build your ai coding assistant
v0.0.2

In 2023, the popularity of generative AI will lead more and more organizations to introduce AI-assisted coding. What is slightly different from GitHub Copilot released in 2021 is that code completion is only one of many scenarios. A large number of companies are exploring scenarios such as generating complete code and code review based on requirements, and are also introducing generative AI to improve development efficiency.
In this context, we (Thoughtworks open source community) have also open sourced a series of AI auxiliary tools to help more organizations build their own AI-assisted coding assistants:
Because when we designed AutoDev, various open source models were constantly evolving. In this context, its steps are:
Therefore, this tutorial is also centered around these three steps. In addition, based on our experience, the sample technology stack for this tutorial:
Since our experience in AI is relatively limited, there will inevitably be some mistakes. Therefore, we also hope to work with more developers to build this open source project.
Combined with the artificial intelligence part of the JetBrains 2023 "Developer Ecosystem" report, we can summarize some general scenarios that reflect the areas where generative AI can play a role in the development process. Here are some of the main scenarios:
When we built AutoDev, we also discovered scenarios such as creating SQL DDL, generating requirements, TDD, etc. so. We provide the ability to customize scenarios so that developers can customize their own AI capabilities. For details, see: https://ide.unitmesh.cc/customize.
In daily coding, there are several different scenarios with different requirements for AI response speed (just as an example):
| scene | Response speed | Generate quality requirements | Size expected | illustrate |
|---|---|---|---|---|
| code completion | quick | middle | 1~6B | Code completion is the most common scenario in daily coding, and response speed is crucial. |
| Document generation | middle | middle | 1 | Documentation generation requires a full understanding of the code structure, and speed and quality are equally important. |
| code review | quick | middle | 1 | Code reviews require high-quality advice but also need to be as responsive as possible. |
| Unit test generation | quick | middle | 6B~ | Unit tests generate less context, and responsiveness and AI quality are equally important. |
| code refactoring | middle | high | 32B~ | Code refactoring may require more contextual understanding, and response times may be moderately slowed down. |
| demand generation | middle | high | 32B~ | Demand generation is a relatively complex scenario, and the response speed can be moderately slowed down to ensure accuracy. |
| Natural language code search and interpretation | Medium-Low | high | 32B~ | Natural language code search and interpretation are relatively complex scenarios, and the response speed can be moderately slowed down to ensure accuracy. |
PS: The 32B here is only expressed as an order of magnitude, because the effect will be better with a larger model.
Therefore, we summarize it as: one large, one middle, one micro and three models, providing comprehensive AI-assisted coding:
AI code completion can combine IDE tools to analyze the code context and rules of the programming language, and AI will automatically generate or suggest code snippets. In code completion tools similar to GitHub Copilot, they are usually divided into three subdivision modes:
Inline completion (Inline)
Similar to FIM (fill in the middle) mode, the completed content is in the current line. For example: BlotPost blogpost = new , the completion is: BlogPost(); to achieve: BlogPost blogpost = new BlogPost();
We can use Deepseek Coder as an example to see the effect in this scenario:
< |fim▁begin| > def quick_sort(arr):
if len(arr) < = 1:
return arr
pivot = arr[0]
left = []
right = []
< |fim▁hole| >
if arr[i] < pivot:
left.append(arr[i])
else:
right.append(arr[i])
return quick_sort(left) + [pivot] + quick_sort(right) < |fim▁end| >Here, we need to combine the code before and after the cursor.
In-block completion (InBlock)
Achieved through context learning (In-Context Learning), the completion content is in the current function block. For example, the original code is:
fun createBlog ( blogDto : CreateBlogDto ): BlogPost {
}The completed code is:
val blogPost = BlogPost (
title = blogDto.title,
content = blogDto.content,
author = blogDto.author
)
return blogRepository.save(blogPost)AfterBlock
Achieved through context learning (In-Context Learning), completion after the current function block, such as: completion of a new function after the current function block. For example, the original code is:
fun createBlog ( blogDto : CreateBlogDto ): BlogPost {
// ...
}The completed code is:
fun updateBlog ( id : Long , blogDto : CreateBlogDto ): BlogPost {
// ...
}
fun deleteBlog ( id : Long ) {
// ...
}When we build the corresponding AI completion function, we also need to consider applying it to the corresponding pattern data set to improve the quality of completion and provide a better user experience.
Some related resources for writing this article:
Code explanations are designed to help developers manage and understand large code bases more effectively. These assistants can answer questions about the code base, provide documentation, search code, identify sources of errors, reduce code duplication, etc., thus improving development efficiency, reducing error rates, and reducing the workload of developers.
In this scenario, depending on the quality of generation we expect, it is usually composed of two models: one large and one micro or one medium and one micro. The larger model has better results in terms of the quality of the generation. Combined with our design experience in the Chocolate Factory tool, usually such a function can be divided into several steps:
As a RAG application, it is divided into two parts: indexing and query.
In the indexing stage, we need to index the code base, which involves text segmentation, vectorization, database indexing and other technologies. One of the most challenging elements is splitting. The splitting rules we refer to are: https://docs.sweep.dev/blogs/chunking-2m-files. Right now:
In different scenarios, we can also divide in different ways. For example, in Chocolate Factory, we divide through AST to ensure the quality of the generated context.
In the querying stage, we need to combine some of our traditional search technologies, such as vectorization search, path search, etc., to ensure the quality of the search. At the same time, in the Chinese scenario, we also need to consider the issue of conversion to Chinese, such as converting English to Chinese to ensure the quality of search.
For daily assistance, we can also achieve it through generative AI, such as automatically creating SQL DDL, automatically creating test cases, automatically creating requirements, etc. These can be achieved only by customizing prompt words and combining specific domain knowledge, so I won’t go into details here.
In addition to the model, context is also an important factor affecting AI assistance capabilities. When we built AutoDev, we also discovered two different context modes:
A simple comparison is as follows:
| relevant context | similar context | |
|---|---|---|
| Search technology | static code analysis | Similarity search |
| data structure information | AST, CFG | Similar Chunk |
| Cross-platform capabilities | Depends on IDE, or independent parser | Not dependent on specific platforms |
| contextual quality | extremely high | high |
| Generate results | extremely high | high |
| build cost | Depends on language and platform | Low |
When the support for IDE is limited, context-related will bring higher cost performance .
GitHub Copilot adopts a similar context architectural pattern, and its detailed architecture is layered as follows:
In the research materials of the "public" Copilot-Explorer project, you can see how Prompt is built. The following is the prompt request sent to:
{
"prefix" : " # Path: codeviz \ app.py n #.... " ,
"suffix" : " if __name__ == '__main__': rn app.run(debug=True) " ,
"isFimEnabled" : true ,
"promptElementRanges" : [
{
"kind" : " PathMarker " ,
"start" : 0 ,
"end" : 23
},
{
"kind" : " SimilarFile " ,
"start" : 23 ,
"end" : 2219
},
{
"kind" : " BeforeCursor " ,
"start" : 2219 ,
"end" : 3142
}
]
}in:
prefix part used to build the prompt is built from promptElements, which includes: BeforeCursor , AfterCursor , SimilarFile , ImportedFile , LanguageMarker , PathMarker , RetrievalSnippet and other types. From the names of several PromptElementKind , we can also see its true meaning.suffix part used to construct the prompt is determined by the part where the cursor is located, and how many positions are left to be calculated based on the upper limit of tokens (2048). The token calculation here is the real LLM token calculation. In Copilot, it is calculated by Cushman002. The token length of Chinese characters is different, such as: { context: "console.log('你好,世界')", lineCount: 1, tokenLength: 30 } , where the length of the content in context is 20, but tokenLength is 30, the length of Chinese characters is 5 (including , ), and the token occupied by a single character is 3.Here is a more detailed example of a Java application context:
// Path: src/main/cc/unitmesh/demo/infrastructure/repositories/ProductRepository.java
// Compare this snippet from src/main/cc/unitmesh/demo/domain/product/Product.java:
// ....
// Compare this snippet from src/main/cc/unitmesh/demo/application/ProductService.java:
// ...
// @Component
// public class ProductService {
// //...
// }
//
package cc . unitmesh . demo . repositories ;
// ...
@ Component
public class ProductRepository {
//...In the computing context, GitHub Copilot uses Jaccard coefficient (Jaccard Similarity). This part of the implementation is implemented in Agent. For more detailed logic, please refer to: After spending more than half a month, I finally reverse-engineered Github Copilot.
Related resources:
As mentioned above, the relevant code relies on static code analysis , mainly with the help of structural information of the code, such as AST, CFG, DDG, etc. In different scenarios and platforms, we can combine different static code analysis tools. The following are some common static code analysis tools:
In the completion scenario, through static code analysis, we can get the current context, such as: current function, current class, current file, etc. The following is an example of AutoDev's context for generating unit tests:
// here are related classes:
// 'filePath: /Users/phodal/IdeaProjects/untitled/src/main/java/cc/unitmesh/untitled/demo/service/BlogService.java
// class BlogService {
// blogRepository
// + public BlogPost createBlog(BlogPost blogDto)
// + public BlogPost getBlogById(Long id)
// + public BlogPost updateBlog(Long id, BlogPost blogDto)
// + public void deleteBlog(Long id)
// }
// 'filePath: /Users/phodal/IdeaProjects/untitled/src/main/java/cc/unitmesh/untitled/demo/dto/CreateBlogRequest.java
// class CreateBlogRequest ...
// 'filePath: /Users/phodal/IdeaProjects/untitled/src/main/java/cc/unitmesh/untitled/demo/entity/BlogPost.java
// class BlogPost {...
@ ApiOperation ( value = "Create a new blog" )
@ PostMapping ( "/" )
public BlogPost createBlog ( @ RequestBody CreateBlogRequest request ) { In this example, the context of createBlog function is analyzed to obtain the function's input and output classes: CreateBlogRequest , BlogPost information, and BlogService class information, which are provided to the model as context (provided in comments). At this point, the model generates more accurate constructors, as well as more accurate test cases.
Since the relevant context relies on static code analysis of different languages and APIs of different IDEs, we also need to adapt to different languages and different IDEs. In terms of construction cost, it is more expensive relative to similar contexts.
IDEs and editors are the main tools for developers, and their design and learning costs are relatively high. First, we can use the official template to generate:
Then, add functionality on top (isn’t it very simple), of course not. The following are some IDEA plug-in resources that you can refer to:
Of course, it is more appropriate to refer to the AutoDev plug-in.
You can directly use the official template to generate the corresponding plug-in: https://github.com/JetBrains/intellij-platform-plugin-template
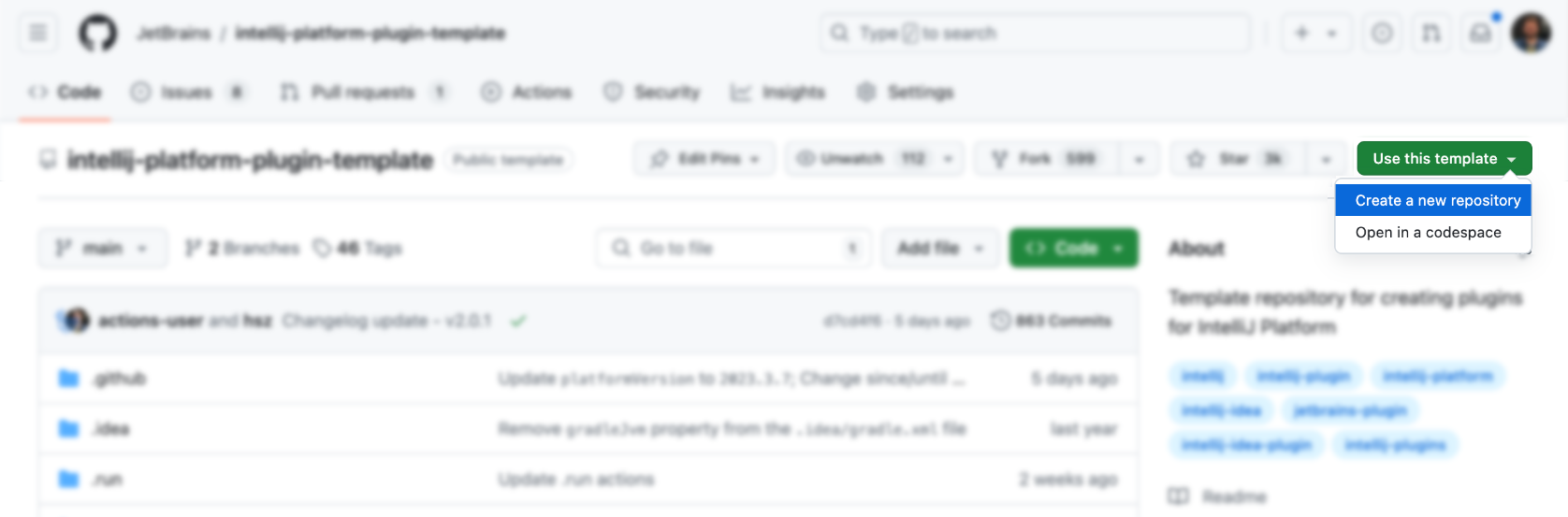
For IDEA plug-in implementation, it is mainly implemented through Action and Listener, which only need to be registered in plugin.xml . For details, please refer to the official documentation: IntelliJ Platform Plugin SDK
Since we did not consider the compatibility issue with IDE versions of AutoDev in the early stage, in order to be compatible with older versions of IDE later, we need to perform compatibility processing on the plug-in. Therefore, as described in the official document: Build Number Ranges, we can see that different versions have different requirements for the JDK. The following are the requirements for different versions:
| Branch number | IntelliJ Platform version |
|---|---|
| 233 | 2023.3 |
| 232 | 2023.2 |
| 231 | 2023.1 |
| 223 | 2022.3 |
| 222 | 2022.2 NOTE Java 17 is now required (blog post) |
| 221 | 2022.1 |
| 213 | 2021.3 |
| 212 | 2021.2 |
| 211 | 2021.1 |
| 203 | 2020.3 NOTE Java 11 is now required (blog post) |
And configure it into gradle.properties :
pluginSinceBuild = 223
pluginUntilBuild = 233.*Subsequent configuration of compatibility is troublesome, so you can refer to AutoDev's design.
In terms of automatic code completion, domestic manufacturers mainly refer to the implementation of GitHub Copilot, and the logic is not complicated.
Trigger using shortcut keys
It mainly monitors user input in Action, and then:
| Function | shortcut key | illustrate |
|---|---|---|
| requestCompletions | Alt + / | Get the current context and then get the completion results through the model |
| applyInlays | TAB | Display completion results on the IDE |
| disposeInlays | ESC | Cancel completion |
| cycleNextInlays | Alt + ] | Switch to the next completion result |
| cyclePrevInlays | Alt + [ | Switch to the previous completion result |
Use automatic triggering method
It mainly monitors user input through EditorFactoryListener , and then triggers different completion results based on different inputs. The core code is as follows:
class AutoDevEditorListener : EditorFactoryListener {
override fun editorCreated ( event : EditorFactoryEvent ) {
// ...
editor.document.addDocumentListener( AutoDevDocumentListener (editor), editorDisposable)
editor.caretModel.addCaretListener( AutoDevCaretListener (editor), editorDisposable)
// ...
}
class AutoDevCaretListener ( val editor : Editor ) : CaretListener {
override fun caretPositionChanged ( event : CaretEvent ) {
// ...
val wasTypeOver = TypeOverHandler .getPendingTypeOverAndReset(editor)
// ...
llmInlayManager.disposeInlays(editor, InlayDisposeContext . CaretChange )
}
}
class AutoDevDocumentListener ( val editor : Editor ) : BulkAwareDocumentListener {
override fun documentChangedNonBulk ( event : DocumentEvent ) {
// ...
val llmInlayManager = LLMInlayManager .getInstance()
llmInlayManager
.editorModified(editor, changeOffset)
}
}
}Then according to different inputs, different completion results are triggered and the structure is processed.
Render completion code
Subsequently, we need to implement an Inlay Render, which inherits from EditorCustomElementRenderer .
Combined with the interface capabilities of the IDE, we need to add the corresponding Action, the corresponding Group, and the corresponding Icon. The following is an example of Action:
<add-to-group group-id="ShowIntentionsGroup" relative-to-action="ShowIntentionActions" anchor="after"/>
The following are some ActionGroups of AutoDev:
| Group ID | AI uses | Description |
|---|---|---|
| ShowIntentionsGroup | Code refactoring, code interpretation, code generation, code testing | Used to display hints in code context and accessed via Alt + Enter and ⌥ + Enter shortcuts on macOS. |
| ConsoleEditorPopupMenu | fix errors | The menu displayed in the console, such as the console of the program execution structure. |
| Vcs.MessageActionGroup | Code information generation | Menu for writing commit messages in VCS. |
| Vcs.Log.ContextMenu | Code review, code interpretation, code generation | Menu for viewing logs in VCS, available functions: AI inspection of code, generation of release logs. |
| EditorPopupMenu | All are acceptable | Right-click menu, you can also add the corresponding ActionGroup |
When writing ShowIntentionsGroup, we can refer to the implementation of AutoDev to build the corresponding Group:
< group id = " AutoDevIntentionsActionGroup " class = " cc.unitmesh.devti.intentions.IntentionsActionGroup "
icon = " cc.unitmesh.devti.AutoDevIcons.AI_COPILOT " searchable = " false " >
< add-to-group group-id = " ShowIntentionsGroup " relative-to-action = " ShowIntentionActions " anchor = " after " />
</ group >Due to Intellij's platform strategy, the difference between running in a Java IDE (Intellij IDEA) and other IDEs such as Python IDE (Pycharm) becomes even greater. We need to provide compatibility based on multi-platform products. For detailed introduction, please refer to: Plugin Compatibility with IntelliJ Platform Products
First, the plug-in architecture is further modularized, that is, different modules are provided for different languages. The following is the modular architecture of AutoDev:
java/ # Java 语言插件
src/main/java/cc/unitmesh/autodev/ # Java 语言入口
src/main/resources/META-INF/plugin.xml
plugin/ # 多平台入口
src/main/resources/META-INF/plugin.xml
src/ # 即核心模块
main/resource/META-INF/core.plugin.xml In plugin/plugin.xml , we need to add the corresponding depends and extensions . The following is an example:
< idea-plugin package = " cc.unitmesh " xmlns : xi = " http://www.w3.org/2001/XInclude " allow-bundled-update = " true " >
< xi : include href = " /META-INF/core.xml " xpointer = " xpointer(/idea-plugin/*) " />
< content >
< module name = " cc.unitmesh.java " />
<!-- 其它模块 -->
</ content >
</ idea-plugin > In java/plugin.xml , we need to add the corresponding depends and extensions . The following is an example:
< idea-plugin package = " cc.unitmesh.java " >
<!-- suppress PluginXmlValidity -->
< dependencies >
< plugin id = " com.intellij.modules.java " />
< plugin id = " org.jetbrains.plugins.gradle " />
</ dependencies >
</ idea-plugin > Subsequently, Intellij will automatically load the corresponding module to achieve multi-language support. Depending on the different languages we expect to support, we need corresponding plugin.xml , such as:
cc.unitmesh.javascript.xml
cc.unitmesh.rust.xml
cc.unitmesh.python.xml
cc.unitmesh.kotlin.xml
cc.unitmesh.java.xml
cc.unitmesh.go.xml
cc.unitmesh.cpp.xmlFinally, just implement the corresponding functions in different language modules.
To simplify this process, we use Unit Eval to show how to build two similar contexts.
Through static code analysis, we can get the current function, current class, current file, etc. Combined with path similarity, find the most relevant context.
private fun findRelatedCode ( container : CodeContainer ): List < CodeDataStruct > {
// 1. collects all similar data structure by imports if exists in a file tree
val byImports = container. Imports
.mapNotNull {
context.fileTree[it. Source ]?.container?. DataStructures
}
.flatten()
// 2. collects by inheritance tree for some node in the same package
val byInheritance = container. DataStructures
.map {
(it. Implements + it. Extend ).mapNotNull { i ->
context.fileTree[i]?.container?. DataStructures
}.flatten()
}
.flatten()
val related = (byImports + byInheritance).distinctBy { it. NodeName }
// 3. convert all similar data structure to uml
return related
}
class RelatedCodeStrategyBuilder ( private val context : JobContext ) : CodeStrategyBuilder {
override fun build (): List < TypedIns > {
// ...
val findRelatedCodeDs = findRelatedCode(container)
val relatedCodePath = findRelatedCodeDs.map { it. FilePath }
val jaccardSimilarity = SimilarChunker .pathLevelJaccardSimilarity(relatedCodePath, currentPath)
val relatedCode = jaccardSimilarity.mapIndexed { index, d ->
findRelatedCodeDs[index] to d
}.sortedByDescending {
it.second
}.take( 3 ).map {
it.first
}
// ...
}
}For the above code, we can use the Imports information of the code as part of the relevant code. Then find relevant code through the inheritance relationship of the code. Finally, the closest context is found through path similarity.
Search first, and then find related code through code similarity. The core logic is shown:
fun pathLevelJaccardSimilarity ( chunks : List < String >, text : String ): List < Double > {
// ...
}
fun tokenize ( chunk : String ): List < String > {
return chunk.split( Regex ( " [^a-zA-Z0-9] " )).filter { it.isNotBlank() }
}
fun similarityScore ( set1 : Set < String >, set2 : Set < String >): Double {
// ...
}For details, see: SimilarChunker
TODO
TreeSitter is a framework for generating efficient custom parsers, developed by GitHub. It uses an LR(1) parser, which means it can parse any language in O(n) time instead of O(n²) time. It also uses a technique called "syntax tree reuse" that allows it to update syntax trees without reparsing the entire file.
Since TreeSitter already provides multi-language support, you can use Node.js, Rust and other languages to build corresponding plug-ins. See: TreeSitter for details.
Depending on our intentions, there are different ways to use TreeSitter:
Parse Symbol
In the code natural language search engine Bloop, we use TreeSitter to parse Symbols to achieve better search quality.
; ; methods
(method_declaration
name: (identifier) @hoist.definition.method)Then, decide how to display it based on the type:
pub static JAVA : TSLanguageConfig = TSLanguageConfig {
language_ids : & [ "Java" ] ,
file_extensions : & [ "java" ] ,
grammar : tree_sitter_java :: language ,
scope_query : MemoizedQuery :: new ( include_str ! ( "./scopes.scm" ) ) ,
hoverable_query : MemoizedQuery :: new (
r#"
[(identifier)
(type_identifier)] @hoverable
"# ,
) ,
namespaces : & [ & [
// variables
"local" ,
// functions
"method" ,
// namespacing, modules
"package" ,
"module" ,
// types
"class" ,
"enum" ,
"enumConstant" ,
"record" ,
"interface" ,
"typedef" ,
// misc.
"label" ,
] ] ,
} ;Chunk code
The following is how TreeSitter is used in Improving LlamaIndex's Code Chunker by Cleaning Tree-Sitter CSTs:
from tree_sitter import Tree
def chunker (
tree : Tree ,
source_code : bytes ,
MAX_CHARS = 512 * 3 ,
coalesce = 50 # Any chunk less than 50 characters long gets coalesced with the next chunk
) -> list [ Span ]:
# 1. Recursively form chunks based on the last post (https://docs.sweep.dev/blogs/chunking-2m-files)
def chunk_node ( node : Node ) -> list [ Span ]:
chunks : list [ Span ] = []
current_chunk : Span = Span ( node . start_byte , node . start_byte )
node_children = node . children
for child in node_children :
if child . end_byte - child . start_byte > MAX_CHARS :
chunks . append ( current_chunk )
current_chunk = Span ( child . end_byte , child . end_byte )
chunks . extend ( chunk_node ( child ))
elif child . end_byte - child . start_byte + len ( current_chunk ) > MAX_CHARS :
chunks . append ( current_chunk )
current_chunk = Span ( child . start_byte , child . end_byte )
else :
current_chunk += Span ( child . start_byte , child . end_byte )
chunks . append ( current_chunk )
return chunks
chunks = chunk_node ( tree . root_node )
# 2. Filling in the gaps
for prev , curr in zip ( chunks [: - 1 ], chunks [ 1 :]):
prev . end = curr . start
curr . start = tree . root_node . end_byte
# 3. Combining small chunks with bigger ones
new_chunks = []
current_chunk = Span ( 0 , 0 )
for chunk in chunks :
current_chunk += chunk
if non_whitespace_len ( current_chunk . extract ( source_code )) > coalesce


