LLaMA Omni
1.0.0
Autoren: Qingkai Fang, Shoutao Guo, Yan Zhou, Zhengrui MA, Shaolei Zhang, Yang Feng*
LAMA-AMNI ist ein sprachsprachiges Modell, das auf Lama-3.1-8b-Instruktur basiert. Es unterstützt geringe Latenz und qualitativ hochwertige Sprachinteraktionen und generiert gleichzeitig sowohl Text- als auch Sprachantworten auf der Grundlage von Sprachanweisungen.
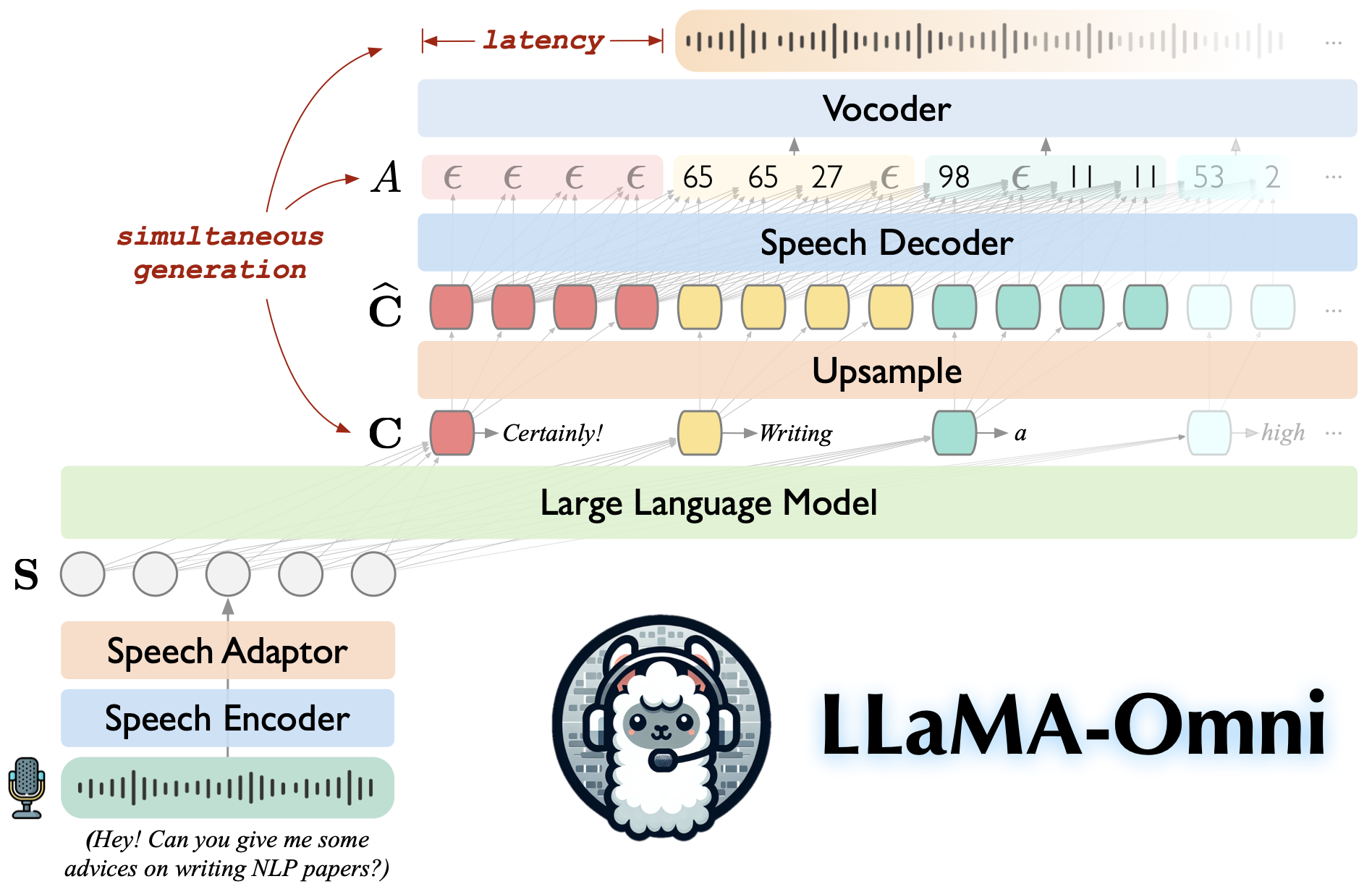
Aufgebaut auf Lama-3.1-8B-Instruktur, um hochwertige Antworten zu gewährleisten.
Sprachinteraktion mit niedriger Latenz mit einer Latenz von nur 226 ms.
Gleichzeitige Erzeugung von Text- und Sprachantworten.
♻️ In weniger als 3 Tagen mit nur 4 GPUs trainiert.
Klonen Sie dieses Repository.
Git Clone https://github.com/ictnlp/llama-omnicd llama-omni
Pakete installieren.
Conda Create -n llama -omni python = 3.10 Conda aktivieren Lama-omni PIP Installieren Sie PIP == 24.0 PIP install -e.
fairseq installieren.
Git Clone https://github.com/pytorch/fairseqcd fairseq PIP install -e. -No-Build-Isolation
Installieren Sie flash-attention .
PIP Installieren Sie Flash-Attn-Nr.
Laden Sie das Llama-3.1-8B-Omni Modell von Huggingface herunter.
Laden Sie das Modell Whisper-large-v3 herunter.
Flüstern importieren
model = wihsper.load_model ("groß-v3", download_root = "models/rede_encoder/")Laden Sie den Hifi-Gan-Vocoder der Einheit herunter.
wGet https://dl.fbaipublicfiles.com/fairseq/speech_to_speech/vocoder/code_hifigan/mhubert_vp_en_es_ff_it3_400k_layer11_km1000_lj/g_00500000 -p vocoder/ wGet https://dl.fbaipublicfiles.com/fairseq/speech_to_speech/vocoder/code_hifigan/mhubert_vp_en_es_ff_it3_400k_layer11_km1000_lj/config.json -p vocoder/
Starten Sie einen Controller.
Python -m omni_speech.serve.Controller -Host 0.0.0.0 -Port 10000
Starten Sie einen Gradio -Webserver.
python -m omni_speech.serve.gradio_web_server-controller http: // localhost: 10000 --port 8000 ---model-list-mode reload-Vocoder Vocoder/G_00500000-VocoCoder/config.json
Starten Sie einen Modellarbeiter.
python -m omni_speech.serve.model_worker-host 0.0.0.0--Controller http: // localhost: 10000 --port 40000-Arbeiter http: // localhost: 40000 ---model-path llama-3.1-8b-omni -Model-name LAMA-3.1-8B-OMNI--S2S
Besuchen Sie http: // localhost: 8000/und interagieren Sie mit LAMA-3.1-8B-OMNI!
Hinweis: Aufgrund der Instabilität des Streaming von Audio -Wiedergabe in Gradio haben wir nur die Streaming -Audio -Synthese implementiert, ohne Autoplay zu aktivieren. Wenn Sie eine gute Lösung haben, können Sie eine PR einreichen. Danke!
Um Inferenz lokal auszuführen, organisieren Sie die Sprachanweisungsdateien nach dem Format im Verzeichnis omni_speech/infer/examples und beziehen Sie sich dann auf das folgende Skript.
bash omni_speech/infer/run.sh omni_speech/infer/Beispiele
Unser Code wird unter der Lizenz Apache-2.0 veröffentlicht. Unser Modell ist nur für akademische Forschungszwecke gedacht und kann möglicherweise nicht für kommerzielle Zwecke verwendet werden.
Sie können dieses Modell frei verwenden, ändern und verteilen, sofern die folgenden Bedingungen erfüllt sind:
Nichtkommerzielle Verwendung : Das Modell wird möglicherweise nicht für kommerzielle Zwecke verwendet.
Zitat : Wenn Sie dieses Modell in Ihrer Forschung verwenden, zitieren Sie bitte die ursprüngliche Arbeit.
Für Anfragen für kommerzielle Nutzung oder um eine kommerzielle Lizenz zu erhalten, wenden Sie sich bitte an [email protected] .
LLAVA: Die Codebasis, auf der wir aufgebaut sind.
SLAM-LLM: Wir leihen uns einen Code über Sprachcodierer und Sprachadapter aus.
Wenn Sie Fragen haben, können Sie bitte ein Problem einreichen oder sich an [email protected] wenden.
Wenn unsere Arbeit für Sie nützlich ist, zitieren Sie bitte:
@article{fang-etal-2024-llama-omni,
title={LLaMA-Omni: Seamless Speech Interaction with Large Language Models},
author={Fang, Qingkai and Guo, Shoutao and Zhou, Yan and Ma, Zhengrui and Zhang, Shaolei and Feng, Yang},
journal={arXiv preprint arXiv:2409.06666},
year={2024}
} 

