amazon sagemaker clip search
1.0.0
Ziel dieses Repositorys ist der Aufbau eines Suchmaschinenprototyps mit maschinellem Lernen (ML), um Produkte basierend auf Text- oder Bildabfragen abzurufen und zu empfehlen. Dies ist eine Schritt-für-Schritt-Anleitung zum Erstellen von SageMaker-Modellen mit Contrastive Language-Image Pre-Training (CLIP), zum Verwenden der Modelle zum Codieren von Bildern und Text in Einbettungen, zum Aufnehmen von Einbettungen in den Amazon OpenSearch Service-Index und zum Abfragen des Index Verwendung der KNN-Funktionalität (K-Nearest Neighbors) des OpenSearch Service.
Embedding-based Retrieval (EBR) wird häufig in Such- und Empfehlungssystemen eingesetzt. Es verwendet Suchalgorithmen für den nächsten (ungefähren) Nachbarn, um ähnliche oder eng verwandte Elemente in einem Einbettungsspeicher (auch als Vektordatenbank bezeichnet) zu finden. Klassische Suchmechanismen basieren stark auf der Übereinstimmung von Schlüsselwörtern und ignorieren die lexikalische Bedeutung oder den Kontext der Abfrage. Ziel von EBR ist es, Benutzern die Möglichkeit zu geben, mithilfe von Freitext die relevantesten Produkte zu finden. Es ist beliebt, weil es im Vergleich zum Schlüsselwortabgleich semantische Konzepte im Abrufprozess nutzt.
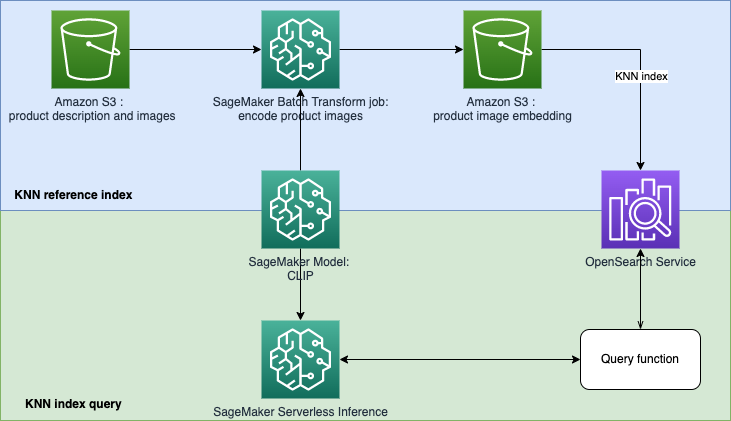
In diesem Repo konzentrieren wir uns auf den Aufbau eines Suchmaschinenprototyps mit maschinellem Lernen (ML), um Produkte basierend auf Text- oder Bildabfragen abzurufen und zu empfehlen. Dabei werden der Amazon OpenSearch Service und seine KNN-Funktionalität (K-Nearest Neighbors) sowie Amazon SageMaker und seine serverlose Inferenzfunktion verwendet. Amazon SageMaker ist ein vollständig verwalteter Dienst, der jedem Entwickler und Datenwissenschaftler die Möglichkeit bietet, ML-Modelle für jeden Anwendungsfall mit vollständig verwalteter Infrastruktur, Tools und Workflows zu erstellen, zu trainieren und bereitzustellen. Amazon OpenSearch Service ist ein vollständig verwalteter Dienst, der die Durchführung interaktiver Protokollanalysen, Echtzeit-Anwendungsüberwachung, Website-Suche und mehr erleichtert.
Contrastive Language-Image Pre-Training (CLIP) ist ein neuronales Netzwerk, das auf eine Vielzahl von Bild- und Textpaaren trainiert wird. Das/die CLIP-Neuronale(s)-Netzwerk(e) ist/sind in der Lage, sowohl Bilder als auch Text in denselben latenten Raum zu projizieren, was bedeutet, dass sie mithilfe eines Ähnlichkeitsmaßes wie der Kosinusähnlichkeit verglichen werden können. Sie können CLIP verwenden, um die Bilder oder Beschreibungen Ihrer Produkte in Einbettungen zu kodieren und diese dann in einer Vektordatenbank zu speichern. Anschließend können Ihre Kunden Abfragen in der Datenbank durchführen, um Produkte abzurufen, die für sie von Interesse sein könnten. Um die Datenbank abzufragen, müssen Ihre Kunden Eingabebilder oder Text bereitstellen. Anschließend wird die Eingabe mit CLIP codiert, bevor sie zur KNN-Suche an die Vektordatenbank gesendet wird.
Die Vektordatenbank übernimmt hier die Rolle einer Suchmaschine. Diese Vektordatenbank unterstützt die Vereinheitlichung von Bildern und die textbasierte Suche, was besonders in der E-Commerce- und Einzelhandelsbranche nützlich ist. Ein Beispiel für eine bildbasierte Suche ist, dass Ihre Kunden nach einem Produkt suchen können, indem sie ein Bild aufnehmen und dann anhand des Bildes eine Datenbankabfrage durchführen. Bei der textbasierten Suche können Ihre Kunden ein Produkt in frei formatiertem Text beschreiben und den Text dann als Suchanfrage verwenden. Die Suchergebnisse werden nach einem Ähnlichkeitswert (Kosinus-Ähnlichkeit) sortiert. Wenn ein Artikel Ihres Inventars der Suchanfrage (einem eingegebenen Bild oder Text) ähnlicher ist, liegt der Wert näher bei 1, andernfalls liegt der Wert eher bei 0. Die Top-K-Produkte Ihrer Suchergebnisse sind die relevantesten Produkte in Ihrem Inventar.
Der OpenSearch-Dienst bietet Textabgleich und Einbettung einer KNN-basierten Suche. Wir werden die Einbettung der KNN-basierten Suche in dieser Lösung verwenden. Sie können sowohl Bilder als auch Text als Abfrage verwenden, um nach Artikeln im Inventar zu suchen. Die Implementierung dieser einheitlichen Bild- und Test-KNN-basierten Suchanwendung besteht aus zwei Phasen:
Die Lösung nutzt die folgenden AWS-Dienste und -Funktionen:
In der Vorlage opensearch.yml wird eine OpenSearch-Domäne erstellt und Ihrer SageMaker Studio-Ausführungsrolle die Verwendung der Domäne gewährt.
In der Vorlage sagemaker-studio-opensearch.yml werden eine neue SageMaker-Domäne, ein Benutzerprofil in der Domäne und eine OpenSearch-Domäne erstellt. Sie können also das StageMaker-Benutzerprofil verwenden, um diesen POC zu erstellen.
Sie können eine der auszuführenden Vorlagen auswählen, indem Sie die unten aufgeführten Schritte ausführen.
Schritt 1: Gehen Sie in Ihrer AWS-Konsole zu CloudFormation Service. 
Schritt 2: Laden Sie eine Vorlage hoch, um einen CloudFormation-Stack clip-poc-stack zu erstellen.
Wenn Sie bereits ein SageMaker Studio ausführen, können Sie die Vorlage opensearch.yml verwenden. 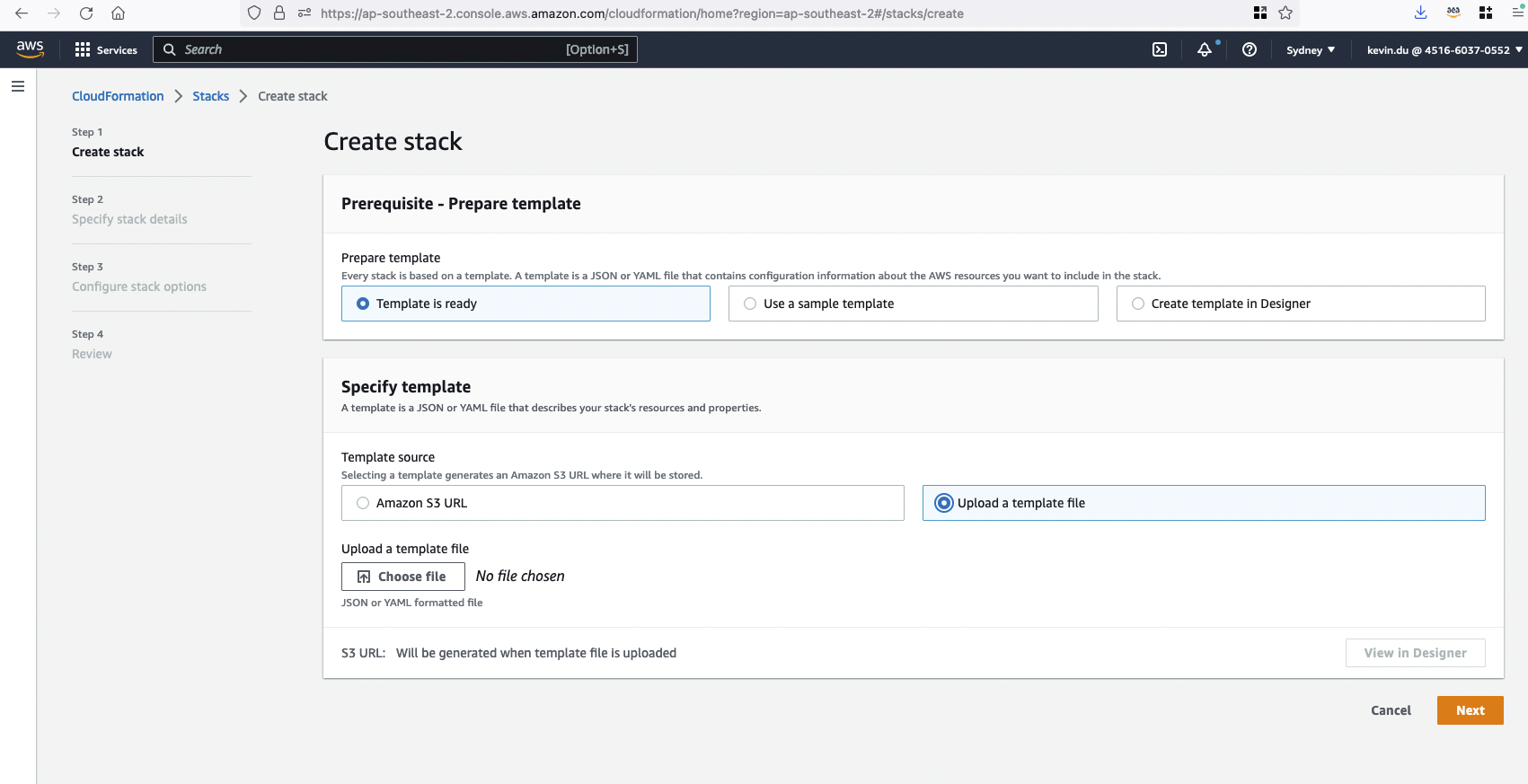
Wenn Sie derzeit kein SageMaker Studio haben, können Sie die Vorlage sagemaker-studio-opensearch.yml verwenden. Es wird eine Studio-Domäne und ein Benutzerprofil für Sie erstellt.
Schritt 3: Überprüfen Sie den Status des CloudFormation-Stacks. Es wird etwa 20 Minuten dauern, bis die Erstellung abgeschlossen ist. 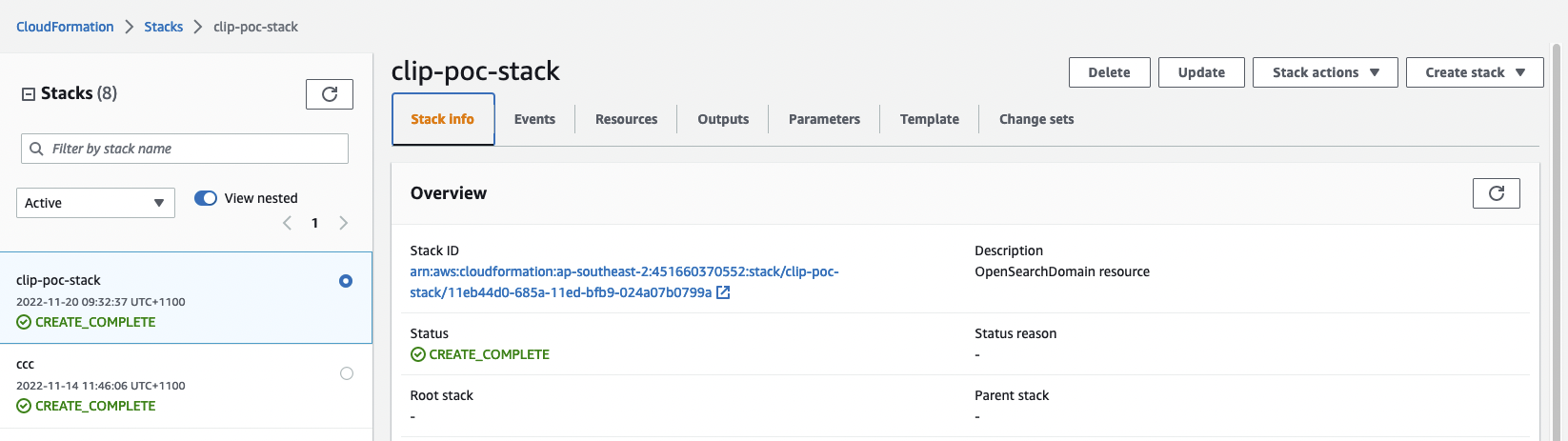
Sobald der Stack erstellt ist, können Sie zur SageMaker-Konsole gehen und auf Open Studio klicken, um die Jupyter-Umgebung aufzurufen. 
Wenn während der Ausführung in CloudFormation Fehler angezeigt werden, dass die mit dem OpenSearch-Dienst verknüpfte Rolle nicht gefunden werden kann. Sie müssen eine serviceverknüpfte Rolle erstellen, indem Sie aws iam create-service-linked-role --aws-service-name es.amazonaws.com in Ihrem AWS-Konto ausführen.
Bitte öffnen Sie die Datei blog_clip.ipynb mit SageMaker Studio und verwenden Sie Data Science Python 3 -Kernel. Sie können Zellen von Anfang an ausführen.
Bei der Implementierung wird der Amazon Berkeley Objects Dataset verwendet. Der Datensatz ist eine Sammlung von 147.702 Produktlisten mit mehrsprachigen Metadaten und 398.212 einzigartigen Katalogbildern. Wir verwenden die Artikelbilder und Artikelnamen nur in US-Englisch. Für Demozwecke werden wir etwa 1.600 Produkte verwenden.
In diesem Abschnitt werden Kostenüberlegungen für die Ausführung dieser Demo erläutert. Durch den Abschluss des POC werden ein OpenSearch-Cluster und ein SageMaker Studio bereitgestellt, was weniger als 2 US-Dollar pro Stunde kostet. Hinweis: Der unten aufgeführte Preis wird anhand der Region us-east-1 berechnet. Die Kosten variieren von Region zu Region. Und auch die Kosten können sich im Laufe der Zeit ändern (der Preis ist hier am 22.11.2022 angegeben).
Weitere Kostenaufschlüsselungen finden Sie weiter unten.
OpenSearch-Service – Die Preise variieren je nach Instanztyp-Nutzung und Speicherkosten. Weitere Informationen finden Sie unter Amazon OpenSearch Service-Preise.
t3.small.search Instanz läuft ca. 1 Stunde lang und kostet 0,036 $ pro Stunde.SageMaker – Die Preise variieren je nach EC2-Instanznutzung für die Studio-Apps, Batch-Transformationsjobs und Serverless Inference-Endpunkte. Weitere Informationen finden Sie unter Amazon SageMaker-Preise.
ml.t3.medium Instanz für Studio-Notebooks läuft etwa 1 Stunde lang und kostet 0,05 $ pro Stunde.ml.c5.xlarge Instanz für Batch Transform läuft ca. 6 Minuten bei 0,204 $ pro Stunde.S3 – Niedrige Kosten, die Preise variieren je nach Größe der gelagerten Modelle/Artefakte. Die ersten 50 TB pro Monat kosten nur 0,023 US-Dollar pro gespeichertem GB. Weitere Informationen finden Sie unter Amazon S3-Preise.
Weitere Informationen finden Sie unter BEITRAGEN.
Diese Bibliothek ist unter der MIT-0-Lizenz lizenziert. Siehe die LICENSE-Datei.


