JoyVASA
1.0.0
Xuyang Cao1* Guoxin Wang12* Sheng Shi1* Jun Zhao1 Yang Yao1
Jintao Fei1 Minyu Gao1
1JD Health International Inc. 2Zhejiang University
Audio-driven portrait animation has made significant advances with diffusion-based models, improving video quality and lipsync accuracy. However, the increasing complexity of these models has led to inefficiencies in training and inference, as well as constraints on video length and inter-frame continuity. In this paper, we propose JoyVASA, a diffusion-based method for generating facial dynamics and head motion in audio-driven facial animation. Specifically, in the first stage, we introduce a decoupled facial representation framework that separates dynamic facial expressions from static 3D facial representations. This decoupling allows the system to generate longer videos by combining any static 3D facial representation with dynamic motion sequences. Then, in the second stage, a diffusion transformer is trained to generate motion sequences directly from audio cues, independent of character identity. Finally, a generator trained in the first stage uses the 3D facial representation and the generated motion sequences as inputs to render high-quality animations. With the decoupled facial representation and the identity-independent motion generation process, JoyVASA extends beyond human portraits to animate animal faces seamlessly. The model is trained on a hybrid dataset of private Chinese and public English data, enabling multilingual support. Experimental results validate the effectiveness of our approach. Future work will focus on improving real-time performance and refining expression control, further expanding the framework’s applications in portrait animation.
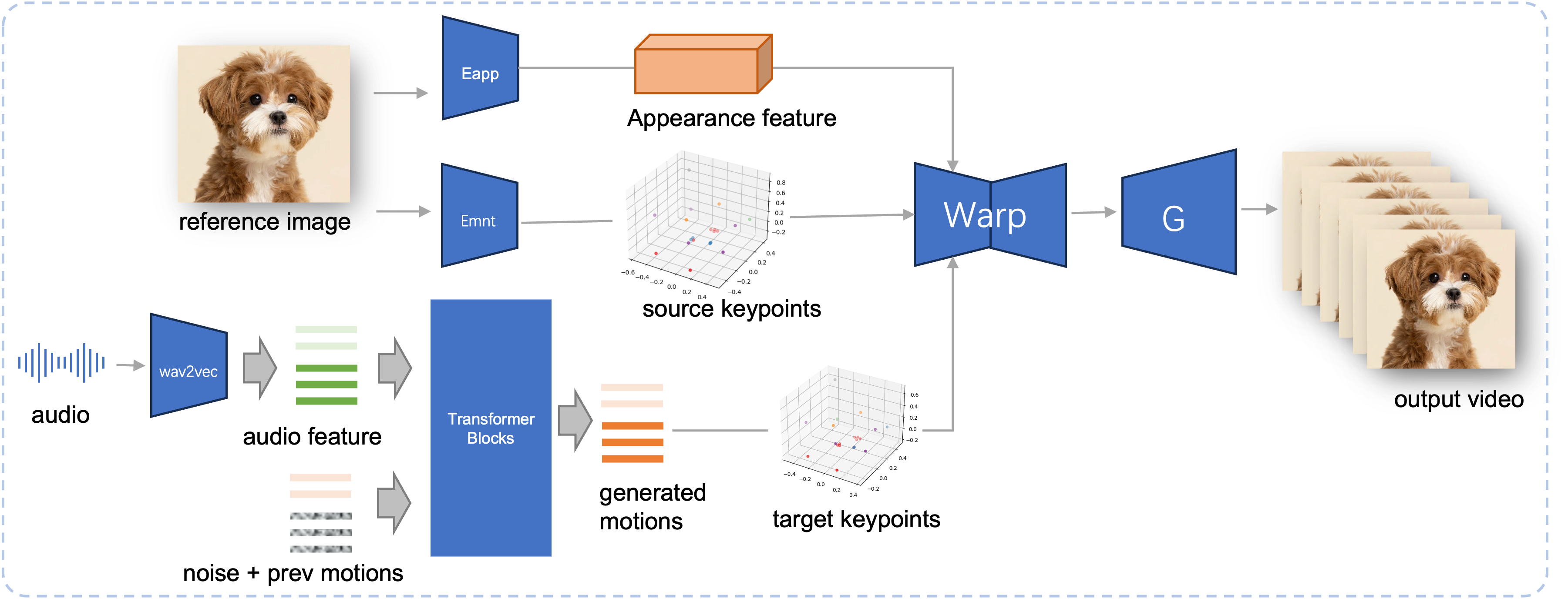
Inference Pipeline of the proposed JoyVASA. Given a reference image, we first extract the 3D facial appearance feature using the appearance encoder in LivePortrait, and also a series of learned 3D keypoints using the motion encoder. For the input speech, the audio features are initially extracted using the wav2vec2 encoder. The audio-driven motion sequences are then sampled using a diffusion model trained in the second stage in a sliding window fashion. Using the 3D keypoints of reference image, and the sampled target motion sequences, the target keypoints are computed. Finally, the 3D facial appearance feature is warped based on the source and target keypoints and rendered by a generator to produce the final output video.
System requirements:
Ubuntu:
Tested on Ubuntu 20.04, Cuda 11.3
Tested GPUs: A100
Windows:
Tested on Windows 11, CUDA 12.1
Tested GPUs: RTX 4060 Laptop 8GB VRAM GPU
Create environment:
# 1. Create base environmentconda create -n joyvasa python=3.10 -y conda activate joyvasa # 2. Install requirementspip install -r requirements.txt# 3. Install ffmpegsudo apt-get update sudo apt-get install ffmpeg -y# 4. Install MultiScaleDeformableAttentioncd src/utils/dependencies/XPose/models/UniPose/ops python setup.py build installcd - # equal to cd ../../../../../../../
Make sure you have git-lfs installed and download all the following checkpoints to pretrained_weights:
git lfs install git clone https://huggingface.co/jdh-algo/JoyVASA
We suport two types of audio encoders, including wav2vec2-base, and hubert-chinese.
Run the following commands to download hubert-chinese pretrained weights:
git lfs install git clone https://huggingface.co/TencentGameMate/chinese-hubert-base
To get the wav2vec2-base pretrained weights, run the following commands:
git lfs install git clone https://huggingface.co/facebook/wav2vec2-base-960h
Note
The motion generation model with wav2vec2 encoder will be supported later.
# !pip install -U "huggingface_hub[cli]"huggingface-cli download KwaiVGI/LivePortrait --local-dir pretrained_weights --exclude "*.git*" "README.md" "docs"
Refering to Liveportrait for more download methods.
pretrained_weights contentsThe final pretrained_weights directory should look like this:
./pretrained_weights/
├── insightface
│ └── models
│ └── buffalo_l
│ ├── 2d106det.onnx
│ └── det_10g.onnx
├── JoyVASA
│ ├── motion_generator
│ │ └── iter_0020000.pt
│ └── motion_template
│ └── motion_template.pkl
├── liveportrait
│ ├── base_models
│ │ ├── appearance_feature_extractor.pth
│ │ ├── motion_extractor.pth
│ │ ├── spade_generator.pth
│ │ └── warping_module.pth
│ ├── landmark.onnx
│ └── retargeting_models
│ └── stitching_retargeting_module.pth
├── liveportrait_animals
│ ├── base_models
│ │ ├── appearance_feature_extractor.pth
│ │ ├── motion_extractor.pth
│ │ ├── spade_generator.pth
│ │ └── warping_module.pth
│ ├── retargeting_models
│ │ └── stitching_retargeting_module.pth
│ └── xpose.pth
├── TencentGameMate:chinese-hubert-base
│ ├── chinese-hubert-base-fairseq-ckpt.pt
│ ├── config.json
│ ├── gitattributes
│ ├── preprocessor_config.json
│ ├── pytorch_model.bin
│ └── README.md
└── wav2vec2-base-960h
├── config.json
├── feature_extractor_config.json
├── model.safetensors
├── preprocessor_config.json
├── pytorch_model.bin
├── README.md
├── special_tokens_map.json
├── tf_model.h5
├── tokenizer_config.json
└── vocab.jsonNote
The folder TencentGameMate:chinese-hubert-base in Windows should be renamed chinese-hubert-base.
Animal:
python inference.py -r assets/examples/imgs/joyvasa_001.png -a assets/examples/audios/joyvasa_001.wav --animation_mode animal --cfg_scale 2.0
Human:
python inference.py -r assets/examples/imgs/joyvasa_003.png -a assets/examples/audios/joyvasa_003.wav --animation_mode human --cfg_scale 2.0
You can change cfg_scale to get results with different expressions and poses.
Note
Mismatching Animation Mode and Reference Image may result in incorrect results.
Use the following command to start web demo:
python app.py
The demo will be create at http://127.0.0.1:7862.
If you find our work helpful, please consider citing us:
@misc{cao2024joyvasaportraitanimalimage,
title={JoyVASA: Portrait and Animal Image Animation with Diffusion-Based Audio-Driven Facial Dynamics and Head Motion Generation},
author={Xuyang Cao and Guoxin Wang and Sheng Shi and Jun Zhao and Yang Yao and Jintao Fei and Minyu Gao},
year={2024},
eprint={2411.09209},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2411.09209},
}We would like to thank the contributors to the LivePortrait, Open Facevid2vid, InsightFace, X-Pose, DiffPoseTalk, Hallo, wav2vec 2.0, Chinese Speech Pretrain, Q-Align, Syncnet, and VBench repositories, for their open research and extraordinary work.


