ai outpainting com
1.0.0
https://www.ai-outpainting.com
pagina de inicio 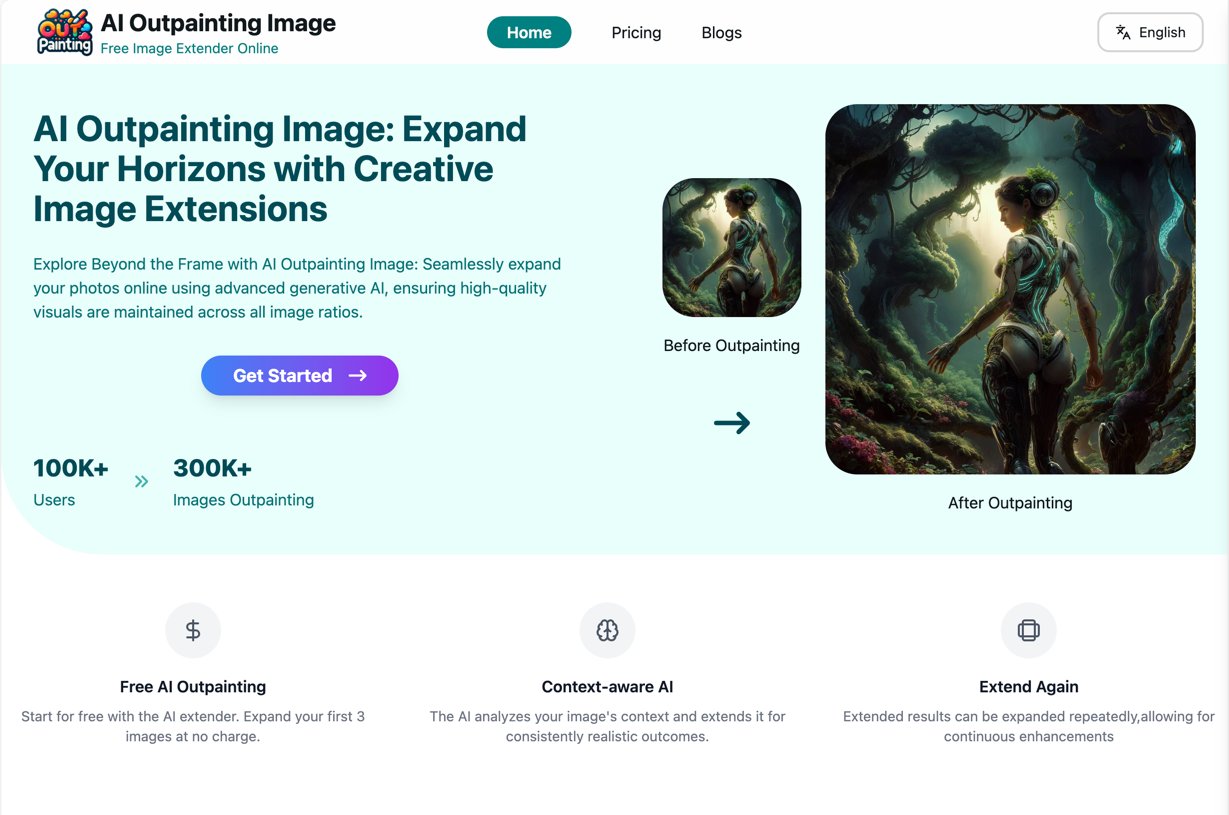
Página de precios 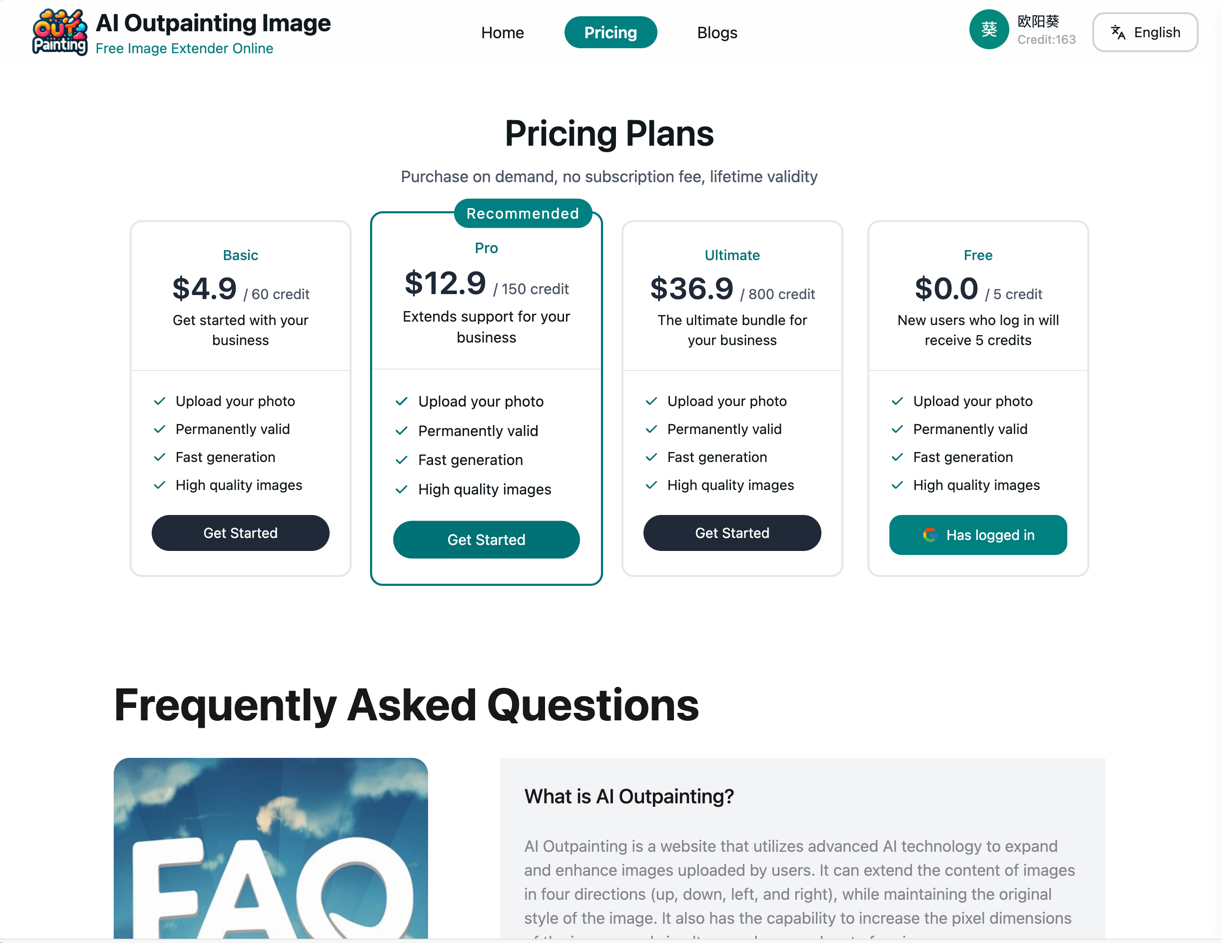
lista de blogs 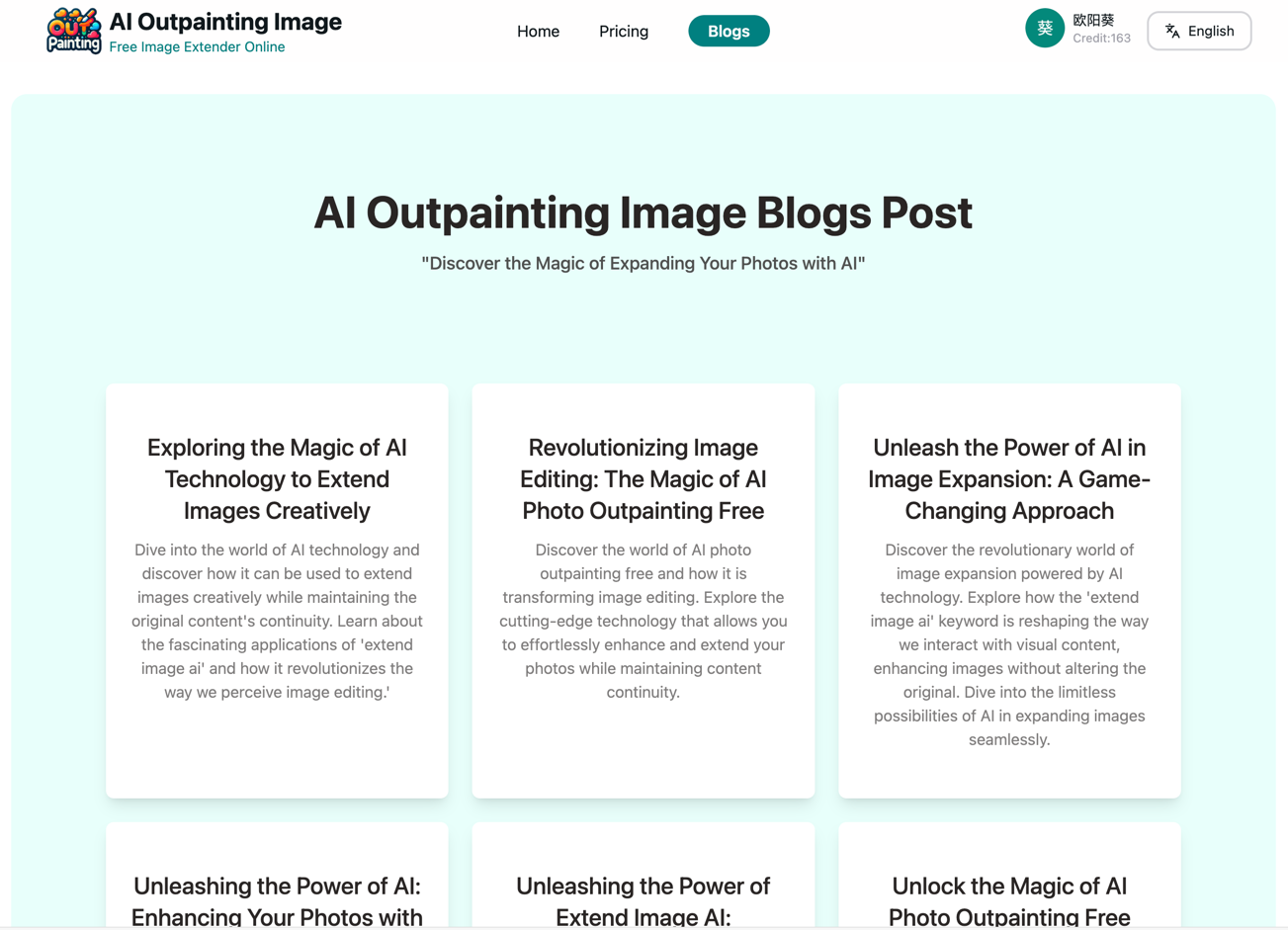
edición de imágenes 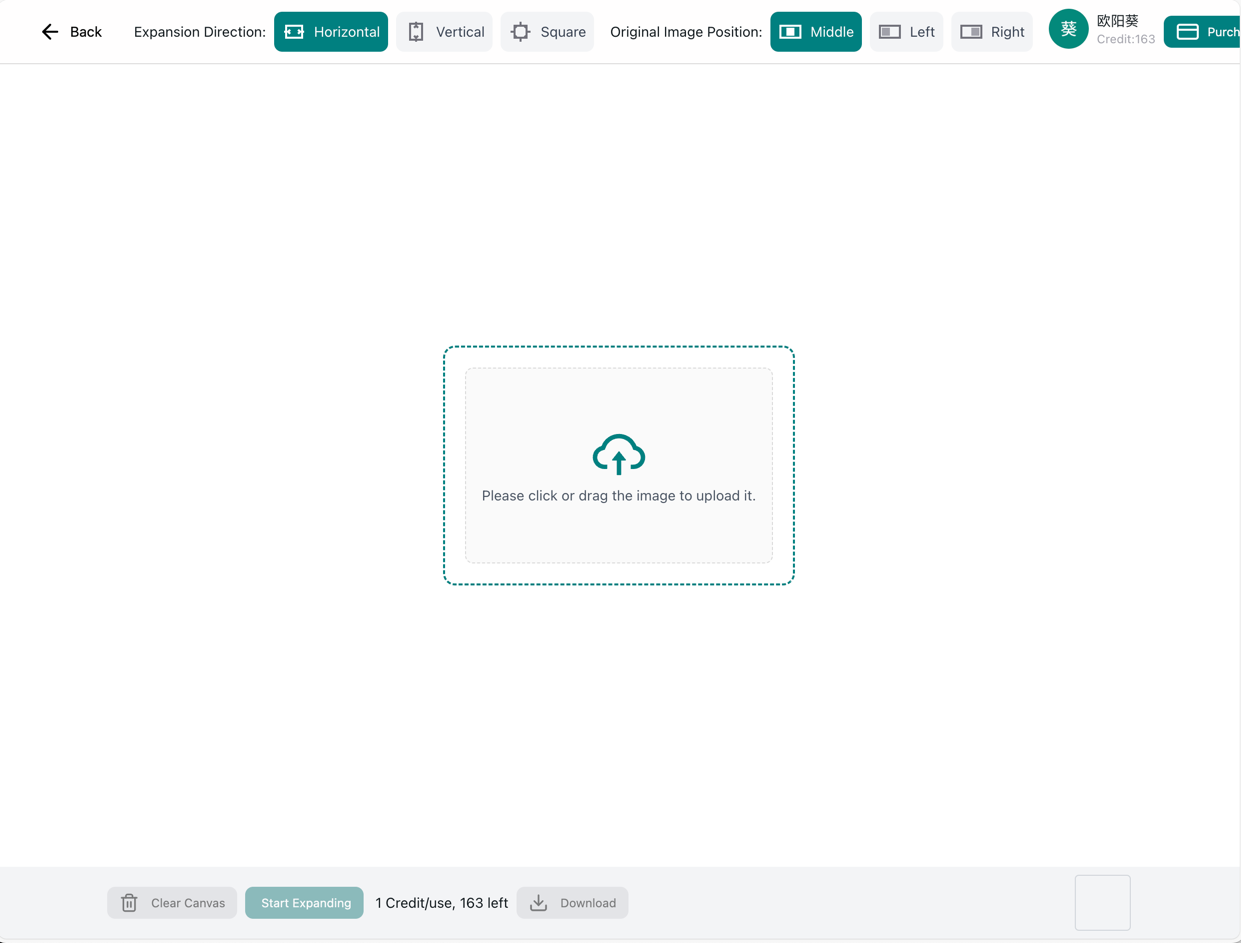
1. Sitio web de expansión de imágenes de IA desarrollado en base a nextjs 14 y tailwindcss3, dirección del sitio web: https://www.ai-outpainting.com/
2. El sitio web debe utilizarse con el modelo de IA de back-end. El modelo de back-end debe crearlo usted mismo.
Dirección del modelo: https://huggingface.co/spaces/fffiloni/diffusers-image-outpaint
3. La internacionalización se implementa usando lingui. La ventaja de esto en comparación con next-intl es que no es necesario generar una clave para cada copia. Extraerá la copia mediante comandos para generar archivos en varios idiomas. Luego haga la traducción basada en archivos en varios idiomas.
4. El proyecto ha escrito algunos scripts automatizados, como traducción automática de contenido internacional y traducción automática de contenido de blog. Estos deben ejecutarse manualmente cuando sea necesario.
5. El proyecto se basa en la base de datos, el almacenamiento en Cloudfare r2, los parámetros necesarios para iniciar sesión en Google y los parámetros de pago de PayPal. Estos parámetros se configuran en archivos .env y .env.production.
6. Utilice next-auth para integrar el inicio de sesión de Google. Si necesita iniciar sesión con Google durante el desarrollo local, debe modificar algún código fuente; de lo contrario, se informará un error. Consulte la descripción a continuación para modificaciones específicas.
7. Pago integrado de paypal y stripe. El entorno sandbox se utiliza para el desarrollo local. Para el entorno formal, los parámetros formales de PayPal deben configurarse en el archivo .env.production.
8. La forma en que el proyecto actual llama al modelo de IA es aproximadamente la siguiente:
Cargue los resultados del procesamiento en el almacenamiento de Cloudfare r2 y llame a la dirección de devolución de llamada para actualizar el estado del pedido del sitio web actual.
Los resultados del procesamiento se envían a la cola MQ al mismo tiempo y el servicio del administrador de colas MQ los envía al front-end. Una vez que el front-end recibe los resultados del procesamiento, los resultados se muestran en la página del front-end.
La interfaz inicia una solicitud para crear un pedido, lleva el número de pedido y la dirección de devolución de llamada de actualización del estado del pedido del sitio web actual y llama al servicio de administrador de colas MQ (este es un microservicio desarrollado en Python y no tengo tiempo para resolver el problema). código por el momento)
Inicie una solicitud SSE al backend del servicio de gestión de colas MQ, continúe esperando a que se complete el servicio del gestor de colas MQ y devuelva el resultado.
Después de recibir la solicitud, el servicio de administrador de colas MQ backend envía directamente la información del pedido a la cola MQ.
El servidor GPU escucha la cola MQ. Después de obtener la información del pedido, comienza a llamar al modelo AI para su procesamiento. Una vez completado el procesamiento, hará dos cosas:
Todo el proceso no implica comunicación directa entre el sitio web y el servidor GPU. Se reenvía a través del servicio de administrador de colas MQ y los archivos se transfieren a través del almacenamiento R2. Esto resuelve el problema de acoplamiento entre el servidor GPU y el sitio web. El volumen del pedido es demasiado grande, la GPU se puede agregar en cualquier momento. El servidor no requiere ningún ajuste en el sitio web.
9. El diagrama de arquitectura general es el siguiente: 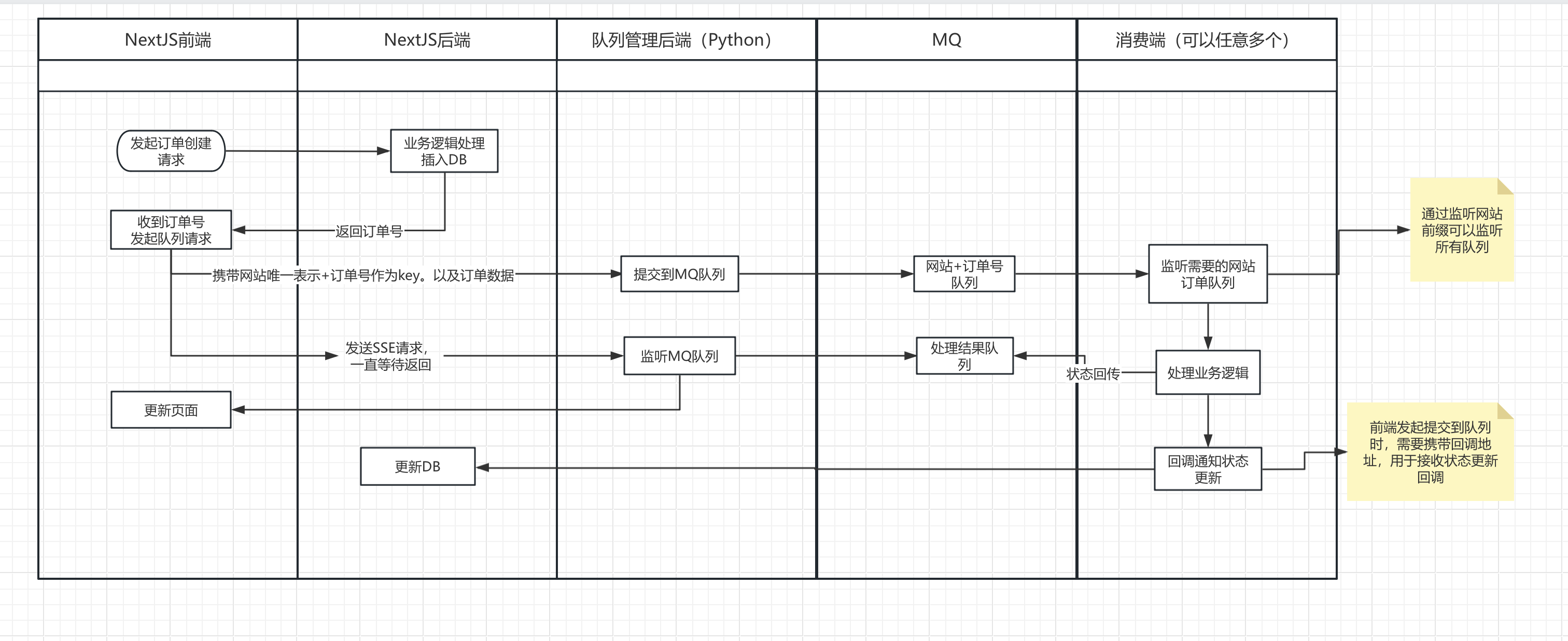
10.Otra solución de implementación
Cargue los resultados del procesamiento en el almacenamiento de Cloudfare r2 y llame a la dirección de devolución de llamada de actualización del estado del pedido del sitio web actual para actualizar el estado del pedido.
Después de que el front-end crea un pedido, la página verifica continuamente el estado del pedido mediante sondeo hasta que se completa el pedido.
Hay otros programas en el backend que escanean periódicamente la base de datos y obtienen pedidos con el estado del pedido pendiente. Después de obtener la información del pedido, comienzan a llamar al modelo AI para su procesamiento. hecho:
11. Si tiene el presupuesto, también puede considerar usar el servicio API de runpod directamente. No necesita implementar el servidor del administrador de colas MQ usted mismo, solo integre su SDK.
Código de referencia
importar runpodSdk, {EndpointCompletedOutput, EndpointIncompleteOutput} de la función async 'runpod-sdk' fetchProcessByRunPod(datos: cualquiera): Promesa<EndpointIncompleteOutput undefinido> {
// const serverUrl = `${UE_PROCESS_API}/create_docker`
// https://docs.runpod.io/serverless/endpoints/job-operatives
const runpod = runpodSdk("N5Jxxxxxxxxxxxxx");
punto final constante = runpod.endpoint("1zgk5xi3ew77pv");
console.log ("iniciar invocar el punto final de runpod, datos:", datos)
devolver punto final?.run({"entrada": datos,
})}Si necesita utilizar completamente la función de expansión de imágenes de IA en el código fuente del proyecto actual, debe elegir una solución como se describe anteriormente y modificar la lógica de creación de pedidos y monitorear el estado de los pedidos en la aplicación/[lang]/(editor )/editor/view.tsx archivo! ! !
Cada vez que se modifica la página para contener contenido nuevo, debe ejecutar el comando yarn extract para extraer la nueva copia en el archivo internacionalizado y ejecutar el comando yarn translate para traducir la copia al idioma correspondiente.
Si hay nuevos artículos de blog, debe ejecutar el comando yarn translate para traducir el nuevo contenido del blog al idioma correspondiente.
La traducción implica llamar a la API. Primero debe solicitar la clave API y luego modificar la clave API en scripts/openai-chat.js.
Si necesita agregar o reducir contenido en varios idiomas, debe modificar estos tres archivos: framework/locale/locale.ts framework/locale/localeConfig.js framework/locale/messagesLoader.ts
Utilice directamente el comando node scripts/generator-website.js para generar contenido del sitio web (este comando generará textos, TDK y títulos de blog relacionados con las palabras clave especificadas)
Primero debe modificar las palabras clave y la descripción y luego ejecutar el comando.
// Palabra clave del sitio web const palabra clave = 'extender imagen ai' // El sitio web debe describirse const descripción = 'Utilice tecnología de inteligencia artificial para expandir la imagen, garantizando al mismo tiempo que la imagen original permanezca sin cambios, expanda el contenido circundante y mantenga la continuidad del contenido con la imagen original.
Modifique la información de configuración en config/site.ts
Coloque su propio logo favicon.ico en el directorio public/ y reemplace directamente el archivo original
Modifique el nombre de dominio en public/sitemap.xml
Modifique la información de configuración en .env y .env.production. Consulte los comentarios para conocer los requisitos de modificación específicos.
El proyecto actual utiliza prisma como marco ORM. La estructura de la tabla se declara en el archivo esquema.prisma. Para usarlo por primera vez, debe ejecutar el siguiente comando.
// Este comando generará una tabla de base de datos basada en la declaración de estructura de la tabla e inicializará los datos de la tabla. Si hay nuevas actualizaciones de campos de tabla, debe ejecutar el comando actual hilo pg:migrate // Para otros comandos de operación, se recomienda leer directamente la documentación oficial de prisma.
La información de coincidencia de colores del sitio web se almacena en el archivo tailwind.config.ts. Si necesita modificar la coincidencia de colores, modifique directamente el contenido en el archivo tailwind.config.ts.
Envíe el código a github.com y luego use vercel para asociar el almacén de códigos para la implementación. Consulte los documentos relevantes para el proceso específico.
【2024-10-19】 Resuelva el Error: ENOENT: no such file or directory xxx/.next/fallback-build-manifest.json arreglando "@lingui/swc-plugin": "4.0.8" , versión resuelta. Elimine el directorio local node_modules y reinstale las dependencias para resolver el problema.
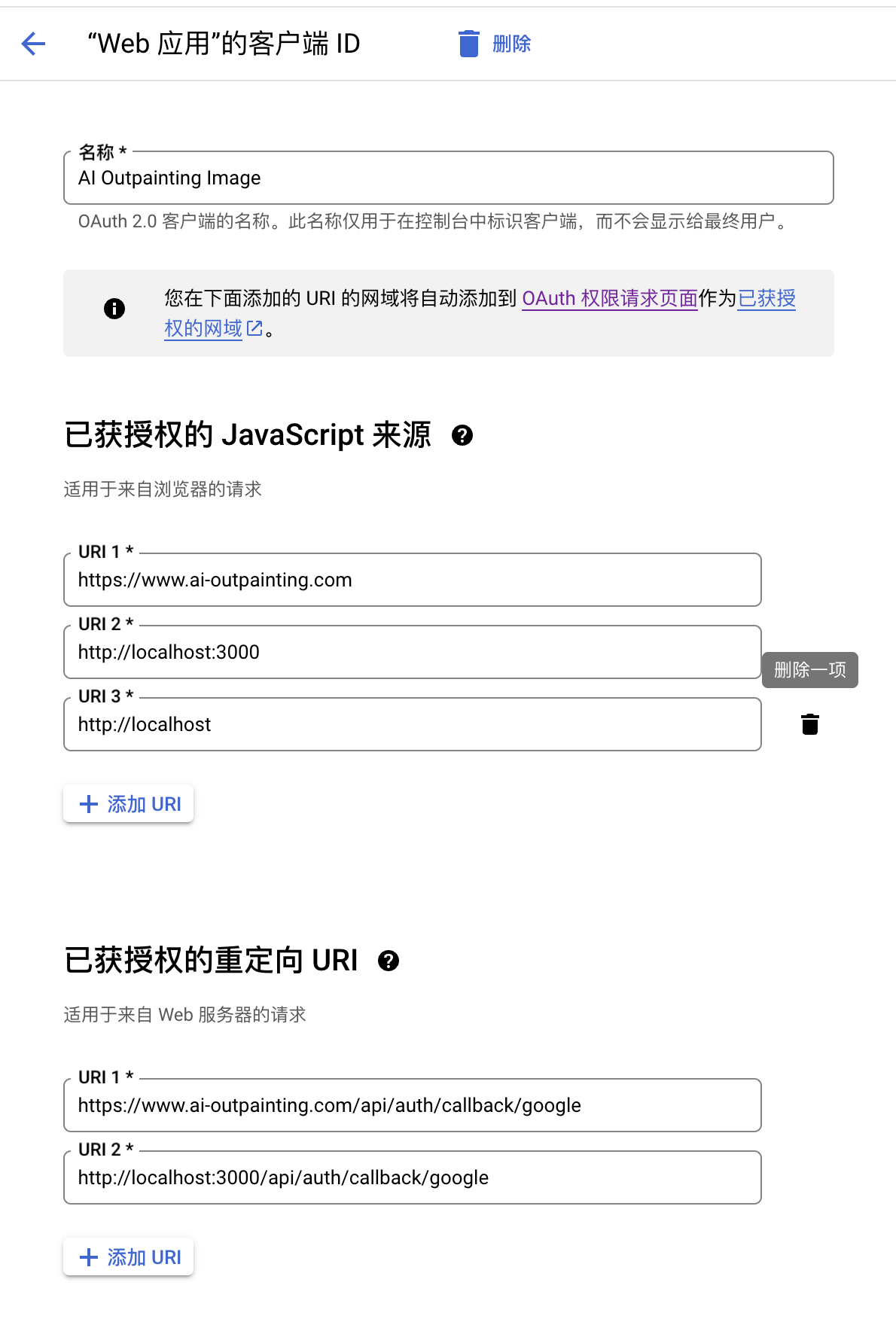
Agregar captura de pantalla de referencia de configuración de inicio de sesión de Google
【2024-10-20】 Resuelva el problema del Error: Cannot find module 'canvas' al iniciar agregando el complemento de ignorar el paquete web. Optimice el método de carga de archivos en varios idiomas.
1. Sitio web del componente de código Pure Tailwindcss
Algunos códigos de componentes ya preparados se pueden copiar directamente desde el sitio web y se implementan completamente en base a dos
2. Marco de interfaz de usuario basado en componentes-nextui.org
Proporciona uso directo basado en componentes encapsulados.
3.icono componente-reaccionar-iconos
Proporciona múltiples conjuntos de íconos predeterminados que se pueden usar directamente
4.Generación de página de precios
shipixén
5.Internacionalización
Generar dinámicamente archivos de internacionalización
6.Blog MDX
Generar contenido de blog basado en MDX
7.Centro de configuración de autenticación de Google
Configure los parámetros necesarios para iniciar sesión en Google
En el entorno de desarrollo de proyectos actual, se utiliza una dirección de proxy personalizada para resolver el problema de no poder llamar a google.com localmente. Para una configuración específica, consulte el código config/auth-config.ts. El entorno de producción no se ve afectado.
https://www.prisma.io/docs/orm/more/help-and-troubleshooting/help-articles/vercel-caching-issue
Al hacer clic en Google para iniciar sesión, la página indica There is a problem with the server configuration. El backend indica [auth][error] OperationProcessingError: "response" body "issuer" property does not match the expected value , modifíquelo de la siguiente manera.
Modifique el archivo node_modules/@auth/core/node_modules/oauth4webapi/build/index.js o node_modules/oauth4webapi/dist/index.js
Después de la modificación, debe eliminar manualmente el directorio .next y volver a compilarlo.
Línea 1034, 1003 o 1237 (las diferentes versiones pueden ser diferentes), comente la excepción generada. Es posible que algunas versiones nuevas no estén necesariamente en esta línea. Puede consultar los siguientes puntos para encontrar el mensaje de error y luego comentarlo.
función validarIssuer(esperado, resultado) {
if (result.claims.iss !== esperado) {// throw new OPE('valor de reclamo inesperado JWT "iss" (emisor)');
}
devolver resultado;}Línea 250 o 238 (puede ser diferente en diferentes versiones), comente sobre la excepción lanzada
if (nueva URL (json.issuer).href! == esperadoIssuerIdentifier.href) {
// lanza nueva OPE('"respuesta" cuerpo "emisor" no coincide con "expectedIssuer"');}Después de la modificación, debe eliminar manualmente el directorio .next y ejecutar run dev nuevamente.
Modifique el código de idioma y las palabras de destino para ajustar la densidad de palabras en scripts/add-word-locale.js
Ejecute el comando en el directorio cd scripts/: bun run add-word-locale.js o node add-word-locale.js
Este proyecto adopta la licencia de código abierto del MIT, respete el contenido del acuerdo.
Si está dispuesto, deje un enlace a mi sitio web: https://www.ai-outpainting.com/ ¡Muchas gracias!
Si el proyecto te resulta útil, dale una estrella, ¡muchas gracias!
Si tiene alguna pregunta técnica, agregue WeChat para comunicarse: fafafa-ai
Pequeño anuncio: el sitio web actual de ai-outpainting acepta el envío pago de enlaces externos. Los amigos que lo necesiten pueden contactarme.


