LLaMA LoRA Tuner
v0.0.20230421
Erleichtert die Bewertung und Feinabstimmung von LLaMA-Modellen mit Low-Rank-Adaption (LoRA).
Aktualisieren :
Im
devgibt es eine neue Chat-Benutzeroberfläche und eine neue Demo-Modus -Konfiguration als einfache Möglichkeit, neue Modelle zu demonstrieren.Allerdings verfügt die neue Version noch nicht über die Feinabstimmungsfunktion und ist nicht abwärtskompatibel, da sie eine neue Methode zur Definition des Ladens von Modellen sowie ein neues Format von Eingabeaufforderungsvorlagen (von LangChain) verwendet.
Weitere Informationen finden Sie unter: #28.
LLM.Tuner.Chat.UI.in.Demo.Mode.mp4
Sehen Sie sich eine Demo zu Hugging Face an . * Dient nur zur Demonstration der Benutzeroberfläche. Um das Training oder die Textgenerierung auszuprobieren, führen Sie Colab aus.
Mit nur einem Klick in Google Colab mit einer Standard-GPU-Laufzeitumgebung starten .
Lädt und speichert Daten in Google Drive.
Bewerten Sie verschiedene LLaMA LoRA-Modelle, die in Ihrem Ordner oder in Hugging Face gespeichert sind. 
Wechseln Sie zwischen Basismodellen wie decapoda-research/llama-7b-hf , nomic-ai/gpt4all-j , databricks/dolly-v2-7b , EleutherAI/gpt-j-6b oder EleutherAI/pythia-6.9b .
Optimieren Sie LLaMA-Modelle mit verschiedenen Eingabeaufforderungsvorlagen und Trainingsdatensatzformaten. 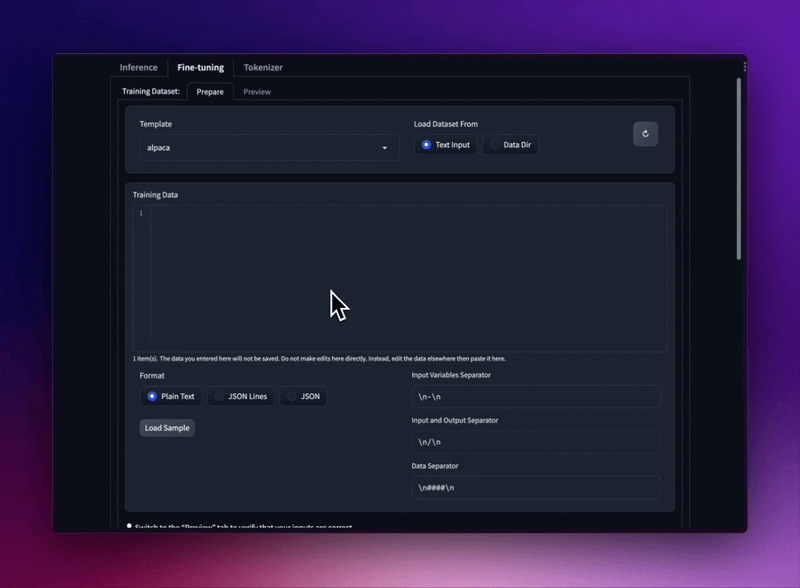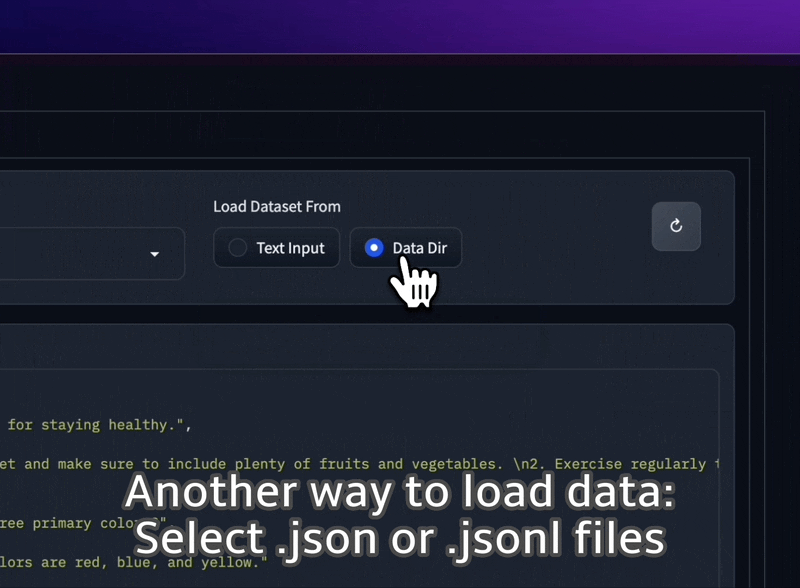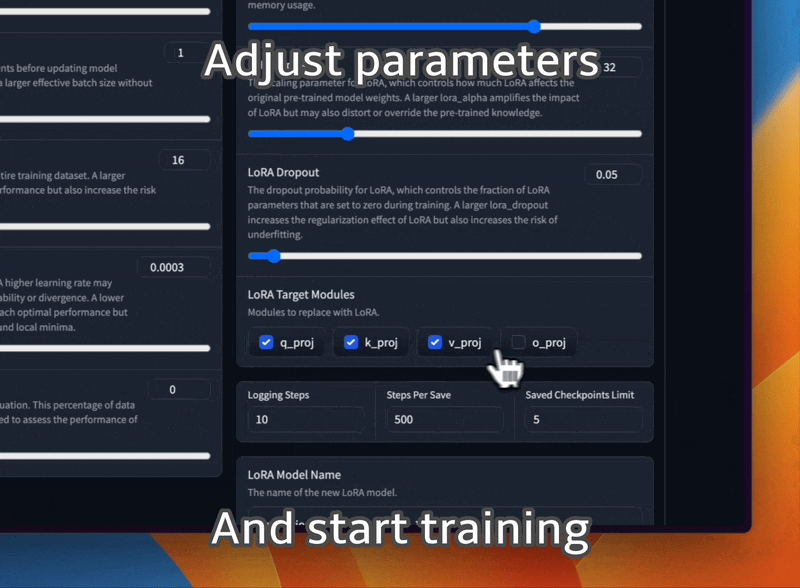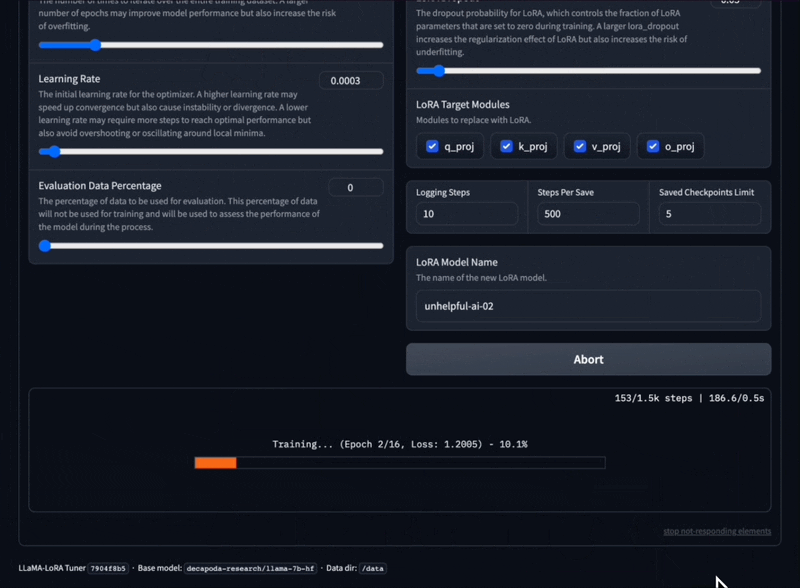
Laden Sie JSON- und JSONL-Datensätze aus Ihrem Ordner oder fügen Sie einfachen Text direkt in die Benutzeroberfläche ein.
Unterstützt Stanford Alpaca seeds_tasks, alpaca_data und OpenAI „prompt“-„completion“-Format.
Verwenden Sie Eingabeaufforderungsvorlagen, um Ihren Datensatz trocken zu halten.
Es gibt verschiedene Möglichkeiten, diese App auszuführen:
Auf Google Colab ausführen : Der einfachste Einstieg: Sie benötigen lediglich ein Google-Konto. Die standardmäßige (kostenlose) GPU-Laufzeit reicht aus, um Generierung und Training mit einer Mikrobatchgröße von 8 auszuführen. Allerdings ist die Textgenerierung und das Training viel langsamer als bei anderen Cloud-Diensten, und Colab bricht die Ausführung möglicherweise bei Inaktivität ab, während lange Aufgaben ausgeführt werden.
Ausführung auf einem Cloud-Dienst über SkyPilot : Wenn Sie über ein Cloud-Dienst-Konto (Lambda Labs, GCP, AWS oder Azure) verfügen, können Sie SkyPilot verwenden, um die App auf einem Cloud-Dienst auszuführen. Zur Aufbewahrung Ihrer Daten kann ein Cloud-Bucket bereitgestellt werden.
Lokal ausführen : Hängt von der Hardware ab, die Sie haben.
Eine Schritt-für-Schritt-Anleitung finden Sie im Video.
Öffnen Sie dieses Colab-Notizbuch und wählen Sie Laufzeit > Alle ausführen ( ⌘/Ctrl+F9 ).
Sie werden aufgefordert, den Zugriff auf Google Drive zu autorisieren, da Google Drive zum Speichern Ihrer Daten verwendet wird. Einstellungen und weitere Informationen finden Sie im Abschnitt „Config“/„Google Drive“.
Nach ca. 5 Minuten Laufzeit sehen Sie die öffentliche URL in der Ausgabe des Abschnitts „Launch“/„Gradio UI starten“ (z. B. „ Running on public URL: https://xxxx.gradio.live “). Öffnen Sie die URL in Ihrem Browser, um die App zu verwenden.
Nachdem Sie der Installationsanleitung von SkyPilot gefolgt sind, erstellen Sie eine .yaml um eine Aufgabe zum Ausführen der App zu definieren:
# llm-tuner.yamlresources: Beschleuniger: A10:1 # 1x NVIDIA A10 GPU, ca. 0,6 US-Dollar pro Stunde in Lambda Cloud. Führen Sie „sky show-gpus“ für unterstützte GPU-Typen und „sky show-gpus [GPU_NAME]“ für detaillierte Informationen zu einem GPU-Typ aus.
cloud: lambda # Optional; Wenn es weggelassen wird, wählt SkyPilot automatisch die günstigste Cloud aus.file_mounts: # Mounten Sie einen ausgewählten Cloud-Speicher, der als Datenverzeichnis verwendet wird.
# (um trainierte Modelle mit Zugdatensätzen zu speichern)
# Weitere Informationen finden Sie unter https://skypilot.readthedocs.io/en/latest/reference/storage.html.
/data:name: llm-tuner-data # Stellen Sie sicher, dass dieser Name eindeutig ist, sonst besitzen Sie diesen Bucket. Wenn es nicht vorhanden ist, versucht SkyPilot, einen Bucket mit diesem Namen zu erstellen.store: s3 # Könnte einer der folgenden sein: [s3, gcs]mode: MOUNT# Klonen Sie das LLaMA-LoRA Tuner-Repo und installieren Sie seine Abhängigkeiten.setup: | conda create -q python=3.8 -n llm-tuner -y conda activate llm-tuner # Klonen Sie das LLaMA-LoRA Tuner-Repo und installieren Sie seine Abhängigkeiten [ ! -d llm_tuner ] && git clone https://github.com/zetavg/LLaMA-LoRA-Tuner.git llm_tuner echo 'Abhängigkeiten installieren...' pip install -r llm_tuner/requirements.lock.txt # Optional: Wandb installieren auf Aktivieren Sie die Protokollierung für Gewichtungen und Biases. pip install wandb # Optional: Bitsandbytes patchen, um den Fehler zu umgehen "libbitsandbytes_cpu.so: undefiniertes Symbol: cget_col_row_stats" BITSANDBYTES_LOCATION="$(pip show bitsandbytes | grep 'Location' | awk '{print $2}')/bitsandbytes" [ -f "$BITSANDBYTES_LOCATION/libbitsandbytes_cpu.so" ] && [ ! -f "$BITSANDBYTES_LOCATION/libbitsandbytes_cpu.so.bak" ] && [ -f "$BITSANDBYTES_LOCATION/libbitsandbytes_cuda121.so" ] && echo 'Bitsandbytes für GPU-Unterstützung patchen...' && mv "$BITSANDBYTES_LOCATION/libbitsandbytes_cuda121.so" "$BITSANDBYTES_LOCATION/libbitsandbytes_cpu.so.bak" && cp "$BITSANDBYTES_LOCATION/libbitsandbytes_cuda121.so" "$BITSANDBYTES_LOCATION/libbitsandbytes_cpu.so" conda install -q cudatoolkit -y echo 'Abhängigkeiten installiert.' # Optional: Installieren und richten Sie Cloudflare Tunnel ein, um die App mit einem benutzerdefinierten Domänennamen dem Internet zugänglich zu machen [ -f /data/secrets/cloudflared_tunnel_token.txt ] && echo "Installing Cloudflare" && curl -L --output cloudflared.deb https: //github.com/cloudflare/cloudflared/releases/latest/download/cloudflared-linux-amd64.deb && sudo dpkg -i cloudflared.deb && sudo cloudflared service uninstall || : && sudo cloudflared service install "$(cat /data/secrets/cloudflared_tunnel_token.txt | tr -d 'n')" # Optional: pre-download models echo "Basismodelle vorab herunterladen, damit Sie nicht warten müssen lange, sobald die App fertig ist ...“ python llm_tuner/download_base_model.py --base_model_names='decapoda-research/llama-7b-hf,nomic-ai/gpt4all-j'# Starten Sie die App. „hf_access_token“, „wandb_api_key“ und „wandb_project“ sind optional.run: | conda activate llm-tuner python llm_tuner/app.py --data_dir='/data' --hf_access_token="$([ -f /data/secrets/hf_access_token.txt ] && cat /data/secrets/hf_access_token.txt | tr -d 'n')" --wandb_api_key="$([ -f /data/secrets/wandb_api_key.txt ] && cat /data/secrets/wandb_api_key.txt |. tr -d 'n')" --wandb_project='llm-tuner' --timezone='Atlantic/Reykjavik' --base_model= 'decapoda-research/llama-7b-hf' --base_model_choices='decapoda-research/llama-7b-hf,nomic-ai/gpt4all-j,databricks/dolly-v2-7b' --shareStarten Sie dann einen Cluster, um die Aufgabe auszuführen:
sky launch -c llm-tuner llm-tuner.yaml
-c ... ist ein optionales Flag zur Angabe eines Clusternamens. Wenn nichts angegeben wird, generiert SkyPilot automatisch einen.
Sie sehen die öffentliche URL der App im Terminal. Öffnen Sie die URL in Ihrem Browser, um die App zu verwenden.
Beachten Sie, dass durch das Beenden von sky launch nur das Protokoll-Streaming beendet und die Aufgabe nicht gestoppt wird. Mit sky queue --skip-finished können Sie den Status laufender oder ausstehender Aufgaben anzeigen, sky logs <cluster_name> <job_id> eine Verbindung zum Protokoll-Streaming herstellen und sky cancel <cluster_name> <job_id> eine Aufgabe stoppen.
Wenn Sie fertig sind, führen Sie sky stop <cluster_name> aus, um den Cluster zu stoppen. Um stattdessen einen Cluster zu beenden, führen Sie sky down <cluster_name> aus.
Denken Sie daran, den Cluster zu stoppen oder herunterzufahren, wenn Sie fertig sind, um unerwartete Kosten zu vermeiden. Führen Sie sky cost-report aus, um die Kosten Ihrer Cluster anzuzeigen.
Um sich bei der Cloud-Maschine anzumelden, führen Sie ssh <cluster_name> aus, z. B. ssh llm-tuner .
Wenn Sie sshfs auf Ihrem lokalen Computer installiert haben, können Sie das Dateisystem des Cloud-Computers auf Ihrem lokalen Computer bereitstellen, indem Sie einen Befehl wie den folgenden ausführen:
mkdir -p /tmp/llm_tuner_server && umount /tmp/llm_tuner_server || : && sshfs llm-tuner:/ /tmp/llm_tuner_server
conda create -y python=3.8 -n llm-tuner Conda aktiviert den LLM-Tuner
pip install -r Anforderungen.lock.txt python app.py --data_dir='./data' --base_model='decapoda-research/llama-7b-hf' --timezone='Atlantic/Reykjavik' --share
Im Terminal werden Ihnen die lokalen und öffentlichen URLs der App angezeigt. Öffnen Sie die URL in Ihrem Browser, um die App zu verwenden.
Weitere Optionen finden Sie unter python app.py --help .
Um die Benutzeroberfläche zu testen, ohne das Sprachmodell zu laden, verwenden Sie das Flag --ui_dev_mode :
python app.py --data_dir='./data' --base_model='decapoda-research/llama-7b-hf' --share --ui_dev_mode
Um Gradio Auto-Reloading zu verwenden, ist eine
config.yamlDatei erforderlich, da Befehlszeilenargumente nicht unterstützt werden. Für den Anfang gibt es eine Beispieldatei:cp config.yaml.sample config.yaml. Führen Sie dann einfachgradio app.pyaus.
Siehe Video auf YouTube.
https://github.com/tloen/alpaca-lora
https://github.com/lxe/simple-llama-finetuner
...
TBC


