lark
1.2.2 - Bugfix for 1.2.1 (Earley issues with ambiguity)
Lark is a parsing toolkit for Python, built with a focus on ergonomics, performance and modularity.
Lark can parse all context-free languages. To put it simply, it means that it is capable of parsing almost any programming language out there, and to some degree most natural languages too.
Who is it for?
Beginners: Lark is very friendly for experimentation. It can parse any grammar you throw at it, no matter how complicated or ambiguous, and do so efficiently. It also constructs an annotated parse-tree for you, using only the grammar and an input, and it gives you convenient and flexible tools to process that parse-tree.
Experts: Lark implements both Earley(SPPF) and LALR(1), and several different lexers, so you can trade-off power and speed, according to your requirements. It also provides a variety of sophisticated features and utilities.
What can it do?
And many more features. Read ahead and find out!
Most importantly, Lark will save you time and prevent you from getting parsing headaches.
$ pip install lark --upgrade
Lark has no dependencies.
Lark provides syntax highlighting for its grammar files (*.lark):
These are implementations of Lark in other languages. They accept Lark grammars, and provide similar utilities.
Here is a little program to parse "Hello, World!" (Or any other similar phrase):
from lark import Lark
l = Lark('''start: WORD "," WORD "!"
%import common.WORD // imports from terminal library
%ignore " " // Disregard spaces in text
''')
print( l.parse("Hello, World!") )And the output is:
Tree(start, [Token(WORD, 'Hello'), Token(WORD, 'World')])Notice punctuation doesn't appear in the resulting tree. It's automatically filtered away by Lark.
Lark is great at handling ambiguity. Here is the result of parsing the phrase "fruit flies like bananas":
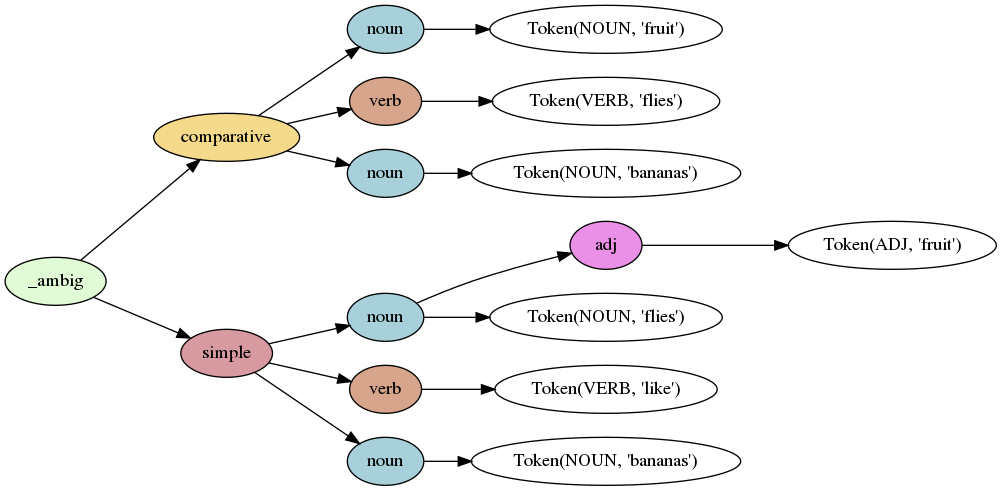
Read the code here, and see more examples here.
See the full list of features here
Lark is fast and light (lower is better)
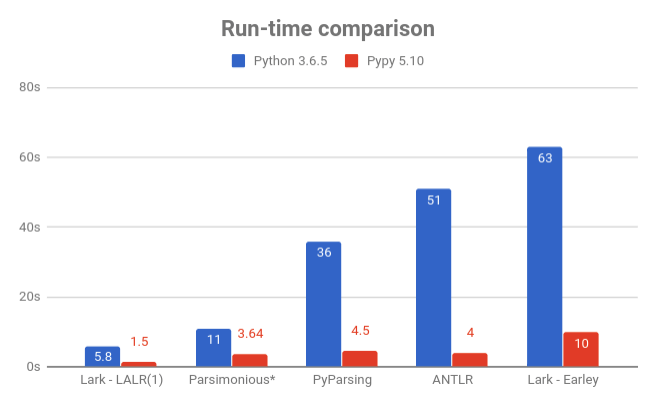
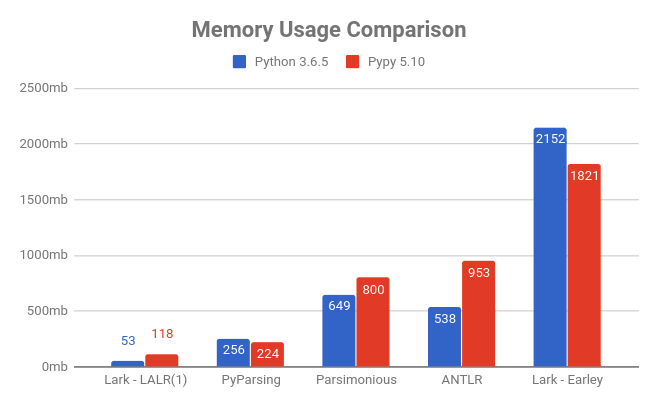
Check out the JSON tutorial for more details on how the comparison was made.
For thorough 3rd-party benchmarks, checkout the Python Parsing Benchmarks repo.
| Library | Algorithm | Grammar | Builds tree? | Supports ambiguity? | Can handle every CFG? | Line/Column tracking | Generates Stand-alone |
|---|---|---|---|---|---|---|---|
| Lark | Earley/LALR(1) | EBNF | Yes! | Yes! | Yes! | Yes! | Yes! (LALR only) |
| PLY | LALR(1) | BNF | No | No | No | No | No |
| PyParsing | PEG | Combinators | No | No | No* | No | No |
| Parsley | PEG | EBNF | No | No | No* | No | No |
| Parsimonious | PEG | EBNF | Yes | No | No* | No | No |
| ANTLR | LL(*) | EBNF | Yes | No | Yes? | Yes | No |
(* PEGs cannot handle non-deterministic grammars. Also, according to Wikipedia, it remains unanswered whether PEGs can really parse all deterministic CFGs)
Full list
Lark uses the MIT license.
(The standalone tool is under MPL2)
Lark accepts pull-requests. See How to develop Lark
Big thanks to everyone who contributed so far:
If you like Lark, and want to see us grow, please consider sponsoring us!
Questions about code are best asked on gitter or in the issues.
For anything else, I can be reached by email at erezshin at gmail com.
-- Erez


