system design primer
1.0.0
Englisch ∙ 日本語 ∙ 简体中文 ∙ 繁體中文 | العَرَبِيَّة ∙ বাংলা ∙ Português do Brasil ∙ Deutsch ∙ ελληνικά ∙ עברית ∙ Italiano ∙ 한국어 ∙ فارسی ∙ Polski ∙ русский язык ∙ Spanisch ∙ ภาษาไทย ∙ Türkçe ∙ Tiếng Việt ∙ Français | Übersetzung hinzufügen
Helfen Sie mit, diesen Leitfaden zu übersetzen!
Erfahren Sie, wie Sie große Systeme entwerfen.
Bereiten Sie sich auf das Systemdesign-Interview vor.
Wenn Sie lernen, skalierbare Systeme zu entwerfen, werden Sie ein besserer Ingenieur.
Systemdesign ist ein weites Thema. Es gibt im Internet eine große Menge an Ressourcen zu Systemdesignprinzipien.
Dieses Repo ist eine organisierte Sammlung von Ressourcen, die Ihnen dabei helfen, zu lernen, wie Sie Systeme im großen Maßstab erstellen.
Dies ist ein ständig aktualisiertes Open-Source-Projekt.
Beiträge sind willkommen!
Neben der Codierung von Interviews ist das Systemdesign in vielen Technologieunternehmen ein erforderlicher Bestandteil des technischen Interviewprozesses .
Üben Sie häufige Fragen in Vorstellungsgesprächen zum Systemdesign und vergleichen Sie Ihre Ergebnisse mit Beispiellösungen : Diskussionen, Code und Diagramme.
Zusätzliche Themen zur Vorbereitung auf Vorstellungsgespräche:
Die bereitgestellten Anki-Lernkartenstapel verwenden räumliche Wiederholungen, um Ihnen dabei zu helfen, wichtige Systemdesignkonzepte beizubehalten.
Ideal für unterwegs.
Suchen Sie nach Ressourcen, die Ihnen bei der Vorbereitung auf das Coding-Interview helfen?
Schauen Sie sich das Schwester-Repo Interactive Coding Challenges an, das ein zusätzliches Anki-Deck enthält:
Lernen Sie von der Community.
Fühlen Sie sich frei, Pull-Requests einzureichen, um zu helfen:
Inhalte, die etwas Feinschliff benötigen, werden derzeit entwickelt.
Lesen Sie die Beitragsrichtlinien.
Zusammenfassungen verschiedener Systemdesignthemen, einschließlich Vor- und Nachteilen. Alles ist ein Kompromiss .
Jeder Abschnitt enthält Links zu ausführlicheren Ressourcen.
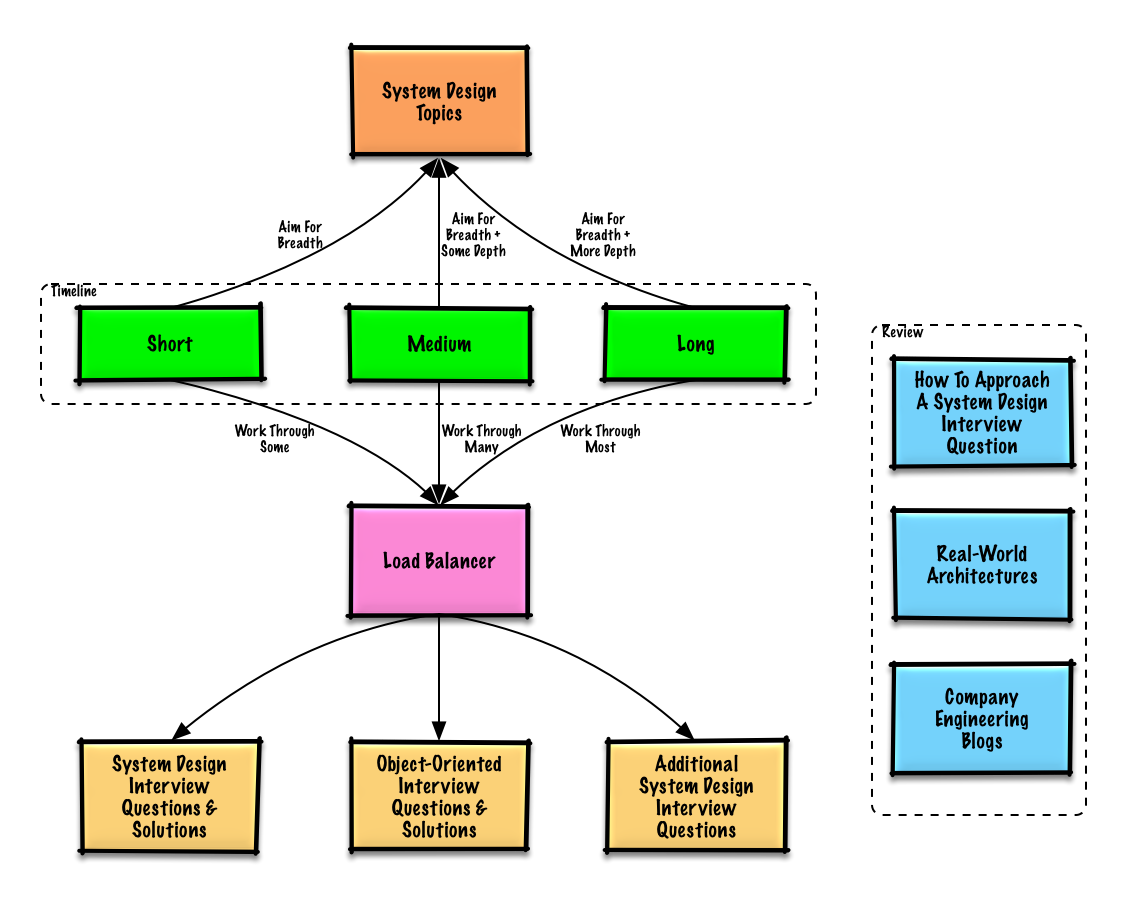
Vorgeschlagene Themen zur Überprüfung basierend auf Ihrem Interviewzeitplan (kurz, mittel, lang).
F: Muss ich für Vorstellungsgespräche hier alles wissen?
A: Nein, Sie müssen hier nicht alles wissen, um sich auf das Vorstellungsgespräch vorzubereiten .
Was Sie in einem Vorstellungsgespräch gefragt werden, hängt von Variablen ab wie:
Von erfahreneren Kandidaten wird im Allgemeinen erwartet, dass sie mehr über Systemdesign wissen. Von Architekten oder Teamleitern kann erwartet werden, dass sie mehr wissen als einzelne Mitwirkende. Top-Technologieunternehmen werden wahrscheinlich eine oder mehrere Design-Interviewrunden abhalten.
Beginnen Sie breit und gehen Sie in einigen Bereichen tiefer. Es ist hilfreich, ein wenig über verschiedene wichtige Systemdesignthemen zu wissen. Passen Sie den folgenden Leitfaden an Ihren Zeitplan, Ihre Erfahrung, die Positionen, für die Sie sich bewerben, und die Unternehmen an, bei denen Sie Vorstellungsgespräche führen.
| Kurz | Medium | Lang | |
|---|---|---|---|
| Lesen Sie die Themen zum Systemdesign durch, um ein umfassendes Verständnis der Funktionsweise von Systemen zu erhalten | ? | ? | ? |
| Lesen Sie einige Artikel in den Engineering-Blogs des Unternehmens für die Unternehmen, mit denen Sie ein Vorstellungsgespräch führen | ? | ? | ? |
| Lesen Sie einige Architekturen aus der realen Welt durch | ? | ? | ? |
| Sehen Sie sich an, wie man eine Frage im Vorstellungsgespräch zum Systemdesign angeht | ? | ? | ? |
| Arbeiten Sie die Fragen im Vorstellungsgespräch zum Systemdesign mit Lösungen durch | Manche | Viele | Am meisten |
| Arbeiten Sie die Interviewfragen zum objektorientierten Design mit Lösungen durch | Manche | Viele | Am meisten |
| Sehen Sie sich die zusätzlichen Fragen zum Systemdesign-Interview an | Manche | Viele | Am meisten |
Wie man eine Frage im Vorstellungsgespräch zum Systemdesign angeht.
Das Systemdesign-Interview ist ein offenes Gespräch . Von Ihnen wird erwartet, dass Sie die Leitung übernehmen.
Sie können die folgenden Schritte als Leitfaden für die Diskussion verwenden. Um diesen Prozess zu festigen, arbeiten Sie den Abschnitt „Fragen zum Systemdesign-Interview mit Lösungen“ mit den folgenden Schritten durch.
Sammeln Sie Anforderungen und grenzen Sie das Problem ein. Stellen Sie Fragen, um Anwendungsfälle und Einschränkungen zu klären. Besprechen Sie Annahmen.
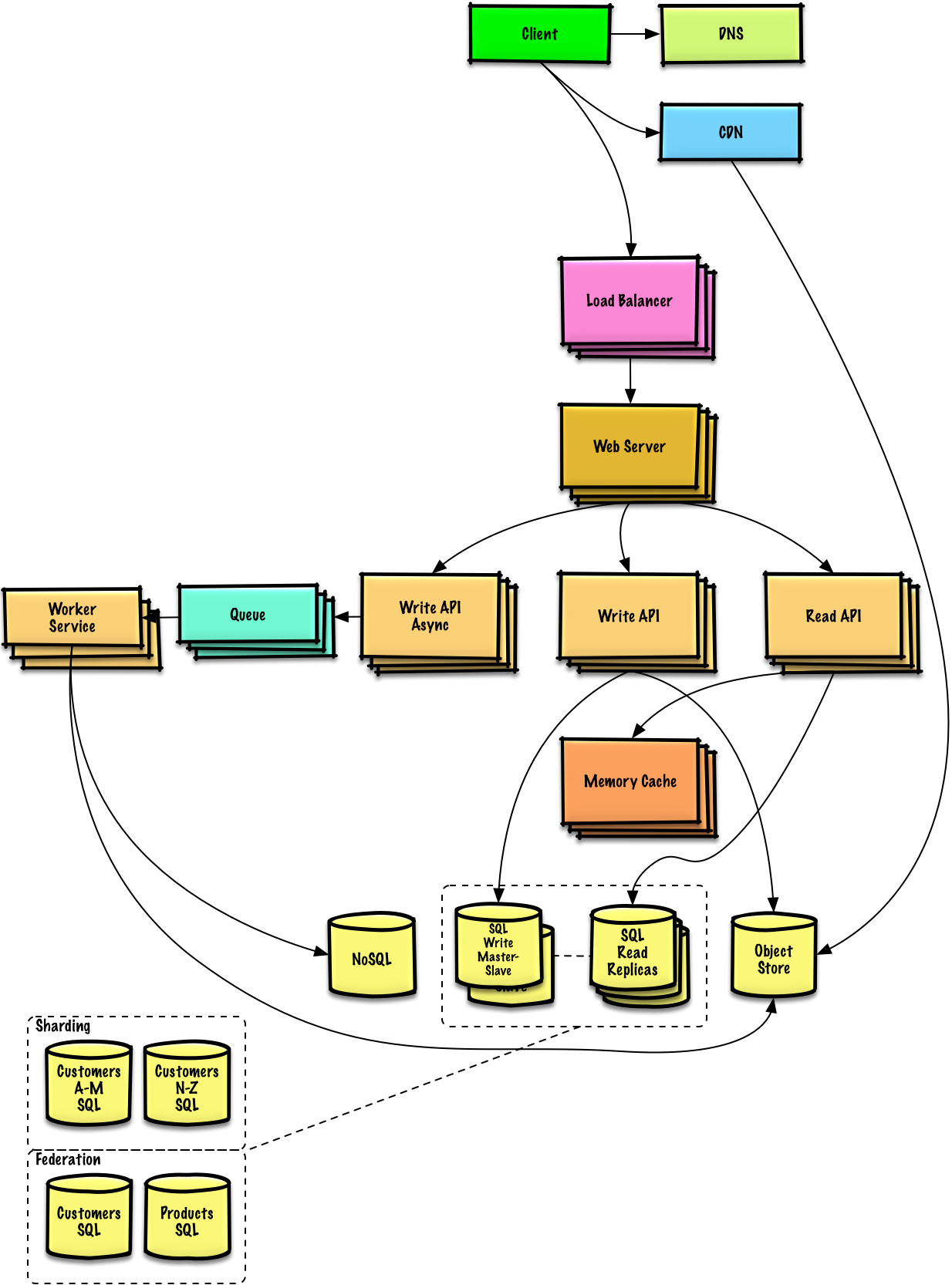
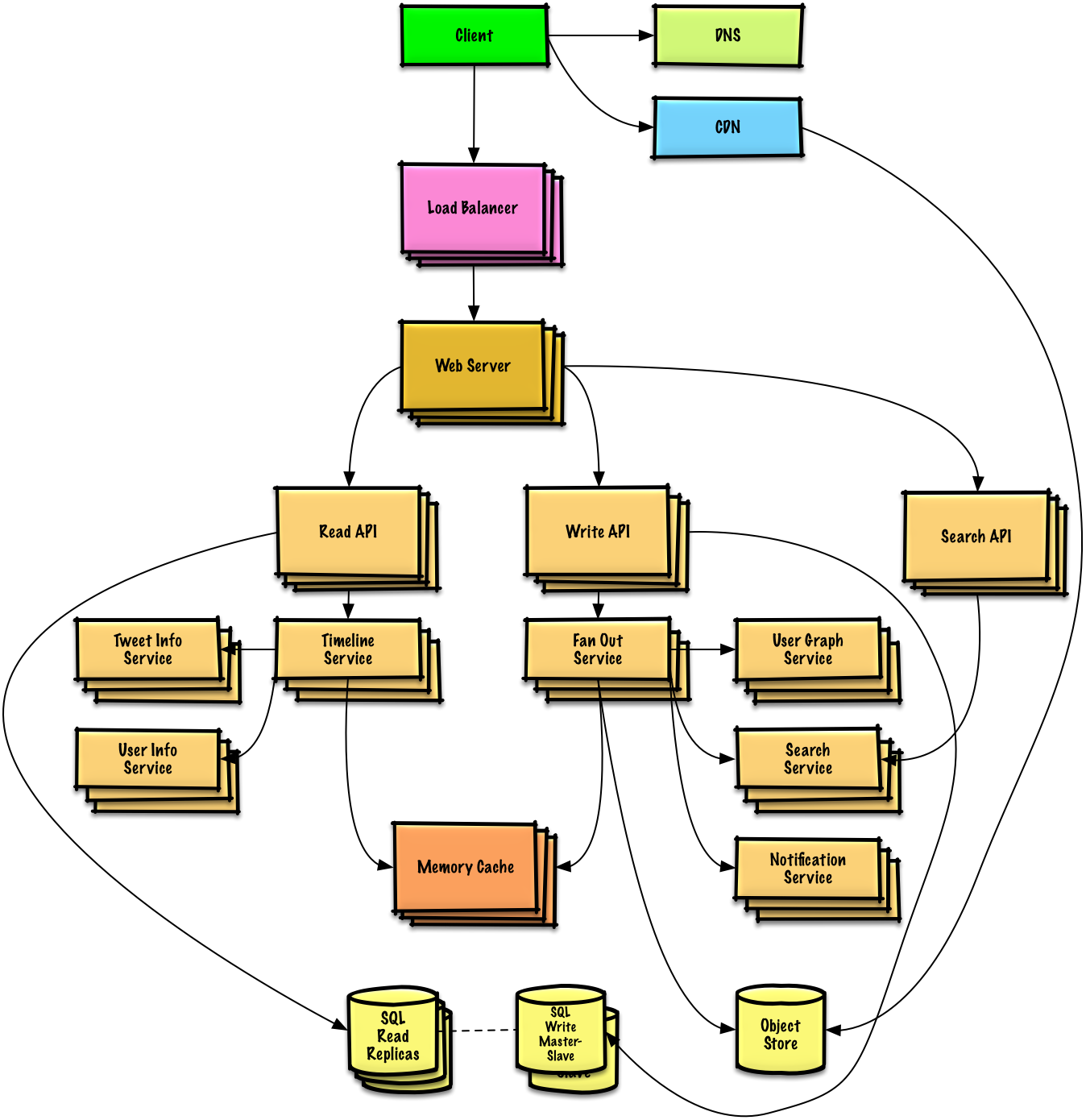
Skizzieren Sie ein High-Level-Design mit allen wichtigen Komponenten.
Tauchen Sie in die Details jeder Kernkomponente ein. Wenn Sie beispielsweise gebeten wurden, einen URL-Verkürzungsdienst zu entwickeln, besprechen Sie Folgendes:
Identifizieren und beheben Sie Engpässe angesichts der Einschränkungen. Benötigen Sie beispielsweise Folgendes, um Skalierbarkeitsprobleme zu lösen?
Besprechen Sie mögliche Lösungen und Kompromisse. Alles ist ein Kompromiss. Beheben Sie Engpässe mithilfe der Prinzipien des skalierbaren Systemdesigns.
Möglicherweise werden Sie gebeten, einige Schätzungen von Hand vorzunehmen. Im Anhang finden Sie die folgenden Ressourcen:
Schauen Sie sich die folgenden Links an, um eine bessere Vorstellung davon zu bekommen, was Sie erwartet:
Häufige Fragen in Vorstellungsgesprächen zum Systemdesign mit Beispieldiskussionen, Code und Diagrammen.
Lösungen, die mit Inhalten im Ordner
solutions/verknüpft sind.
| Frage | |
|---|---|
| Entwerfen Sie Pastebin.com (oder Bit.ly) | Lösung |
| Entwerfen Sie die Twitter-Timeline und die Suche (oder den Facebook-Feed und die Suche) | Lösung |
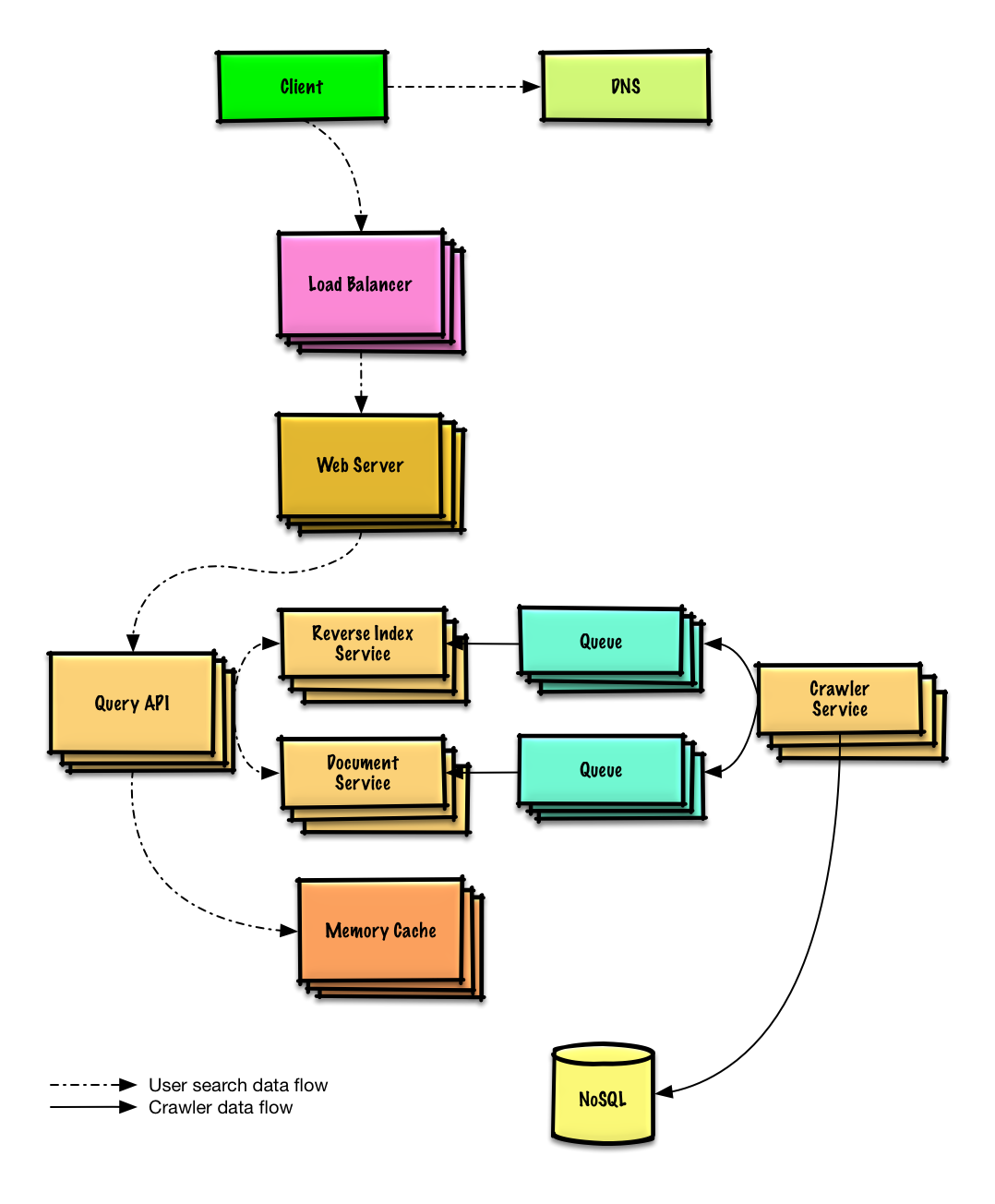
| Entwerfen Sie einen Webcrawler | Lösung |
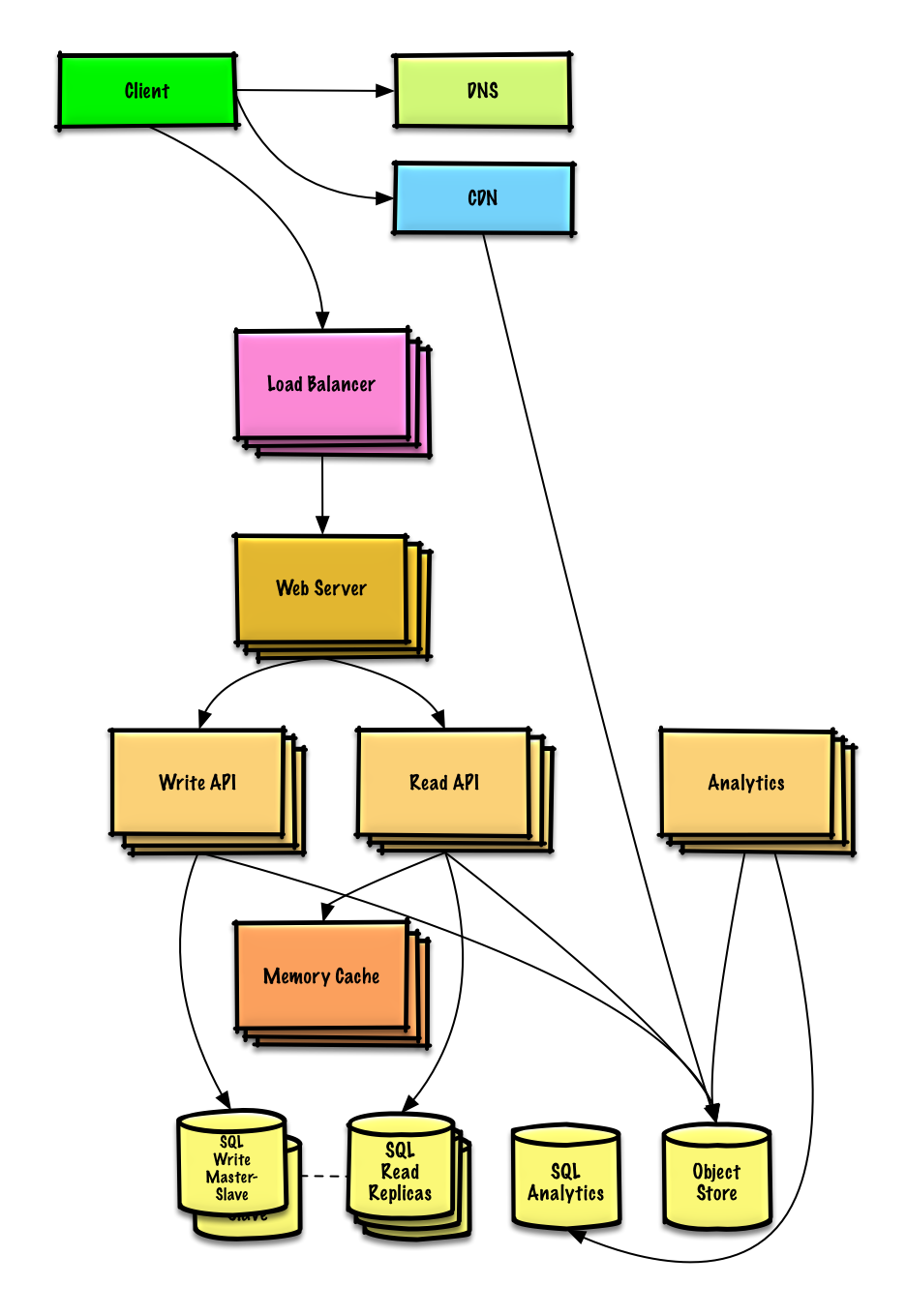
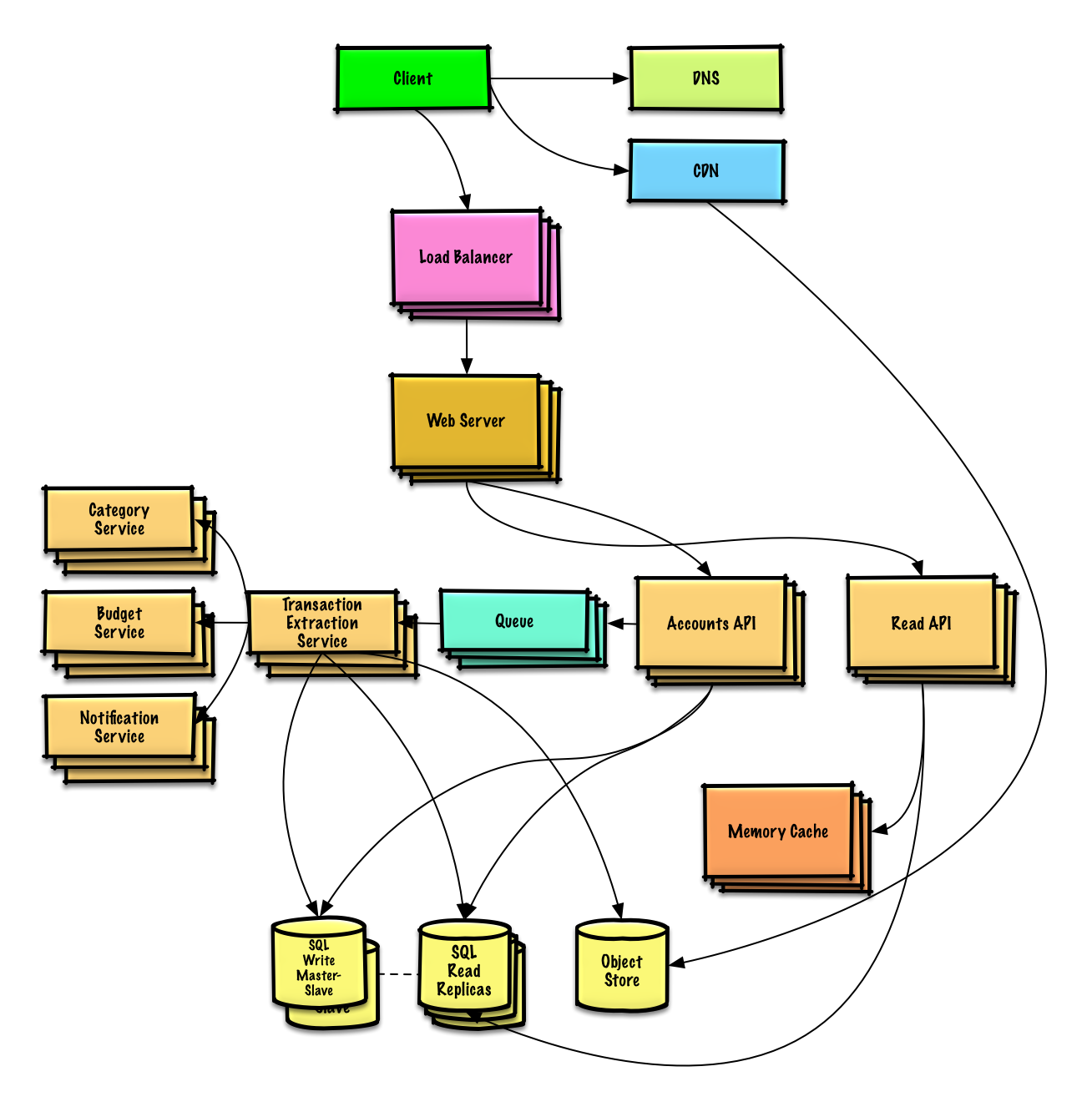
| Design Mint.com | Lösung |
| Entwerfen Sie die Datenstrukturen für ein soziales Netzwerk | Lösung |
| Entwerfen Sie einen Schlüsselwertspeicher für eine Suchmaschine | Lösung |
| Entwerfen Sie das Verkaufsranking von Amazon nach Kategoriefunktion | Lösung |
| Entwerfen Sie ein System, das für Millionen von Benutzern auf AWS skalierbar ist | Lösung |
| Fügen Sie eine Frage zum Systemdesign hinzu | Beitragen |
Übung und Lösung ansehen
Übung und Lösung ansehen
Übung und Lösung ansehen
Übung und Lösung ansehen
Übung und Lösung ansehen
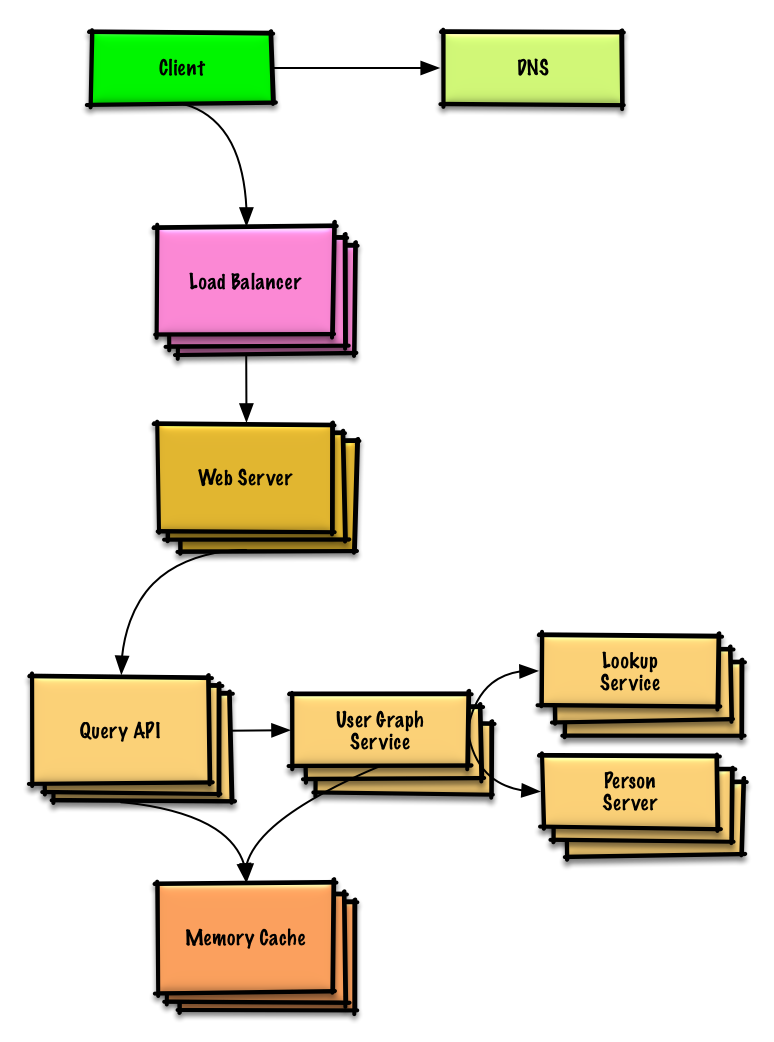
Übung und Lösung ansehen
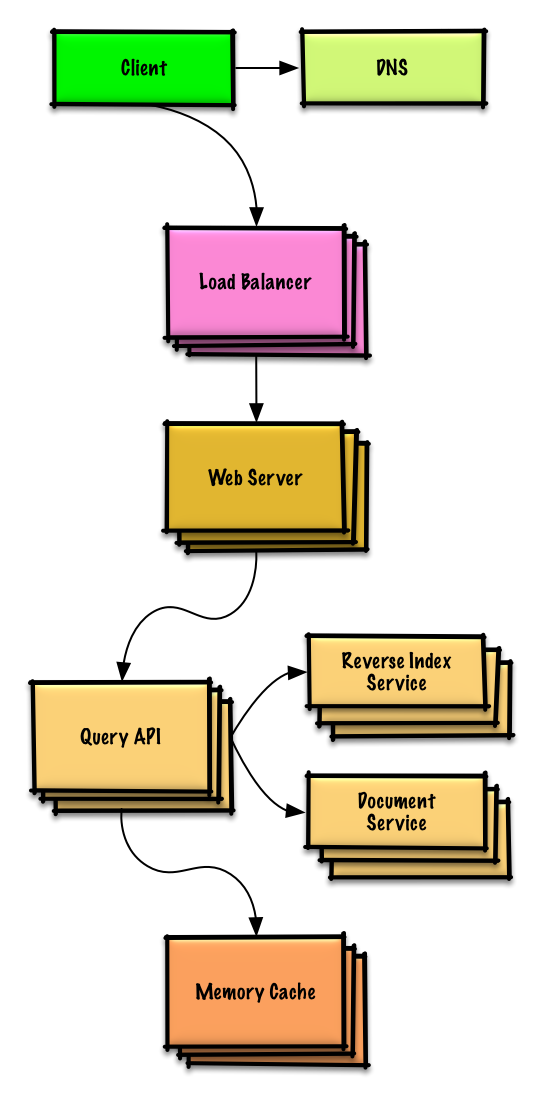
Übung und Lösung ansehen
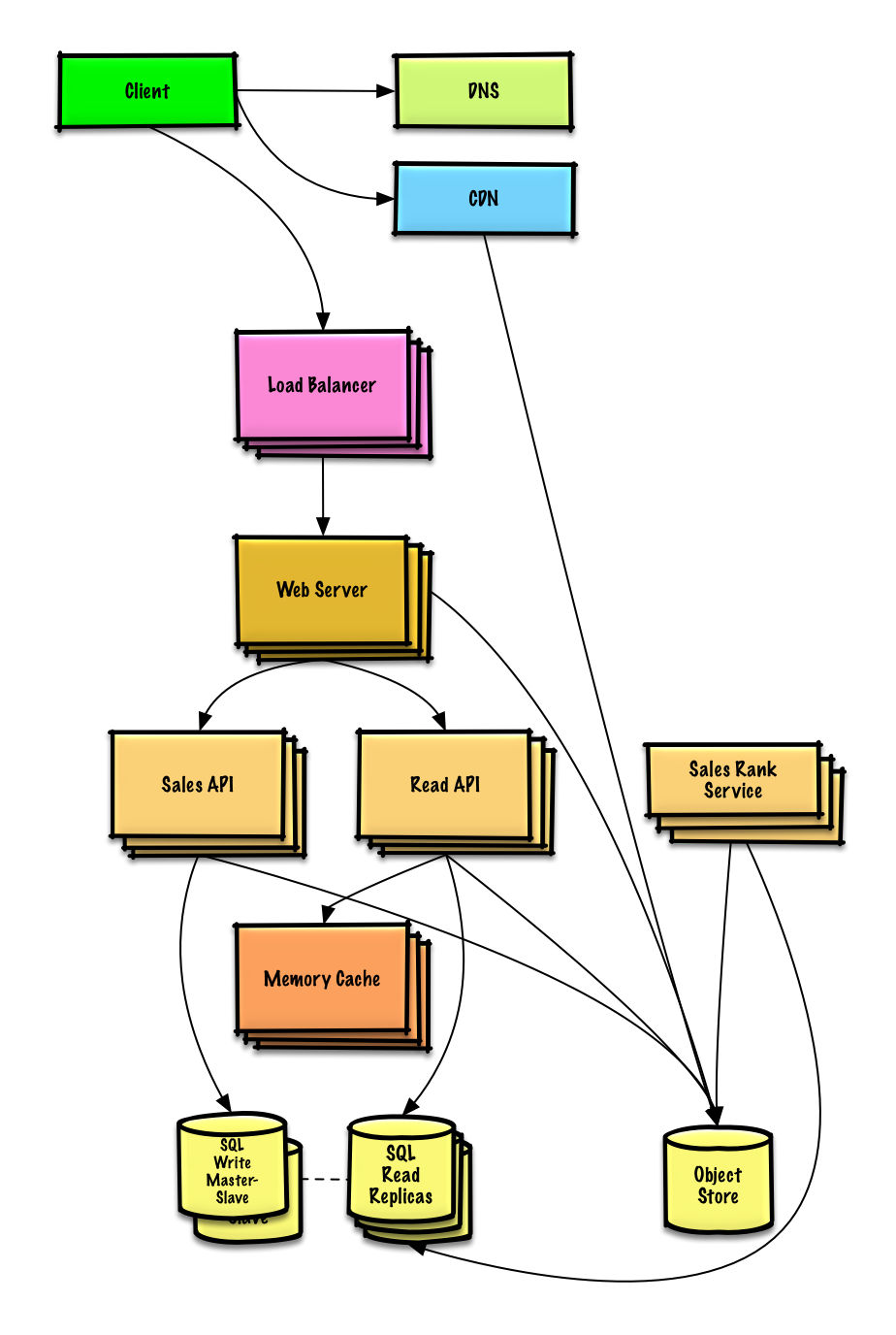
Übung und Lösung ansehen
Häufige Interviewfragen zum objektorientierten Design mit Beispieldiskussionen, Code und Diagrammen.
Lösungen, die mit Inhalten im Ordner
solutions/verknüpft sind.
Hinweis: Dieser Abschnitt befindet sich in der Entwicklung
| Frage | |
|---|---|
| Entwerfen Sie eine Hash-Map | Lösung |
| Entwerfen Sie einen zuletzt verwendeten Cache | Lösung |
| Entwerfen Sie ein Callcenter | Lösung |
| Entwerfen Sie ein Kartenspiel | Lösung |
| Entwerfen Sie einen Parkplatz | Lösung |
| Entwerfen Sie einen Chat-Server | Lösung |
| Entwerfen Sie eine kreisförmige Anordnung | Beitragen |
| Fügen Sie eine objektorientierte Designfrage hinzu | Beitragen |
Neu im Systemdesign?
Zunächst benötigen Sie ein grundlegendes Verständnis allgemeiner Prinzipien und erfahren, was sie sind, wie sie verwendet werden und welche Vor- und Nachteile sie haben.
Skalierbarkeitsvorlesung in Harvard
Skalierbarkeit
Als Nächstes schauen wir uns die Kompromisse auf hoher Ebene an:
Bedenken Sie, dass alles ein Kompromiss ist .
Anschließend befassen wir uns mit spezifischeren Themen wie DNS, CDNs und Load Balancern.
Ein Dienst ist skalierbar , wenn er proportional zu den hinzugefügten Ressourcen zu einer Leistungssteigerung führt. Im Allgemeinen bedeutet eine Leistungssteigerung die Bereitstellung von mehr Arbeitseinheiten, es kann jedoch auch darum gehen, größere Arbeitseinheiten zu verarbeiten, beispielsweise wenn Datensätze wachsen. 1
Eine andere Möglichkeit, Leistung vs. Skalierbarkeit zu betrachten:
Latenz ist die Zeit, in der eine Aktion ausgeführt oder ein Ergebnis erzielt wird.
Der Durchsatz ist die Anzahl solcher Aktionen oder Ergebnisse pro Zeiteinheit.
Im Allgemeinen sollten Sie einen maximalen Durchsatz bei akzeptabler Latenz anstreben.
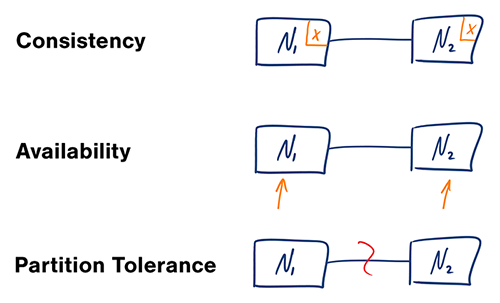
Quelle: CAP-Theorem überarbeitet
In einem verteilten Computersystem können Sie nur zwei der folgenden Garantien unterstützen:
Netzwerke sind nicht zuverlässig, daher müssen Sie Partitionstoleranz unterstützen. Sie müssen einen Software-Kompromiss zwischen Konsistenz und Verfügbarkeit eingehen.
Das Warten auf eine Antwort vom partitionierten Knoten kann zu einem Zeitüberschreitungsfehler führen. CP ist eine gute Wahl, wenn Ihre Geschäftsanforderungen atomare Lese- und Schreibvorgänge erfordern.
Antworten geben die am schnellsten verfügbare Version der auf jedem Knoten verfügbaren Daten zurück, die möglicherweise nicht die neueste ist. Es kann einige Zeit dauern, bis sich Schreibvorgänge verbreiten, wenn die Partition aufgelöst ist.
AP ist eine gute Wahl, wenn das Unternehmen eine letztendliche Konsistenz gewährleisten muss oder wenn das System trotz externer Fehler weiterarbeiten muss.
Bei mehreren Kopien derselben Daten stehen wir vor Möglichkeiten, diese zu synchronisieren, damit Kunden eine konsistente Sicht auf die Daten haben. Erinnern Sie sich an die Definition der Konsistenz aus dem CAP-Theorem: Jeder Lesevorgang erhält den letzten Schreibvorgang oder einen Fehler.
Nach einem Schreibvorgang können Lesevorgänge ihn sehen oder auch nicht. Es wird ein Best-Effort-Ansatz verfolgt.
Dieser Ansatz wird in Systemen wie Memcached beobachtet. Eine schwache Konsistenz funktioniert gut in Echtzeit-Anwendungsfällen wie VoIP, Video-Chat und Echtzeit-Multiplayer-Spielen. Wenn Sie beispielsweise gerade telefonieren und für einige Sekunden den Empfang verlieren, hören Sie bei erneuter Verbindungsaufnahme nicht, was während der Verbindungsunterbrechung gesprochen wurde.
Nach einem Schreibvorgang wird es schließlich von Lesevorgängen erkannt (normalerweise innerhalb von Millisekunden). Daten werden asynchron repliziert.
Dieser Ansatz findet sich in Systemen wie DNS und E-Mail. Eventuelle Konsistenz funktioniert gut in hochverfügbaren Systemen.
Nach einem Schreibvorgang wird es den Lesevorgängen angezeigt. Daten werden synchron repliziert.
Dieser Ansatz findet sich in Dateisystemen und RDBMS. Starke Konsistenz funktioniert gut in Systemen, die Transaktionen benötigen.
Es gibt zwei komplementäre Muster zur Unterstützung der Hochverfügbarkeit: Failover und Replikation .
Beim Aktiv-Passiv-Failover werden Heartbeats zwischen dem aktiven und dem passiven Server im Standby-Modus gesendet. Wenn der Heartbeat unterbrochen wird, übernimmt der passive Server die IP-Adresse des aktiven und nimmt den Dienst wieder auf.
Die Dauer der Ausfallzeit hängt davon ab, ob der passive Server bereits im „Hot“-Standby läuft oder ob er aus dem „Cold“-Standby hochfahren muss. Nur der aktive Server verarbeitet den Datenverkehr.
Aktiv-Passiv-Failover kann auch als Master-Slave-Failover bezeichnet werden.
Im Aktiv-Aktiv-Modus verwalten beide Server den Datenverkehr und verteilen die Last zwischen ihnen.
Wenn die Server öffentlich zugänglich sind, muss das DNS die öffentlichen IP-Adressen beider Server kennen. Wenn es sich bei den Servern um interne Server handelt, muss die Anwendungslogik über beide Server Bescheid wissen.
Aktiv-Aktiv-Failover kann auch als Master-Master-Failover bezeichnet werden.
Dieses Thema wird im Abschnitt „Datenbank“ weiter behandelt:
Die Verfügbarkeit wird oft durch die Betriebszeit (oder Ausfallzeit) als Prozentsatz der Zeit, in der der Dienst verfügbar ist, quantifiziert. Die Verfügbarkeit wird im Allgemeinen in der Anzahl der Neunen gemessen – ein Dienst mit einer Verfügbarkeit von 99,99 % wird als mit vier Neunen beschrieben.
| Dauer | Akzeptable Ausfallzeit |
|---|---|
| Ausfallzeit pro Jahr | 8h 45min 57s |
| Ausfallzeit pro Monat | 43m 49,7s |
| Ausfallzeit pro Woche | 10m 4,8s |
| Ausfallzeit pro Tag | 1 Min. 26,4 Sek |
| Dauer | Akzeptable Ausfallzeit |
|---|---|
| Ausfallzeit pro Jahr | 52 Min. 35,7 Sek |
| Ausfallzeit pro Monat | 4m 23s |
| Ausfallzeit pro Woche | 1m 5s |
| Ausfallzeit pro Tag | 8,6s |
Wenn ein Dienst aus mehreren fehleranfälligen Komponenten besteht, hängt die Gesamtverfügbarkeit des Dienstes davon ab, ob die Komponenten nacheinander oder parallel sind.
Die Gesamtverfügbarkeit nimmt ab, wenn zwei Komponenten mit einer Verfügbarkeit < 100 % nacheinander sind:
Availability (Total) = Availability (Foo) * Availability (Bar)
Wenn sowohl Foo als auch Bar jeweils eine Verfügbarkeit von 99,9 % hätten, wäre ihre Gesamtverfügbarkeit in Folge 99,8 %.
Die Gesamtverfügbarkeit erhöht sich, wenn zwei Komponenten mit einer Verfügbarkeit < 100 % parallel geschaltet werden:
Availability (Total) = 1 - (1 - Availability (Foo)) * (1 - Availability (Bar))
Wenn sowohl Foo als auch Bar jeweils eine Verfügbarkeit von 99,9 % hätten, wäre ihre Gesamtverfügbarkeit parallel 99,9999 %.
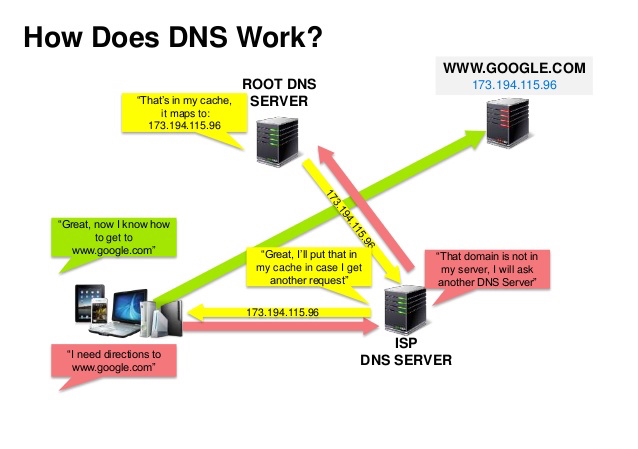
Quelle: DNS-Sicherheitspräsentation
Ein Domain Name System (DNS) übersetzt einen Domainnamen wie www.example.com in eine IP-Adresse.
DNS ist hierarchisch aufgebaut, mit einigen autorisierenden Servern auf der obersten Ebene. Ihr Router oder ISP stellt Informationen darüber bereit, welche DNS-Server bei einer Suche kontaktiert werden sollen. DNS-Server auf niedrigerer Ebene speichern Zuordnungen im Cache, die aufgrund von DNS-Verbreitungsverzögerungen veraltet sein könnten. DNS-Ergebnisse können auch von Ihrem Browser oder Betriebssystem für einen bestimmten Zeitraum zwischengespeichert werden, der durch die Lebensdauer (TTL) bestimmt wird.
CNAME (example.com auf www.example.com) oder auf einen A Datensatz.Dienste wie CloudFlare und Route 53 bieten verwaltete DNS-Dienste. Einige DNS-Dienste können den Datenverkehr über verschiedene Methoden weiterleiten:
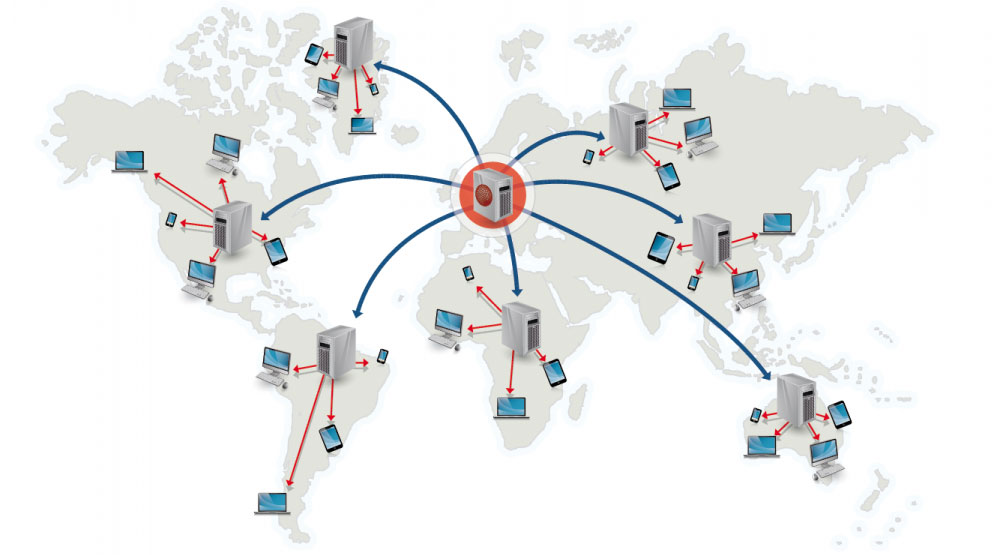
Quelle: Warum ein CDN verwenden
Ein Content Delivery Network (CDN) ist ein weltweit verteiltes Netzwerk von Proxyservern, das Inhalte von Standorten bereitstellt, die näher am Benutzer liegen. Im Allgemeinen werden statische Dateien wie HTML/CSS/JS, Fotos und Videos vom CDN bereitgestellt, obwohl einige CDNs wie Amazons CloudFront dynamische Inhalte unterstützen. Die DNS-Auflösung der Site teilt den Clients mit, welchen Server sie kontaktieren sollen.
Die Bereitstellung von Inhalten über CDNs kann die Leistung auf zwei Arten erheblich verbessern:
Push-CDNs empfangen neue Inhalte, wenn Änderungen auf Ihrem Server auftreten. Sie übernehmen die volle Verantwortung für die Bereitstellung von Inhalten, das direkte Hochladen in das CDN und das Umschreiben von URLs, die auf das CDN verweisen. Sie können konfigurieren, wann Inhalte ablaufen und wann sie aktualisiert werden. Inhalte werden nur dann hochgeladen, wenn sie neu sind oder sich geändert haben, wodurch der Datenverkehr minimiert, aber der Speicherplatz maximiert wird.
Websites mit geringem Datenverkehr oder Websites mit Inhalten, die nicht oft aktualisiert werden, eignen sich gut für Push-CDNs. Inhalte werden einmalig auf den CDNs platziert, anstatt in regelmäßigen Abständen erneut abgerufen zu werden.
Pull-CDNs rufen neue Inhalte von Ihrem Server ab, wenn der erste Benutzer die Inhalte anfordert. Sie belassen den Inhalt auf Ihrem Server und schreiben URLs so um, dass sie auf das CDN verweisen. Dies führt zu einer langsameren Anfrage, bis der Inhalt im CDN zwischengespeichert wird.
Eine Time-to-Live (TTL) bestimmt, wie lange Inhalte zwischengespeichert werden. Pull-CDNs minimieren den Speicherplatz im CDN, können aber zu redundantem Datenverkehr führen, wenn Dateien ablaufen und abgerufen werden, bevor sie sich tatsächlich geändert haben.
Websites mit starkem Datenverkehr funktionieren gut mit Pull-CDNs, da der Datenverkehr gleichmäßiger verteilt wird und nur kürzlich angeforderte Inhalte im CDN verbleiben.
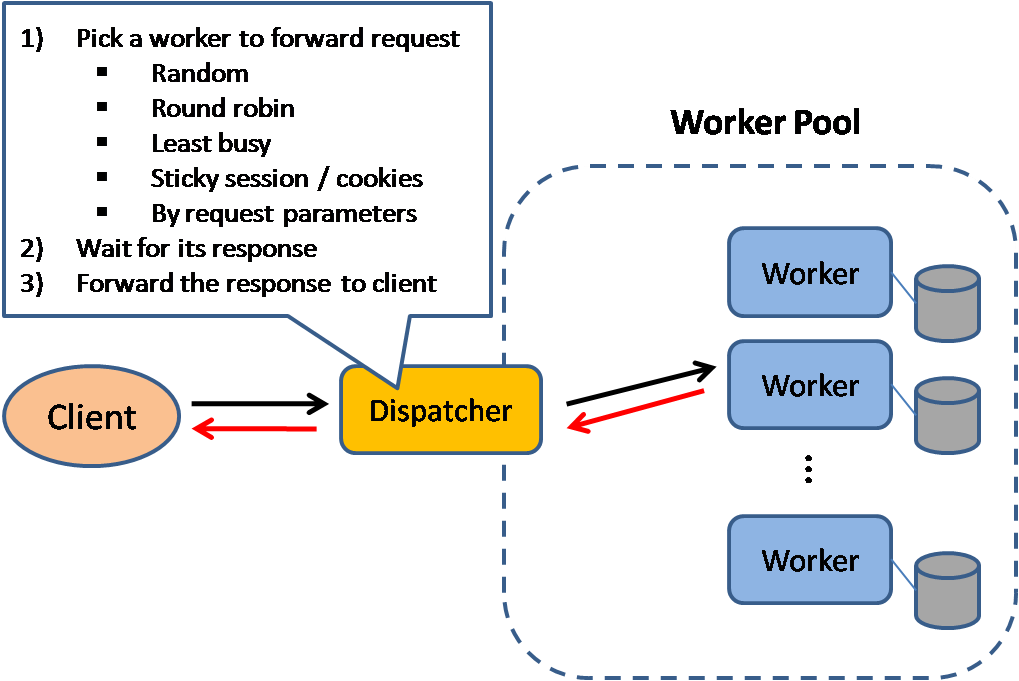
Quelle: Skalierbare Systementwurfsmuster
Load Balancer verteilen eingehende Client-Anfragen an Rechenressourcen wie Anwendungsserver und Datenbanken. In jedem Fall gibt der Load Balancer die Antwort von der Rechenressource an den entsprechenden Client zurück. Load Balancer sind wirksam bei:
Load Balancer können mit Hardware (teuer) oder mit Software wie HAProxy implementiert werden.
Zu den weiteren Vorteilen gehören:
Zum Schutz vor Ausfällen ist es üblich, mehrere Load Balancer einzurichten, entweder im Aktiv-Passiv- oder Aktiv-Aktiv-Modus.
Load Balancer können den Datenverkehr basierend auf verschiedenen Metriken weiterleiten, darunter:
Load Balancer der Schicht 4 prüfen die Informationen auf der Transportschicht, um zu entscheiden, wie Anforderungen verteilt werden. Im Allgemeinen betrifft dies die Quell-, Ziel-IP-Adressen und Ports im Header, nicht jedoch den Inhalt des Pakets. Layer-4-Load-Balancer leiten Netzwerkpakete zum und vom Upstream-Server weiter und führen dabei Network Address Translation (NAT) durch.
Load Balancer der Schicht 7 schauen sich die Anwendungsschicht an, um zu entscheiden, wie Anforderungen verteilt werden. Dabei kann es sich um Header-, Nachrichten- und Cookies-Inhalte handeln. Layer-7-Load-Balancer beenden den Netzwerkverkehr, lesen die Nachricht, treffen eine Load-Balancing-Entscheidung und öffnen dann eine Verbindung zum ausgewählten Server. Beispielsweise kann ein Layer-7-Load-Balancer den Videoverkehr an Server leiten, die Videos hosten, während sensiblerer Benutzerabrechnungsverkehr an Server mit erhöhter Sicherheit weitergeleitet wird.
Auf Kosten der Flexibilität erfordert der Lastausgleich auf Schicht 4 weniger Zeit und Rechenressourcen als Schicht 7, obwohl die Auswirkungen auf die Leistung auf moderner Standardhardware minimal sein können.
Load Balancer können auch bei der horizontalen Skalierung helfen und so Leistung und Verfügbarkeit verbessern. Die horizontale Skalierung mithilfe von Standardmaschinen ist kosteneffizienter und führt zu einer höheren Verfügbarkeit als die vertikale Skalierung eines einzelnen Servers auf teurerer Hardware. Außerdem ist es einfacher, Talente einzustellen, die an Standardhardware arbeiten, als für spezialisierte Unternehmenssysteme.
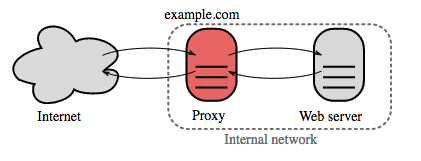
Quelle: Wikipedia
Ein Reverse-Proxy ist ein Webserver, der interne Dienste zentralisiert und einheitliche Schnittstellen für die Öffentlichkeit bereitstellt. Anfragen von Clients werden an einen Server weitergeleitet, der sie erfüllen kann, bevor der Reverse-Proxy die Antwort des Servers an den Client zurücksendet.
Zu den weiteren Vorteilen gehören:
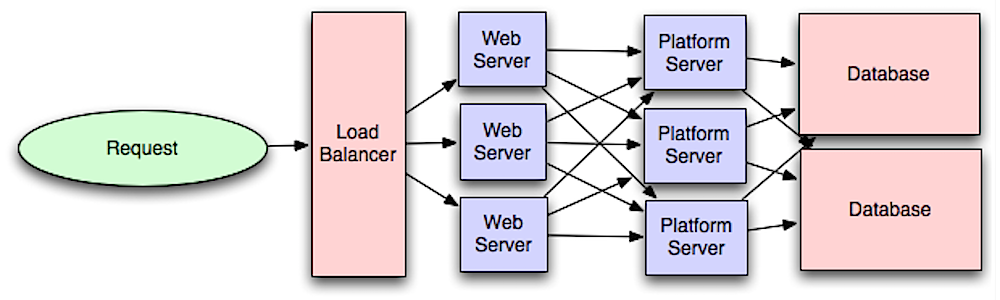
Quelle: Einführung in die skalierbare Architektur von Systemen
Durch die Trennung der Webschicht von der Anwendungsschicht (auch Plattformschicht genannt) können Sie beide Schichten unabhängig voneinander skalieren und konfigurieren. Das Hinzufügen einer neuen API führt zum Hinzufügen von Anwendungsservern, ohne dass unbedingt zusätzliche Webserver hinzugefügt werden müssen. Das Prinzip der Einzelverantwortung plädiert für kleine und autonome Dienste, die zusammenarbeiten. Kleine Teams mit kleinen Dienstleistungen können für ein schnelles Wachstum aggressiver planen.
Worker in der Anwendungsschicht tragen auch dazu bei, Asynchronismus zu ermöglichen.
Im Zusammenhang mit dieser Diskussion stehen Microservices, die als eine Reihe unabhängig voneinander einsetzbarer, kleiner, modularer Services beschrieben werden können. Jeder Dienst führt einen einzigartigen Prozess aus und kommuniziert über einen klar definierten, einfachen Mechanismus, um ein Geschäftsziel zu erreichen. 1
Pinterest könnte beispielsweise über folgende Microservices verfügen: Benutzerprofil, Follower, Feed, Suche, Foto-Upload usw.
Systeme wie Consul, Etcd und Zookeeper können Diensten helfen, sich gegenseitig zu finden, indem sie registrierte Namen, Adressen und Ports verfolgen. Integritätsprüfungen helfen bei der Überprüfung der Dienstintegrität und werden häufig über einen HTTP-Endpunkt durchgeführt. Sowohl Consul als auch Etcd verfügen über einen integrierten Schlüsselwertspeicher, der zum Speichern von Konfigurationswerten und anderen gemeinsam genutzten Daten nützlich sein kann.
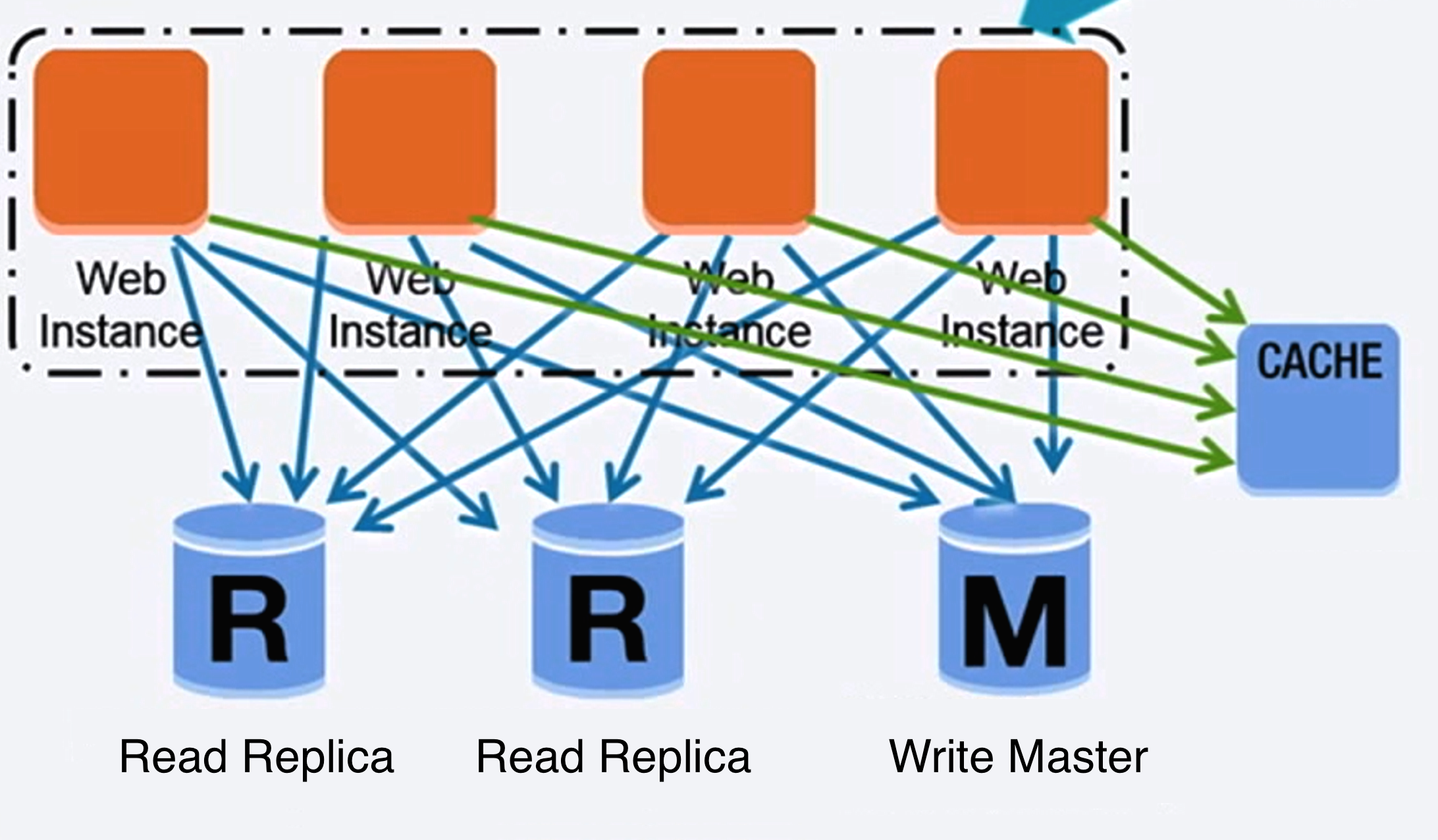
Quelle: Skalierung auf Ihre ersten 10 Millionen Benutzer
Eine relationale Datenbank wie SQL ist eine Sammlung von Datenelementen, die in Tabellen organisiert sind.
ACID ist eine Reihe von Eigenschaften relationaler Datenbanktransaktionen.
Es gibt viele Techniken zum Skalieren einer relationalen Datenbank: Master-Slave-Replikation , Master-Master-Replikation , Föderation , Sharding , Denormalisierung und SQL-Tuning .
Der Master bedient Lese- und Schreibvorgänge und repliziert Schreibvorgänge auf einen oder mehrere Slaves, die nur Lesevorgänge durchführen. Slaves können auch baumartig auf weitere Slaves replizieren. Wenn der Master offline geht, kann das System im schreibgeschützten Modus weiterarbeiten, bis ein Slave zum Master befördert oder ein neuer Master bereitgestellt wird.
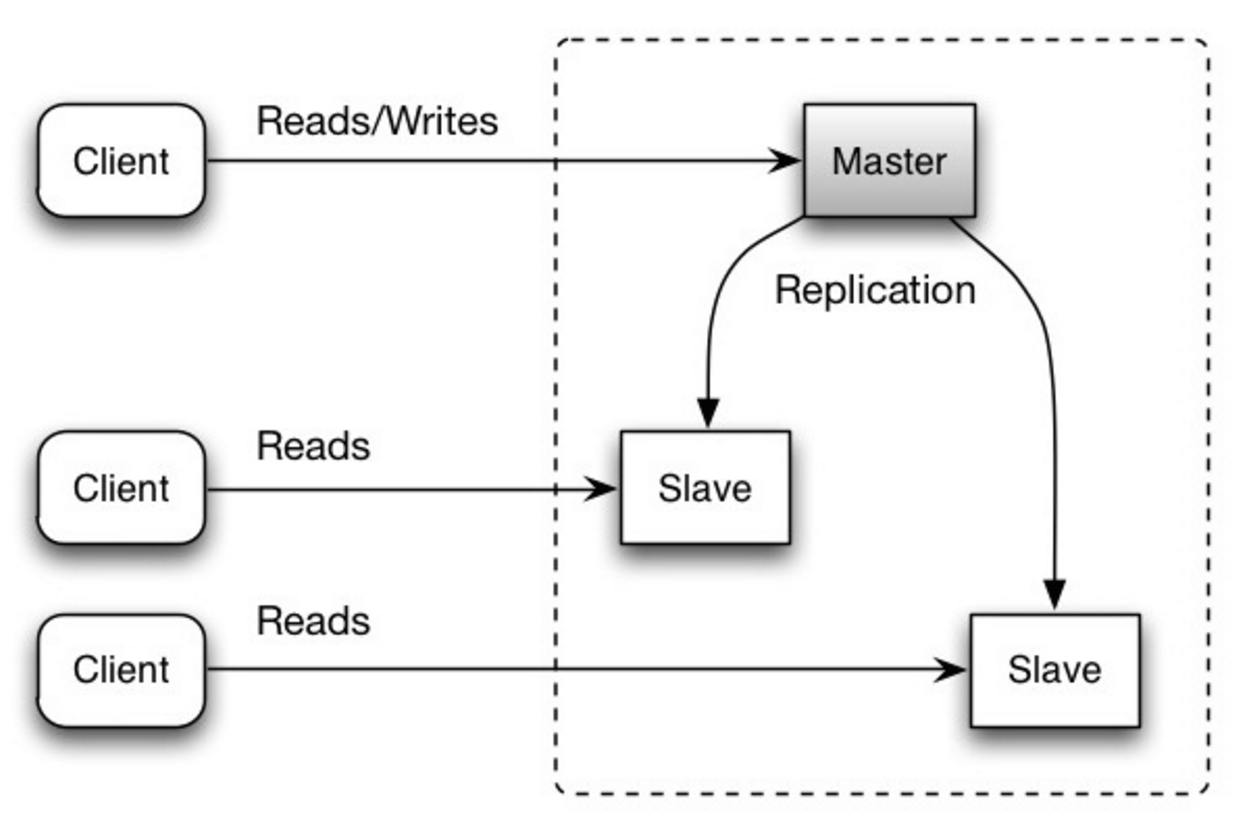
Quelle: Skalierbarkeit, Verfügbarkeit, Stabilität, Muster
Beide Master bedienen Lese- und Schreibvorgänge und koordinieren Schreibvorgänge miteinander. Wenn einer der Master ausfällt, kann das System sowohl mit Lese- als auch mit Schreibvorgängen weiterarbeiten.
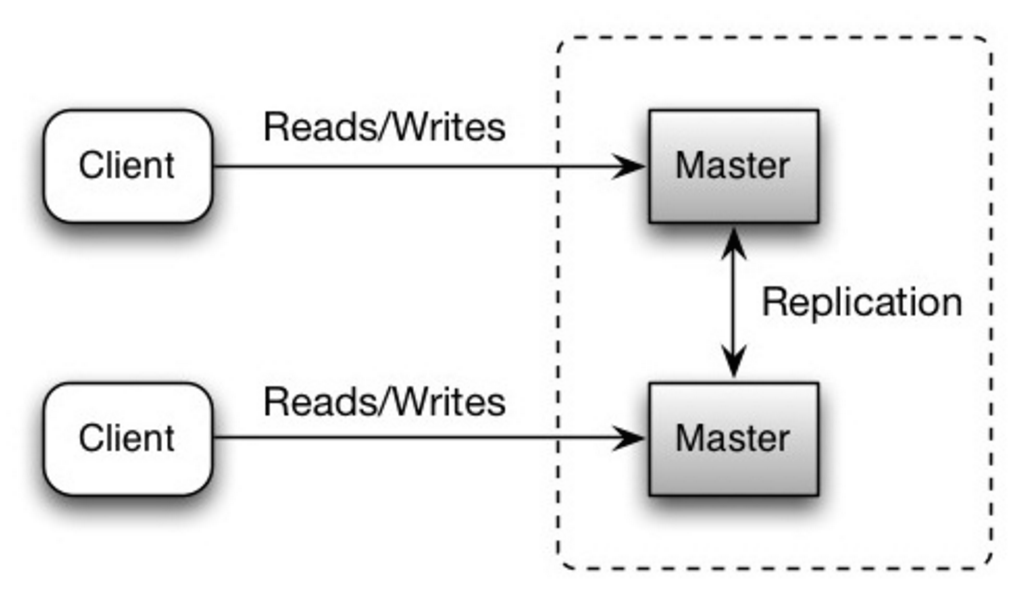
Quelle: Skalierbarkeit, Verfügbarkeit, Stabilität, Muster
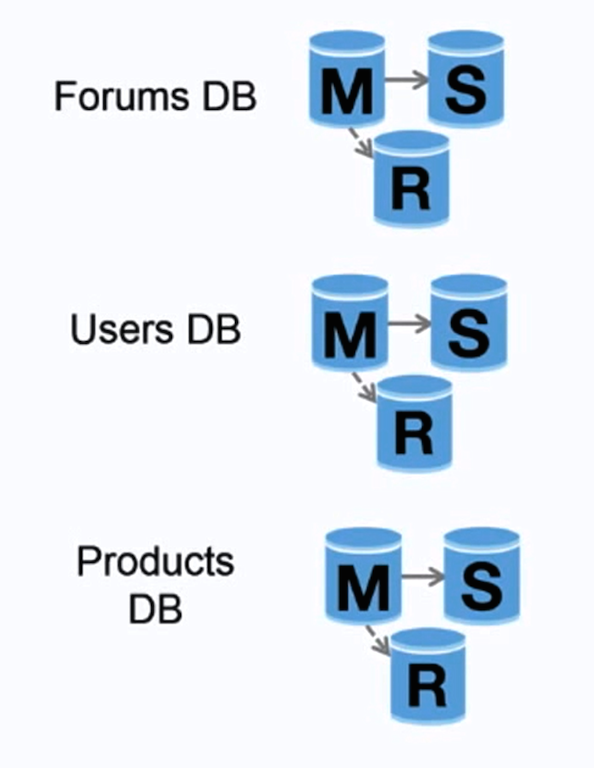
Quelle: Skalierung auf Ihre ersten 10 Millionen Benutzer
Durch die Föderation (oder funktionale Partitionierung) werden Datenbanken nach Funktion aufgeteilt. Anstelle einer einzelnen, monolithischen Datenbank könnten Sie beispielsweise drei Datenbanken haben: Foren , Benutzer und Produkte , was zu weniger Lese- und Schreibverkehr zu jeder Datenbank und damit zu einer geringeren Replikationsverzögerung führt. Kleinere Datenbanken führen dazu, dass mehr Daten in den Speicher passen, was wiederum aufgrund der verbesserten Cache-Lokalität zu mehr Cache-Treffern führt. Da es keinen einzigen zentralen Master gibt, der Schreibvorgänge serialisiert, können Sie parallel schreiben und so den Durchsatz erhöhen.
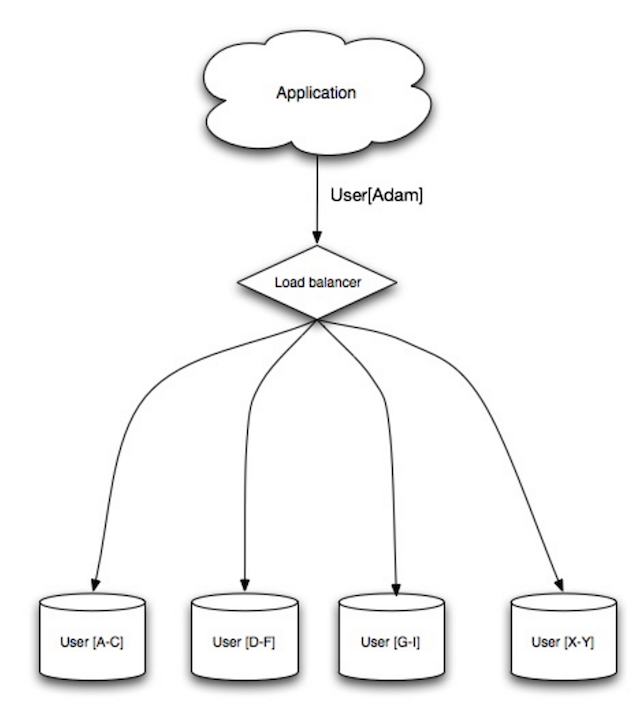
Quelle: Skalierbarkeit, Verfügbarkeit, Stabilität, Muster
Beim Sharding werden Daten auf verschiedene Datenbanken verteilt, sodass jede Datenbank nur eine Teilmenge der Daten verwalten kann. Nehmen wir als Beispiel eine Benutzerdatenbank: Mit zunehmender Anzahl von Benutzern werden dem Cluster weitere Shards hinzugefügt.
Ähnlich wie die Vorteile der Föderation führt Sharding zu weniger Lese- und Schreibverkehr, weniger Replikation und mehr Cache-Treffern. Außerdem wird die Indexgröße reduziert, was im Allgemeinen die Leistung bei schnelleren Abfragen verbessert. Wenn ein Shard ausfällt, sind die anderen Shards weiterhin betriebsbereit. Sie sollten jedoch eine Form der Replikation hinzufügen, um Datenverluste zu vermeiden. Wie bei der Föderation gibt es keinen einzelnen zentralen Master, der Schreibvorgänge serialisiert, sodass Sie parallel mit erhöhtem Durchsatz schreiben können.
Übliche Methoden zum Shardieren einer Benutzertabelle sind entweder der Anfangsbuchstabe des Nachnamens des Benutzers oder der geografische Standort des Benutzers.
Die Denormalisierung versucht, die Leseleistung auf Kosten einer Schreibleistung zu verbessern. Redundante Kopien der Daten werden in mehreren Tabellen geschrieben, um teure Verknüpfungen zu vermeiden. Einige RDBMs wie PostgreSQL und Oracle unterstützen materialisierte Ansichten, die die Arbeit des Speicherns redundanter Informationen und die konsistenten Aufbewahrung von redundanten Kopien übernehmen.
Sobald die Daten mit Techniken wie Föderation und Sharding verteilt werden, erhöht die Verwaltung von Beilagen über Rechenzentren die Komplexität weiter. Die Denormalisierung könnte die Notwendigkeit solcher komplexen Verbindungen umgehen.
In den meisten Systemen können Lesevorgänge in hohem Maße zahlenmäßig unterlegen, wie 100: 1 oder sogar 1000: 1. Eine Lektüre, die zu einem komplexen Datenbankjoinse führt, kann sehr teuer sein und viel Zeit für Disk -Operationen verbringt.
SQL Tuning ist ein breites Thema und viele Bücher wurden als Referenz geschrieben.
Es ist wichtig, das Benchmark und das Profil zu simulieren und Engpässe aufzudecken.
Benchmarking und Profiling können Sie auf die folgenden Optimierungen hinweisen.
CHAR anstelle von VARCHAR für Felder mit fester Länge.CHAR ermöglicht effektiv einen schnellen, zufälligen Zugriff, während Sie mit VARCHAR das Ende einer Zeichenfolge finden müssen, bevor Sie zur nächsten übergehen.TEXT für große Textblöcke wie Blog -Beiträge. TEXT ermöglicht auch Boolesche Suchvorgänge. Die Verwendung eines TEXT führt zum Speichern eines Zeigers auf der Festplatte, mit dem der Textblock lokalisiert wird.INT für größere Zahlen bis zu 2^32 oder 4 Milliarden.DECIMAL for Currency, um Floating Point Repräsentationsfehler zu vermeiden.BLOBS aufzubewahren, und speichern Sie den Ort, an dem stattdessen das Objekt erhalten.VARCHAR(255) ist die größte Anzahl von Zeichen, die in einer 8 -Bit -Zahl gezählt werden können, wodurch die Verwendung eines Byte in einigen RDBMs häufig maximiert wird.NOT NULL -Einschränkung fest, um die Suchleistung zu verbessern. SELECT , GROUP BY , ORDER BY , JOIN ) können mit Indizes schneller sein.NoSQL ist eine Sammlung von Datenelementen, die in einem Schlüsselwertspeicher , einem Dokumentspeicher , einem breiten Spaltenspeicher oder einer Diagrammdatenbank dargestellt werden. Die Daten werden denormalisiert und Verbindungen werden im Allgemeinen im Anwendungscode durchgeführt. In den meisten NoSQL -Speichern fehlen echte Säure -Transaktionen und bevorzugen die eventuelle Konsistenz.
Basis wird häufig verwendet, um die Eigenschaften von NoSQL -Datenbanken zu beschreiben. Im Vergleich zum CAP -Theorem wählt Base die Verfügbarkeit über die Konsistenz.
Neben der Auswahl zwischen SQL oder NoSQL ist es hilfreich zu verstehen, welche Art von NoSQL -Datenbank am besten zu Ihren Anwendungsfällen passt. Wir werden im nächsten Abschnitt Schlüsselwertspeicher , Dokumentspeicher , breite Spaltenspeicher und Diagrammdatenbanken überprüfen.
Abstraktion: Hash -Tabelle
Ein Schlüsselwertgeschäft ermöglicht im Allgemeinen O (1) O (1) Lese- und Schreibvorgänge und wird häufig durch Speicher oder SSD unterstützt. Datenspeicher können Schlüssel in lexikografischer Reihenfolge aufrechterhalten und ein effizientes Abrufen der Schlüsselbereiche ermöglichen. Schlüsselwertgeschäfte können die Speicherung von Metadaten mit einem Wert ermöglichen.
Schlüsselwertespeicher bieten eine hohe Leistung und werden häufig für einfache Datenmodelle oder für sich schnell verändernde Daten verwendet, wie z. B. eine In-Memory-Cache-Ebene. Da sie nur eine begrenzte Reihe von Vorgängen anbieten, wird die Komplexität in die Anwendungsschicht verlagert, wenn zusätzliche Vorgänge erforderlich sind.
Ein Schlüsselwertspeicher ist die Grundlage für komplexere Systeme wie einen Dokumentspeicher und in einigen Fällen eine Diagrammdatenbank.
Abstraktion: Schlüsselwertspeicher mit Dokumenten, die als Werte gespeichert sind
Ein Dokumentgeschäft befindet sich auf Dokumente (XML, JSON, Binary usw.), wobei ein Dokument alle Informationen für ein bestimmtes Objekt speichert. Dokumentspeicher bieten APIs oder Abfragestraßen für Abfragen basierend auf der internen Struktur des Dokuments selbst. Beachten Sie, dass viele Schlüsselwertgeschäfte Funktionen für die Arbeit mit den Metadaten eines Werts enthalten und die Leitungen zwischen diesen beiden Speichertypen verwischen.
Basierend auf der zugrunde liegenden Implementierung werden Dokumente durch Sammlungen, Tags, Metadaten oder Verzeichnisse organisiert. Obwohl Dokumente organisiert oder gruppiert werden können, haben Dokumente möglicherweise Felder, die sich völlig voneinander unterscheiden.
Einige Dokumentgeschäfte wie MongoDB und CouchDB bieten auch eine SQL-ähnliche Sprache, um komplexe Abfragen durchzuführen. DynamoDB unterstützt sowohl Schlüsselwerte als auch Dokumente.
Dokumentgeschäfte bieten eine hohe Flexibilität und werden häufig für die Arbeit mit gelegentlich ändernden Daten verwendet.
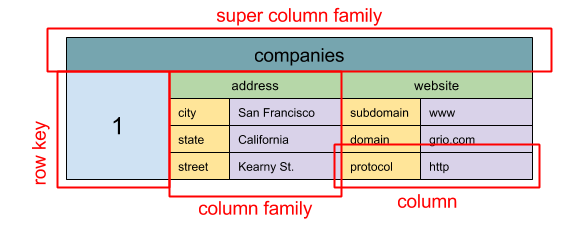
Quelle: SQL & NoSQL, eine kurze Geschichte
Abstraktion: verschachtelte
ColumnFamily<RowKey, Columns<ColKey, Value, Timestamp>>
Die grundlegende Dateneinheit eines breiten Spaltenspeichers ist eine Spalte (Name/Wertpaar). Eine Spalte kann in Säulenfamilien gruppiert werden (analog zu einer SQL -Tabelle). Super -Kolumne -Familien weitere Gruppenspaltenfamilien. Sie können auf jede Spalte unabhängig mit einer Zeilenschlüssel und Spalten mit derselben Zeilenschlüssel zugreifen. Jeder Wert enthält einen Zeitstempel für die Versionierung und für die Konfliktlösung.
Google stellte Bigtable als erstes breites Spaltengeschäft vor, das die Open-Source-HBase im Hadoop-Ökosystem und Cassandra von Facebook beeinflusste. Geschäfte wie Bigtable, HBase und Cassandra halten Schlüssel in lexikografischer Reihenfolge auf und ermöglichen ein effizientes Abrufen selektiver Schlüsselbereiche.
Breite Säulengeschäfte bieten hohe Verfügbarkeit und hohe Skalierbarkeit. Sie werden oft für sehr große Datensätze verwendet.
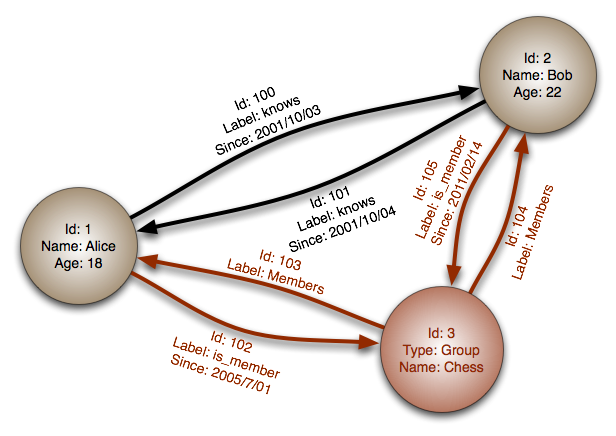
Quelle: Diagrammdatenbank
Abstraktion: Diagramm
In einer Graph -Datenbank ist jeder Knoten ein Datensatz und jeder Bogen ist eine Beziehung zwischen zwei Knoten. Diagrammdatenbanken sind optimiert, um komplexe Beziehungen zu vielen ausländischen Schlüsseln oder vielen zu vielen Beziehungen darzustellen.
Diagrammdatenbanken bieten eine hohe Leistung für Datenmodelle mit komplexen Beziehungen wie einem sozialen Netzwerk. Sie sind relativ neu und sind noch nicht weit verbreitet; Es könnte schwieriger sein, Entwicklungstools und Ressourcen zu finden. Auf viele Grafiken kann nur mit REST -APIs zugegriffen werden.
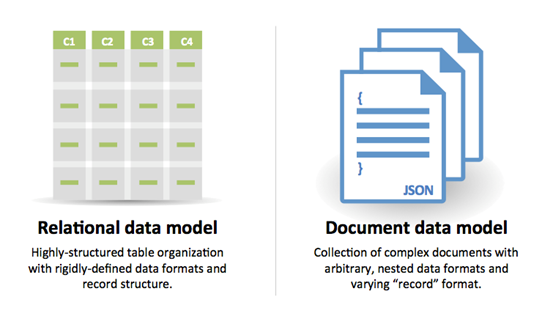
Quelle: Übergang von RDBMs zu NoSQL
Gründe für SQL :
Gründe für NoSQL :
Beispieldaten für NoSQL geeignet:
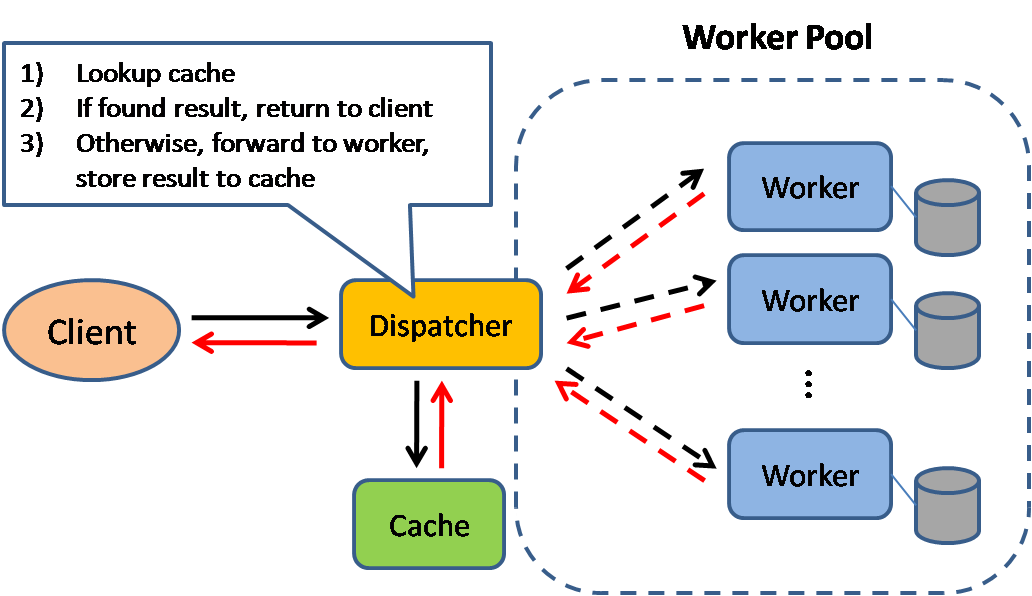
Quelle: Skalierbare Systemdesignmuster
Das Caching verbessert die Ladezeiten der Seiten und kann die Last auf Ihren Servern und Datenbanken reduzieren. In diesem Modell sucht der Dispatcher zunächst, wenn die Anfrage zuvor gestellt wurde, und versucht, das vorherige Ergebnis zurückzugeben, um die tatsächliche Ausführung zu speichern.
Datenbanken profitieren häufig von einer einheitlichen Verteilung von Lesevorgängen und Schreibvorgängen in ihren Partitionen. Beliebte Gegenstände können die Verteilung verzerren und Engpässe verursachen. Wenn Sie einen Cache vor eine Datenbank stellen, können Sie ungleichmäßige Lasten und Spitzen im Verkehr aufnehmen.
Caches können auf Client -Seite (Betriebssystem oder Browser), Serverseite oder in einer bestimmten Cache -Ebene gefunden werden.
CDNs gelten als eine Art Cache.
Umgekehrte Proxys und Caches wie Lack können statischen und dynamischen Inhalt direkt dienen. Webserver können auch Anfragen zwischenspeichern und Antworten zurückgeben, ohne Anwendungsserver zu kontaktieren.
Ihre Datenbank enthält normalerweise ein gewisses Maß an Caching in einer Standardkonfiguration, die für einen generischen Anwendungsfall optimiert ist. Wenn Sie diese Einstellungen für bestimmte Verwendungsmuster optimieren, können Sie die Leistung weiter steigern.
In-Memory-Caches wie Memcached und Redis sind Schlüsselwertspeicher zwischen Ihrer Anwendung und Ihrer Datenspeicherung. Da die Daten in RAM enthalten sind, ist sie viel schneller als typische Datenbanken, in denen Daten auf der Festplatte gespeichert werden. RAM ist begrenzter als die Festplatte, sodass Cache -Invalidierungsalgorithmen wie in jüngster Zeit verwendet (LRU) beispielsweise "kalte" Einträge ungültig machen und "heiße" Daten in RAM aufbewahren.
Redis hat die folgenden zusätzlichen Funktionen:
Es gibt mehrere Ebenen, die Sie unterbinden können, die in zwei allgemeine Kategorien fallen: Datenbankabfragen und Objekte :
Im Allgemeinen sollten Sie versuchen, dateibasiertes Caching zu vermeiden, da es das Klonen und automatisch schwieriger wird.
Wenn Sie die Datenbank abfragen, haben Sie die Abfrage als Schlüssel und speichern Sie das Ergebnis im Cache. Dieser Ansatz leidet unter Ablaufproblemen:
Sehen Sie Ihre Daten als Objekt an, ähnlich wie Sie mit Ihrem Anwendungscode tun. Lassen Sie Ihre Anwendung den Datensatz aus der Datenbank in eine Klasseninstanz oder eine Datenstruktur (en) zusammenstellen:
Vorschläge, was zu einem zwischengestrichenen kann:
Da Sie nur eine begrenzte Menge an Daten in Cache speichern können, müssen Sie feststellen, welche Cache -Update -Strategie für Ihren Anwendungsfall am besten geeignet ist.
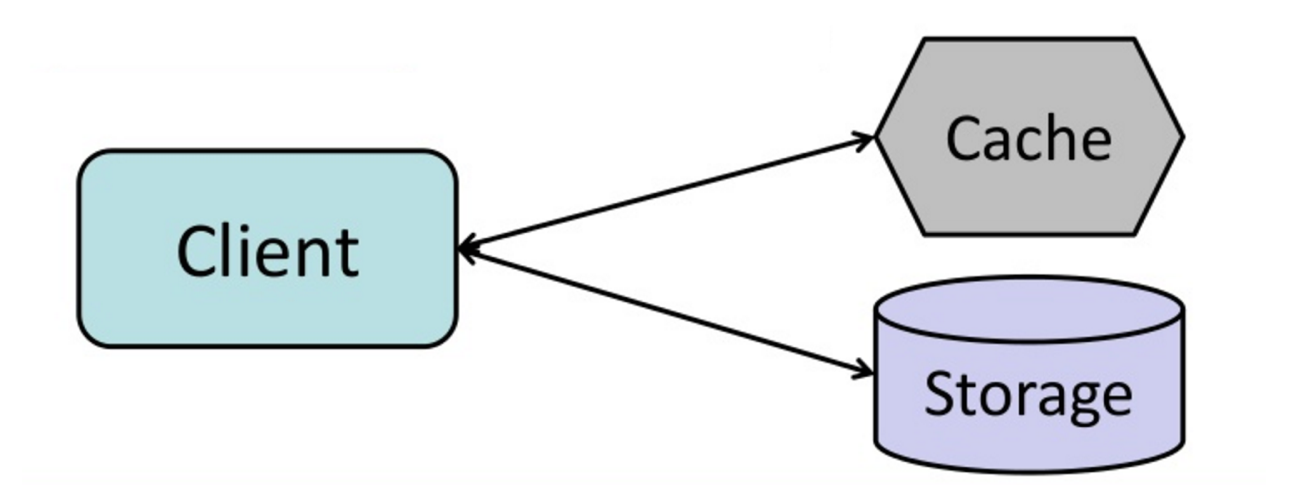
Quelle: Vom Cache zu In-Memory-Datenraster
Die Anwendung ist für das Lesen und Schreiben aus dem Speicher verantwortlich. Der Cache interagiert nicht direkt mit Speicher. Die Anwendung führt Folgendes aus:
def get_user ( self , user_id ):
user = cache . get ( "user.{0}" , user_id )
if user is None :
user = db . query ( "SELECT * FROM users WHERE user_id = {0}" , user_id )
if user is not None :
key = "user.{0}" . format ( user_id )
cache . set ( key , json . dumps ( user ))
return userMemcached wird im Allgemeinen auf diese Weise verwendet.
Nachfolgende Daten von Daten, die zum Cache hinzugefügt wurden, sind schnell. Cache-Aside wird ebenfalls als faules Laden bezeichnet. Es werden nur angeforderte Daten zwischengespeichert, wodurch das Ausfüllen des Cache mit nicht angeforderten Daten ausgefüllt wird.
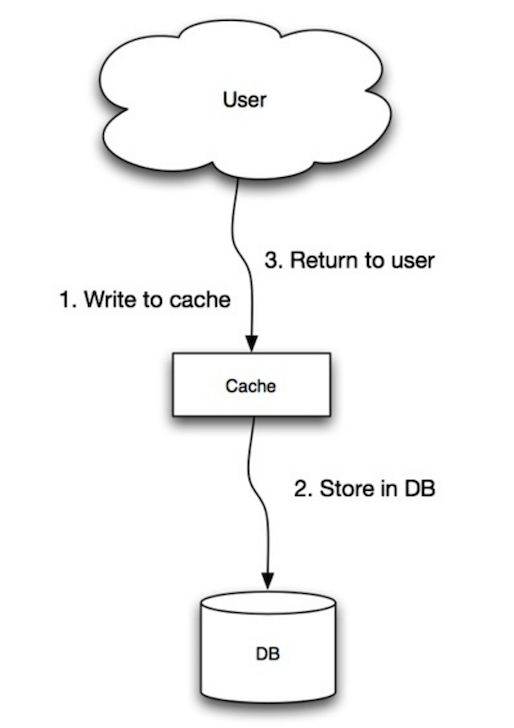
Quelle: Skalierbarkeit, Verfügbarkeit, Stabilität, Muster
Die Anwendung verwendet den Cache als Hauptdatenspeicher, Lesen und Schreiben von Daten, während der Cache für das Lesen und Schreiben in die Datenbank verantwortlich ist:
Anwendungscode:
set_user ( 12345 , { "foo" : "bar" })Cache -Code:
def set_user ( user_id , values ):
user = db . query ( "UPDATE Users WHERE id = {0}" , user_id , values )
cache . set ( user_id , user )Schreib- durch den Schreibvorgang ist ein langsamer Gesamtbetrieb, aber nachfolgende Lesevorgänge gerechter schriftlicher Daten sind schnell. Benutzer sind im Allgemeinen toleranter gegenüber Latenz, wenn sie Daten aktualisieren, als Daten zu lesen. Daten im Cache sind nicht veraltet.
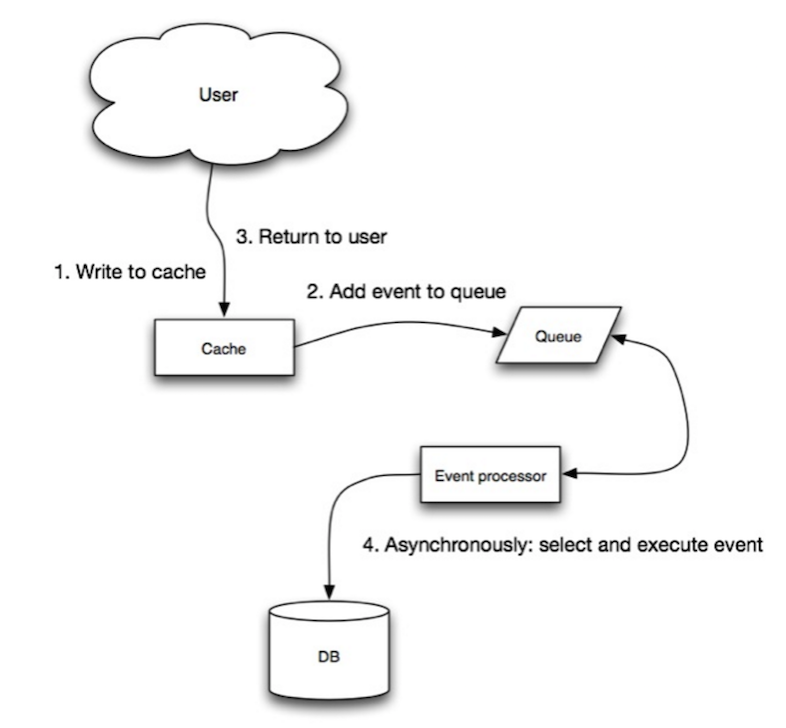
Quelle: Skalierbarkeit, Verfügbarkeit, Stabilität, Muster
In Write-Behind führt die Anwendung Folgendes aus:
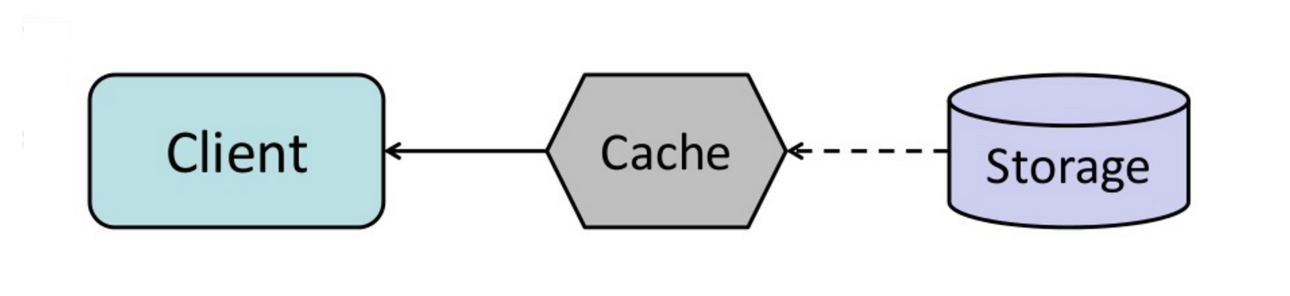
Quelle: Vom Cache zu In-Memory-Datenraster
Sie können den Cache so konfigurieren, dass es vor dem Ablauf automatisch alle kürzlich zugegriffenen Cache -Eintragungen aktualisiert hat.
Refresh-Ahead kann zu einer verringerten Latenz im Vergleich zum Lesen führen, wenn der Cache genau vorhersagen kann, welche Elemente in Zukunft wahrscheinlich benötigt werden.
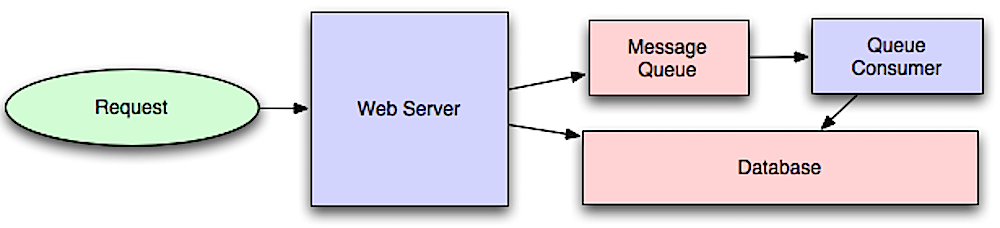
Quelle: Intro in Architektierungssysteme für die Skalierung
Asynchrone Workflows reduzieren die Antragszeiten für teure Vorgänge, die ansonsten in der Linie durchgeführt werden. Sie können auch helfen, indem sie zeitaufwändige Arbeiten im Voraus erledigen, wie z. B. regelmäßige Datenaggregation.
Nachrichtenwarteschlangen empfangen, halten und senden Nachrichten. Wenn eine Operation zu langsam ist, um Inline auszuführen, können Sie eine Meldungswarteschlange mit dem folgenden Workflow verwenden:
Der Benutzer ist nicht blockiert und der Job wird im Hintergrund verarbeitet. Während dieser Zeit kann der Kunde optional eine kleine Menge an Verarbeitung durchführen, damit die Aufgabe erledigt ist. Wenn Sie beispielsweise einen Tweet veröffentlichen, kann der Tweet sofort in Ihre Zeitleiste veröffentlicht werden, aber es kann einige Zeit dauern, bis Ihr Tweet tatsächlich an alle Ihre Follower geliefert wird.
Redis ist nützlich als einfacher Nachrichtenbroker, aber Nachrichten können verloren gehen.
RabbitMQ ist beliebt, aber Sie müssen sich an das "AMQP" -Protokoll anpassen und Ihre eigenen Knoten verwalten.
Amazon SQS wird gehostet, kann jedoch eine hohe Latenz haben und hat die Möglichkeit, dass Nachrichten zweimal übermittelt werden.
Aufgaben Warteschlangen erhalten Aufgaben und ihre damit verbundenen Daten, liefert sie und liefert dann ihre Ergebnisse. Sie können die Planung unterstützen und können verwendet werden, um rechnerischintensive Jobs im Hintergrund auszuführen.
Celery unterstützt die Planung und hauptsächlich Python -Unterstützung.
Wenn die Warteschlangen erheblich wachsen, kann die Warteschlangengröße größer als der Speicher werden, was zu Cache -Misses, Festplatten und sogar langsamere Leistung führt. Der Rückdruck kann helfen, indem die Warteschlangengröße begrenzt wird, wodurch eine hohe Durchsatzrate und gute Reaktionszeiten für Jobs in der Warteschlange beibehalten werden. Sobald die Warteschlange ausgefüllt ist, erhalten Clients einen Serverbetrieb oder einen HTTP 503 -Statuscode, um es später erneut zu versuchen. Kunden können die Anfrage zu einem späteren Zeitpunkt wiederholen, möglicherweise mit exponentiellem Backoff.
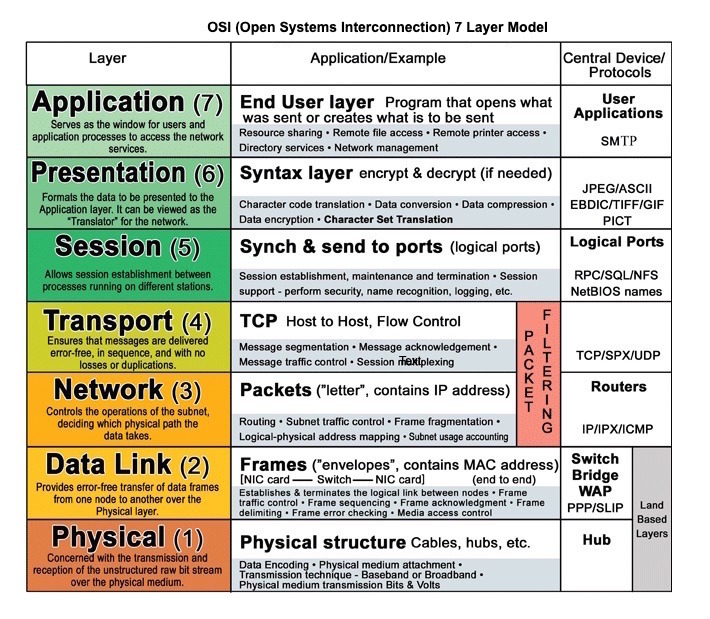
Quelle: OSI 7 -Layer -Modell
HTTP ist eine Methode zum Codieren und Transport von Daten zwischen einem Client und einem Server. Es handelt sich um ein Anfrage-/Antwortprotokoll: Clients geben Anfragen und Server aus, die Antworten mit relevanten Inhalten und Abschlussstatussinformationen zur Anfrage ausstellen. HTTP ist in sich geschlossen und ermöglicht Anforderungen und Antworten, durch viele Zwischenrouter und Server zu fließen, die Lastausgleich, Zwischenspeicherung, Verschlüsselung und Komprimierung durchführen.
Eine grundlegende HTTP -Anforderung besteht aus einem Verb (Methode) und einer Ressource (Endpunkt). Unten finden Sie gemeinsame HTTP -Verben:
| Verb | Beschreibung | Idempotent* | Sicher | Cachebar |
|---|---|---|---|---|
| ERHALTEN | Liest eine Ressource | Ja | Ja | Ja |
| POST | Erstellt eine Ressource oder löst einen Prozess aus, der Daten umgeht | NEIN | NEIN | Ja, wenn die Antwort Frischinformationen enthält |
| SETZEN | Erstellt oder ersetzen Sie eine Ressource | Ja | NEIN | NEIN |
| PATCH | Aktualisiert teilweise eine Ressource | NEIN | NEIN | Ja, wenn die Antwort Frischinformationen enthält |
| LÖSCHEN | Löscht eine Ressource | Ja | NEIN | NEIN |
*Kann viele Male ohne unterschiedliche Ergebnisse aufgerufen werden.
HTTP ist ein Anwendungsschichtprotokoll, das auf Protokollen auf niedrigerer Ebene wie TCP und UDP stützt.
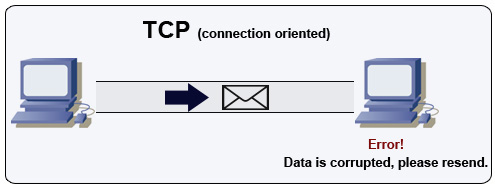
Quelle: Wie man ein Multiplayer -Spiel erstellt
TCP ist ein verbindungsorientiertes Protokoll über einem IP-Netzwerk. Die Verbindung wird unter Verwendung eines Handschlags hergestellt und beendet. Alle gesendeten Pakete erreichen garantiert das Ziel in der ursprünglichen Reihenfolge und ohne Korruption durch:
Wenn der Absender keine korrekte Antwort erhält, wird die Pakete wiedergegeben. Wenn es mehrere Zeitüberschreitungen gibt, wird die Verbindung fallen gelassen. TCP implementiert auch die Flusskontrolle und die Überlastungskontrolle. Diese Garantien verursachen Verzögerungen und führen im Allgemeinen zu einer weniger effizienten Übertragung als UDP.
Um einen hohen Durchsatz zu gewährleisten, können Webserver eine große Anzahl von TCP -Verbindungen offen halten, was zu einer hohen Speicherverwendung führt. Es kann teuer sein, eine große Anzahl offener Verbindungen zwischen Webserverthreads und einem Memcached -Server zu haben. Das Verbindungsbad kann zusätzlich zum Umschalten auf UDP hilfreich sein.
TCP ist nützlich für Anwendungen, die eine hohe Zuverlässigkeit erfordern, aber weniger zeitkritisch sind. Einige Beispiele sind Webserver, Datenbankinformationen, SMTP, FTP und SSH.
Verwenden Sie TCP über UDP, wenn:
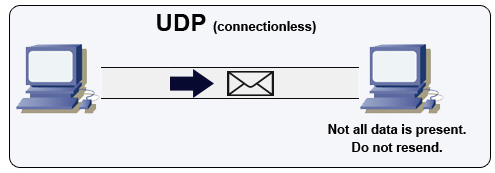
Quelle: Wie man ein Multiplayer -Spiel erstellt
UDP ist verbindlos. Datagramme (analog zu Paketen) sind nur auf Datagrammebene garantiert. Datagramme können ihr Ziel nicht in Ordnung erreichen oder gar nicht. UDP unterstützt keine Überlastungskontrolle. Ohne die Garantien, dass die TCP -Unterstützung im Allgemeinen effizienter ist.
UDP kann übertragen und Datagramme an alle Geräte auf dem Subnetz senden. Dies ist bei DHCP nützlich, da der Client noch keine IP -Adresse erhalten hat und so eine Möglichkeit für TCP verhindert, ohne die IP -Adresse zu streamen.
UDP ist weniger zuverlässig, funktioniert aber in Echtzeit -Anwendungsfällen wie VoIP, Video -Chat, Streaming und Echtzeit -Multiplayer -Spielen.
Verwenden Sie UDP über TCP, wenn:
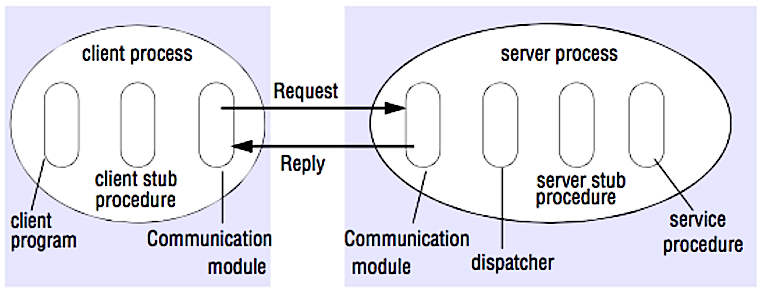
Quelle: Cracken Sie das Systemdesign -Interview
In einem RPC führt ein Client dazu, dass ein Verfahren auf einem anderen Adressraum ausgeführt wird, normalerweise einen Remote -Server. Die Prozedur wird so codiert, als wäre es ein lokaler Verfahrensanruf, der die Details zur Kommunikation mit dem Server aus dem Client -Programm abstrahiert. Remote -Anrufe sind normalerweise langsamer und weniger zuverlässig als lokale Anrufe, daher ist es hilfreich, RPC -Anrufe von lokalen Anrufen zu unterscheiden. Zu den beliebten RPC -Frameworks gehören Protobuf, Thrift und Avro.
RPC ist ein Request-Response-Protokoll:
Beispiel -RPC -Anrufe:
GET /someoperation?data=anId
POST /anotheroperation
{
"data":"anId";
"anotherdata": "another value"
}
RPC konzentriert sich darauf, Verhaltensweisen aufzudecken. RPCs werden häufig aus Leistungsgründen mit interner Kommunikation verwendet, da Sie native Anrufe von Hand handeln können, um Ihre Anwendungsfälle besser anzupassen.
Wählen Sie eine native Bibliothek (auch bekannt als SDK), wenn:
HTTP -APIs nach Ruhe werden in der Regel häufiger für öffentliche APIs verwendet.
REST ist ein architektonischer Stil, der ein Client/Server -Modell durchsetzt, bei dem der Client auf einer Reihe von Ressourcen handelt, die vom Server verwaltet werden. Der Server bietet eine Darstellung von Ressourcen und Aktionen, die entweder manipulieren oder eine neue Darstellung von Ressourcen erhalten können. Die gesamte Kommunikation muss staatenlos und zwischengespeichert werden.
Es gibt vier Eigenschaften einer erholsamen Schnittstelle:
Beispielrückrufe:
GET /someresources/anId
PUT /someresources/anId
{"anotherdata": "another value"}
Die Ruhe konzentriert sich darauf, Daten freizulegen. Es minimiert die Kopplung zwischen Client/Server und wird häufig für öffentliche HTTP -APIs verwendet. Rest verwendet eine generischer und einheitlichere Methode, um Ressourcen durch URIs, Repräsentation durch Header und Aktionen durch Verben wie Get, Post, Put, Löschen und Patch auszusetzen. Als Staatelo ist Ruhe großartig für die horizontale Skalierung und Partitionierung.
| Betrieb | RPC | AUSRUHEN |
|---|---|---|
| Melden Sie sich an | Post /Anmeldung | Post /Personen |
| Zurücktreten | Post /Rücktritt { "Personid": "1234" } | Löschen /Personen /1234 |
| Lesen Sie eine Person | Get /Readperson? Personid = 1234 | Get /persons /1234 |
| Lesen Sie die Artikelliste einer Person | GET /READUSERSITEMSList? Personid = 1234 | Get /persons/1234/Artikel |
| Fügen Sie einen Artikel zu den Artikeln einer Person hinzu | Post /AddItemTouSeStemsList { "Personid": "1234"; "itemId": "456" } | Post /Personen/1234/Artikel { "itemId": "456" } |
| Aktualisieren Sie einen Artikel | Post /modifyItem { "itemId": "456"; "Schlüssel": "Wert" } | Put /Artikel /456 { "Schlüssel": "Wert" } |
| Einen Artikel löschen | Post /removeItem { "itemId": "456" } | Löschen /Elemente /456 |
Quelle: Wissen Sie wirklich, warum Sie Pause gegenüber RPC bevorzugen?
Dieser Abschnitt könnte einige Aktualisierungen verwenden. Überlegen Sie, ob Sie einen Beitrag leisten!
Sicherheit ist ein breites Thema. Sofern Sie keine über umfassende Erfahrung, einen Sicherheitshintergrund verfügen oder sich für eine Position bewerben, die Kenntnisse über Sicherheit erfordert, müssen Sie wahrscheinlich nicht mehr wissen als die Grundlagen:
Manchmal werden Sie gebeten, Schätzungen von "Back-of-the-the-the-Envelope" vorzunehmen. Zum Beispiel müssen Sie möglicherweise bestimmen, wie lange es dauern wird, bis 100 Bildmedumbänder von der Festplatte generiert werden oder wie viel Speicher eine Datenstruktur dauert. Die Kräfte von zwei Tabellen- und Latenznummern, die jeder Programmierer kennen sollte, sind praktische Referenzen.
Power Exact Value Approx Value Bytes
---------------------------------------------------------------
7 128
8 256
10 1024 1 thousand 1 KB
16 65,536 64 KB
20 1,048,576 1 million 1 MB
30 1,073,741,824 1 billion 1 GB
32 4,294,967,296 4 GB
40 1,099,511,627,776 1 trillion 1 TB
Latency Comparison Numbers
--------------------------
L1 cache reference 0.5 ns
Branch mispredict 5 ns
L2 cache reference 7 ns 14x L1 cache
Mutex lock/unlock 25 ns
Main memory reference 100 ns 20x L2 cache, 200x L1 cache
Compress 1K bytes with Zippy 10,000 ns 10 us
Send 1 KB bytes over 1 Gbps network 10,000 ns 10 us
Read 4 KB randomly from SSD* 150,000 ns 150 us ~1GB/sec SSD
Read 1 MB sequentially from memory 250,000 ns 250 us
Round trip within same datacenter 500,000 ns 500 us
Read 1 MB sequentially from SSD* 1,000,000 ns 1,000 us 1 ms ~1GB/sec SSD, 4X memory
HDD seek 10,000,000 ns 10,000 us 10 ms 20x datacenter roundtrip
Read 1 MB sequentially from 1 Gbps 10,000,000 ns 10,000 us 10 ms 40x memory, 10X SSD
Read 1 MB sequentially from HDD 30,000,000 ns 30,000 us 30 ms 120x memory, 30X SSD
Send packet CA->Netherlands->CA 150,000,000 ns 150,000 us 150 ms
Notes
-----
1 ns = 10^-9 seconds
1 us = 10^-6 seconds = 1,000 ns
1 ms = 10^-3 seconds = 1,000 us = 1,000,000 ns
Handliche Metriken basierend auf den obigen Zahlen:
Fragen zur allgemeinen Systemdesign -Interviewfragen mit Links zu Ressourcen zur Lösung jeweils.
| Frage | Referenz (en) |
|---|---|
| Entwerfen Sie einen Dateisynchronisierungsdienst wie Dropbox | youtube.com |
| Entwerfen Sie eine Suchmaschine wie Google | queue.acm.org stackexchange.com Ardendertat.com stanford.edu |
| Entwerfen Sie einen skalierbaren Webcrawler wie Google | quora.com |
| Entwerfen Sie Google Docs | code.google.com neil.fraser.name |
| Entwerfen Sie einen Schlüsselwertgeschäft wie Redis | Slideshare.net |
| Entwerfen Sie ein Cache -System wie Memcached | Slideshare.net |
| Entwerfen Sie ein Empfehlungssystem wie Amazon's | hulu.com IJCAI13.org |
| Entwerfen Sie ein Tinyurl -System wie Bitly | n00tc0d3r.blogspot.com |
| Entwerfen Sie eine Chat -App wie WhatsApp | HighScalability.com |
| Entwerfen Sie ein Bildfreigabesystem wie Instagram | HighScalability.com HighScalability.com |
| Entwerfen Sie die Facebook -News -Feed -Funktion | quora.com quora.com Slideshare.net |
| Entwerfen Sie die Facebook -Timeline -Funktion | facebook.com HighScalability.com |
| Entwerfen Sie die Facebook -Chat -Funktion | Erlang-factory.com facebook.com |
| Entwerfen Sie eine Graph -Suchfunktion wie Facebooks | facebook.com facebook.com facebook.com |
| Entwerfen Sie ein Inhaltsdeliefer -Netzwerk wie CloudFlare | Figshare.com |
| Entwerfen Sie ein Trendthema -System wie Twitters | Michael-Noll.com snikolov .wordpress.com |
| Entwerfen Sie ein zufälliges ID -Generierungssystem | blog.twitter.com github.com |
| Geben Sie die Top -K -Anfragen während eines Zeitintervalls zurück | cs.ucsb.edu wpi.edu |
| Entwerfen Sie ein System, das Daten aus mehreren Rechenzentren bedient | HighScalability.com |
| Entwerfen Sie ein Online -Multiplayer -Kartenspiel | indieflashblog.com BuildNewgames.com |
| Entwerfen Sie ein Müllsammlungssystem | StuffWithStuff.com Washington.edu |
| Entwerfen Sie einen API -Ratenbegrenzer | https://stripe.com/blog/ |
| Entwerfen Sie eine Börse (wie Nasdaq oder Binance) | Jane Street Golang -Implementierung GO -Implementierung |
| Fügen Sie eine Systemdesignfrage hinzu | Beitragen |
Artikel darüber, wie reale Systeme entwickelt werden.
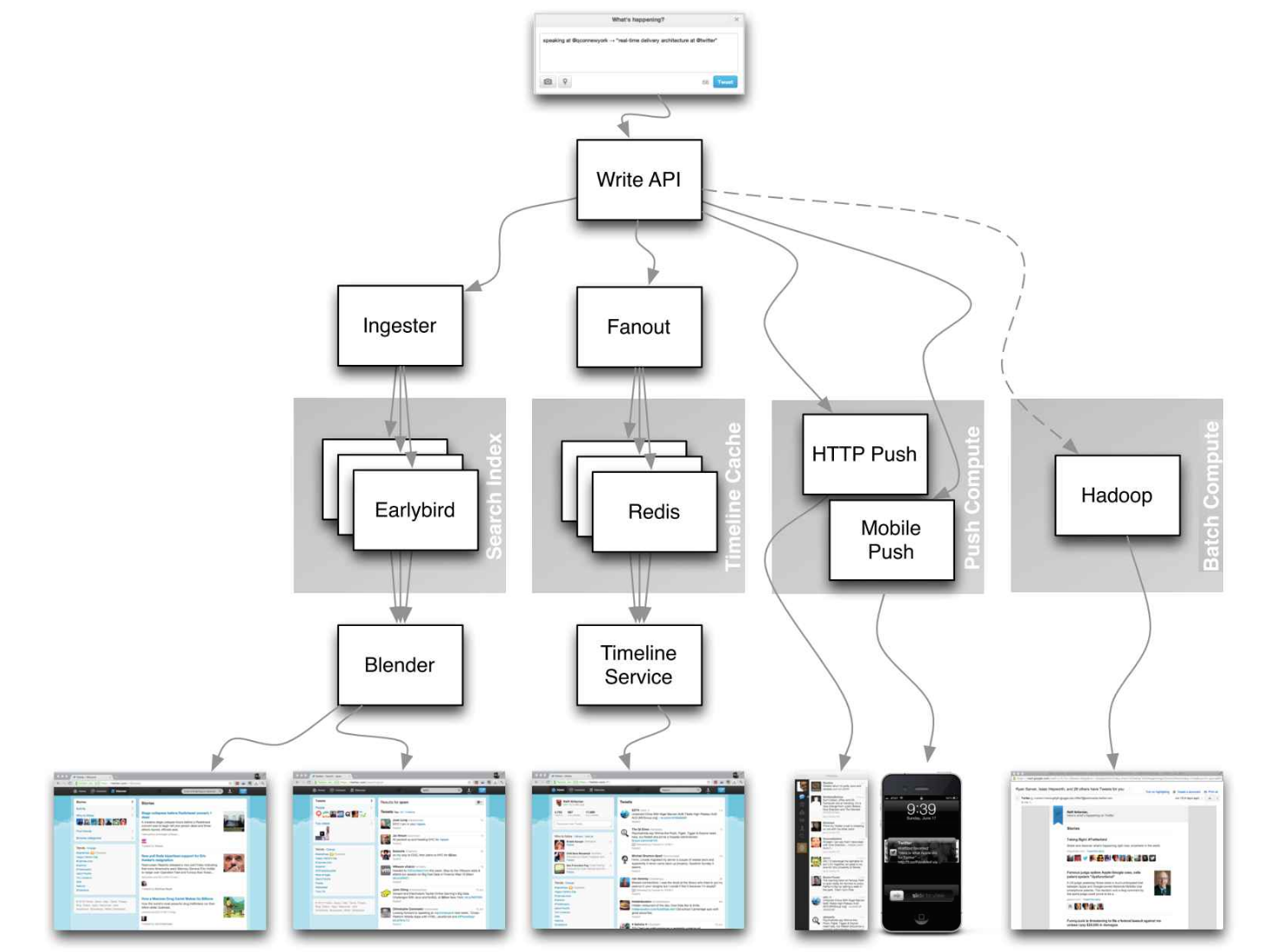
Quelle: Twitter -Zeitlinien im Maßstab
Konzentrieren Sie sich nicht auf detaillierte Details für die folgenden Artikel: stattdessen:
| Typ | System | Referenz (en) |
|---|---|---|
| Datenverarbeitung | MapReduce - Verteilte Datenverarbeitung von Google | Research.google.com |
| Datenverarbeitung | Spark - Verteilte Datenverarbeitung aus Datenbanken | Slideshare.net |
| Datenverarbeitung | Sturm - Verteilte Datenverarbeitung von Twitter | Slideshare.net |
| Datenspeicher | Bigtable - Verteilte spaltenorientierte Datenbank von Google | harvard.edu |
| Datenspeicher | HBase - Open Source -Implementierung von Bigtable | Slideshare.net |
| Datenspeicher | Cassandra - Verteilte spaltenorientierte Datenbank von Facebook | Slideshare.net |
| Datenspeicher | DynamoDB - Dokumentorientierte Datenbank von Amazon | harvard.edu |
| Datenspeicher | MongoDB - Dokumentorientierte Datenbank | Slideshare.net |
| Datenspeicher | Spanner - global verteilte Datenbank von Google | Research.google.com |
| Datenspeicher | Memcached - verteiltes Speicher -Caching -System | slideshare.net |
| Data store | Redis - Distributed memory caching system with persistence and value types | slideshare.net |
| File system | Google File System (GFS) - Distributed file system | research.google.com |
| File system | Hadoop File System (HDFS) - Open source implementation of GFS | apache.org |
| Sonstiges | Chubby - Lock service for loosely-coupled distributed systems from Google | research.google.com |
| Sonstiges | Dapper - Distributed systems tracing infrastructure | research.google.com |
| Sonstiges | Kafka - Pub/sub message queue from LinkedIn | slideshare.net |
| Sonstiges | Zookeeper - Centralized infrastructure and services enabling synchronization | slideshare.net |
| Add an architecture | Beitragen |
| Unternehmen | Reference(s) |
|---|---|
| Amazonas | Amazon architecture |
| Cinchcast | Producing 1,500 hours of audio every day |
| DataSift | Realtime datamining At 120,000 tweets per second |
| Dropbox | How we've scaled Dropbox |
| ESPN | Operating At 100,000 duh nuh nuhs per second |
| Google architecture | |
| 14 million users, terabytes of photos What powers Instagram | |
| Justin.tv | Justin.Tv's live video broadcasting architecture |
| Scaling memcached at Facebook TAO: Facebook's distributed data store for the social graph Facebook's photo storage How Facebook Live Streams To 800,000 Simultaneous Viewers | |
| Flickr | Flickr architecture |
| Briefkasten | From 0 to one million users in 6 weeks |
| Netflix | A 360 Degree View Of The Entire Netflix Stack Netflix: What Happens When You Press Play? |
| From 0 To 10s of billions of page views a month 18 million visitors, 10x growth, 12 employees | |
| Playfish | 50 million monthly users and growing |
| PlentyOfFish | PlentyOfFish architecture |
| Salesforce | How they handle 1.3 billion transactions a day |
| Stack Overflow | Stack Overflow architecture |
| TripAdvisor | 40M visitors, 200M dynamic page views, 30TB data |
| Tumblr | 15 billion page views a month |
| Making Twitter 10000 percent faster Storing 250 million tweets a day using MySQL 150M active users, 300K QPS, a 22 MB/S firehose Timelines at scale Big and small data at Twitter Operations at Twitter: scaling beyond 100 million users How Twitter Handles 3,000 Images Per Second | |
| Uber | How Uber scales their real-time market platform Lessons Learned From Scaling Uber To 2000 Engineers, 1000 Services, And 8000 Git Repositories |
| The WhatsApp architecture Facebook bought for $19 billion | |
| YouTube | YouTube scalability YouTube architecture |
Architectures for companies you are interviewing with.
Questions you encounter might be from the same domain.
Looking to add a blog? To avoid duplicating work, consider adding your company blog to the following repo:
Interested in adding a section or helping complete one in-progress? Beitragen!
Credits and sources are provided throughout this repo.
Besonderer Dank geht an:
Feel free to contact me to discuss any issues, questions, or comments.
My contact info can be found on my GitHub page.
I am providing code and resources in this repository to you under an open source license. Because this is my personal repository, the license you receive to my code and resources is from me and not my employer (Facebook).
Copyright 2017 Donne Martin
Creative Commons Attribution 4.0 International License (CC BY 4.0)
http://creativecommons.org/licenses/by/4.0/


