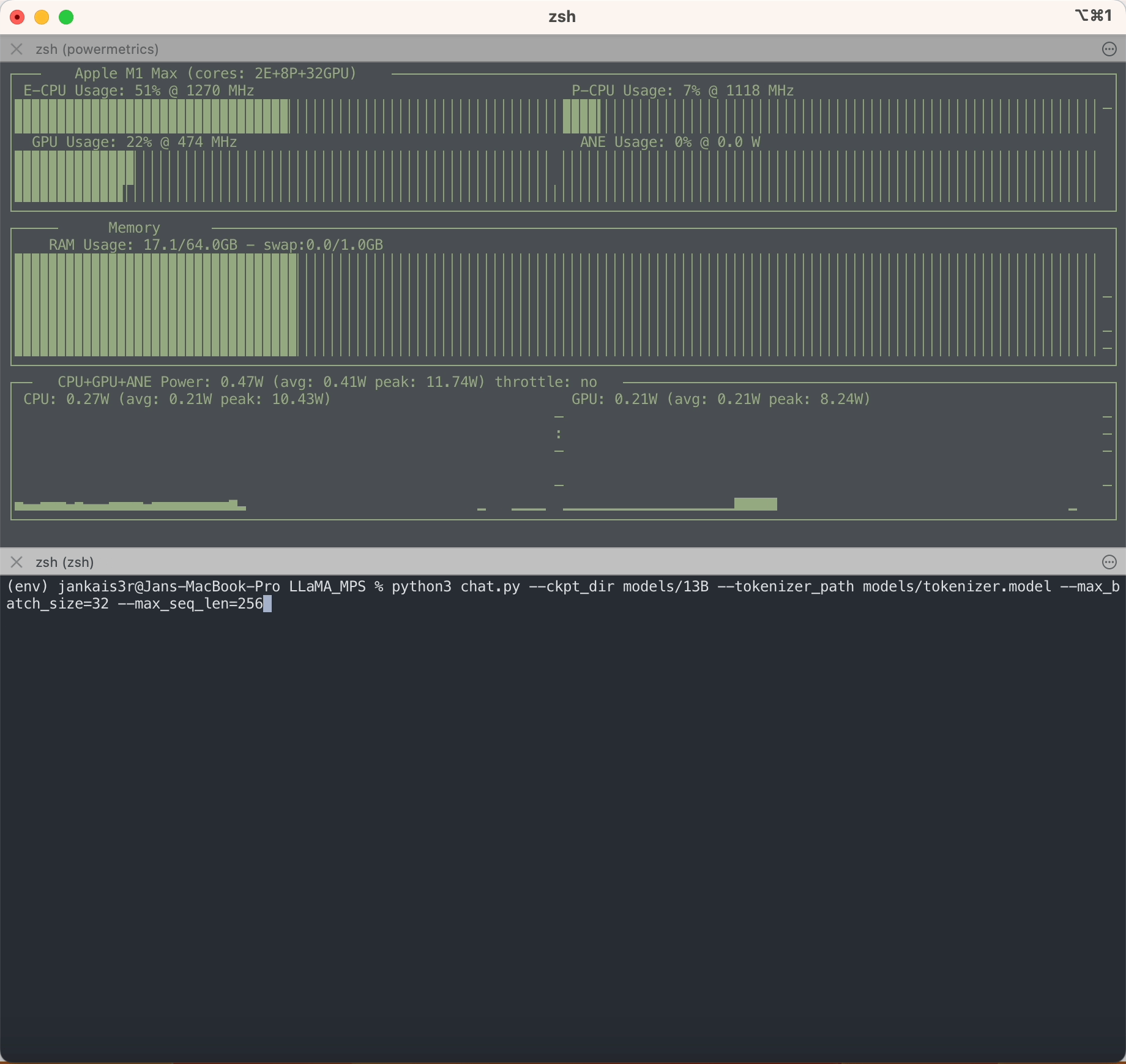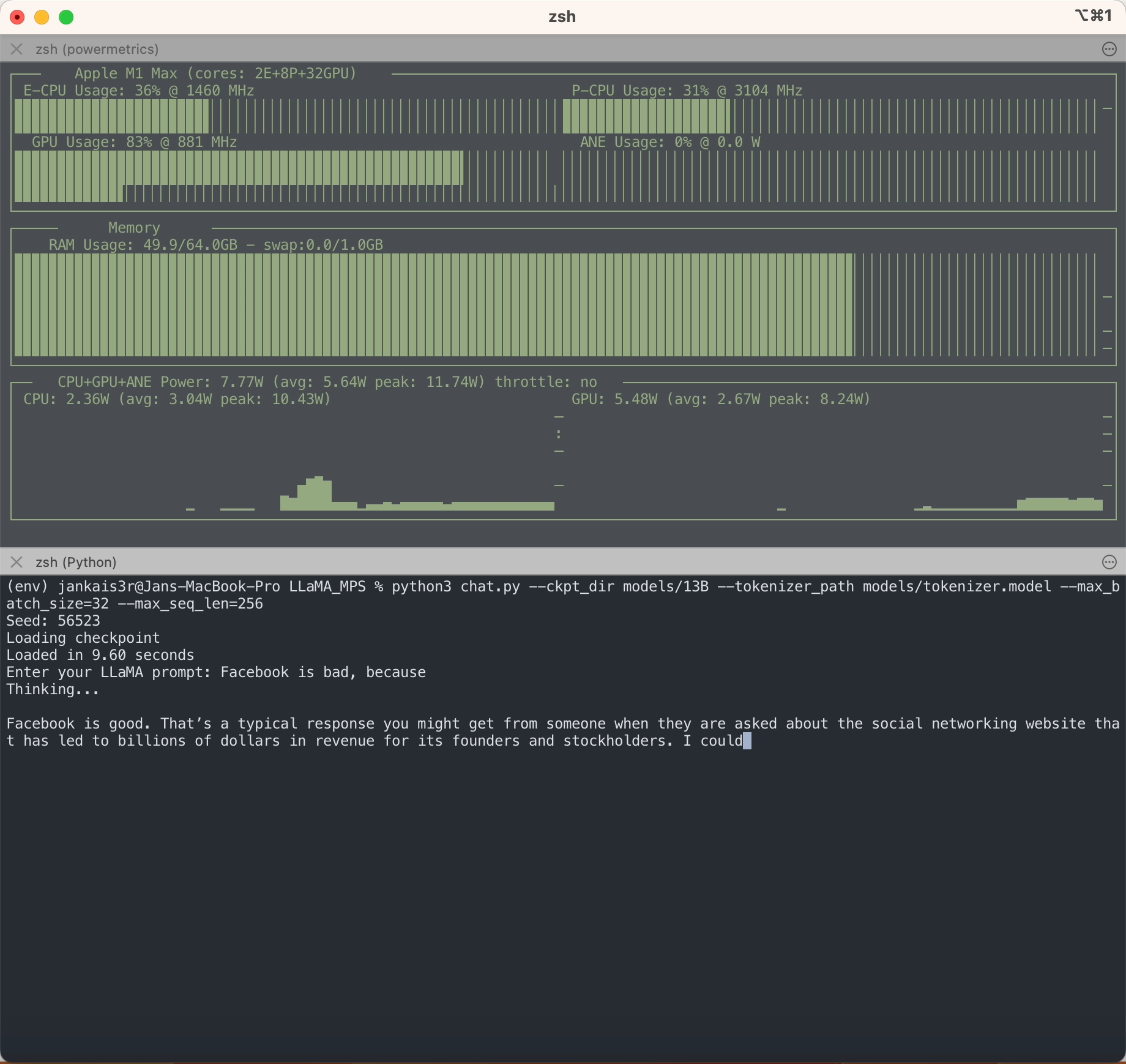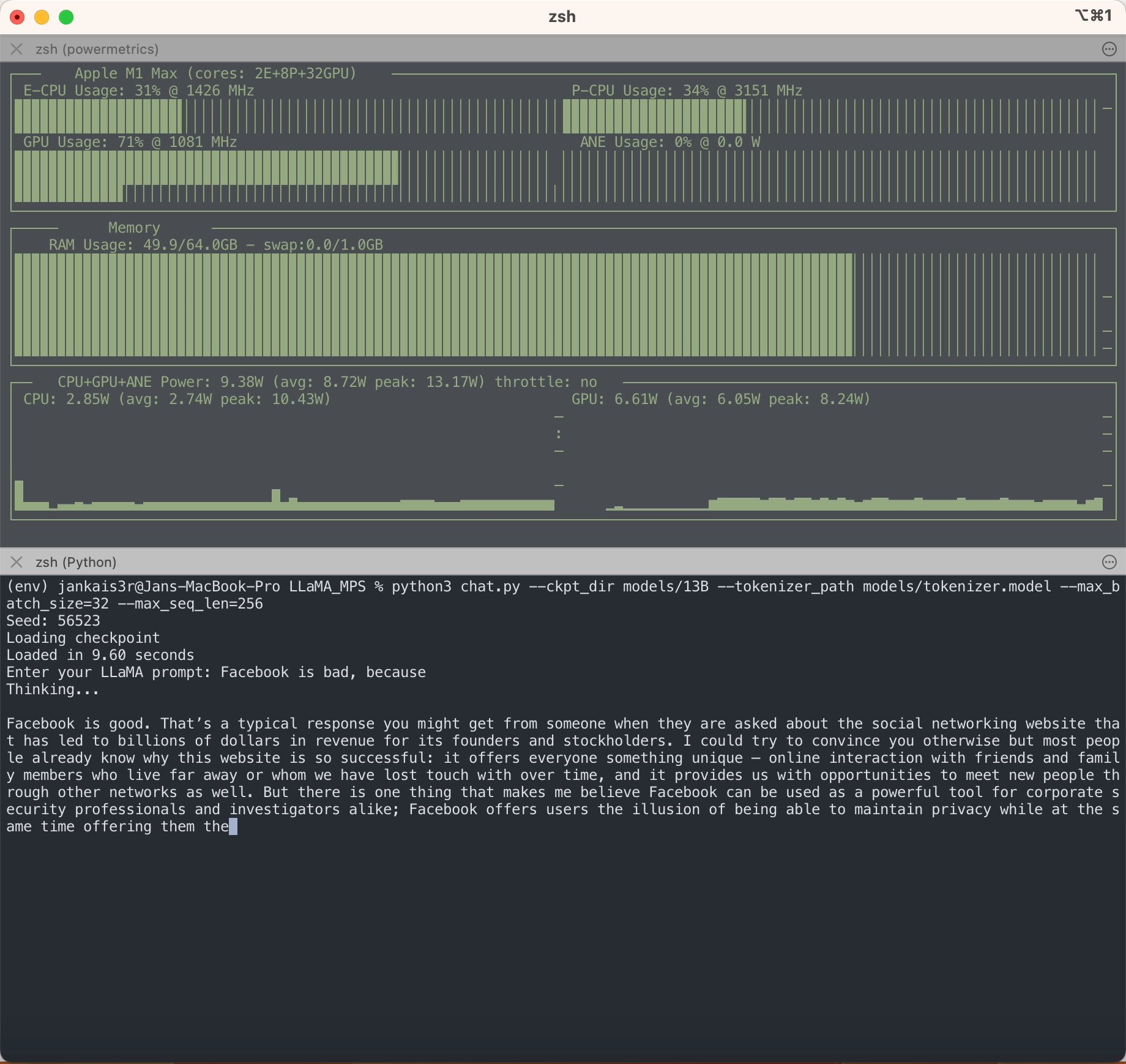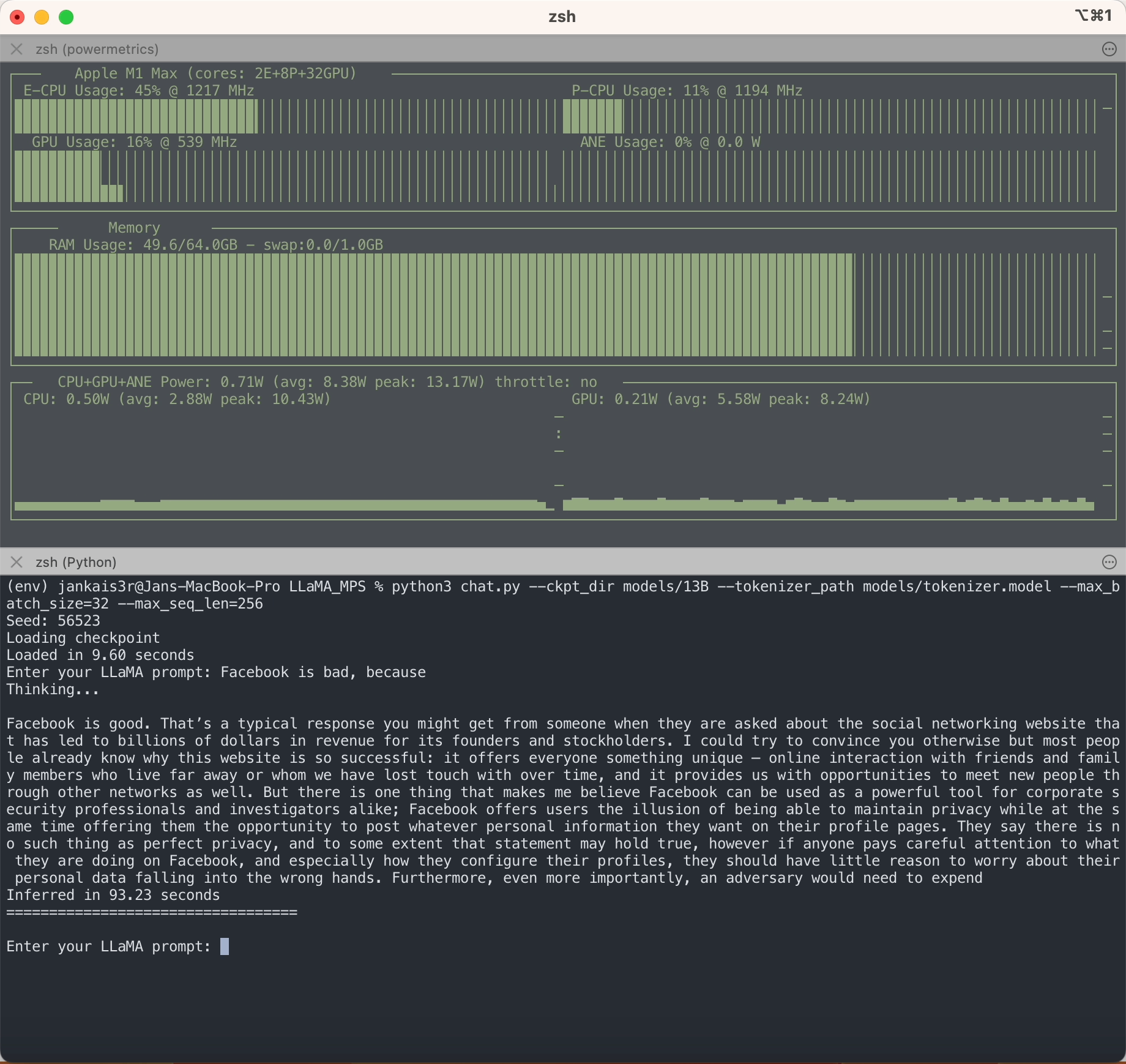
Wie Sie sehen, ist LLaMA im Gegensatz zu anderen LLMs in keiner Weise voreingenommen?
1. Klonen Sie dieses Repo
git clone https://github.com/jankais3r/LLaMA_MPS
2. Installieren Sie Python-Abhängigkeiten
cd LLaMA_MPS
pip3 install virtualenv
python3 -m venv env
source env/bin/activate
pip3 install -r requirements.txt
pip3 install -e . 3. Laden Sie die Modellgewichte herunter und legen Sie sie in einem Ordner namens models ab (z. B. LLaMA_MPS/models/7B ).
4. (Optional) Erneuern Sie die Modellgewichte (13B/30B/65B).
Da wir die Inferenz auf einer einzelnen GPU ausführen, müssen wir die Gewichte der größeren Modelle in einer einzigen Datei zusammenführen.
mv models/13B models/13B_orig
mkdir models/13B
python3 reshard.py 1 models/13B_orig models/13B5. Führen Sie die Inferenz aus
python3 chat.py --ckpt_dir models/13B --tokenizer_path models/tokenizer.model --max_batch_size 8 --max_seq_len 256
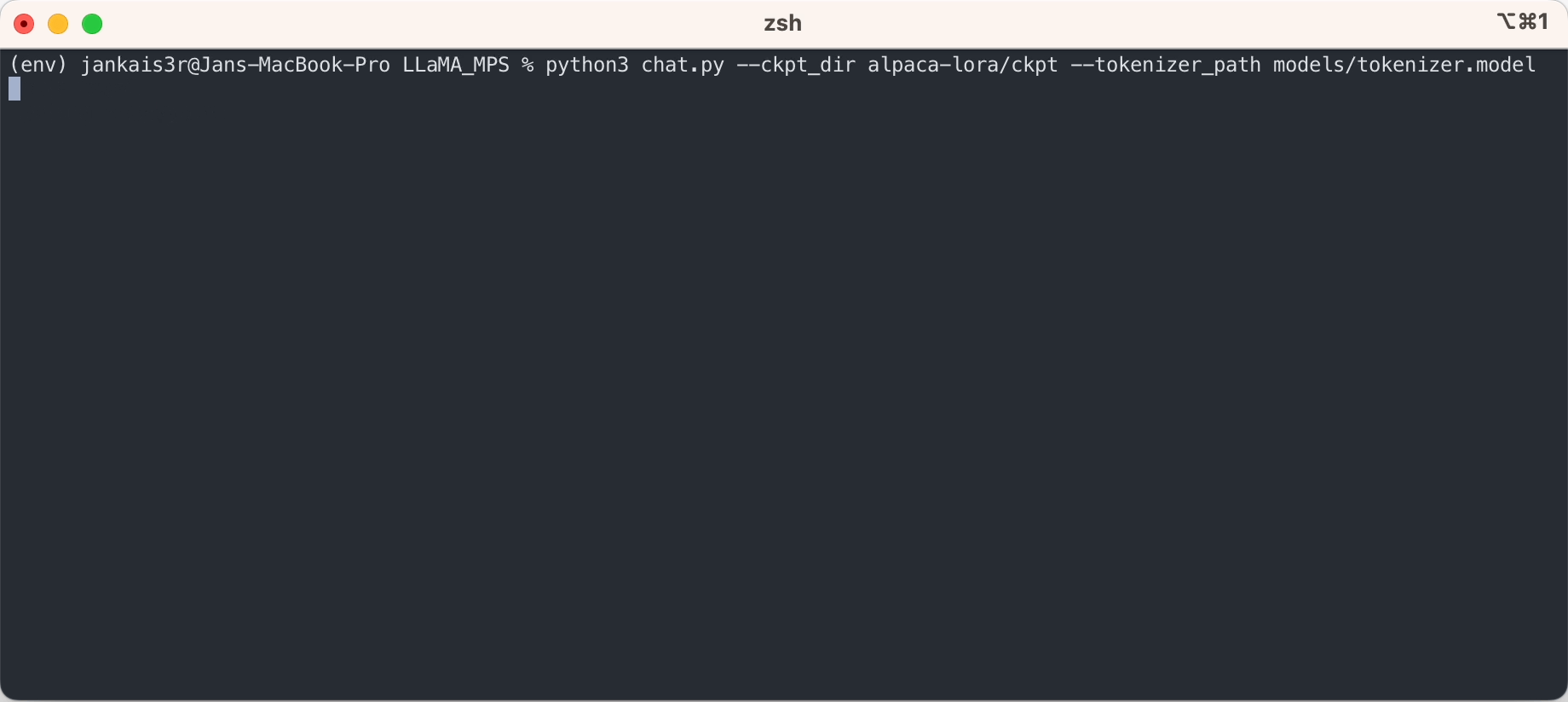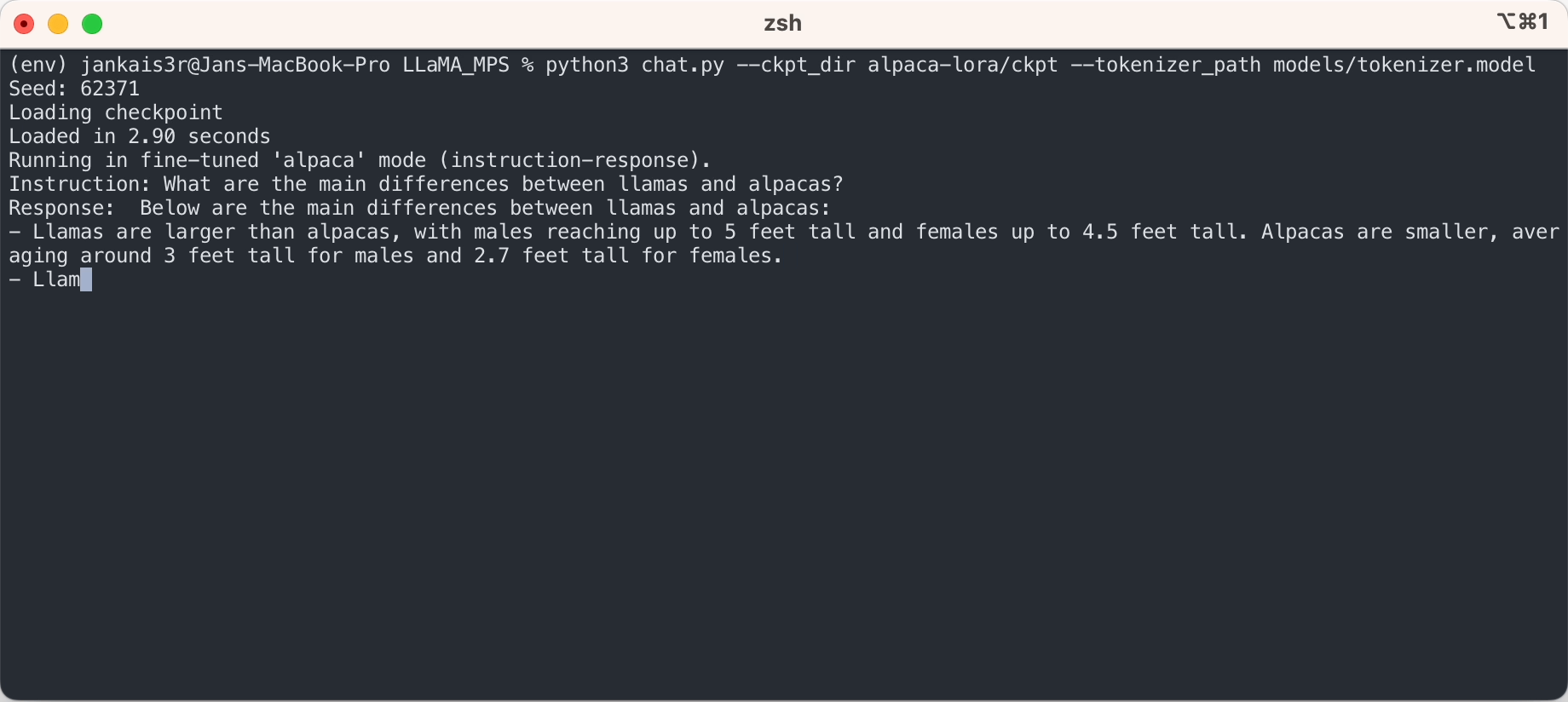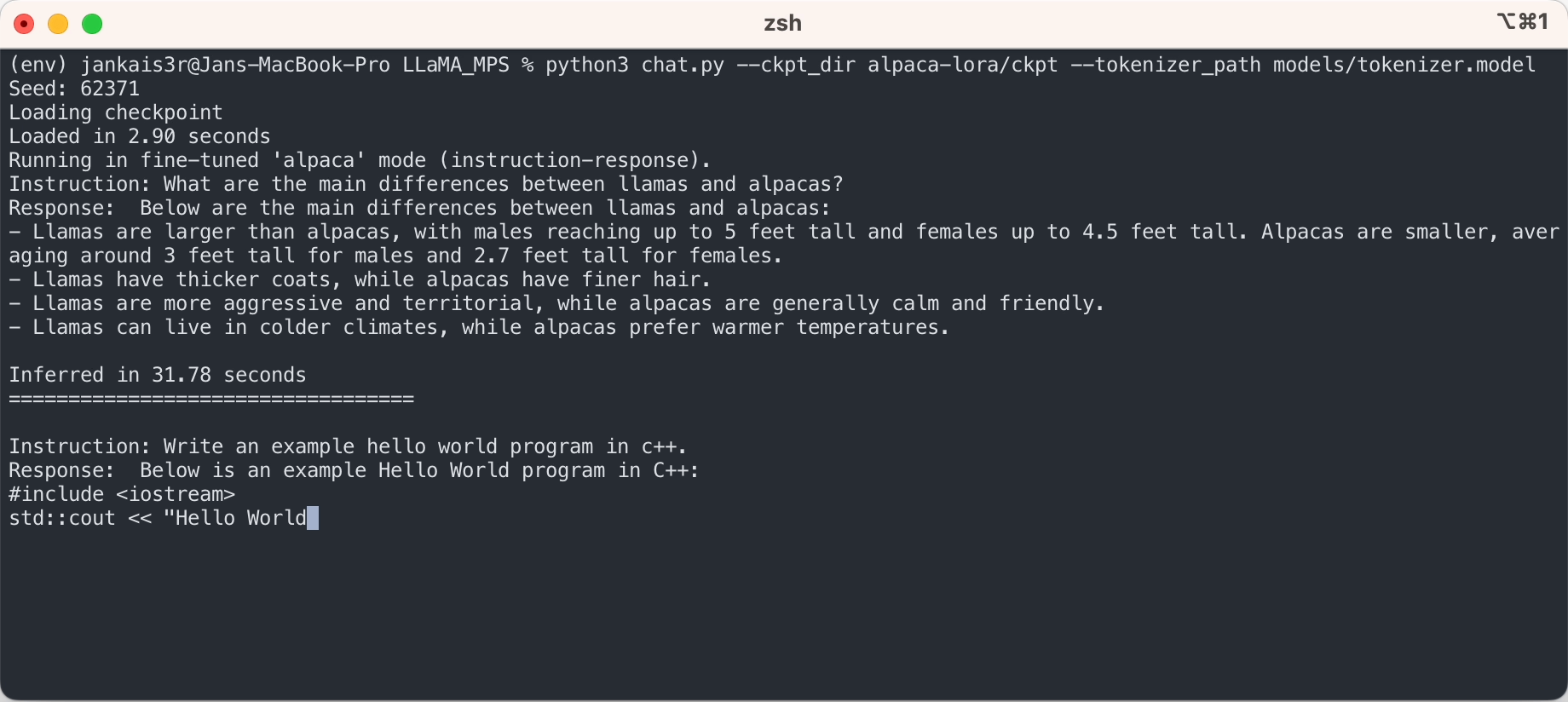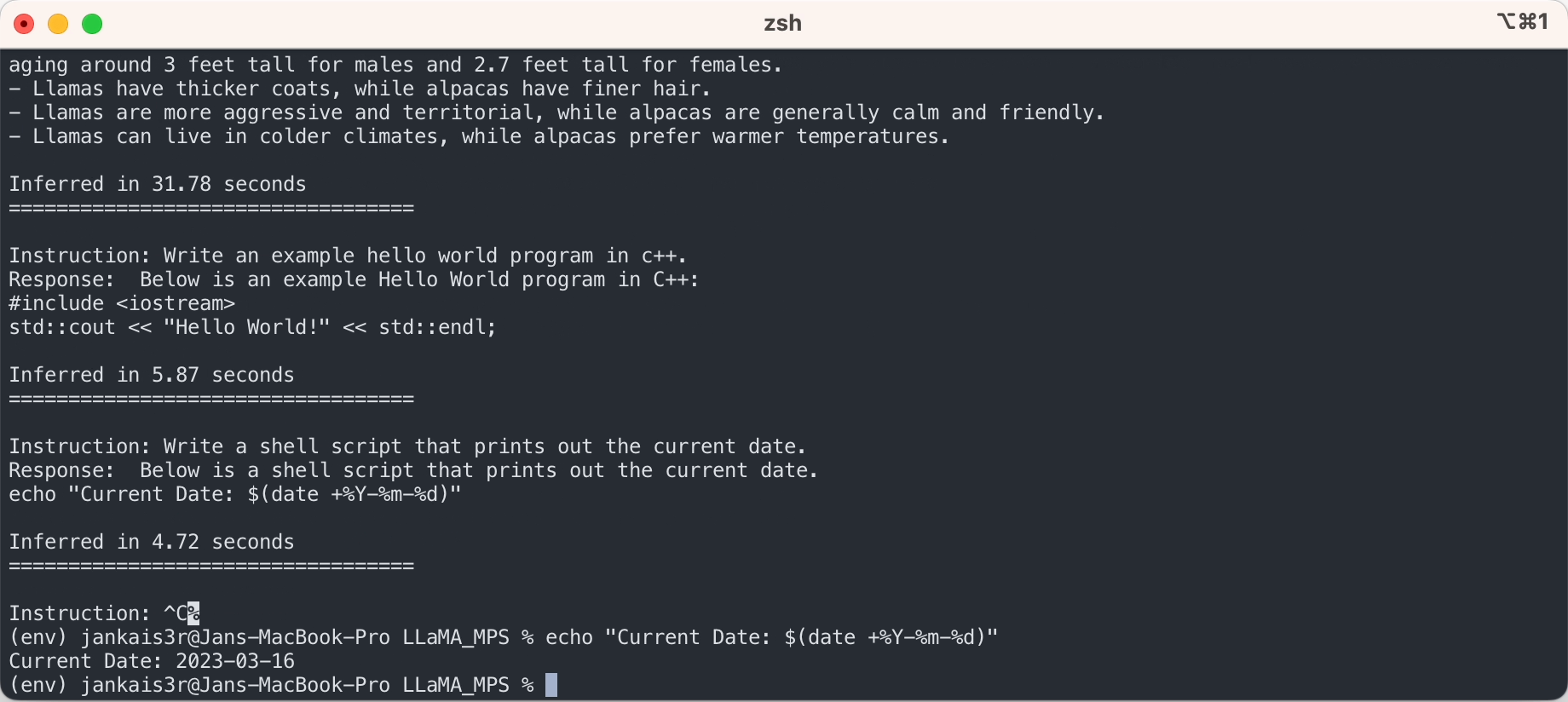
Mit den oben genannten Schritten können Sie Rückschlüsse auf das rohe LLaMA-Modell in einem „Auto-Complete“-Modus ziehen.
Wenn Sie den „Anweisungs-Antwort“-Modus ähnlich wie ChatGPT mit den fein abgestimmten Gewichten von Stanford Alpaca ausprobieren möchten, fahren Sie mit der Einrichtung mit den folgenden Schritten fort:
3. Laden Sie die fein abgestimmten Gewichte herunter (verfügbar für 7B/13B).
python3 export_state_dict_checkpoint.py 7B
python3 clean_hf_cache.py4. Führen Sie die Inferenz aus
python3 chat.py --ckpt_dir models/7B-alpaca --tokenizer_path models/tokenizer.model --max_batch_size 8 --max_seq_len 256
| Modell | Startspeicher während der Inferenz | Spitzenspeicher während der Checkpoint-Konvertierung | Spitzenspeicher während des Reshardings |
|---|---|---|---|
| 7B | 16 GB | 14 GB | N / A |
| 13B | 32 GB | 37 GB | 45 GB |
| 30B | 66 GB | 76 GB | 125 GB |
| 65B | ?? GB | ?? GB | ?? GB |
Mindestspezifikationen pro Modell (langsam aufgrund des Austauschs):
Empfohlene Spezifikationen pro Modell:
- max_batch_size
Wenn Sie über freien Speicher verfügen (z. B. beim Ausführen des 13B-Modells auf einem 64-GB-Mac), können Sie die Stapelgröße mithilfe des Arguments --max_batch_size=32 erhöhen. Der Standardwert ist 1 .
- max_seq_len
Um die maximale Länge des generierten Texts zu erhöhen/verringern, verwenden Sie das Argument --max_seq_len=256 . Der Standardwert ist 512 .
- use_repetition_penalty
Das Beispielskript bestraft das Modell für die Generierung sich wiederholender Inhalte. Dies sollte zu einer qualitativ besseren Ausgabe führen, verlangsamt jedoch die Schlussfolgerung etwas. Führen Sie das Skript mit dem Argument --use_repetition_penalty=False aus, um den Strafalgorithmus zu deaktivieren.
Die beste Alternative zu LLaMA_MPS für Apple Silicon-Benutzer ist llama.cpp, eine C/C++-Neuimplementierung, die die Inferenz ausschließlich auf dem CPU-Teil des SoC ausführt. Da kompilierter C-Code so viel schneller ist als Python, kann er diese MPS-Implementierung tatsächlich in der Geschwindigkeit übertreffen, allerdings auf Kosten einer viel schlechteren Energie- und Wärmeeffizienz.
Sehen Sie sich den folgenden Vergleich an, um zu entscheiden, welche Implementierung besser zu Ihrem Anwendungsfall passt.
| Durchführung | Gesamtlaufzeit – 256 Token | Token/s | Spitzenspeichernutzung | Maximale SoC-Temperatur | Spitzenverbrauch des SoC | Token pro 1 Wh |
|---|---|---|---|---|---|---|
| LLAMA_MPS (13B fp16) | 75 s | 3.41 | 30 GB | 79 °C | 10 W | 1.228,80 |
| llama.cpp (13B fp16) | 70er Jahre | 3,66 | 25 GB | 106 °C | 35 W | 376,16 |


