context search engine
1.0.0

The primary objective of this project is to showcase Vector Search Capabilities by providing a user-friendly interface that enables users to perform contextual searches across a corpus of text documents. By leveraging the power of Hugging Face's BERT and Facebook's FAISS, we return highly relevant text passages based on the semantic meaning of the user's query rather than mere keyword matches. This project serves as a starting point for developers, researchers, and enthusiasts who wish to dive deeper into the world of contextualized text search and enhance their applications with state-of-the-art NLP techniques.
My goal is to ensure we understand vector database behind the scenes from scratch.
Screen Shot of Application:
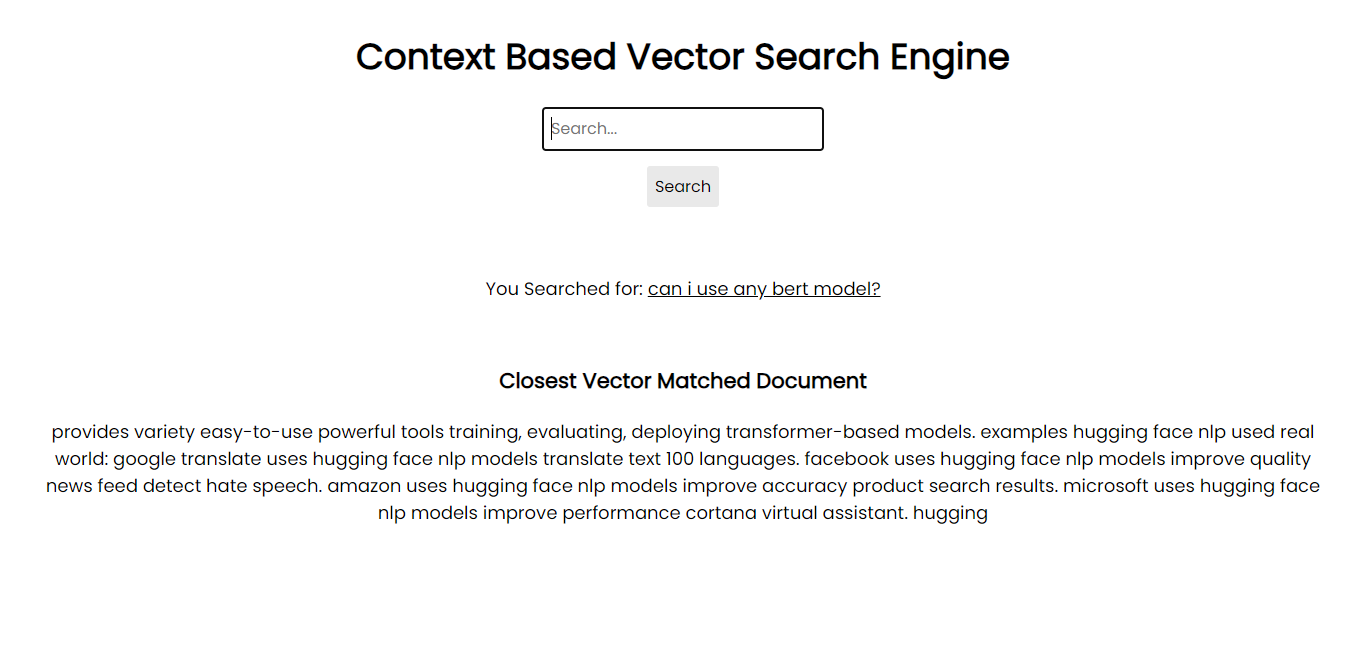
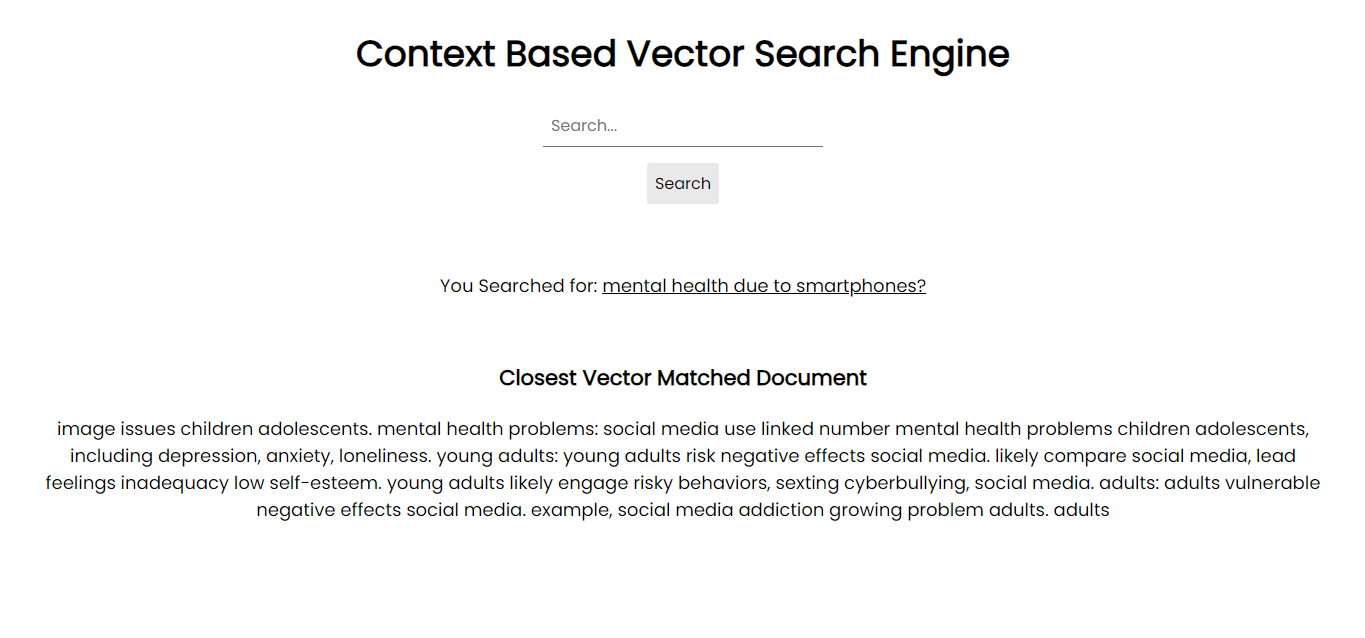
In order to run on your system, you can install the all the necessary packages via pip using requirements files:
pip install -r requirements.txtFor your information, I am using Python 3.10.1.
However, if you have a GPU, you are requested to install FAISS GPU for faster and larger database integrations.
The current version of this project encompasses:
While the project offers a functional contextual search system, it is designed to be modular, allowing for potential expansion and integration into larger systems or applications.
The foundation of this project lies in the belief that modern NLP techniques can offer far more accurate and contextually relevant search results compared to traditional keyword-based methods. Here's a breakdown of our approach:
Based on the approach, I have divided the project into 2 sections:
Section 1: Generating Searchable Vectored Data
In this section, we first read input from documents, break it down to smaller chunks, create vectors using BERT based model, and then store it efficiently using FAISS. Here is a flow diagram that illustrates the same.
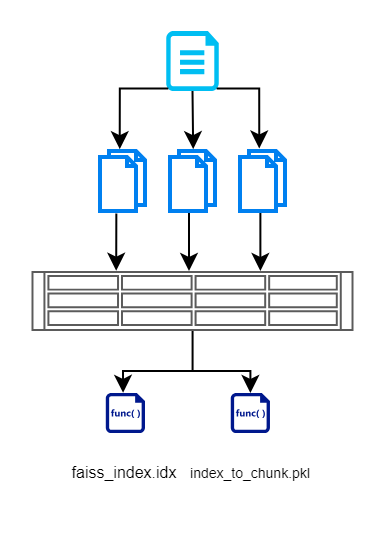
We create FAISS Index file which contains vector representation of the chunked document. We also store index of each chunk. This is maintain so that we do not have to query the database/documents again. This helps us in removing redundant read operations.
We perform this section using create_index.py. It will generate the above 2 files. If you need to use other models, you are open to do it from HuggingFace hub ?
Note: If you find issues in setting up hyperparameter for dimension, check the models config.json file to find details on dimension of the model you are trying to use.
Section 2: Building Searchable Application Interface
In this section, my goal is to build an interface which can allow users to interact with the documents. I prioritize minimalistic design without causing additional hurdles.
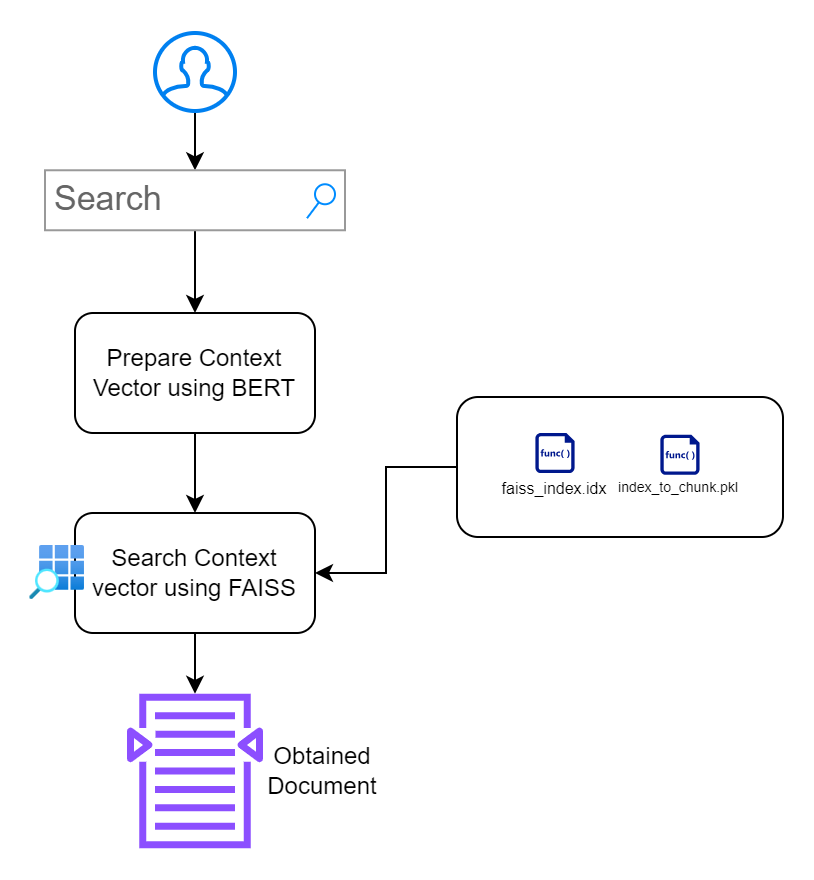
index.html: Front-end HTML page for inputting search queries.app.py: Flask application that serves the front-end and handles search queries.search_engine.py: Contains logic for embedding generation, FAISS searching, and keyword highlighting./context_search/
- templates/
- index.html
- static/
- css/
- style.css
- images/
- img1.png
- img2.png
- Approach.png files
- app.py
- search_engine.py
- create_index.py
- index_to_chunk.pkl
- faiss_index.idxfaiss_index.idx) and an accompanying mapping from index to text chunk (index_to_chunk.pkl).python app.py
-- OR --
flask run --host=127.0.0.1 --port=5000
http://localhost:5000.There's always room for enhancements. Here are some potential improvements and additional features that can be integrated:
This project is under the MIT License. Feel free to use by cite, modify, distribute, and contribute. Read more.
If you're interested in improving this project, your contributions are welcome! Please open a Pull Request or Issue on this repository. I am essentially prioritizing the above things to do for improvements. Other pull requests will also be considered but less prioritized.
Thanks in advance for your interest. :happy: .


